文章目录
- 一、深度学习步骤回顾
- 二、常规指导
- 三、训练过程中Loss很大
- 3.1 原因1:模型过于简单
- 3.2 原因2:优化得不好
- 3.3 原因1 or 原因2 ?
- 四、训练过程Loss小。测试过程Loss大
- 4.1 原因1:过拟合 Overfitting
- 4.2 原因2:Mismatch
- 五、N折交叉验证
- 六、When gradient is small ...
- 6.1 Batch
- 6.2 Momentum
- 七、Adaptive Learning Rate
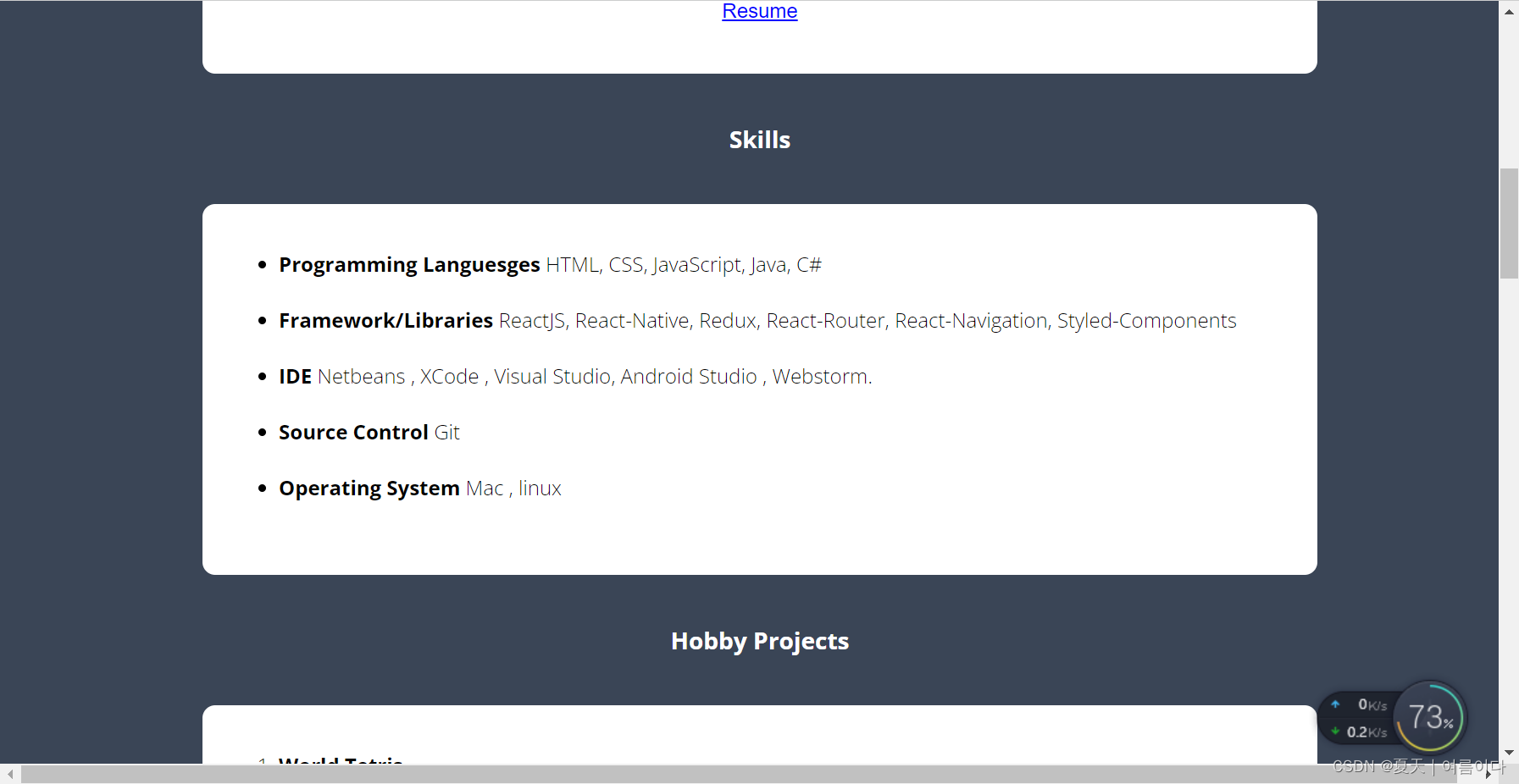
一、深度学习步骤回顾
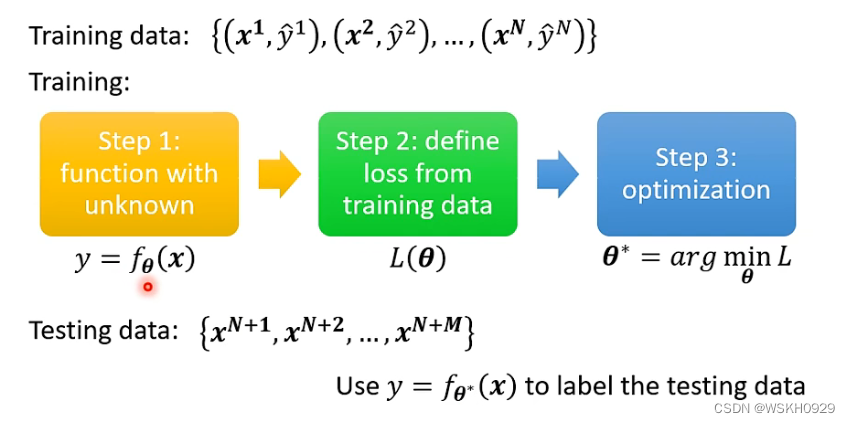
二、常规指导
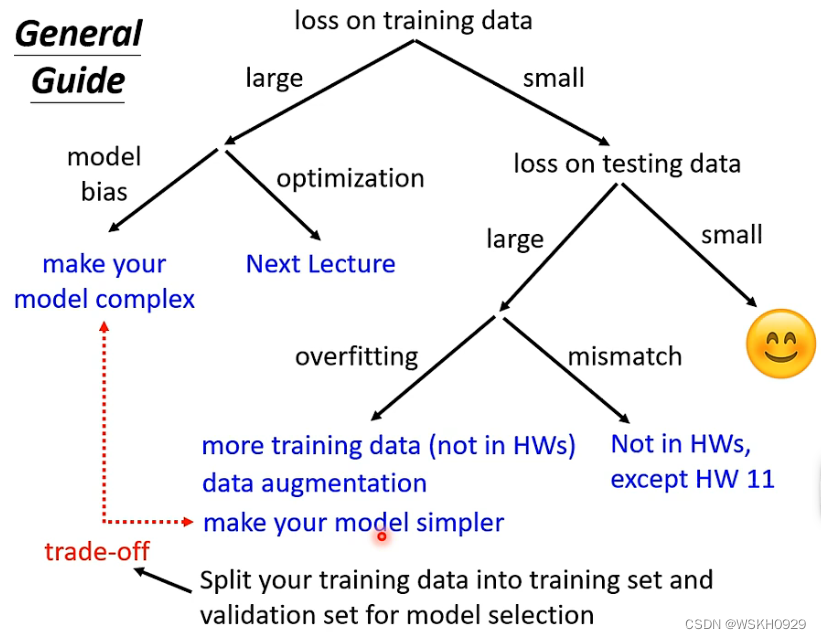
三、训练过程中Loss很大
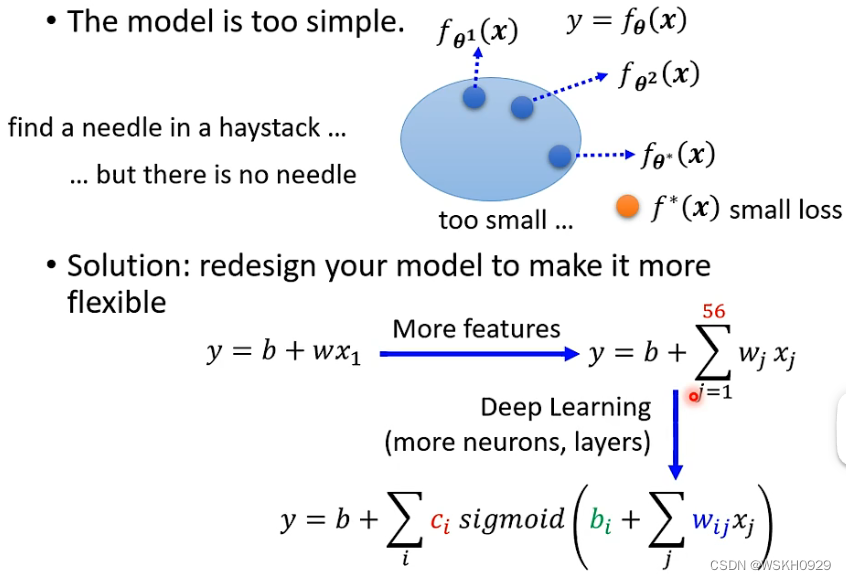
