目录
四、 Spring Data Redis
五、 Spring Data ElasticSearch
四、 Spring Data Redis
Redis 是一个基于内存的数据结构存储系统,它可以用作数据库或者缓存。它支持多种 类型的数据结构,这些数据结构类型分别为 String(字符串)、List(列表)、Set(集合)、 Hash(散列)和 Zset(有序集合)。
Spring Data Redis 通过一段简单的配置即可让 JAVA 程序访问 redis 服务,它的底层 是对 redis 开发包(如 Jedis、JedisPool)的高度封装。
1 Spring Data Redis 项目搭建
1. 安装 redis
2. 安装 RedisDesktopManager
3. 创建 SpringBoot 项目,创建时加入 Spring Data Redis 起步依赖。
4. 写配置文件
spring:
redis:
# Redis 服务器主机。
host: localhost
# Redis 服务器端口。
port: 6379
jedis:
pool:
# 连接池在给定时间可以分配的最大连接数。
max-active: 8
# 连接池中空闲连接的最大数量。
max-idle: 8
# 连接池中空闲连接的最小数量。
min-idle: 05. 测试
// 注:对象名必须叫 redisTemplate,否则由于容器中有多个 RedisTemplate 类型对象造成无法注入
@Autowired
private RedisTemplate redisTemplate;
@Test
public void t1() {
//获取操作 string 数据的工具
ValueOperations operations = redisTemplate.opsForValue();
operations.set("name","tong"); // 存
Object name = operations.get("name"); // 取
System.out.println(name);
}
2 序列化器
在入门案例中,我们看到 Spring Data Redis 存入 Redis 的是一串二进制数据,这是因为 Spring Data Redis 在保存数据的时候,底层有一个序列化器在工作,它会将要保存的数据(键和值)按照一定的规则进行序列化操作后再进行存储。spring-data-redis 提供如 下几种序列化器:
JdkSerializationRedisSerializer: 默认,序列化为二进制数据
StringRedisSerializer: 简单的序列化为字符串
GenericToStringSerializer: 可以将任何对象序列化为字符串
Jackson2JsonRedisSerializer: 序列化对象为 json 字符串
GenericJackson2JsonRedisSerializer:功能同上,但是更容易反序列化
OxmSerializer: 序列化对象为 xml
如果想改变使用的序列化器,可以通过 redisTemplate 对象设置。
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());3 Spring Data Redis 操作 string
在 Redis 中有五种常见类型,Spring Data Redis 对每一种数据类型都提供了一 个 xxxOperations的工具类,分别是:
ValueOperations:用来操作 string 类型数据
HashOperations: 用来操作 hash 类型数据
ListOperations:用来操作 list 类型数据
SetOperations:用来操作 set 类型数
ZSetOperations:用来操作 zset
RedisTemplate 常用方法:
delete(K key):删除键值对
delete(Collection keys):批量删除
ValueOperations 的常用方法:
void set(K key, V value):设置键值对
void set(K key, V value, long timeout, TimeUnit unit):设置有时效的键值对
void multiSet(Map map):批量设置键值对
V get(Object key):获取值
List multiGet(Collection keys):批量获取值
Long size(K key):获取值的长度
Long increment(K key):数字类型值自增
Long increment(K key, long delta):数字类型值自增设定值
Long decrement(K key):数字类型值自减
Long decrement(K key, long delta):数字类型值自减设定值
4 Spring Data Redis 操作 hash
HashOperations 的常用方法:
put(H key, HK hashKey, HV value):新增 hash
HV get(H key, Object hashKey):获取 hash 的值
Boolean hasKey(H key, Object hashKey):判断 hash 是否有该键
Set keys(H key):获取 hash 的所有键
List values(H key):获取 hash 的所有值
Map entries(H key):获取 hash 的所有键值对
Long delete(H key, Object... hashKeys):根据 hash 的键删除 hash 的值
5 Spring Data Redis 操作 list
Long leftPush(K key, V value):左侧加入元素
Long leftPushAll(K key, V... values):左侧加入多个元素
Long rightPush(K key, V value):右侧加入元素
Long rightPushAll(K key, V... values):右侧加入多个元素
V index(K key, long index) 根据索引进行查询:
0 开始代表从左开始:0 1 2...
