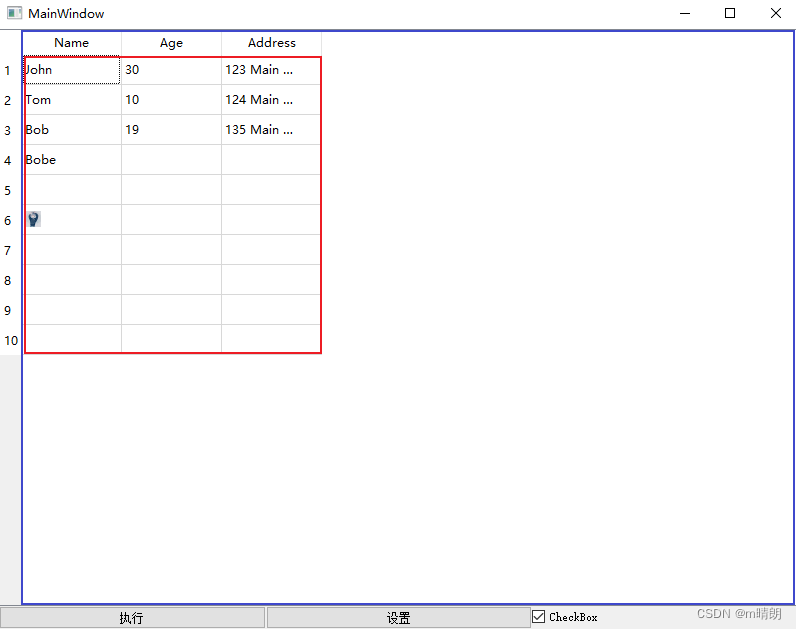
目录
1.算法描述
2.仿真效果预览
3.MATLAB核心程序
4.完整MATLAB
1.算法描述
蚁群算法是通过对自然界中真实蚂蚁的集体行为的观察,模拟而得到一种仿生优化算法,它具有很好的并行性,分布性.根据蚂蚁群体不同的集体行为特征,蚁群算法可分为受蚂蚁觅食行为启发的模型和受孵化分类启发的模型,受劳动分工和协作运输启发的模型.本文重点研究了前两种蚁群算法模型. 受蚂蚁觅食行为启发的模型又称为蚁群优化算法(ACO),是继模拟退火算法,遗传算法,禁忌搜索等之后又一启发式智能优化算法.目前它已成功应用于求解TSP问题,地图着色,路径车辆调度等优化问题.本文针对蚁群算法收敛时间长,易陷入局部最优的缺点,通过对路径上信息素的更新方式作出动态调整,建立信息素平滑机制,进而使得不同路径上的信息素的更新速度有所不同,从而使改进后算法能够有效地缩短搜索的时间,并能对最终解进行优化,避免过早的陷入局部最优. 聚类是数据挖掘的重要技术之一,它可按照某种规则将数据对象划分为多个类或簇,使同一类的数据对象有较高的相似度,而不同类的数据对象差异较大.
算法基本思想:
(1)根据具体问题设置多只蚂蚁,分头并行搜索。
(2)每只蚂蚁完成一次周游后,在行进的路上释放信息素,信息素量与解的质量成正比。
(3)蚂蚁路径的选择根据信息素强度大小(初始信息素量设为相等),同时考虑两点之间的距离,采用随机的局部搜索策略。这使得距离较短的边,其上的信息素量较大,后来的蚂蚁选择该边的概率也较大。
(4)每只蚂蚁只能走合法路线(经过每个城市1次且仅1次),为此设置禁忌表来控制。
(5)所有蚂蚁都搜索完一次就是迭代一次,每迭代一次就对所有的边做一次信息素更新,原来的蚂蚁死掉,新的蚂蚁进行新一轮搜索。
(6)更新信息素包括原有信息素的蒸发和经过的路径上信息素的增加。
(7)达到预定的迭代步数,或出现停滞现象(所有蚂蚁都选择同样的路径,解不再变化),则算法结束,以当前最优解作为问题的最优解。
1.1发车
选择节点X为发车节点选择该节点的发车数量Y.检索连通节点,排除禁忌表内节点,按照信息素浓度随机选择节点,将该节点加入路径表,将上一节点加入禁忌表,反复调用此方法直至抵达邮件目的地,对路径上节点做一次信息素增加,对全部节点做一次信息素挥发,挥发时判断各个节点车辆数是否过少如果过少则提高挥发率.
