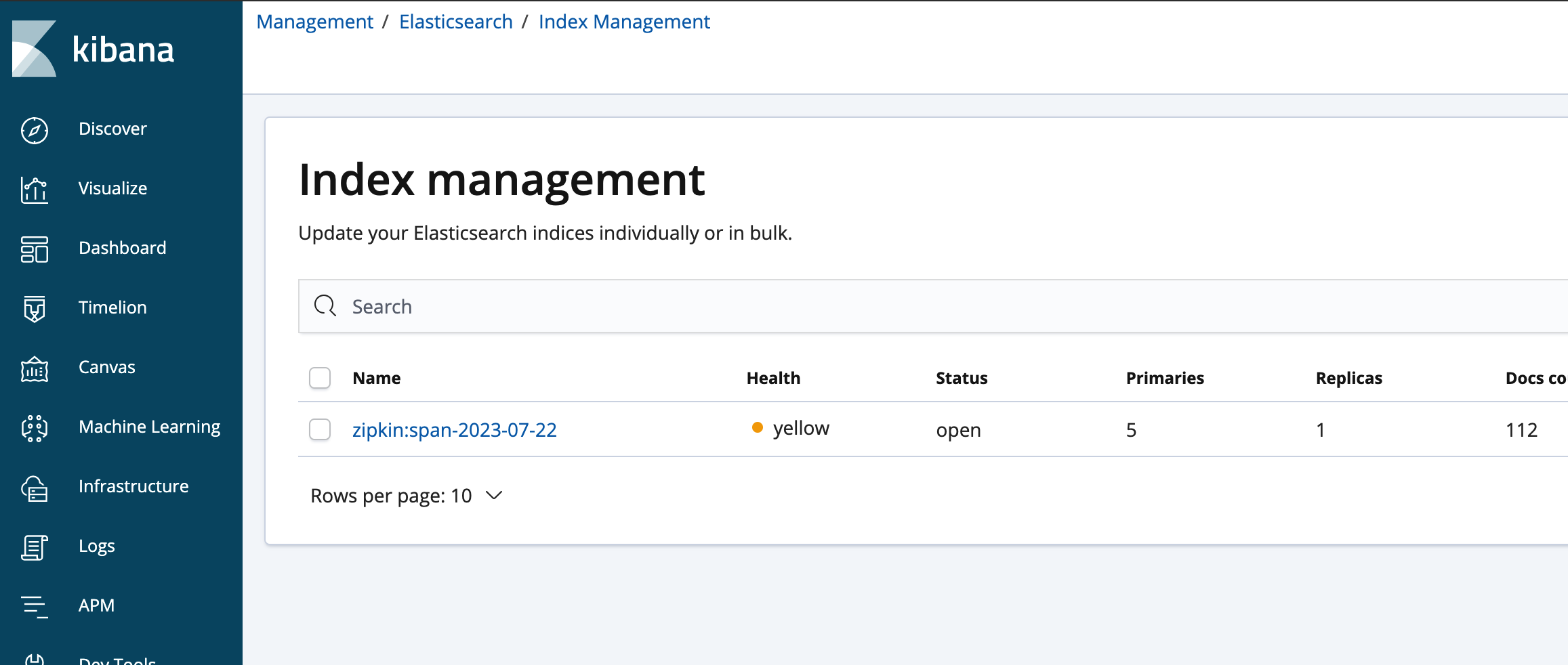
“智能算式批改系统”开发与部署优化
摘要
本次大作业搭建并实现了“智能算式批改系统”的开发与部署优化。“智能算式批改系统”是一款集yolo目标检测、paddleocr识别和四则运算判别算法的智能批改系统。该系统能够对上传包含四则运算题的页面进行批改,包括识别出算式区域并判断运算结果正误。系统的前端页面由vue3框架搭建,后端由python的flask框架搭建,同时部分功能已同步至微信小程序。系统拥有检测、识别和批改算式的功能,同时拥有一套反馈与自更新机制。该系统在经过大量的训练与优化后,其中的yolo目标检测实现了精确的算式区域坐标检测,paddleocr手写识别也准确地识别算式内容并判断结果正误。系统的总体批改效果良好,但仍拥有很大的改进空间。
-
“智能算式批改系统”简介
-
1.1 简介
小学算式题的批改是一项重复性劳动,其过程乏味且容易批改错误,因此其适合利用深度学习的方法设计一套批改系统以进行智能批改,因此“智能算式批改系统”因此而来。“智能算式批改系统”主要面向于简单四则运算的作业批改,此系统拥有算式检测、识别和批改的功能。系统拥有较为完整的可视化页面(如下图1、2所示),能运行电脑和手机上。
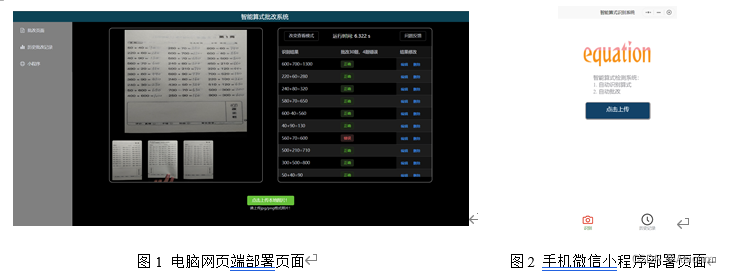
系统的原理是先利用yolo进行算式检测,然后将检测出来的算式图片片段传给paddleocr进行算式识别。得到算式内容后,使用四则运算判断算法对算式的计算结果进行判断,并最后将算式指标数据、内容数据、判断结果发送到由vue3框架搭建的前端页面中进行可视化(其原理图如下图图3所示)。除此之外,“智能批改系统”还拥有人为纠错反馈、问题反馈功能、定期模型自更新功能,对于识别模型我们还将其进行了压缩优化以提升推理速度。
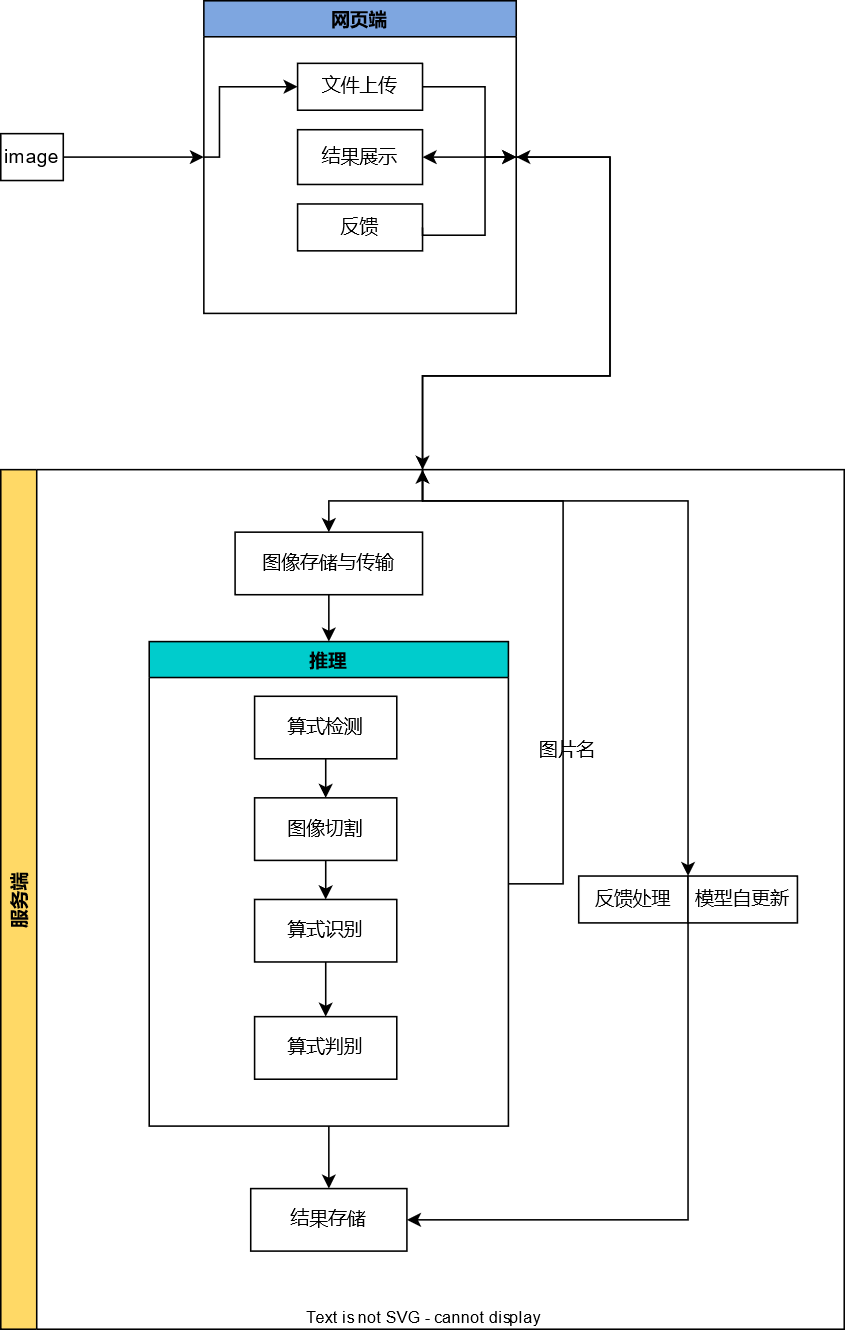
图3 “智能批改系统”整体功能图
1.2 相关工作
“智能算式批改系统”的开发工作主要分为4步,分别为数据收集与标注、模型训练、模型部署、模型优化。
对于数据收集与标注,我们先自行完成了一本小学算式习题集(手算结果并非百分百正确),然后将习题集拍照上传并利用CVAT平台对算式进行位置标注与添加算式内容至属性中。完成数据标注后,我们配合已有数据集进行了数据格式转换,并依据一定的方法进行了数据集划分。
对于模型训练,我们选取了yolo对应的模型作为算式检测模型,paddleocr中的模型作为算式识别模型。在训练过程中,yolo检测模型拥有不错的效果,但是paddleocr算式识别模型却拥有过拟合现象。
对于模型部署,我们选用vue框架配合element plus搭建了前端页面,前端页面主要负责上传图片、获取结果并统计绘图。而后端框架我们选用了python的flask轻量级框架,其主要负责接收图片、检测算式、切割图片、识别内容并返回内容给前端。同时后端还会于前端用户修改的结果同步,并记录反馈内容,同时拥有模型自更新策略。
对于模型优化,我们首先对paddle的识别模型进行了模型进行了量化的操作,使得权重结果更小更易于存储与计算。除此之外,我们还构件了模型的自更新机制,以用户上传并预测的图片作为数据集,当其数量达到某个阈值时程序会启动训练模式得到更新更符合实际的权重结果以进行替代。
-
基于CVAT的数据标注
2.1 数据标注
在进行模型训练前,需搜集合适的数据集,并对数据集进行必要的内容标注,“智能算式批改系统”使用了小学口算习题本中的习题页面作为数据集,其中人工填写答案,且答案可对可错。填写完后拍照保存。

