文章目录
- 简介
- 卷积层
- 池化层
- 激活层
- 线性层
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介

上图摘自网络
受生物神经网络的启发,每个神经元与其他神经元相连,当它兴奋的时候就会向相连的神经元发送化学信号,从而改变这些神经元内的电位,当神经元的电位超过阈值后就会被激活,即也变得兴奋起来,继而向其他神经元发送化学信号。
神经网络中可以看成是由若干节点和边组成的图。节点就是神经元,可以存储数字;边用来存储权重,表示传给哪些神经元,而是否超过阈值达到兴奋就是激活函数。神经网络的学习就是从训练数据中,根据损失函数,找到使得损失函数最小的权重参数。
神经网络可以分为前馈神经网络和反馈神经网络。前馈神经网络就是信息从前向后传递,神经元接受上一次的的输入,并输出传递给下一层,各层之间没有反馈。反馈神经网络则可以将输出经过一步的时移,再次接入到输入层当中,神经元间可以互连。此外,也可分为根据每层神经元功能,可以分为输入层、隐含层、输出层。

上图摘自网络
输入层和输出层是必须有的,中间的隐含层可以没有(单层感知机),也可以有多层(多层感知机)。直观上层数越多,则越表达的特征越多效果越好,但是就像多线程一样,并不是层数无限大效果就无限好。层数越多相应训练参数的算力开销也就越大。
从实际操作上划分,根据具体的功能,隐含层中又可以分为卷积层、池化层、激活层、线性层等。本文将介绍相关原理及Pytorch中代码应用。
卷积层
卷积是最基本常用的操作,可以看作是一种滤波器,对数据进行降维和加工。简单来说,就是相乘相加。