1.2到站
节点可看到下一目的地为自身的且当前位置在路上的车辆,当车到达时点击抵达——记录行驶成本,需记录在额外的表中.
1.3中途发车
如果行驶路径中仍有节点,判断当前节点是否有目的地与改车辆路径相符的邮件,如果有则将这些邮件装车直至邮件装完或者到达载重最大值,依行驶路径继续发车,车辆状态改为驶向节点Z。
1.4终点返程
如果行驶路径中没有节点了,将车辆目的地设为车辆归属地,判断当前节点是否有目的地与改车辆路径相符的邮件,如果有则将这些邮件装车直至这些邮件装完或者到达载重最大值,将车辆驶向车辆归属地节点。
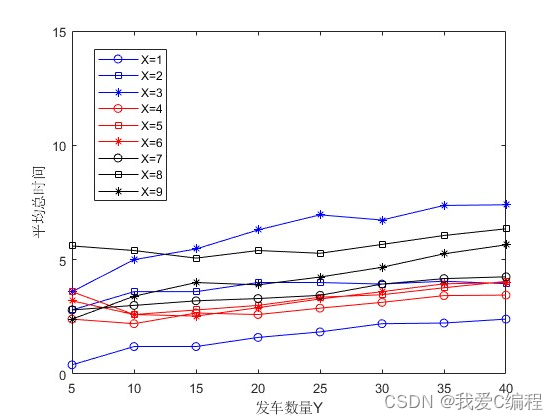
2.仿真效果预览
matlab2022a仿真结果如下:



3.MATLAB核心程序
%蚁群算法的参数
n = 9;
%信息素增加量
gamma0 = 0.1;
gamma = gamma0*ones(LEN,n);
%低于一定百分比,这里设置为50%
lvl1 = 0.5;
lvl2 = 0.7;%正常值
rho0 = 0.05; % 信息素挥发因子
rho = rho0*ones(LEN,n);
delta = 0.00012;
alpha = 0.5; % 信息素重要程度因子
beta = 0.5; % 启发函数重要程度因子
Q = 1; % 常系数
Eta = 1./D; % 启发函数
m = Tlate-Tearly;
Tau = 0.01*ones(LEN,n); % 信息素矩阵
Table = zeros(LEN,n); % 路径记录表
iter = 1; % 迭代次数初值
iter_max = 50;
%迭代寻找最佳路径
while iter <= iter_max
%%
iter
if iter==1
gamma0=0.1*ones(size(gamma));
end
% %首先记录运输车辆的发车时间并对车辆的到达时间做出预估,得出不同时间的各个节点的承运能力记录,
for i=1:Tlate-Tearly;
%这里按时间段进行分类统计不同整数时间段的邮件数量和重量
s1 = Tearly+i-1;
e1 = Tearly+i;
idx = find(Timee>=s1 & Timee < e1);
L = length(idx);
Mail_point0{i} = ends(idx);%....
Mail_Wpoint0{i} = package2(idx,6);%....
Mail_nums0(i,1) = L;%....
Mail_weight0(i,1) = sum(package2(idx,6));
for j = 1:length(idx)
Mail_paths0{i}{j} = mypaths{idx(j)};
end
Mail_idx0{i} = package2(idx,1);
end
Mail_point = Mail_point0;
Mail_Wpoint= Mail_Wpoint0;
Mail_nums = Mail_nums0;
Mail_weight= Mail_weight0;
Mail_paths = Mail_paths0;
Mail_idx = Mail_idx0;
%对Mail_paths进行处理
cnt1=1;
for i=1:Tlate-Tearly;
s1_ = [];
e1_ = [];
for j1 = 1:length(Mail_paths0{i})
path_tmp1 = Mail_paths0{i}{j1};
if isempty(path_tmp1)==0
s1_(j1) = path_tmp1(1);
e1_(j1) = path_tmp1(end);
end
end
bs=[];%得到唯一值
ms=[];%唯一值的缩影
ns=[];%相同的位置
[bs,ms,ns] = unique(e1_);
%合并相同的
idxx=[];
for j1=1:length(bs)
idxx = find(ns==j1);
%输出唯一路径
Mail_paths0_unique{i}{j1} = Mail_paths0{i}{ms(j1)};
Mail_point0_unique{i}(j1) = bs(j1);%....