图4 口算习题本页面示例
将保存的习题页面图片集上传至共享数据集标注网站CVAT中进行数据标注。
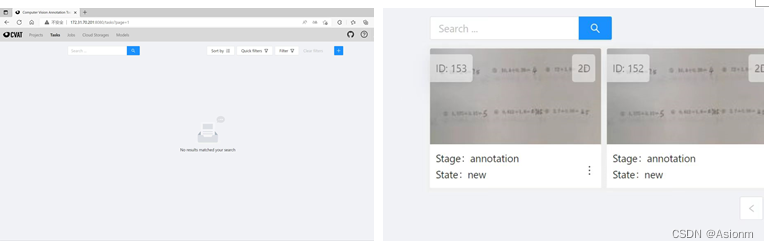
图5 将保存的图片集上传至CVAT
利用基于CVAT的标注工具进行标注,主要用矩形将算式框住,格式为“equation”,标注内容为算式与人工填写的结果,并将标注结果导出为xml格式作为训练集供后续的yolo目标检测算法训练。
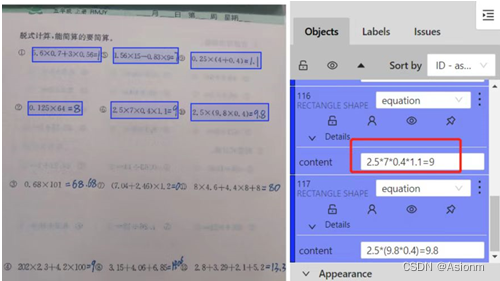
图6 数据标注示例
而对于paddleocr训练数据集来说,通常将原图片作为训练图片放入同一个文件夹,并用一个txt文件记录图片路径和标签,txt文件里的内容如下:
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 文本内容1
train_data/rec/train/word_002.jpg 文本内容2
...
且图片路径和文本标签需用“ ”隔开,否则训练时将报错.最终训练集的文件路径结构应如下所示:
|-train_data
|-rec
|- rec_gt_test.txt
|- train
|- word_001.jpg
|- word_002.jpg
|- word_003.jpg
| ...
2.2 数据集划分
此次paddleocr文本识别的数据集采用已有的四则运算习题页面图片集和人工填写的习题集结合,将习题页面切割成只包含算式部分的图块,并记录图片算式内容和图片路径,将数据集以7:3随机划分。以训练集为例如图所示:

图7 paddleocr训练集如图
-
基于yolo与paddleocr的模型设计
3.1 yolo目标检测
“智能算式批改”主要分三步走,其中第一步就是需要将算式的位置定位出来。因此在这里我们使用了yolov5对数据集进行了训练,以达到检测算式的目的。
3.1.1 训练前的配置
训练前的配置主要有三个内容,分别为数据集格式转换、数据集配置文件、网络结构配置。
- 数据集格式转换
首先对数据的格式进行处理,由于有部分的数据集是voc格式的,因此需要将此格式的数据转换为yolo格式的。对于voc格式其文件为xml类型的文件,而yolo却是txt格式的。因此格式的转换主要是将xml文件里面的坐标信息提取到txt文件中。代码见yolov5.zip里面的datasets/custom/格式转换/voc2yolo.py,代码主要参考于
【最全教程】VOC格式转YOLO格式数据_voc转yolo_蓝胖胖▸的博客-CSDN博客。转换完后的yolo格式如下所示,其中每张图片都对应于一个txt文件,txt文件中主要存储坐标值。

图8 yolo标签格式
- 数据集配置文件
在对数据集进行转换后,编辑数据集的配置文件。此文件见于yolov5.zip压缩包中的yolov5-master/data/equation.yaml,其内容主要是设置数据集的路径以及分类的类别,其内容如下图所示。

图9 数据集配置文件内容
- 网络结构配置
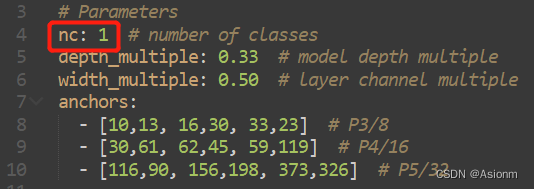
对于训练所使用的网络我们选择的是yolov5s的网络模型,对于原本的模型其输出的类别是80种,因此此处需要将80改为1。其修改的地址为yolov5.zip中的yolov5-master/models/yolov5s.yaml修改的内容如下,将nc的值变为1。
|
|
| 图10 yolo网络结构配置 |
3.1.2 模型训练
在完成训练前的配置后,接下来就是模型的训练。模型的训练一开始我们是使用自己电脑进行的,由于没有显卡所以效果比较差,而后面在腾讯云中购买了GPU服务器所以就将之前自身电脑上训练得到的权重迁移到GPU服务器中训练。
在GPU服务器中的训练首先需要将yolov5文件夹进行压缩并传输到服务器中,然后进行解压。解压过后输入指令 cd yolov5/yolov5-master进入到文件夹中,然后输入指令pip install -r requirement.txt安装相应的包,其中pytorch安装需要参考官网安装对应的gpu版本。在完成安装后,输入下面的指令进行训练,指令对train.py进行了传参数,指定了数据集的配置文件,模型的网络文件,预训练模型路径,图片的处理大小以及epochs轮数。
![]()
训练时的截图如下所示,
|
|
| 图11 yolo训练截图 |

3.1.3 训练结果
在完成到336轮次时由于再也没有提升空间所以系统推出了训练并将结果进行了保存,截图如下所示。结果文件exp18可见于yolov5.zip压缩包下的yolov5-master/runs/train/exp18。
|
|
| 图12 yolo训练完成后截图 |

将gpu服务器中的训练结果接上本地训练的10轮结果可绘制下图,
|
|
| 图13 yolo训练结果图 |
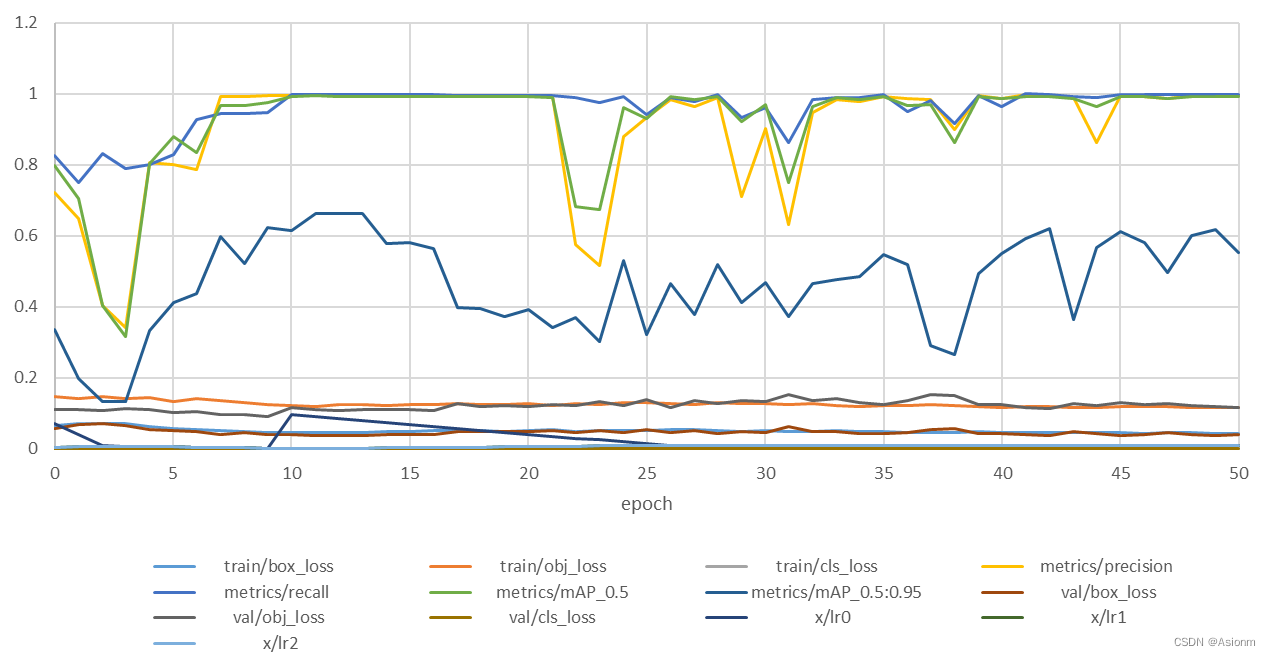
其中横轴为训练轮次,由于后面轮次结果基本一致所以此处截取了前50轮的,纵轴为各项指标的值。可以看到一开始时map50值、精确值、召回率等指标呈现一定的下降趋势但是这是短暂的,后面指标的值快速地爬升以接近于0,然后后面稳定在0.9,并在20到35轮次间发生了较大的波动然后又区域稳定。而对于损失值指标,其基本都趋于下降趋势,中间存在一些波动但是基本稳定。
从上面的图表分析可以得,yolo目标检测模型基本能很好地处理目前的数据集的检测问题,其准确率基本维持在0.9以上。
3.1.4 模型不足与改进方向
虽然此次训练的yolo模型能有效地检测出数据集内的算式,然而在后面的测试中却发现,其不能有效地处理其他与数据集样式不同的算式页面,如下图图9所示。原本的数据集中并有过多的文字出现,而新的算式页面却拥有与算式形状差不多的文字出现,因此容易出现下图的情况,这也表明此模型的泛用性并不好。除此之外,对于一些特别的环境比如背面算式写得太大力以至于有部分显示与当面,其也会识别。
|
| |
| 图14 模型识别错误图 | |

