说明:本人使用CDH虚拟机搭建了Hbase集群,但是在压测的时发现线程多个的时候直接回OOM,记录一下
执行命令
hbase pe --nomapred --oneCon=true --table=rw_test_1 --rows=1000 --valueSize=100 --compress=SNAPPY --presplit=10 --autoFlush=true randomWrite 100
异常
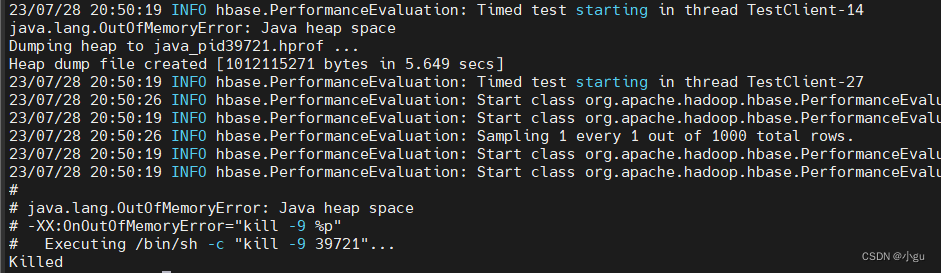
不光爆了异常,还dump 了 heap
修改参数最后面的nclients发现客户端数量比较多的时候直接内存OOM,堆内存溢出
修改堆的大小,然后重新调整,可以逐步增加线程数量。
Java Heap Size of HBase Master in Bytes


pe相关介绍
帮助命令
hbase pe
hbase pe <OPTIONS> [-D<property=value>]* <command> <nclients>
参数含义
nomapred:表示采用MapReduce多线程测试还是本地多线程测试,一般采用本地多线程的方式,在命令中加上–nomapred即可;
oneCon:是否所有线程使用一个Connection连接,默认false,表示每个线程都会创建一个HBase Connection,这样不合理,建议设置为true,命令中加–oneCon=true即可;
valueSize:写入HBase的value的size,单位Byte,默认值为1000。需要根据实际的业务字段值的大小设置valueSize,比如–valueSize=100;
table:测试表的名称,如果不设置则默认为TestTable;
rows:单个线程测试的行数,默认值为1048576,实际测试时可自行制定,比如–rows=100000。注意这是单线程的行数,实际行数要乘以线程数,比如10个线程写入时就会往HBase中写100000*10=100w条记录;
size:单个线程测试的大小,单位为GB,默认值为1,这个参数与rows是互斥的,不能同时设置;
compress:设置表的压缩算法,默认None,表示不压缩,可以根据实际情况设置比如–compress=SNAPPY。这个设置也可以用来测试不同压缩算法对读写性能的影响;
presplit:表的预分区数量即region个数,一般要参考regionserver数量,设置一个合理值以避免数据热点和影响测试结果,比如–presplit=10;
autoFlush:写入操作的autoFlush属性,默认false,这里是BufferedMutator写入方式,禁用autoFlush表示会批量写入,一般建议设置为true以获得单条写的性能测试,即–autoFlush=true;
caching:Scan读操作的caching属性,默认值为30,一般可以根据实际使用设置,比如–caching=100
command 是PE支持的读写测试类型,包括randomRead,randomWrite,SequentialRead,SequentialWrite等,具体如上。nclients 就是开启的线程数量。上面的问题就是nclients比较大导致OOM