%质量合并
Mail_Wpoint0_unique{i}{j1} = Mail_Wpoint0{i}(idxx);%....
Mail_Wpoint0_sumunique{i}{j1} = sum(Mail_Wpoint0{i}(idxx));%....
%统计合并后的各个区间的邮件编号
Mail_idx0_total{i}{j1} = Mail_idx0{i}(idxx);%....
end
end
Mail_point__ = Mail_point0;
Mail_Wpoint__= Mail_Wpoint0_sumunique;
Mail_nums__ = Mail_nums0;
Mail_weight__= Mail_weight0;
Mail_paths__ = Mail_paths0_unique;
Mail_idx__ = Mail_idx0_total;
%Mail_point
%Mail_Wpoint
%Mail_nums
%Mail_weight
%Mail_paths
figure(1);
subplot(211)
bar([Tearly:Tlate-1],Mail_nums)
title('不同时间段下的邮件数量');
subplot(212)
bar([Tearly:Tlate-1],Mail_weight)
title('不同时间段下的邮件总重量');
%%
%当蚂蚁出发时,预估到达各个节点时该节点的承运量水平
Carrying_capacity1 = zeros(Tlate-Tearly,n);%不同时刻,不同节点的承运量水平
Carrying_capacity2 = zeros(Tlate-Tearly,n);%不同时刻,不同节点的承运量水平对应的百分比
Carrying_select = zeros(Tlate-Tearly,n);%路节点被选择的概率越来越低。
for i=1:Tlate-Tearly;
point = Mail_point{i};
for j = 1:n%统计各个节点的承运量水平
Npoint = find(point==j);
if isempty(Npoint)==0
Carrying_capacity1(i,j) = [sum(sum(Mail_Wpoint{i}))]/(ceil((Tlate-Tearly)/2));
Carrying_capacity2(i,j) = Carrying_capacity1(i,j)/sum(sum(Carrying_capacity1));
else
Carrying_capacity1(i,j) = 0;
Carrying_capacity2(i,j) = 1;
end
end
end
%%
%如果预计到达某节点时该节点承运能力低于一定百分比,即使蚂蚁选择了这个节点,通过后信息素增加量也会很少,
for i=1:Tlate-Tearly;
point = Mail_point{i};
for j = 1:n%统计各个节点的承运量水平
Npoint = find(point==j);
if Carrying_capacity2(i,j)<lvl1 & isempty(Npoint)==0
gamma(i,j)=gamma0(i,j)*0.9;%信息素增加量也会很少,变少的方式可以自己定义不同的方式,我这里按原来0.9来定义
else
gamma(i,j)=gamma0(i,j);
end
%而当蚂蚁不通过这个节点时,信息素的挥发率rho会增大,
pathss = Mail_paths{i};
for jj = 1:length(pathss)
pathss2 = pathss{jj};
ix = find(pathss2==j);
if isempty(ix)==1%而当蚂蚁不通过这个节点时,信息素的挥发率rho会增大,
rho(i,j) = (1+delta)*rho(i,j);
else
rho(i,j) = (1-delta)*rho(i,j);
end
end
%这样当该节点的承运能力越来越低时,该路节点被选择的概率越来越低。%这里,将节点选择概率和承载百分比等同处理
Carrying_select(i,j) = Carrying_capacity2(i,j);
end
end
%%
for i=1:Tlate-Tearly;
point = Mail_point{i};
for j = 1:n
pathss = Mail_paths{i};
for jj = 1:length(pathss)
if isempty(pathss{jj}) == 0
Npoint = find(pathss{jj}(end)==j);
%节点的承运能力也将得到一定的恢复,将当前时刻的这两个变量变为正常情况下的标准情况下的承运能力
Carrying_capacity1(i,j) = round(0.9*Carrying_capacity1(i,j)); %一定程度的恢复
Carrying_capacity2(i,j) = 1-Carrying_capacity1(i,j)/sum(Mail_Wpoint{i});;%一定程度的恢复
%当承运能力恢复到一定水平的时候,再将该路径的信息素增加量和挥发率调整回正常值。
if Carrying_capacity2(i,j) > lvl2
rho(i,j) = rho0;
gamma(i,j)= gamma0(i,j);
end
end
end
end
end
%%