对于此种情况我们接下来的改进方向是增加不同类别不同环境下的数据集,以提高模型的泛化能力,同时也会通过数据增广的方式进步提升模型。
3.2 paddleocr算式识别
3.2.1 本地连接腾讯云GPU资源
Paddleocr的文本识别训练需要大量数据集进行训练收敛,而小组成员的笔记本只带有CPU无独立GPU,训练效率十分缓慢,效果较差,因此考虑将电脑连接腾讯云云端的GPU资源进行训练。进入腾讯云官网,选择购买合适的云服务器,选择合适的服务器配置。这里我们选择适合深度学习训练的GPU机型GN8,含56G显存6核与200G内存配置。
图15 所使用的GPU服务器
在腾讯云官网注册账号购买GPU资源后,将系统重装为Ubuntu系统方便连接编码操作。打开本地pycharm,通过连接公网IP将运行终端与腾讯云服务器中的Ubuntu终端连接,输入用户名及密码即可本地使用云端服务器GPU资源。
|
|
|
| 图16 连接腾讯云终端资源 | |
3.2.2 安装PaddlePaddle环境
本次训练使用百度飞浆成熟的paddleocr识别体系作为基础,在GitHub(链接于参考文献中)中下载paddleocr框架,并上传同步至云端Ubuntu系统中。

图17 已下载的paddleocr
在训练之前安装paddlepaddle环境与相应的依赖包:
|
|
|
| 图18 环境与依赖库安装 | |
3.2.3 启动训练
- 训练模型下载与准备
在gitee中下载paddleocr官方文字识别训练模型,这里选用的是中英文超轻量训练模型

图19 paddleocr文字识别训练模型下载
选择合适的yml文件,将训练集和验证集数据导入的路径改为之前划分好的数据集路径,调整训练轮数、batch大小以及学习率

图20 选用的yml文件
- 字典修改
因为在算式识别过程中,要识别的内容仅为数字与运算符号,因此需将原有的字典文件修改,使得识别输出的内容仅为数字和运算符等。这里需要注意除号的特殊性,应为“÷”符号
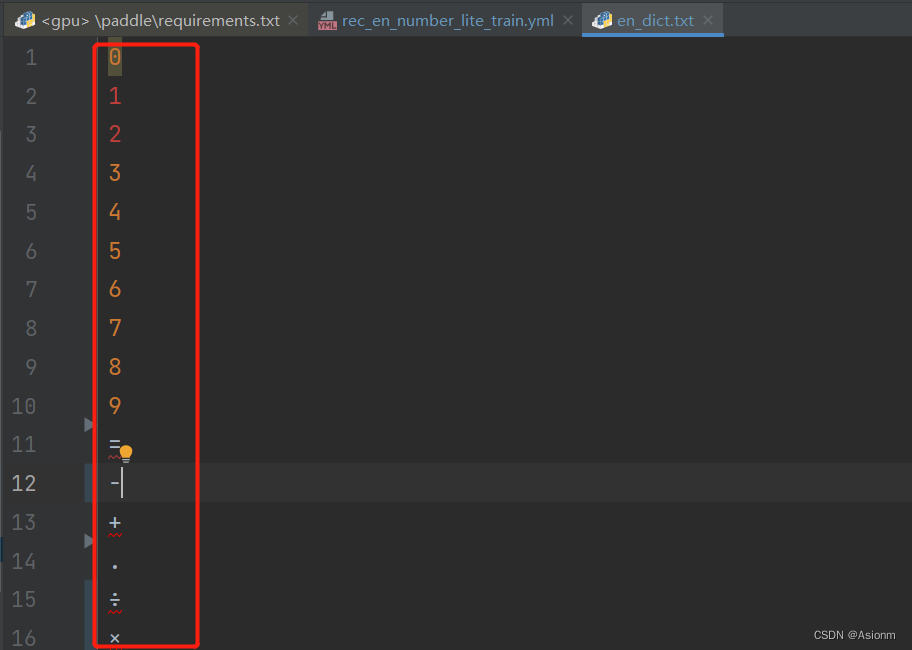
图21字典文件
- 后台训练
启动训练代码需在终端中调用选择的yml文件和train.py文件,同时指定下载好的训练模型,将训练好后的最佳权重参数文件保存
# GPU训练
# 训练icdar15英文数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
python tools/train.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
由于网络连接不稳定,容易在训练过程中出现断连导致训练失败,因此使用nohup后台训练,保证训练的稳定性和连续性。首先编写train.sh文件,将训练的命令代码输入至该文件中,后将运行权限赋予该sh文件,并将输出结果导入至nohup.out文件中,