3.1 原因1:模型过于简单
原因分析
如果你的设计的模型(函数表达式)过于简单,可能会拟合不出复杂的函数,导致预测误差较高
解决方案
解决方法也很简单,就是增加模型的复杂度。如上一节课(【深度学习】李宏毅2021/2022春深度学习课程笔记 - Deep Learning Introduction)所讲的,我们可以将原本简单的线性表达式转化为复杂的非线性表达式,这样就可以拟合出更多复杂的函数,从而为减小误差提供可能。
3.2 原因2:优化得不好
原因分析
以当前模型确实存在一组参数使得Loss较低,但是由于优化算法的效果不好,没办法找到可以使得Loss较低的参数
解决方案
更换效果更好的优化算法
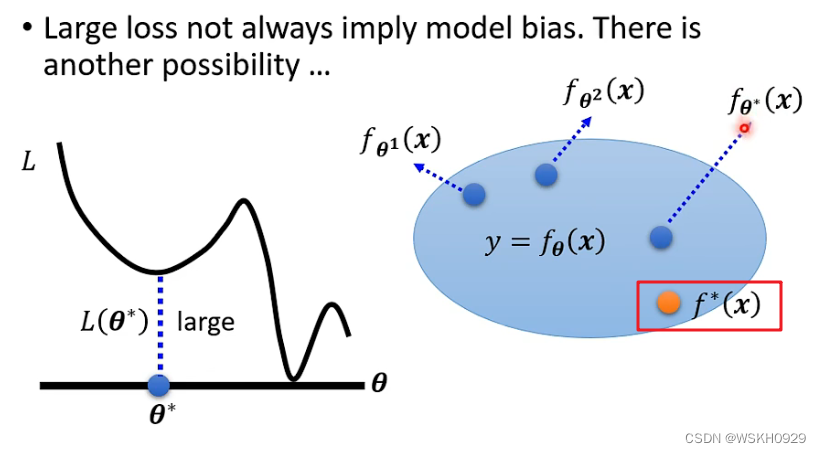
3.3 原因1 or 原因2 ?
这一节会讲述,我们应该怎么判断到底是原因1导致的训练过程Loss过高,还是原因2导致的