addcar = zeros(Tlate-Tearly,n);
for i=1:Tlate-Tearly;
for j = 1:n
if Carrying_capacity2(i,j) < lvl1%如果某个节点滞留的快件过多
%增加其他车辆前来的几率帮助此节点减轻快件压力。以此来达到整个运输网络的负载均衡。
addcar(i,j)=1;%用这个变量表示当前时刻对应的节点增加车辆,如果是0,则不增加
end
end
end
%更新Table
m = LEN;%每个邮件对应一个蚂蚁,构建信息表
start = zeros(m,1);
for i = 1:m
start(i) = Xsel;
end
%先将起点写入禁忌表
Table(1:m,1) = start;
%构建解空间
citys_index = 1:n;
%禁忌表Table的更新
for i = 1:m
target = mypaths{i};
for j = 2:length(target)
Table(i,j) = target(j);
end
for j = length(target)+1:n
Table(i,j) = target(end);
end
end
% 计算各个蚂蚁的路径距离
Length = zeros(m,1);
for i = 1:m
Route = Table(i,:);
target = mypaths{i};
for j = 1:length(target)-1
Length(i) = Length(i) + D(Route(j),Route(j + 1));
end
Length(i) = Length(i) + D(Route(n),Route(1));
end
%概率选择优化,参考文献3.4.2
for i = 1:m
Route = Table(i,:);
for j = 1:n
if mean(Carrying_capacity2(:,j))<0.4
miu=0.2;
end
if mean(Carrying_capacity2(:,j))>0.4 & mean(Carrying_capacity2(:,j))<1
miu=0.7;
end
if mean(Carrying_capacity2(:,j))>=1
miu=1;
end
if j<=n-1
PP(i,j) = (1-miu) * Tau(i,j)^alpha*[1/D(Route(j),Route(j + 1))]^beta/sum(sum(Tau(i,:).^alpha.*[1./D(Route(j),:)].^beta)) + miu*gamma(i,j)/gamma0(i,j);
else
PP(i,j) = (1-miu) * Tau(i,j)^alpha*[1/D(Route(1),Route(j))]^beta/sum(sum(Tau(i,:).^alpha.*[1./D(Route(j),:)].^beta)) + miu*gamma(i,j)/gamma0(i,j);
end
PP(i,j) = min(PP(i,j),1);
end
end
% 计算最短路径距离及平均距离
for i = 1:LEN
if iter == 1
[min_Length,min_index] = min(Length);
Length_best(iter) = min_Length;
Length_ave(iter) = mean(Length);
%找到最大概率值
[VV,II] = max((PP(i,:)));
Route_best{iter} = Table(i,1:II);
else
[min_Length,min_index] = min(Length);
Length_best(iter) = min(Length_best(iter - 1),min_Length);
Length_ave(iter) = mean(Length);
if Length_best(iter) <= min_Length
[VV,II] = max(sum(PP));
Route_best{iter} = Table(i,1:II);
else
Route_best{iter} = Route_best{iter-1};
end
end
%通过遗传之后,更新mypath这个变量,这样后面的消重合叠加的就是蚁群优化的后的变量了
%mypathss{i} = unique(Table(i,1:II)) ;
[ioo,joo] = unique(Table(i,1:II),'first');
mypathss{i} = Table(i,sort(joo));
end
%更新信息素
Delta_Tau = zeros(n,n);
for i = 1:m
for j = 1:n
Tau(i,j) = (1-rho(i,j)) * Tau(i,j) + rho(i,j)*gamma(i,j);%论文公式3.11 gamma为要求中提到的每次修正后的增量
end
end
iter = iter + 1;
gamma0=Tau;
end
%更新,
mypaths=mypathss;
for i=1:Tlate-Tearly;
%这里按时间段进行分类统计不同整数时间段的邮件数量和重量
s1 = Tearly+i-1;
e1 = Tearly+i;
idx = find(Timee>=s1 & Timee < e1);
L = length(idx);
Mail_point0{i} = ends(idx);%....