图22 后台运行命令代码
随后,在生成的nohup.out文件中可观察到训练的实时过程和训练结果
图23 nohup.out输出内容
3.2.3 模型预测与导出
模型训练完后,需对模型进行检验并预测。随机选择一张四则运算习题图片进行检测,可见模型识别效果良好。
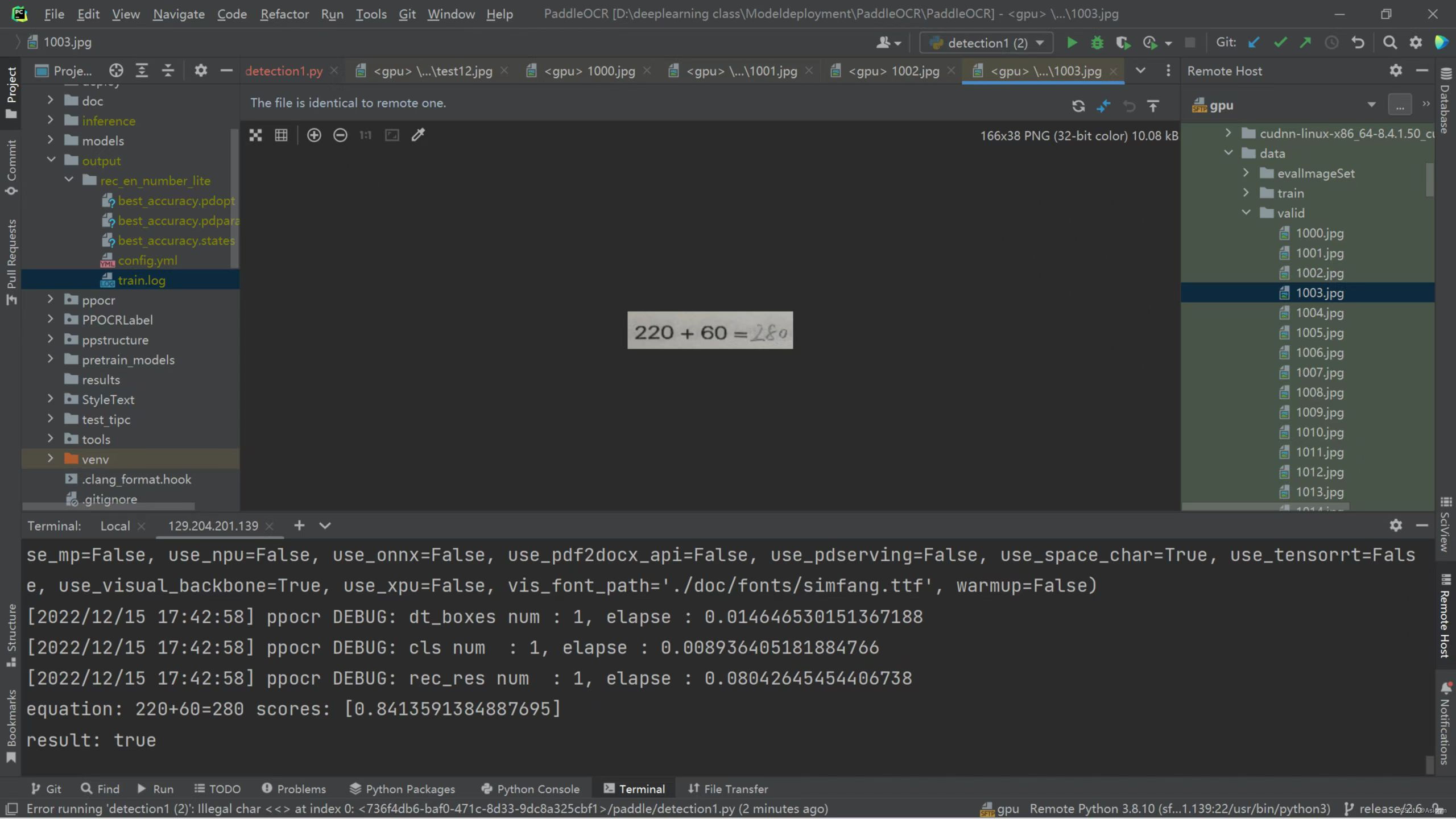
图24 训练模型检测结果
将训练好的训练模型导出成后续可用的推理模型,命令如下:
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python tools/export_model.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=output/rec_en_number_lite//best_accuracy Global.save_inference_dir=inference/equation_rec/
导出的推理模型与inference文件夹中 。
3.2.4 四则运算判别算法与识别接口
将模型导出后,为了衔接前端和yolo的目标检测,需将yolo给出的检测图块识别算式文本内容,并分析算式运算结果是否正确。部分算法代码如图所示,完整代码于paddleocr文件中的detectionq1.py文件中。其大致原理为将识别出的文本内容中分别提取数字、运算符和“=”后的结果,再根据识别的内容按照运算顺序放置并运算,比对运算结果和文本识别结果来判断对错。
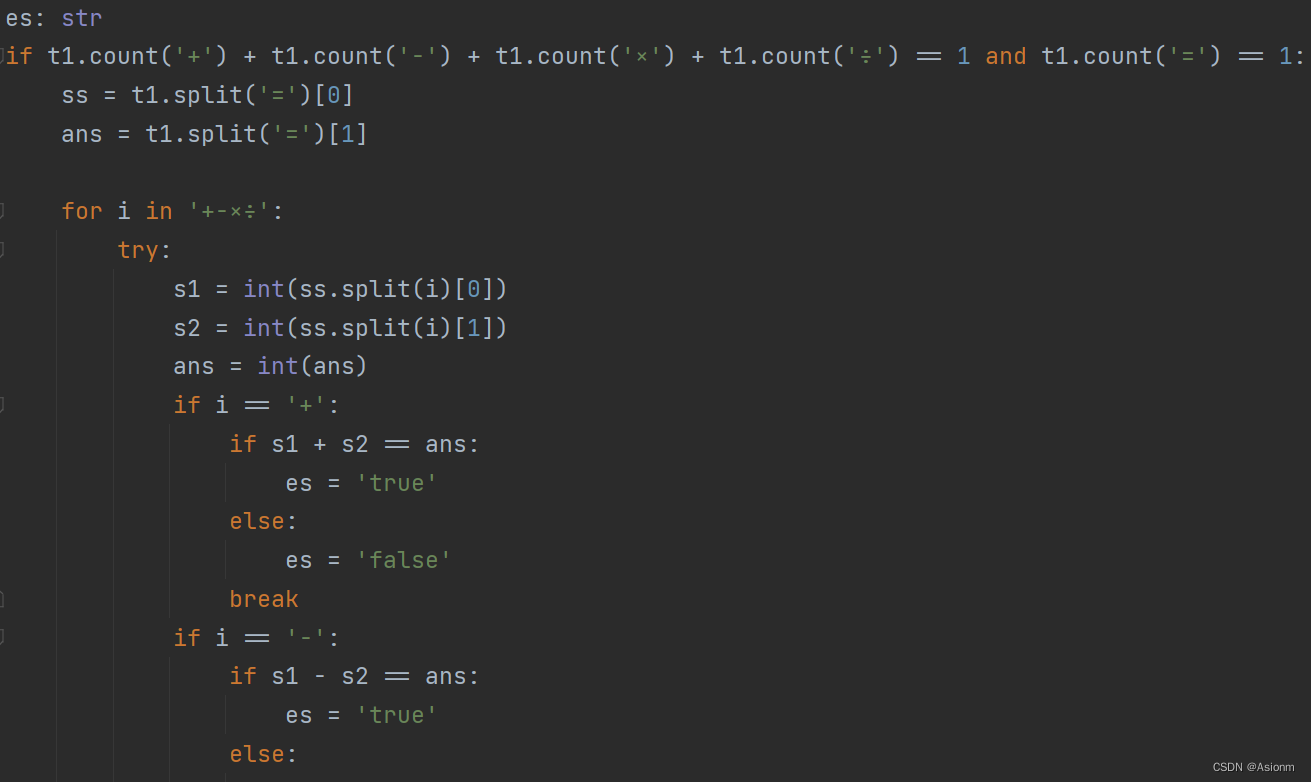
图25 四则运算结果判别算法
-
基于flask与vue以及微信小程序的模型部署
对于模型的部署,我们实现了在电脑网页端和手机端的部署。电脑网页端的页面使用了vue框架进行编写,而手机端则是使用了小程序用的是vue基础上的uniapp。无论是电脑端还是手机端,后端服务器均是依靠flask框架。下面将详细介绍部署的流程。
4.1 flask后端
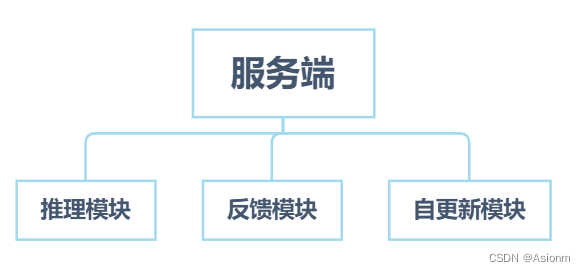
Flask后端主要起到的作用是将模型推理的结果以及性能信息整理成json格式发送到前端中,同时也起到存储信息的作用。后端主要分为推理模块、反馈模块、自更新模块。下面我将逐一介绍各模块的功能与执行流程。
|
|
| 图26 服务端组织结构图 |
- 推理模块
推理模块是服务端的核心部分,其又可细分为算式检测、算式识别、算式批改三个部分。其中算式检测是使用yolo进行的前面已详细说明。在检测出各算式后会得到其坐标值,程序会利用这些值将图像切割并逐一传输到paddleocr中进行算式识别。识别出来的算式最后会传给算式批改区进行批改,最后得到True或False的值。其中程序中图像处理的部分是通过opencv进行的。在推理运行的全过程都会有时间记录,以统计推理的性能,并将此时间信息传递给前端。
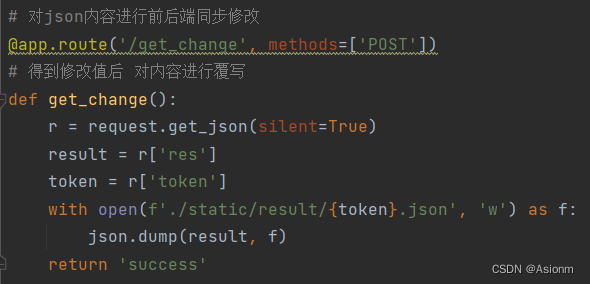
- 反馈模块
反馈模块主要起到结果编辑,功能反馈的功能。反馈模块会与前端绑定,当用户编辑一条算式或删除一条算式时前端会将编辑结果发送到后端,而后端就会依据这些结果实时更新后端的json文件,其代码内容如下图11所示。
|
|
| 图27 结果编辑后端代码 |
而功能反馈则会依据用户从前端反馈回来的内容输入到当前的反馈信息文件中,此文件会以日期命名为txt格式,其示例内容如下图12所示。
|
|
| 图28 问题反馈后台txt文档 |