比如输入为4×4:
| 1 | 2 | 1 | 0 |
|---|---|---|---|
| 2 | 0 | 1 | 3 |
| 0 | 5 | 4 | 2 |
| 4 | 1 | 2 | 5 |
卷积核为3×3:
| 0 | 1 | 0 |
|---|---|---|
| 2 | 1 | 1 |
| 1 | 0 | 1 |
将卷积核与输入左上角对齐,将3×3中9个元素相乘相加:
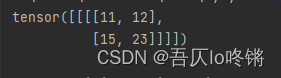
1×0+2×1+1×0+2×2+0×1+1×1+0×1+5×0+4×1=11
然后将卷积核向右移动一步(可定义移动多步),计算卷积:
2×0+1×1+0×0+0×2+1×1+3×1+5×1+4×0+2×1=12
此时向右不可移动后,移到最左端,遍历下一行,计算卷积:
2×0+0×1+1×0+0×2+5×1+4×1+4×1+1×0+2×1=15
再向右移动一步,计算卷积:
0×0+1×1+3×0+5×2+4×1+2×1+1×1+2×0+5×1=23
最后得到卷积后结果:
| 11 | 12 |
|---|---|
| 15 | 23 |
可以使用torch.nn.functional中conv2d计算二维卷积,如果有多个卷积核就会生成多层,同样的如果输入有多个,也就是多个通道channel,然后是高height和宽weight。默认移动步长是1,padding填充=0,也就是在输入外围加一圈0,变成6×6。
相关动画可参考官网:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
import torch
import torch.nn.functional as F
# 输入
input = torch.tensor([[1, 2, 1, 0],
[2, 0, 1, 3],
[0, 5, 4, 2],
[4, 1, 2, 5],
])
# 卷积核
kernel = torch.tensor([[0, 1, 0],
[2, 1, 1],
[1, 0, 1]])
# 1层1通道4高4宽
input = torch.reshape(input, (1, 1, 4, 4))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input,kernel)
print(output)
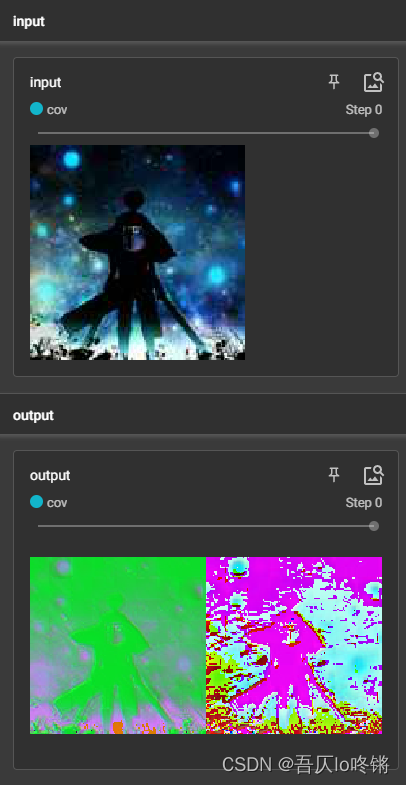
创建神经网络,包含一个简单的卷积层,对图像进行卷积:
其中可视化部分可参考另一篇博客:深度学习-Tensorboard可视化面板
import torch
from PIL import Image
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 自定义神经网络,需继承nn.Module
class MyNet(nn.Module):
# 初始化
def __init__(self) -> None:
super().__init__()
# 包含一个卷积层,输入通道3,输出通道6,卷积核3,移动步长1,不填充
self.cov = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
# 前馈
def forward(self, x):
x = self.cov(x)
return x
writer = SummaryWriter(log_dir='runs/cov') # 可视化
img_PIL = Image.open('icon.jpg') # 读取图片
trans = transforms.ToTensor()
img = trans(img_PIL) # 转为tensor
writer.add_image("input", img)
net = MyNet() # 创建网络
output = net(img) # (6,130,130)
output = torch.reshape(output, (-1, 3, 130, 130)) # (2,3,130,130)
writer.add_images("output", output)
writer.close()
output", output)
writer.close()
池化层
池化可以有效的降维,扩大感知野,实现非线性。大大降低了计算量,降低参数量,减少冗余。常用的池化包括最大池化、平均池化等。
也就是说,把卷积的相乘相加,变成了取最大值/平均值。比如输入为4×4:
| 1 | 2 | 1 | 0 |
|---|---|---|---|
| 2 | 0 | 1 | 3 |
| 0 | 5 | 4 | 2 |
| 4 | 1 | 2 | 5 |
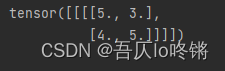
使用3×3池化核,最大池化后:
| 5 | 3 |
|---|---|
| 4 | 5 |
这里ceil_mode为True,也就是保留取整。第一个5是左上角9个元素中最大元素,然后移动步长不是1,右移到未池化的元素处,也就是{0,3,2}的最大值3,然后回到最左端向下,取{4,1,2}最大值4,最后是取{5}最大值5。若ceil_mode为Fasle(默认),则不足3×3=9个元素的地方都不考虑,池化结果就是5。
import torch
import torch.nn.functional as F
# 输入
input = torch.tensor([[1, 2, 1, 0],
[2, 0, 1, 3],
[0, 5, 4, 2],
[4, 1, 2, 5],
], dtype=torch.float)
# 1层1通道4高4宽
input = torch.reshape(input, (1, 1, 4, 4))
output = F.max_pool2d(input, kernel_size=3, ceil_mode=True)
print(output)