Mail_Wpoint0{i} = package2(idx,6);%....
Mail_nums0(i,1) = L;%....
Mail_weight0(i,1) = sum(package2(idx,6));
for j = 1:length(idx)
Mail_paths0{i}{j} = mypaths{idx(j)};
end
Mail_idx0{i} = package2(idx,1);
end
Mail_point = Mail_point0;
Mail_Wpoint= Mail_Wpoint0;
Mail_nums = Mail_nums0;
Mail_weight= Mail_weight0;
Mail_paths = Mail_paths0;
Mail_idx = Mail_idx0;
%对Mail_paths进行处理
cnt1=1;
for i=1:Tlate-Tearly;
s1_ = [];
e1_ = [];
for j1 = 1:length(Mail_paths0{i})
path_tmp1 = Mail_paths0{i}{j1};
if isempty(path_tmp1)==0
s1_(j1) = path_tmp1(1);
e1_(j1) = path_tmp1(end);
end
end
bs=[];%得到唯一值
ms=[];%唯一值的缩影
ns=[];%相同的位置
[bs,ms,ns] = unique(e1_);
%合并相同的
idxx=[];
for j1=1:length(bs)
idxx = find(ns==j1);
%输出唯一路径
Mail_paths0_unique{i}{j1} = Mail_paths0{i}{ms(j1)};
Mail_point0_unique{i}(j1) = bs(j1);%....
%质量合并
Mail_Wpoint0_unique{i}{j1} = Mail_Wpoint0{i}(idxx);%....
Mail_Wpoint0_sumunique{i}{j1} = sum(Mail_Wpoint0{i}(idxx));%....
%统计合并后的各个区间的邮件编号
Mail_idx0_total{i}{j1} = Mail_idx0{i}(idxx);%....
end
end
Mail_point__ = Mail_point0;
Mail_Wpoint__= Mail_Wpoint0_sumunique;
Mail_nums__ = Mail_nums0;
Mail_weight__= Mail_weight0;
Mail_paths__ = Mail_paths0_unique;
Mail_idx__ = Mail_idx0_total;
%%
id=0;
for i = 1:Tlate-Tearly
pointss=Mail_paths__{i};
for j = 1:length(pointss)
id=id+1;
%把路径记录下来Shortest_Route,
d = func_RL2d(Mail_paths__{i}{j},dist2);
LL{id} = d;%路径长度
RL{id} = Mail_paths__{i}{j}; %路径编号
NM{id} = id; %路径编号
end
end
%如果路径已记录累加路径上通过的邮件质量
%邮件质量
for i = 1:LEN
MASS2(i) = MASS(i);%重量
MASST(i) = package2(i,6); %路径质量
end
MASS3=MASS2;
for i = 1:Ynum
%将路径记录在车辆信息后,将记录的该路径质量归零,邮件状态设置为在车牌为XXXXX的某辆车上;
if MASS3(i)>=MASST(i)%载重大于等于质量最高的路径
Info{i}{1} = ['在车牌为',num2str(CARD(NM{i},:)),'的某辆车上'];
Info{i}{2} = [MASST(i)];%记录车辆载重
MASST(i) = 0;%清零
end
%则将路径记录在车辆信息后,将记录的该路径质量减去车辆载重的数值,
%邮件状态依序设置为在车牌为XXXXX的某辆车上直至车辆满载