- 自更新模块
自更新模块主要用于自动构建数据集进行自动更新训练。此模块我通过一个类的方法来进行构建,此类命名给update,其组织结构图如下所示。
|
|
| 图29 自更新类组织图 |

初始化模块主要用来添加保护文件名列表,构建保存文件夹。获取json数据函数是用于获取文件夹里所有的json文件夹中数据。判断已满函数是用于判断文件夹中的图片数是否已经达到可用于构建数据集的数量,如果已满则运行程序。运行程序函数是类里面的核心部分,其功能是将获取到的json文件全部写入label.txt文件内,图片进行切割,以及删除原文件。自更新模块只能用于构建训练数据集暂时未提供自动训练的接口,因为这可能需要人工审核数据集的正确性。
后端源码说明:后端源码存储于equation后端.zip压缩包中,其中server.py是主要用来运行的程序,只要输入指令python server.py即可运行服务器。Run.py是用于推理的文件。Detection.py是用于算式识别的文件,update.py是用于自更新的文件。而static文件夹主要用来存储发送过来的图片以及结果文件,feedback文件夹存储着反馈信息文件。其余文件均为嵌入yolov5和paddleocr时自带的文件。
4.2 vue前端设计
此处的前端设计指电脑的网页端页面的设计,此页面主要用于可视化显示。其能提供了图片上传,接收、显示、编辑推理结果以及问题反馈的功能。除此之外还存在一些未开发的索引页面如批改记录页面。下面将主要介绍展示和反馈功能模块。
- 结果展示
结果展示在web电脑端中有两种展示模型,一种是纯文本模式,另外一种带框的格式(如下图13、14所示)。
|
|
|
| 图30 纯文本结果显示格式 | 图31带框结果显示格式 |
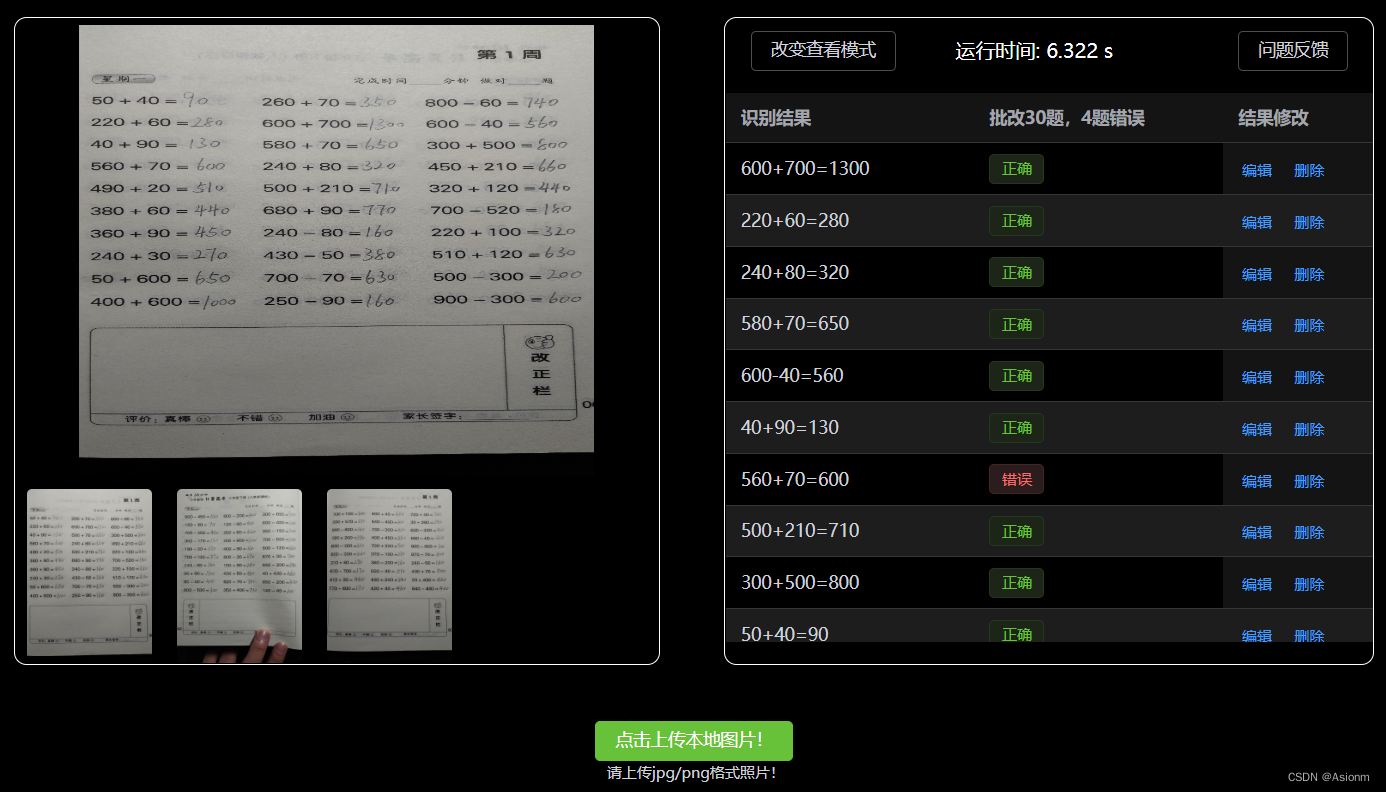
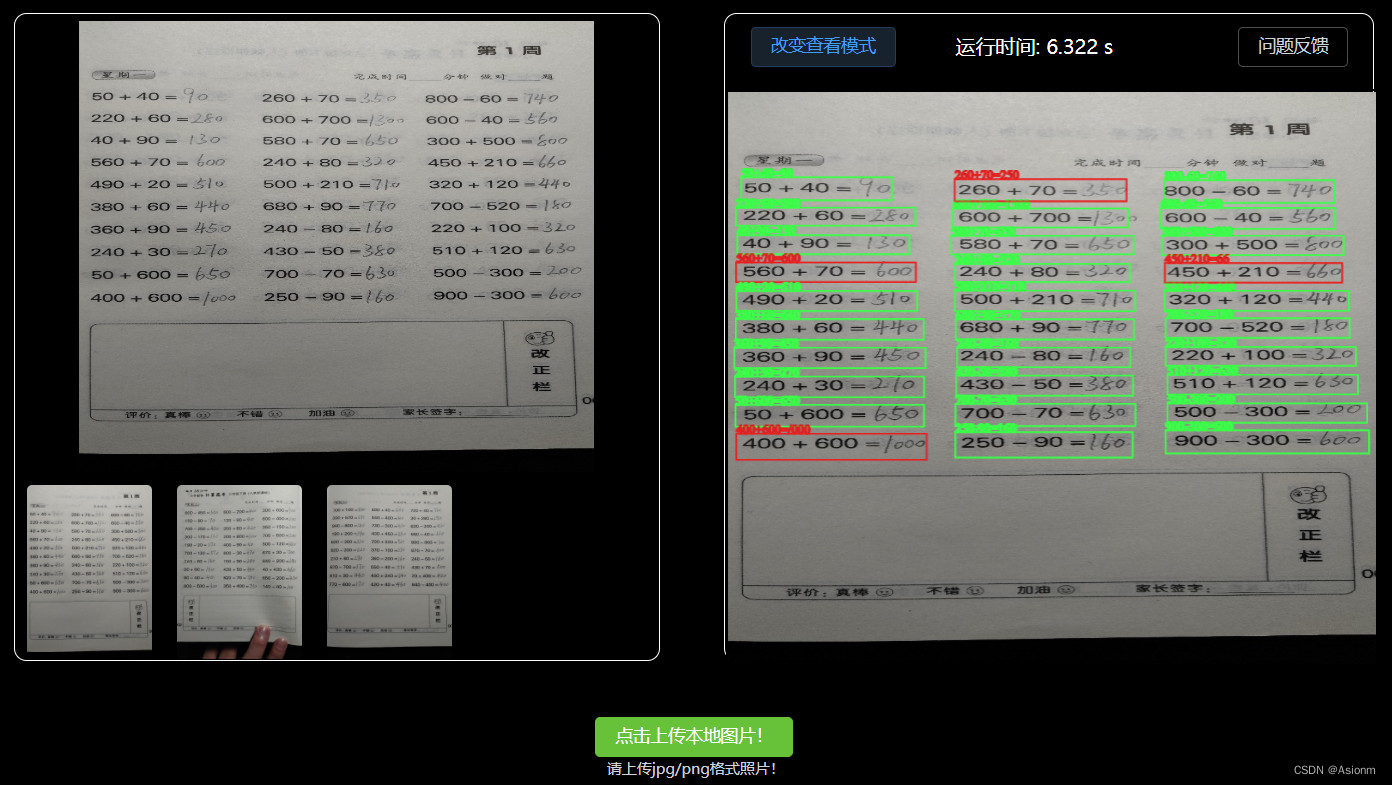
结果展示页面以及下面的功能反馈页面均集中于一个组件中进行编写,组件的名称为UpdatePart.vue中。展示区的原理是通过axios接收后端传回来包含算式坐标、内容、正确信息、运行效率的信息,然后将这些信息进行渲染统计。其中渲染的页面主要通过element plus和canvas的第三方库fabric.js进行。电脑网页端不仅仅是单张的识别,可以进行多张的切换,且一打开页面时就可以看到三张demo照片。
- 功能反馈
此处的功能反馈包括了算式编辑、删除、功能反馈这几方面,算式编辑删除的页面如下图图15所示,功能反馈如图16所示。
|
|
| 图32 算式编辑页面 |
|
|
| 图33 问题反馈页面 |
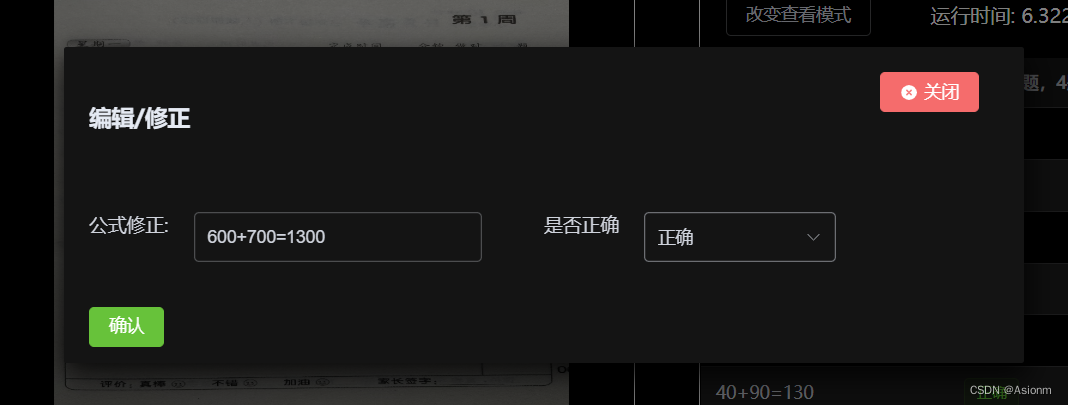
