📫作者简介:小明java问道之路,专注于研究 Java/ Liunx内核/ C++及汇编/计算机底层原理/源码,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 CSDN博客专家/后端领域优质创作者/内容合伙人、InfoQ签约作者、阿里云专家/签约博主、51CTO专家 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
专栏系列(点击解锁)
学习路线(点击解锁)
知识定位
🔥MySQL从入门到精通🔥
MySQL从入门到精通
全面讲解MySQL知识与实战
🔥计算机底层原理🔥
深入理解计算机系统CSAPP
构件计算机体系和计算机思维
Linux内核源码解析
围绕Linux内核讲解计算机底层原理与并发
🔥数据结构与企业题库精讲🔥
数据结构与企业题库精讲
结合工作经验深入浅出,适合各层次,笔试面试算法题精讲
🔥互联网架构分析与实战🔥
企业系统架构分析实践与落地
行业前沿视角,专注于技术架构升级路线、架构实践
互联网企业防资损实践
金融公司的防资损方法论、代码与实践。
本文目录
本文导读
一、什么是布隆过滤器(Bloom Filter)
二、布隆过滤器的工作原理与设计思想
三、Redis中的布隆过滤器
1、安装 RedisBloom
1.1、docker镜像安装
1.2、直接编译
2、Redis中布隆过滤器的使用
四、布隆过滤器特点与使用场景
总结
本文导读
本文系统性学习布隆过滤器(Bloom Filter),了解什么是布隆过滤器,布隆过滤器的原理,同时学习Redis中的布隆过滤器的安装与使用,针对其原理和特点,给出一些常见的使用场景。
一、什么是布隆过滤器(Bloom Filter)

布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
所以我们可以把布隆过滤器理解为一个不准确的 set 集合,当使用 contains 方法判断一个元素是否在一个集合中的时候,有可能会误判。
当布隆过滤器表示某个值存在时,该值可能不存在;当它说一个值不存在时,它就一定不存在。
例如,当它说它不认识你时,它一定是真的不认识你;当它说它认识你时,它可能根本没有见过你,只是因为你的脸和它认识的人的脸相似(一些熟悉面孔的系数组合),所以它误判了它以前认识你。
二、布隆过滤器的工作原理与设计思想
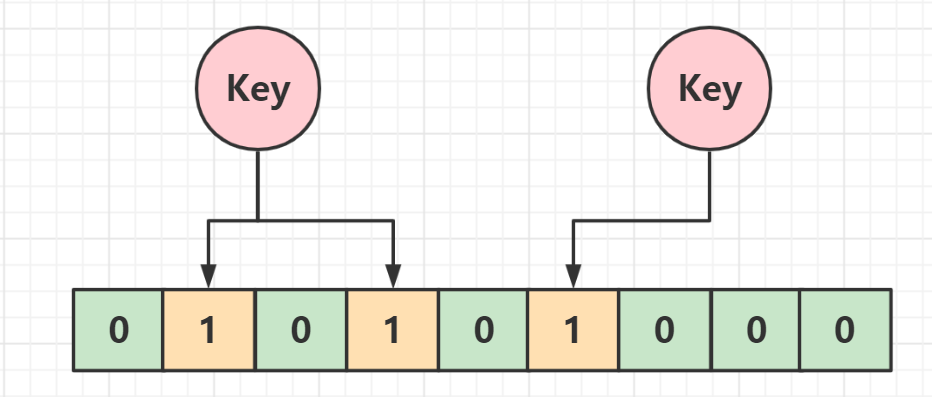
布隆过滤器(Bloom Filter)是一种数据结构,一个长度为 M 比特的位数组(bit array)与 K 个哈希函数(hash function) 组成。
1、布隆过滤器主要用于检索元素是否在集合中,位数组中元素的初始值为0,所有哈希函数都可以对输入数据进行统一和低哈希。