-1 开始代表从右开始:-1 -2 -3...
List range(K key, long start, long end):根据索引范围查询
V leftPop(K key):从左删除一个元素
V rightPop(K key):从右删除一个元素
6 Spring Data Redis 操作 set
Long add(K key, V... values):添加元素
Set members(K key):查看所有元素
V randomMember(K key):随机获取一个元素
Long remove(K key, Object... values):删除多个元素
Set intersect(K key, K otherKey):两个 set 取交集
Set union(K key, K otherKey):两个 set 取并集
7 Spring Data Redis 操作 zse
Boolean add(K key, V value, double score):添加元素
Double incrementScore(K key, V value, double delta):为元素增减分数
Double score(K key, Object o):查询一个元素的分数
Long rank(K key, Object o):查询一个元素在集合中的排名,从 0 开始
Set range(K key, long start, long end):根据排名区间来获取元素列表
Set> rangeWithScores(K key, long start, long end):根据 排名区间来获取元素列表,包括分数
Set rangeByScore(K key, double min, double max):根据分数区间来获取 元素列表
Set> rangeByScoreWithScores(K key, double min, double max):根据分数区间来获取元素列表,包括分数
Long zCard(K key):统计集合大小
Long count(K key, double min, double max):统计分数区间的元素数量
Long remove(K key, Object... values):根据 key 删除元素
Long removeRange(K key, long start, long end):根据排名区间删除元素
Long removeRangeByScore(K key, double min, double max):根据分数区间删除元素
8 使用 Repository 操作 Redis
一般我们更多的时候使用 Template 方式操作 Redis,因为 Redis 并不像关系型数据库 存入的大部分是对象,操作 Redis 也不一定和对象相关。所以使用 Repository 操作 Redis 的方式我们了解即可。
创建实体类:
// 表示将对象存入 key 为 student 的 hash 中
@RedisHash("student")
public class Student {
// hash 的键存的是 id 字段
@Id
private String id;
private String name;
private Integer age;
// 省略 getter/setter、构造方法、toString 方法
}
创建 Repository 接口:
public interface StudentRepository extends CrudRepository<Student, String> {}测试:
@Autowired
private StudentRepository studentRepository;
@Test
public void t1() {
Student student = new Student("1001", "懒羊羊", 10);
studentRepository.save(student);
}五、 Spring Data ElasticSearch
1 概念
Elasticsearch 是一个实时的分布式搜索和分析引擎。它底层封装了 Lucene 框架,可以提供分布式全文检索服务。
Spring Data ElasticSearch 是 SpringData 技术对 ElasticSearch 原生 API 封装之后的 产物,它通过对原生 API 的封装,使得程序员可以简单的对 ElasticSearch 进行各种操作。
2 Elasticsearch 回顾
2.1 核心概念
索引(index):索引是一个拥有几分相似特征的文档的集合,类似于关系型数据 库中的库的概念。
类型(type):类型是索引中的一个逻辑上的分类/分区,类似于关系型数据库中的数据表的概念。
文档(document):文档是一个可被索引的基础信息单元,类似于关系型数据库中的记录的概念。
域(Fied):document 由多个域组成,不同类型的 document 里面同名的 field一定具有相同的类型,类似于关系型数据库中的字段的概念。
ElasticSearch 跟关系型数据库中概念的对比:
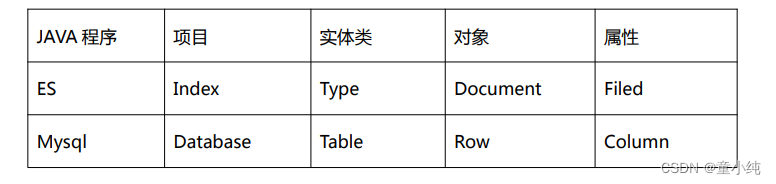
注:ES7.X 之后删除了 type 的概念,一个索引不会代表一个库,而是代表一张表。我们课程中使用 ES7,所以此时概念对比为:

2.2 安装 ElasticSearch
2.2.1 安装 ES 服务
1. 解压 elasticsearch 压缩文件
2. 解压 elasticsearch-analysis-ik,将解压后的文件夹拷贝到 elasticsearch 的 plugins 目录下
3. 修改 es 服务器 config 目录下的 yml 文件,加入以下配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4. 启动 bin/elasticsearch.bat
5. 访问 http://127.0.0.1:9200
2.2.2 安装 ES 图形化管理软件 kibana
ES 需要一个图形化管理软件方便我们操作,此处我们安装 kibana。
1. 解压 kibana 压缩文件