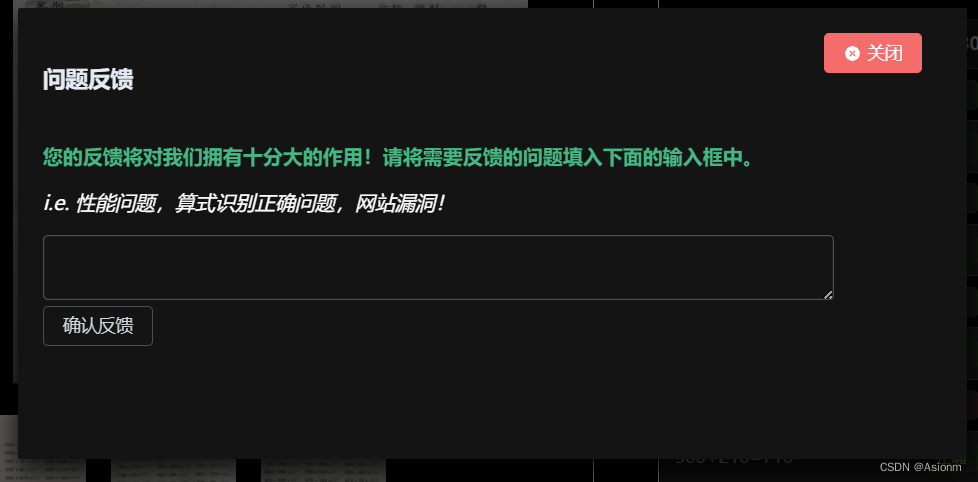
每当编辑按钮为确认时,编辑结果状态就会为True然后当切换图片或关闭页面时,前端就会将编辑的信息发送给后端以实现同步。而对于问题反馈,其原理仅仅只是个文本发送的功能。
源码文件说明:若要运行前端程序,需要先用npm i安装相应的以来包。电脑web端的代码在equation.zip处,其中主要的代码存储于src/views处,其包括了主要的几个页面,如索引页面、上传展示页面、未开发的历史页面、小程序页面。而主要的代码是通过组件的形式传到上传展示页面的,此文件位于src/components/Uploader.vue。除此之外src/api主要用于封装axios用于网络传输,src/router文件夹主要存储路由信息,src/main.js是整体的一些配置如引入全局包等等。
4.3 微信小程序设计
微信小程序使用的是uniapp,而其代码基本与电脑端的类似仅仅只是进行了一定的适应性修改。微信小程序的功能相对于电脑网页端的而言只保留了单张推理展示的功能,并未提供编辑结果、功能反馈等的功能。同时由于后端服务器只是为临时性服务器所以并未申请域名于ssl证书所以开真实使用上并不能连接到后端因此目前小程序只存在外观展示。而在开发中小程序的功能已经得以实现,具体的展示视频可见于小程序展示.mp4。具体代码可见于小程序.zip压缩包中,由于功能基本于电脑网页端的一致,因此不再展开描述。
-
模型压缩与自更新策略
5.1 模型优化讨论
对于我们模型中存在的问题,我们已在第三章模型设计中进行了论述。为了解决这些问题,我们将实现一系列的优化方法。为了应对模型的泛化能力不足的问题,我们将从添加各种环境下的数据以构成更庞大的数据集进行训练得到泛化能力更强的模型。而对于推理速度慢的问题,我们将从模型压缩方面考虑,将模型进行量化。将32位浮点数转换为8位置整型数以提升cpu的运行能力,同时也减少模型的体积减缓存储压力。下面将从上面提到的两方面进行详细论述实行。
5.2 模型自更新策略
更大的数据集用于训练,在此处我们通过模型的自更新策略进行。自更新原理已在第四章服务端中的自更新模块进行了论述,因此此处不再进行论述。对于此策略,我们主要通过大批量用户提供的经过一定修改的数据构成新的训练数据集,然后调用paddleocr的训练接口进行进一步的训练,在训练完后经过机器验证或人工验证无误后,将此权重代替旧的。因此模型的泛化能力将会得到提供,此策略主要依靠于用户的使用量,若用户多使用次数也多那么生成的数据集也越大越丰富,相应更新出来的模型泛化能力也会越强。下图为自动构建的数据集截图。主要代码可见于equation后端.zip中的update.py文件。
|
|
| 图34 自动生成数据集截图 |