尝试不同的模型,对比不同模型下,训练过程的Loss。如下图所示,56层的模型的Loss反而比20层的模型还要大,说明应该是原因2导致的训练过程Loss过高

四、训练过程Loss小。测试过程Loss大
4.1 原因1:过拟合 Overfitting
原因分析
在大部分情况下,训练数据只是数据全集的一小部分,甚至有可能存在部分噪声数据,所以如果模型对训练数据学习得过于深入,有可能学到噪声,导致模型的泛化性变差
解决方案
- 使用更多的训练数据(当然更多,也要是正确的训练数据多才行噢),减少噪声的影响,增加训练数据的全面性,让模型可以更好地拟合真实函数

其他解决方案
- 使用更少参数的模型
- 使用更少的特征数量
- 提早停止 Early Stopping
- 正则化
- Dropout
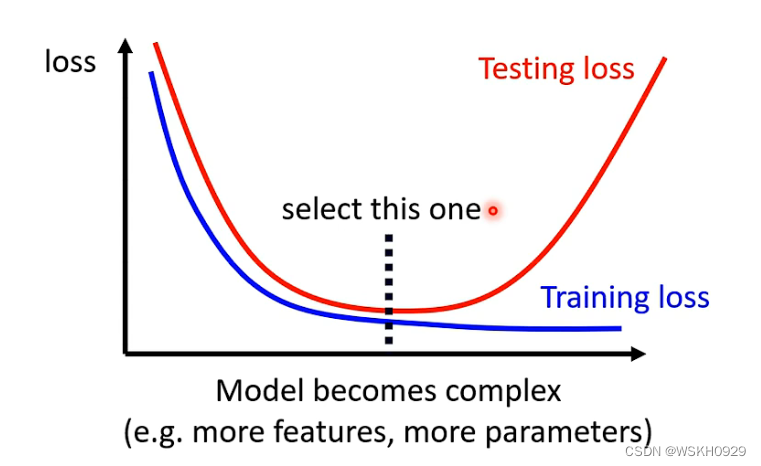
4.2 原因2:Mismatch