if MASS3(i)<MASST(i)%载重小于等于质量最高的路径
Mass_ = MASST(i)-MASS3(i); %反复使用此方法直至达到发车数量Y为止)
if i<=Ynum-1
MASS3(i+1) = MASS3(i+1) + Mass_;%累计到后一个车进行运载
end
Info{i}{1} = ['在车牌为',num2str(CARD(NM{i},:)),'的某辆车上'];
Info{i}{2} = [MASS3(i)];
end
end
% 如果未满载车辆有经过未装车邮件目的地的节点相符合,
% 将邮件装车(设置邮件状态在车XXXXX上,车辆载重增加邮件质量)
% (设置邮件状态在车XXXXX上,车辆载重增加邮件质量)直至邮件装完或者全部车辆满载。
%将未装车邮件目的地
Info0=[];%单独存放这个增加变量
for i = 1:LEN-Ynum%——将未装车邮件目的地
ends = package2(Ynum+i,5); %未装车邮件目的地的节点
MASSother = MASS(Ynum+i);
for j = 1:Ynum%未满载车辆路径进行比对
Paths = RL{j};%如果未满载车辆
%判断是否有经过
idx = find(Paths==ends);
if isempty(idx) == 1%没有经过,不做处理
end
if isempty(idx) == 0%有经过
Info{j}{1} = ['在车牌为',num2str(CARD(NM{j},:)),'的某辆车上'];
if Info{j}{2} < MASS(j); %如果没装满
if MASS(j)-Info{j}{2}>=MASSother
Info{j}{2} = Info{j}{2}+MASSother;
MASS(Ynum+i)=0;
Info0{j}{1}=MASSother;
else
Info{j}{2} = MASS(j);
Info0{j}{1}= 0;
end
end
end
end
end
%%
%到站
%节点可看到下一目的地为自身的且当前位置在路上的车辆,当车到达时点击抵达
%——记录行驶成本(按照车辆载重*节点间公里数*收费标准),
%需记录在额外的表中(记录下车牌号,抵达时间,行驶路径段,这段路的载重,产生的费用,这段路运输的邮件数量)
%——更新车辆信息(当前位置),更新车辆上邮件所在地(即更新表中当前运输车辆为车牌XXXXX的车辆的邮件所在地为抵达的节点)
Info2=Info;%这个阶段,用info2去更新
for i = 1:Ynum
tmps1 = Info2{i}{1};%车牌信息
tmps2 = Info2{i}{2};%重量
%根据路段计算长度
dist = func_RL2d(RL{i},dist2);
Info2{i}{3} = tmps2*dist*MONEY;%记录行驶成本按照车辆载重*节点间公里数*收费标准)
Info2{i}{4} = RL{i};%行驶路径段
%计算时间
times = func_RL2T(RL{i},TME2);
Info2{i}{5} = times;
%这段路运输的邮件数量
Info2{i}{6} = tmps2/package2(i,6);
%当前位置
Info2{i}{7} = RL{i}(end);
end
%——判断抵达情况(终点,节点1,不是终点也不是节点1)
for i = 1:Ynum
if RL{i}(end)==package2(i,5)%终点
Info2{i}{8} = 1;%抵达情况
elseif RL{i}(end)==package2(i,4)%节点1
Info2{i}{8} = 0;%抵达情况
else
Info2{i}{8} = 2;%不是终点也不是节点1
end
end
%——①如果是终点则将所有邮件从车上卸载(删去当前运输车辆中的属性),
%将已抵达的邮件(当前所在地与目的地相同)状态设置为已抵达,记录抵达时间,然后使用终点返程功能
%——②如果如果到达的节点不是终点但是是节点1,先将目的地与当前所在地一致的邮件卸车,
for ii = 1:Ynum
if Info2{ii}{8}==1%终点
Info2{ii}{2}=0;%卸载,变为0.