5.3 paddleocr识别模型模型压缩
复杂的模型有利于提高模型的性能,但也导致模型中存在一定冗余,模型量化将全精度缩减到定点数减少这种冗余,达到减少模型计算复杂度,提高模型推理性能的目的。使用量化后的模型在移动端等部署时更具备速度优势。而 PaddleSlim 集成了模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等多种业界常用且领先的模型压缩功能。
- 安装paddleslim
使用pip 下载2.3.2版本
pip3 install paddleslim==2.3.2

图35 paddleslim安装
- 量化训练
将训练好的模型进行量化训练,量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,以PPOCRv3检测模型为例,训练指令如下:
python deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model='ch_PP-OCRv3_rec_distill_train/best_accuracy' Global.save_model_dir=./output/quant_model_distill/
- 导出模型
在得到量化训练保存的模型后,我们可以将其导出为inference_model,用于预测部署:
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_rec_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
5.4 后期优化讨论
目前的模型仍拥有很大的优化提升空间,目前模型的推理速度仍可以进一步提升。后期我们将通过知识蒸馏的方法尝试使用更小地模型尝试更进一步加快推理速度。除此之外,目前算式识别的内容仅仅只是四则运算内容,而后期若要提高其实用性,那么就不仅仅只是四则运算,还希望能够识别如微积分运算、对数运算、复合运算等更复杂的公式判别和结果判断,所以下一步我们也将引入latex格式公式以求进一步优化模型。
结论
本文中识别模型部分主要架构为yolo目标检测和paddleocr文本识别,而在训练过程中遇到了非常多的问题,包括数据集格式、训练集和数据集导入路径问题,以及在训练后检测效果差的问题。对于paddleocr,由于训练集模板数量仍不足够,且训练的时间成本高,发生了训练过拟合、检测结果出现中英文等等问题,逐个原因排查后,训练后的模型的检测效果和不同场景、不同纸张与不同字迹的识别准确度仍有很大的进步空间,初步分析为有选用的paddleocr中的训练模型CRNN网络结构仍有待针对性的调整、数据集的选用、数据预处理的合理性以及是否考虑数据增广等等因素。整体智能批改习题的核心识别部分有待进一步的改进和完善。