还是看上一节课讲的案例,2/26是星期五,按照以往的规律,星期五一般学习Deep Learning的人数都是比较少的,所以模型也认为2/26日播放量应该比较少,然而事实是,2/26反而是播放量最多的一天。
这是一种反常的现象,称之为 mismatch。即机器遇到了反常的现象,即测试数据体现出的规律和训练资料体现出的规律有很大不同
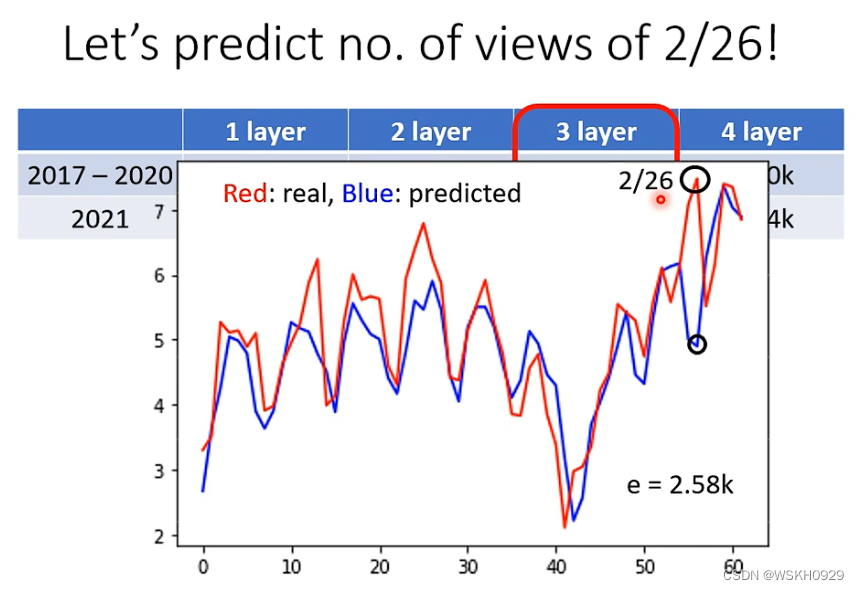
下面例子,体现了Mismatch的产生原因,训练数据和测试数据体现的规律有很大不同

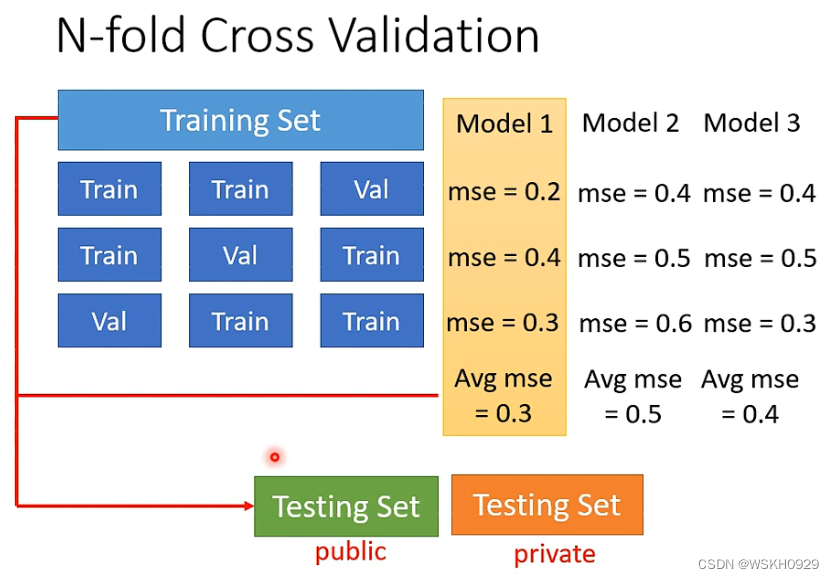
五、N折交叉验证
为了判断当前模型是否出现过拟合现象,我们需要从原始训练数据中,分出一部分作为验证集,然后选出在验证集上Loss最小的模型作为最终模型
六、When gradient is small …
下面只讨论,当Optimization失败时,怎么把梯度下降做得更好
人们对于Optimization失败时,有如下图所示的猜想,认为模型被优化到了一个使得梯度非常接近0的点,导致优化无法继续。这一类点通常是局部最小值点或者鞍点。
