今年早些时候,Meta AI 发布了他们的新开源项目: Segment Anything Model(SAM) ,在计算机视觉社区引起了巨大的轰动。SAM 是一种快速分割系统,它擅长于对不熟悉的物体和图像进行零样本泛化,而不需要额外的训练。
在本教程中,我将演示如何结合使用 SAM 和 GroundingDINO 以及Stable Diffusion 来创建一个接受文本作为输入的pipeline,以便使用生成式 AI 执行图像inpainting和outpainting。
在演示之前,总体了解下我们的pipeline:

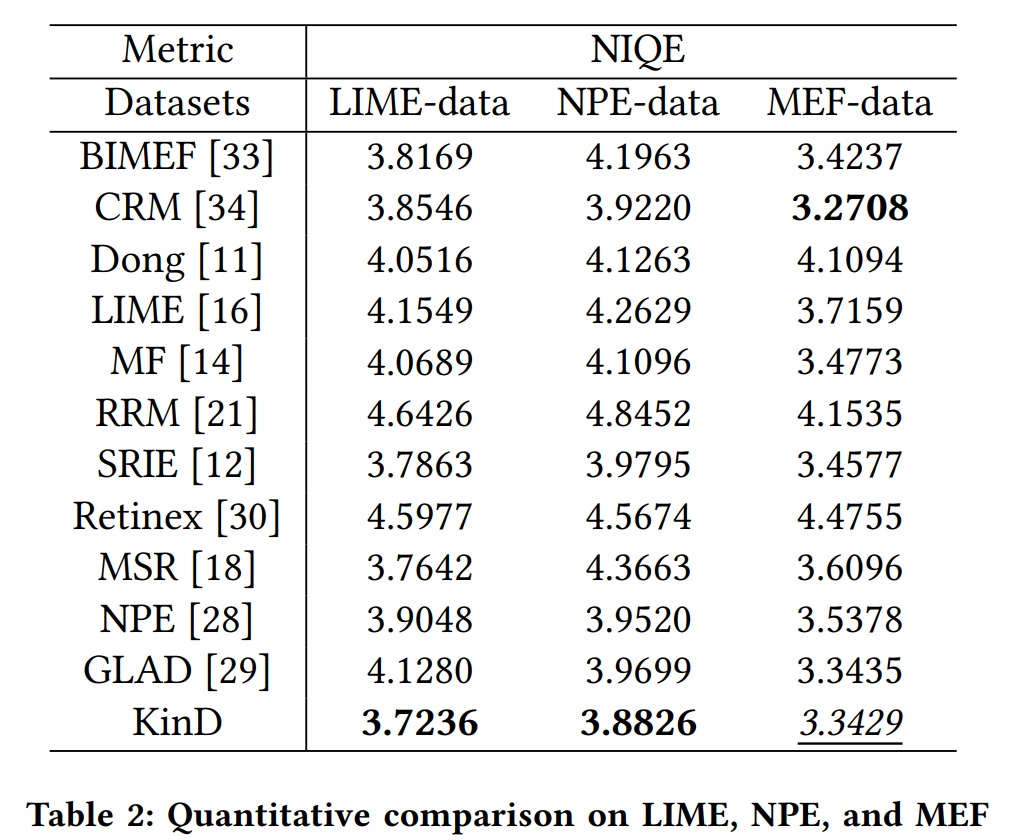
系统先使用Grounding DINO 根据输入的文本进行对象检测,然后将对象检测结果作为输入 传递给 Segment Everything 得到图像掩码(Mask),这些掩码结合文本prompts 作为Stable Diffusion的输入,由SD来进行图像的重绘。
为了让大家对上述流程更清楚的理解,先介绍下 SAM,从官方宣传片得知,它擅长识别图片中的多对象,包括背景:

https://huggingface.co/spaces/segments/panoptic-segment-anythingHuggingface 有个空间,可以来尝试SAM:
比如针对下面左边图,输入对象类别:car,bus,person
右边图就能够识别每种类型的对象,并用不同的颜色标记出来。
比如你只想看识别出来的car:

这里只看识别出来的person:

还有人眼都看不清的 bus:

还有其他类别,比如 buildings,sidewalk,sky等:

还有马路上的电车:

以及在汽车前面等红绿灯的摩托车以及被电灯竖杆挡住的car 都能精准识别:

这确实让人震惊了,如果这种对象识别稳定的话,那用于自动驾驶L5级别完全没有问题。
为了进一步测试它的效果,我找来一张鸭子养殖户的照片,看看能不能数出来有多少只鸭:


果然不出所料:只识别出来2只,比我预料的差多了!不知道是我哪里没用对还是 模型 不行。 先不管了,有空再研究吧。继续我们的正题。
SAM是搅局者 Meta AI的重量级产品,被认为是计算机视觉的第一个基础模型。是什么让 SAM 如此特别呢? SAM 接受了包含 1100 万张图像和 11 亿个分割掩模的海量数据集的训练,Meta 也公开发布了该数据集。基础模型是使用神经网络通过海量的无标签数据集上训练得来的,模型强大的能力带来了诸如ChatGPT和BERT这样的产品。
但是在计算机领域,还没有这种预训练模型,但是 SAM 改变了这一现状。
这么重要的基础模型,我们怎么用呢?很简单,SAM接受多种输入(交互)方式,主要有三种:
1. 鼠标点击(point input):

2. 有界框(bounding box):

3. 文本prompt:

但是SAM并没有很好的集成这些输入方式,但是SAM的输出却能够很好地跟下游AI应用结合。但是Grounding DINO 却能够补齐SAM的这一不足。这就是上图中 Grounding DINO +SAM+ Stable Diffusion 三剑客组成的pipeline 来 生成图像的由来。
接下来,我们看如何使用这一组合生成下面的图像:

左边是原图,右边是结果图。我们的目标是保持背景不变,重新绘制fox,将它变成斗牛犬。
首先准备一张 狐狸的图片:

BOX_THRESHOLD = 0.35
TEXT_THRESHOLD = 0.25
MODEL_TYPE = "vit_h" # default
IMAGE_PATH = f"{HOME}/data/fox.png"
TEXT_PROMPT = "fox . background"
image_bgr = cv2.imread(IMAGE_PATH)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)然后实例化两个模型:GroundingDINO和SAM:
from groundingdino.util.inference import ( load_model, load_image, predict, annotate, Model, ) # 实例化 GroundingDINO模型 grounding_dino_model = Model( model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH, )
# Instantiate SAM model sam = sam_model_registry[MODEL_TYPE](checkpoint=SAM_CHECKPOINT_PATH).to(device=device) mask_generator = SamAutomaticMaskGenerator(sam) sam_predictor = SamPredictor(sam)
最后初始化 Stable Diffusion Inpainting Pipeline ,这个模型也可以用于outpainting:
sd_pipe = StableDiffusionInpaintPipeline.from_pretrained( "stabilityai/stable-diffusion-2-inpainting", torch_dtype=torch.float16, ).to(device)
初始化完成之后,就可以用 grounding_dino_model来检测对象了:
# detect objects
detections, phrases = grounding_dino_model.predict_with_caption(
image=image_bgr,
caption=TEXT_PROMPT,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD,
)
detections.class_id = phrases
# convert bbox detections to masks and add to detections object
detections.mask = segment(
sam_predictor=sam_predictor, image=image_bgr, xyxy=detections.xyxy
)
fox = detections.mask[0]
background = detections.mask[1]其中:fox = detections.mask[0]
background = detections.mask[1]
是我们需要拿到的对象掩码。
ip_prompt = "a brown bulldog"
ip_negative_prompt = "low resolution, ugly"
ip_SEED = -1
generated_image = generate_image(
image=image_source_pil,
mask=image_mask_pil,
prompt=ip_prompt,
negative_prompt=ip_negative_prompt,
pipe=sd_pipe,
seed=ip_SEED,
)
generated_image调用sd depipeline 就可以根据mask对象来 inpainting对象了:

怎么样,相比 通过SD WebUI 手动绘制mask 得到蒙版,效率是不是快多了。这一过程中,你根本不需要关心mask的存在,只需要编程拿到对象作为参数传入sd即可。
再举个outpainting的例子,现在我们的目标变成这样的:狐狸不变,背景换掉。
此时只需要将背景mask 作为sd的参数既可:
op_prompt = "a hill with green grasses, weak sunlight"
op_negative_prompt = "low resolution, ugly"
op_SEED = -1
generated_image = generate_image(
image=image_source_pil,
mask=image_mask_pil,
prompt=op_prompt,
negative_prompt=op_negative_prompt,
pipe=sd_pipe,
seed=op_SEED,
)
generated_image以上代码在colab运行的,需要源代码的同学,请关注我的微信公众号:纵横AI大世界。






![切片[::-1]解析列表list表示的“非负整数加1”](https://img-blog.csdnimg.cn/20210916225739194.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzU3MTU4NDk2,size_16,color_FFFFFF,t_70)