Info2{ii}{9}=1;%已抵达Info2{i}{6}为抵达时间
%终点返程
%如果行驶路径中没有节点了,将车辆目的地设为车辆归属地,
%判断当前节点是否有目的地与改车辆路径相符的邮件,
%如果有则将这些邮件装车直至这些邮件装完或者到达载重最大值,将车辆驶向车辆归属地节点。
for i = 1:LEN-Ynum%——将未装车邮件目的地
ends = package2(Ynum+i,5); %未装车邮件目的地的节点
MASSother = MASS(Ynum+i);
for j = 1:Ynum%未满载车辆路径进行比对
Paths = RL{j};%如果未满载车辆
%判断当前节点是否有目的地与改车辆路径相符的邮件
idx = find(Paths(end)==ends);
if isempty(idx) == 1%没有经过,不做处理
end
if isempty(idx) == 0%有经过
Info2{j}{1} = ['在车牌为',num2str(CARD(NM{j},:)),'的某辆车上'];
if Info2{j}{2} < MASS(j); %如果没装满
if MASS(j)-Info2{j}{2}>=MASSother
Info2{j}{2} = Info2{j}{2}+MASSother;
MASS(Ynum+i)=0;
else
Info2{j}{2} = MASS(j);
end
end
end
end
end
end
if Info2{ii}{8}==0%节点1
Info2{ii}{2}=Info2{ii}{2}-Info0{ii}{1};%卸载,变为0.先将目的地与当前所在地一致的邮件卸车,即中间临时存放的
Info2{ii}{9}=1;%抵达Info2{i}{6}为抵达时间
%中途发车功能
%如果行驶路径中仍有节点,判断当前节点是否有目的地与改车辆路径相符的邮件,
%如果有则将这些邮件装车直至邮件装完或者到达载重最大值,
%依行驶路径继续发车,车辆状态改为驶向节点Z。
for i = 1:LEN-Ynum%——将未装车邮件目的地
ends = package2(Ynum+i,5); %未装车邮件目的地的节点
MASSother = MASS(Ynum+i);
for j = 1:Ynum%未满载车辆路径进行比对
Paths = RL{j};%如果未满载车辆
%如果行驶路径中仍有节点,判断当前节点
idx = find(Paths(2)==ends);
if isempty(idx) == 1%没有经过,不做处理
end
if isempty(idx) == 0%有经过
Info2{j}{1} = ['在车牌为',num2str(CARD(NM{j},:)),'的某辆车上'];
if Info2{j}{2} < MASS(j); %如果没装满
if MASS(j)-Info2{j}{2}>=MASSother
Info2{j}{2} = Info2{j}{2}+MASSother;
MASS(Ynum+i)=0;
else
Info2{j}{2} = MASS(j);
end
end
end
end
end
end
if Info2{ii}{8}==2%不是终点也不是节点1
Info2{ii}{2}=Info2{ii}{2};%将这些邮件卸车
Info2{ii}{9}=1;%抵达Info2{i}{6}为抵达时间
end
end
%更新价格和时间
for i = 1:Ynum
tmps1 = Info2{i}{1};%车牌信息
tmps2 = Info2{i}{2};%重量
%根据路段计算长度
dist = func_RL2d(RL{i},dist2);
Info2{i}{3} = tmps2*dist*MONEY;%记录行驶成本按照车辆载重*节点间公里数*收费标准)
Info2{i}{4} = RL{i};%行驶路径段
%计算时间
times = func_RL2T(RL{i},TME2);
Info2{i}{5} = times;
end
%根据上面的数据分别统计各个邮件的行走信息
xx = 0;
xy = 0;
for i = 1:length(Mail_idx__)
tmps = Mail_idx__{i};
weigh= Mail_Wpoint0_unique{i};
for j = 1:length(tmps)
xy = xy+1;
tmps2 =tmps{j};
weigh2=weigh{j};
yx =mod(xy,Ynum)+1;
for k = 1:length(tmps2)
xx = xx + 1;
%邮件对应车辆的车牌信息
pkg_info{xx}{1}=Info2{yx}{1};
%邮件的本身重量
pkg_info{xx}{2}=weigh2(k);
%记录重量*节点间公里数*收费标准)
pkg_info{xx}{3}=pkg_info{xx}{2}*func_RL2d(Mail_paths__{i}{j},dist2)*MONEY;
%%行驶路径段
pkg_info{xx}{4}=Mail_paths__{i}{j};
%计算时间
pkg_info{xx}{5}=func_RL2T(Mail_paths__{i}{j},TME2);
%和其相同路段上的邮件数量
pkg_info{xx}{6}=length(tmps2);
%邮件序号
pkg_info{xx}{7}=tmps2(k);
end
end
end
%%
%核算部分,计算运输成本与平均运达所需时间
for ii = 1:length(Info2)
moneys(ii) = Info2{ii}{3};
times(ii) = Info2{ii}{5};
end
moneysavg = mean(moneys)
timesavg = mean(times)
02_075m4.完整MATLAB
V

![[附源码]Python计算机毕业设计大学生社团管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/9a16bf1b01d74101837158307f630892.png)