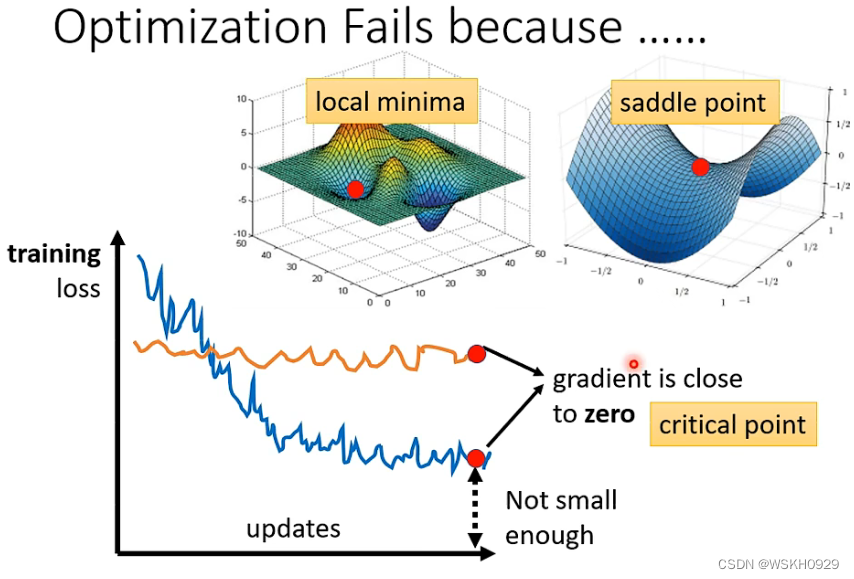
那么,如果卡在局部最小值或者鞍点时,应该怎么办呢?下面会介绍解决这个问题的办法。
6.1 Batch
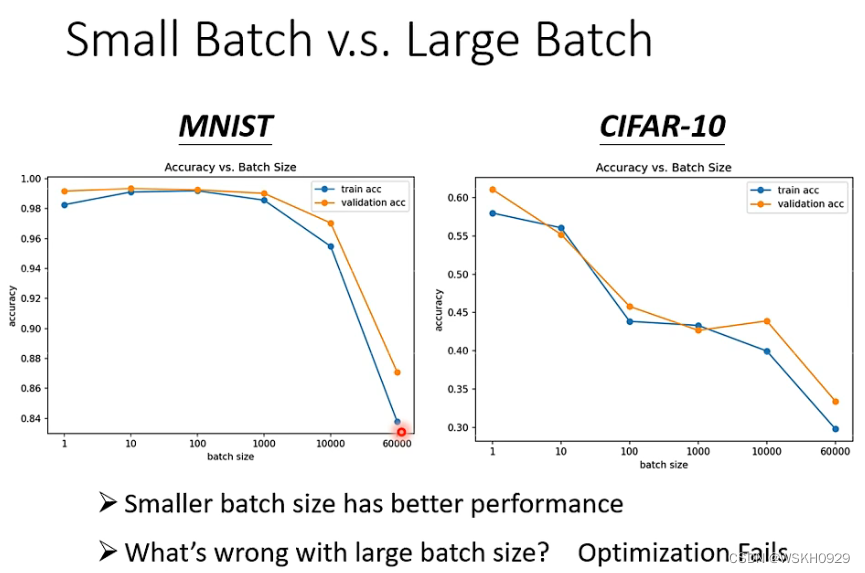
Batch 指的是每次更新参数时,只用训练数据中的一小批数据进行参数更新

如下图所示,一般来说,较小的 Batch Size 可能会得到更好的结果
6.2 Momentum
在介绍 Momentum 之前,先来回顾一下,传统的梯度下降是怎么更新参数的。如下图所示,每到一个点,就按照梯度的反方向更新参数

接下来看看,加上 Momentum 之后的参数更新是什么样的。如下图所示,所谓 Momentum 就是考虑了上一步移动的方向,相当于给参数的更新加上了惯性,让参数的更新不止是根据梯度,还要根据上一步移动的方向进行更新参数,这样有利于跳出局部最优点和鞍点