当我们想要插入一个元素时,将其输入K个哈希函数以生成K个哈希值。同时,使用这些哈希值作为位组的下标,并将与这些下标对应的位值设置为1。
当我们想查询一个元素时,你也可以将它输入K个哈希函数来生成K个哈希值,然后检查这些哈希值中对应的比特值。
如果任何位值为0,则元素必须不存在,如果所有位值均为1,则元素可能存在。为什么不是一定?因为位值1可能会受到其他元素的影响。随着数据的增加,越来越多的位值被设置为1。可能从未存储过值,但哈希函数返回的位值都是1。
因此,布隆过滤器用于检测元素是否必须不存在或可能存在。
三、Redis中的布隆过滤器
布隆过滤器(Bloom Filter)是Redis 4.0提供的新功能。它作为插件加载到Redis服务器中,为Redis提供了强大的重复数据消除功能。
与Set集合的重复数据消除功能相比,Blum过滤器可以节省90%以上的空间,但其缺点是重复数据消除率约为99%,即误报率约为1%。
该误差由布隆过滤器本身的结构决定。如果你想节省空间,类似于需要牺牲1%的假阳性率,这在处理海量数据时几乎可以忽略。
1、安装 RedisBloom
安装一般选用 docker镜像安装和直接编译的方式,下面给出两种方法
1.1、docker镜像安装
# docker 镜像安装布隆过滤器
# 拉取镜像
docker pull redislabs/rebloom:latest
# 运行容器
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom bash
# 连接容器中Redis服务
redis-cli1.2、直接编译
# 下载地址
https://github.com/RedisBloom/RedisBloom
# 解压文件
unzip RedisBloom-master.zip
# 进入目录
cd RedisBloom-master
# 执行编译命令,生成redisbloom.so 文件
make
# 拷贝至指定目录
cp redisbloom.so /usr/local/redis/bin/redisbloom.so
# 在redis配置文件里加入以下配置
loadmodule /usr/local/redis/bin/redisbloom.so
# 配置完成后重启redis服务
sudo /etc/init.d/redis-server restart
# 测试是否安装成功
127.0.0.1:6379> bf.add www.biancheng.net hello2、Redis中布隆过滤器的使用
常用命令
bf.add:添加元素到布隆过滤器。
bf.exists:判断某个元素是否在于布隆过滤器中。
bf.madd:同时添加多个元素到布隆过滤器。
bf.mexists:同时判断多个元素是否存在于布隆过滤器中。
bf.reserve:以自定义的方式设置布隆过滤器参数值,共有 3 个参数分别是 key、error_rate(错误率)、initial_size(初始大小)。
错误率过高的问题
因为上诉hash的分散原理,错误率越低,所需的空间越大。因此尽可能准确地估计元素的数量,以避免空间浪费,所以需要根据具体业务确定错误率的允许范围,对于不需要太精确的业务场景,可以设置稍高的错误率。
四、布隆过滤器特点与使用场景
特点
1、底层原理是哈希判断,所以时间效率非常高。空间效率也是一个主要优势
2、存在计算错误的可能性,应在特定场景中使用(哈希冲突无法区分,所以不容易删除它们)
使用场景
1、黑名单:垃圾邮件过滤功能,从数十亿个垃圾邮件列表(类似地,垃圾邮件)中判断电子邮件是否为垃圾邮件
2、URL重复数据消除:web爬虫对URL进行重复数据消除,以避免对同一URL地址进行爬网,我们希望它每次只抓取最新的页面,而不抓取尚未更新的页面。因为策略爬虫系统必须对已爬网的URL进行重复数据消除,否则将严重影响执行效率。但是,如果使用集合来加载这些URL地址,则会严重浪费资源空间。
4、Key-Value缓存系统的密钥验证(缓存渗透):缓存渗透,将所有可能的数据缓存放入Bloon过滤器。当黑客访问不存在的缓存时,他们会迅速返回以避免缓存和数据库发生故障。
3、身份验证:例如,订单系统查询订单ID是否存在,如果不存在则直接返回。
总结
本文系统性学习布隆过滤器(Bloom Filter),了解什么是布隆过滤器,布隆过滤器的原理,同时学习Redis中的布隆过滤器的安装与使用,针对其原理和特点,给出一些常见的使用场景。






![[附源码]Python计算机毕业设计宠物寄养平台设计Django(程序+LW)](https://img-blog.csdnimg.cn/f10ab18d410b4589b6a56e771a72a66c.png)