2. 启动 bin/kibana.bat
3. 访问 http://127.0.0.1:5601
2.3 使用 Restful 风格的 http 请求方式操作 ES
创建索引
路径:localhost:9200/索引
提交方式:put
请求体:
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":
{
"properties":{
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"ik_smart
},
"content":{
"type":"text",
"store":true,
"index":true,
"analyzer":"ik_max_word"
}
}
}
}创建/修改文档
路径:localhost:9200/索引/_doc/[文档id]
提交方式:POST
请求体:
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。"
}删除文档
路径:localhost:9200/索引/_doc/文档 id
提交方式:DELETE查询文档
路径:localhost:9200/索引/_search
提交方式:POST
请求体:
{
"query": {
"查询类型": {
"查询属性": "查询条件值"
}
}
}
查询类型:match_all、term、range、fuzzy等使用 SQL 查询文档
在 ES7.X 版本后,ES支持原生 SQL 查询文档
路径:localhost:9200/_sql?format=txt
提交方式:POST
请求体:
{
"query": "SELECT * FROM travel where id = 1"
}2.4 使用 JAVA 原生代码操作 ES
使用 JAVA 原生代码操作 ES 代码非常繁琐,我们了解一下即可。
这是一段创建索引的代码:
CreateIndexRequest request = new CreateIndexRequest(indexName);
request.settings(Settings.builder()
.put("index.number_of_shards", 3)
.put("index.number_of_replicas", 2)
);
// 创建索引结构,es7 及以后去掉了映射类型
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject()
.startObject("properties")
.startObject("name")
.field("type", "text")
.field("analyzer", "ik_smart")
.endObject()
.startObject("age")
.field("type", "integer")
.endObject()
.startObject("desc")
.field("type", "text")
.field("analyzer", "ik_smart")
.endObject()
.startObject("id")
.field("type", "integer")
.endObject()
.endObject()
.endObject();
request.mapping(builder);
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
// 指示是否所有节点都已确认请求
boolean acknowledged = response.isAcknowledged();
// 指示是否在超时之前为索引中的每个分片启动了必需的分片副本数
boolean shardsAcknowledged = response.isShardsAcknowledged();
if (acknowledged || shardsAcknowledged) {
log.info("创建索引成功!索引名称为{}", indexName);
return true;
}
return false;由于使用 JAVA 原生代码操作 ES 代码非常繁琐,我们在开发中更多使用 Spring Data ElasticSearch 框架操作 ES,下面我们就学习使用 Spring Data ElasticSearch。
3 Spring Data ElasticSearch 项目搭建
1. 创建 SpringBoot 项目,创建时加入 Spring Data Redis 起步依赖。
2. 写配置文件
spring:
elasticsearch:
rest:
uris: http://localhost:92003. 创建实体类
@Document(indexName = "travel")
public class Product {
@Id
@Field(type = FieldType.Integer,store = true)
private Integer id;
@Field(type = FieldType.text,store = true,analyzer = "ik_max_word")
private String productName;
@Field(type = FieldType.text,store = true,analyzer = "ik_max_word")
private String productDesc;
}@Document:标记在类上,标记实体类为文档对象,一般有以下属性,如下:
indexName:对应索引库的名称
shards:分片数量
replicas:副本数量
createIndex:是否自动创建索引 @Id:标记在成员变量上,标记一个字段作为主键 @Field:标记在成员变量上,标记为文档中的字段,并指定字段映射属性:
type:字段类型
index:是否索引,默认是 true
store:是否存储,默认是 false
analyzer:分词器名称
searchAnalyzer:搜索时的分词器名称
4. 创建 ProductRepository 接口继承 ElasticsearchRepository
5. 在测试类注入