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
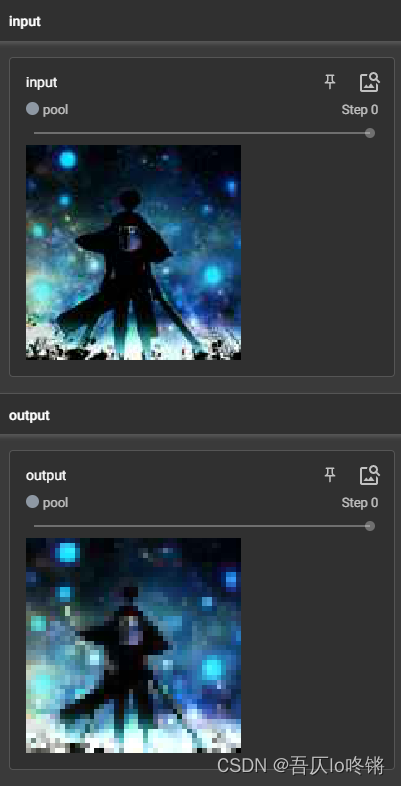
同样创建一个只含最大池化层的神经网络,对图像进行测试:
from PIL import Image
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 自定义神经网络,需继承nn.Module
class MyNet(nn.Module):
# 初始化
def __init__(self) -> None:
super().__init__()
# 包含一个最大池化层,池化核大小3×3,保留取整
self.pool = nn.MaxPool2d(kernel_size=3, ceil_mode=True)
# 前馈
def forward(self, x):
x = self.pool(x)
return x
writer = SummaryWriter(log_dir='runs/pool') # 可视化
img_PIL = Image.open('icon.jpg') # 读取图片
trans = transforms.ToTensor()
img = trans(img_PIL) # 转为tensor
writer.add_image("input", img)
net = MyNet() # 创建网络
output = net(img)
writer.add_image("output", output)
writer.close()
激活层
线性往往拟合效果差,激活函数加入非线性因素,加入线性因素可以增强拟合能力,同时避免梯度消失等情况。常用的非线性激活函数包括Relu、sigmoid、softmax、Tanh等。
| ReLu | R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x) |
|---|---|
| Sigmoid | S i g m o i d ( x ) = l o g ( 1 1 + e x p ( − x ) ) Sigmoid(x)=log(\frac{1}{1+exp(-x)}) Sigmoid(x)=log(1+exp(−x)1) |
| Softmax | S o f t m a x ( x i ) = e x p ( x i ) ∑ j x j Softmax(x_i)=\frac{exp(x_i)}{\sum_j{x_j}} Softmax(xi)=∑jxjexp(xi) |
| Tanh | T a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) Tanh(x)=\frac{exp(x)-exp(-x)}{exp(x)+exp(-x)} Tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x) |
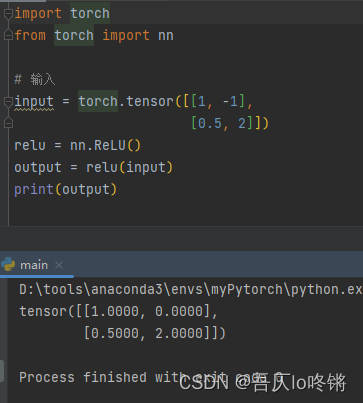
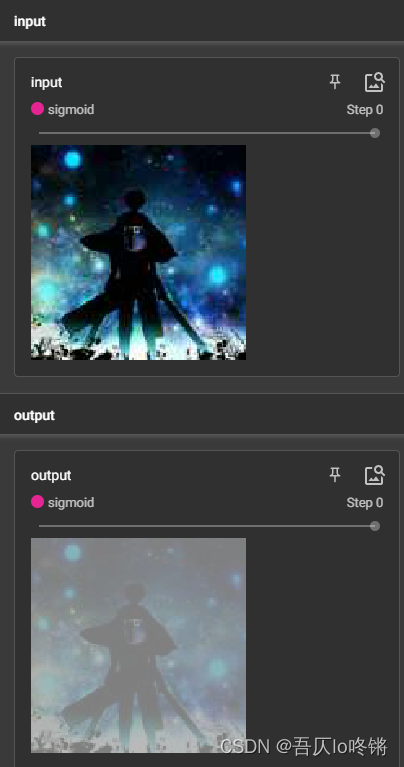
图片输入是1-255正值,ReLu后无变化,以Sigmoid测试:
from PIL import Image
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 自定义神经网络,需继承nn.Module
class MyNet(nn.Module):
# 初始化
def __init__(self) -> None:
super().__init__()
self.sigmoid = nn.Sigmoid()
# 前馈
def forward(self, x):
x = self.sigmoid(x)
return x
writer = SummaryWriter(log_dir='runs/sigmoid') # 可视化
img_PIL = Image.open('icon.jpg') # 读取图片
trans = transforms.ToTensor()
img = trans(img_PIL) # 转为tensor
writer.add_image("input", img)
net = MyNet() # 创建网络
output = net(img)
writer.add_image("output", output)
writer.close()
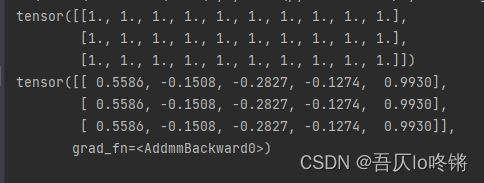
线性层
即对张量进行线性变换,就是全连接层,从输入维度转换为输出维度,可以加偏置项。
import torch
from torch import nn
linear = nn.Linear(in_features=10,out_features=5)
input = torch.ones(3, 10)
print(input)
output = linear(input)
print(output)
还有一些相对少用的层,这里不再赘述。如正则化层,采用正则化可以防止模型过于复杂(过拟合),可以加快神经网络的训练速度。衰减层,按概率随机将元素置零,防止过拟合。更多Layers可参考官方文档。
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤






![[附源码]Python计算机毕业设计宠物寄养平台设计Django(程序+LW)](https://img-blog.csdnimg.cn/f10ab18d410b4589b6a56e771a72a66c.png)






![[附源码]Node.js计算机毕业设计大数据与智能工程系教师档案管理系统Express](https://img-blog.csdnimg.cn/6ababa4ecaba44cb8f203e5b0be4567d.png)