七、Adaptive Learning Rate
下图展示了固定学习率的缺点。如果学习率太大,会导致最终模型可能在最优解附近来回震荡,但始终无法收敛至最优点。如果学习率太小,又会导致模型需要迭代很多次,收敛速度很慢
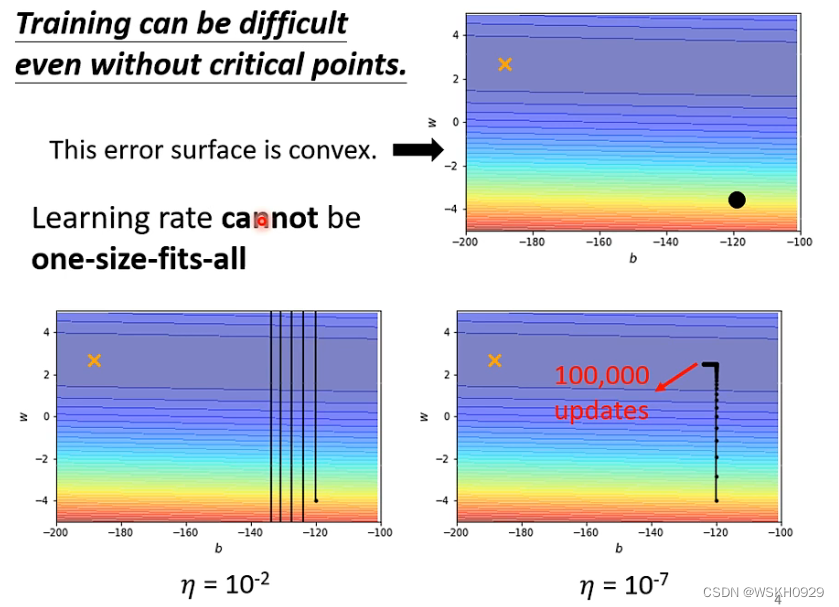
针对上面提到的,采用固定学习率带来的缺点,我们认为,可以给不同的参数设置不同的参数更新权重,且这个权重是随着迭代进行自适应变化的,进而提高模型迭代的效率与质量
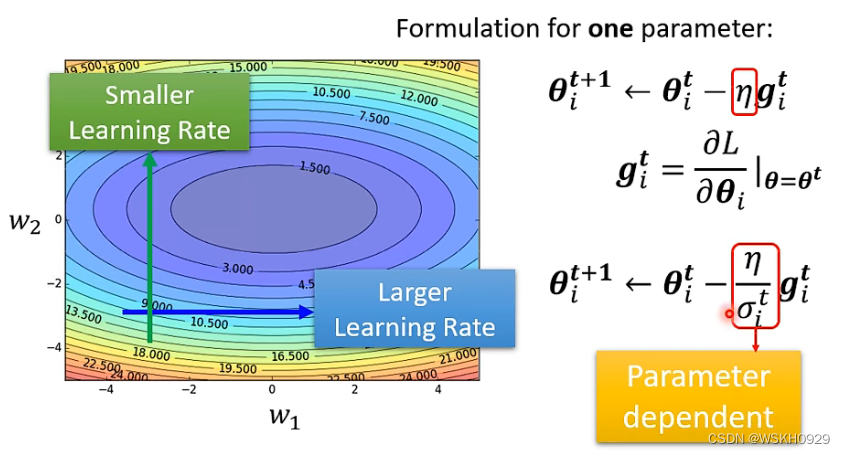
下面给出了 Learing rate 的更新方法,参数更新权重是根据历史梯度计算的

以上,还不是关于学习率优化的最终版本。我们还希望,对于同一个参数的学习率,它对于不同时期的历史梯度信息的权重应该是不一样的,于是就有了 RMSProp , 它用 α 来控制当前梯度和历史梯度的权重

综上所述,就有了很强的优化器, Adam !

让我们来看看用了自适应学习率之后的寻优路线,如下图所示。我们可以看到,在接近最优点的时候,在竖直方向上发生了较大幅度的震荡,这是由于自适应学习率是考虑了历史上所有梯度的,而最开始时竖直方向的梯度较大,所以导致其会发生竖直震荡
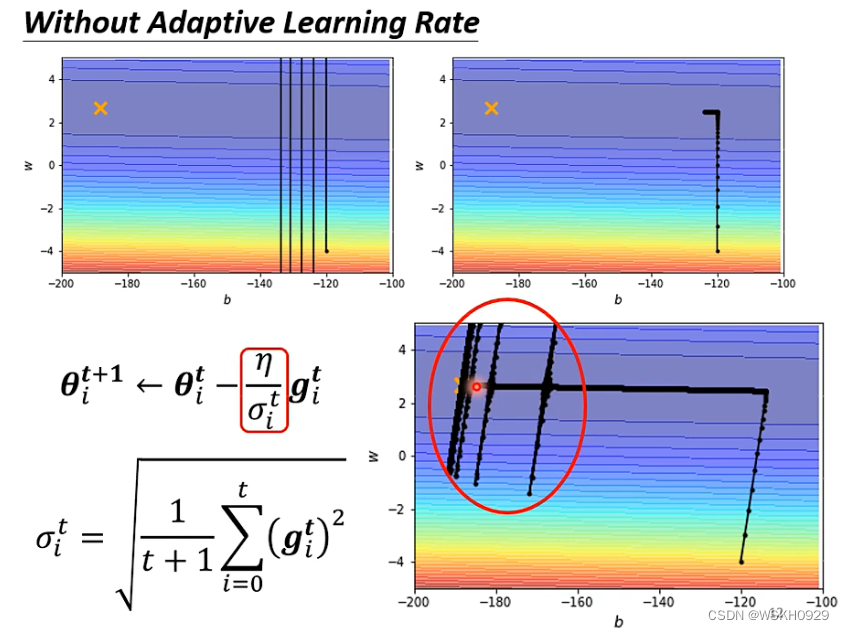
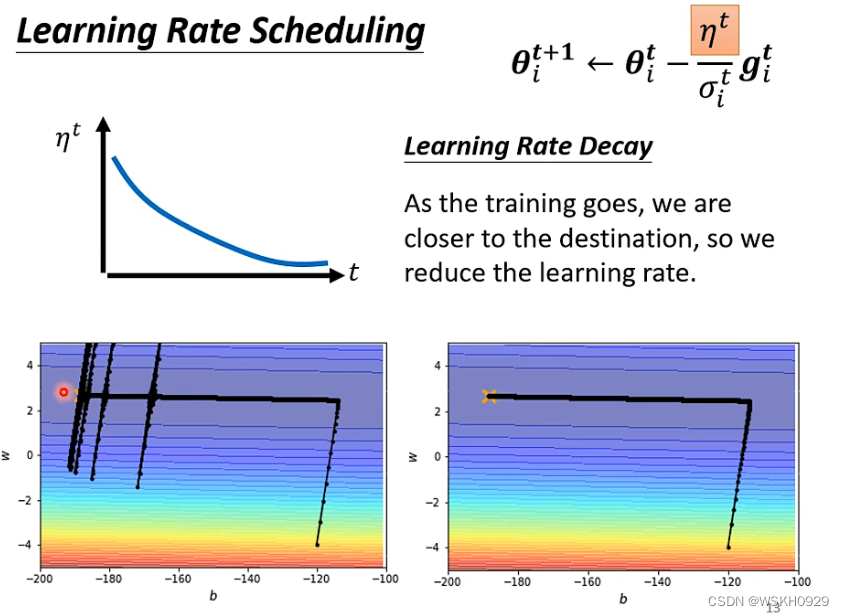
为了解决上面的震荡问题,我们可以采用 根据迭代次数而自适应变化的学习率,称之为 Learning Rate Scheduling
下面采用了 学习率随迭代次数递减的策略,可以看到,震荡现象就消失了
除了学习率递减策略,还有一个常用策略是 Warm Up 策略 , 学习率先逐渐上升,然后到一个阈值后,再逐渐下降到一个阈值











![[附源码]Python计算机毕业设计Djangoospringboot作业管理系统](https://img-blog.csdnimg.cn/8a78827d55934b51a1678112870d5095.png)