1 摘要
问题:无监督域适应传统方法将超过一定置信度阈值的数据视为目标域的伪标记数据,因此选择合适的阈值会影响目标性能。
在本文中,提出了一种新的基于置信度的加权方案来获得伪标签,并提出了一种自适应阈值调整策略,以在整个训练过程中提供足够和准确的伪标签。 准确地说,基于置信度的加权方案根据置信度生成伪标签具有不同的贡献,这使得性能对阈值不太敏感。 此外,所提出的自适应阈值调整方法根据网络对目标域的适应程度来选择阈值,从而避免了对适当阈值的穷举搜索的需要。
2 介绍
背景
伪标记[21] 是对未标记数据进行人工标记,将无监督学习转化为半监督学习的过程。 本文遵循的前提,即具有高置信度输出的样本可以用作准确的标签 [22]、[23]。 具体来说,置信度超过某个阈值的未标记样本被视为真实标签,称之为伪标签。 伪标记技术的性能在很大程度上依赖于阈值,其中选择合适的阈值对于实现高性能至关重要。 高阈值会导致更准确的伪标签,从而获得高性能,但也会导致标签不足。 另一方面,低阈值会导致大量伪标签,但也会因伪标签不准确而导致性能不佳。 因此,找到合适的阈值以实现高性能是伪标记中的一个主要问题。
此外,传统方法不是在整个训练过程中固定阈值,而是随着训练的进行不断增加阈值 [18]-[20]。 随着训练的进行,网络会适应目标域,这意味着与训练的早期阶段相比,将生成更多具有高置信度的伪标签。 当训练进行到一定程度时,即使阈值很高,网络也能够提供足够的伪标签。 因此,网络专注于通过在整个训练过程中增加阈值来生成准确的伪标签。然而,上述关于阈值选择的方法具有局限性。
首先,性能对阈值极其敏感,阈值的微小差异会产生巨大的负面影响。 进行详尽搜索以找到正确的阈值,这很耗时并且需要针对不同的数据集单独完成。其次,先前的工作根据源域训练的进度或网络的准确性调整阈值。尽管伪标签是从目标域样本生成的,但阈值对目标域没有依赖性。
为了克服传统方法的上述局限性,我们提出了一种基于置信度的加权方案来构建伪标签和一种自适应阈值调整方法。 我们基于置信度的加权方案限制了高阈值和低阈值的缺点。 我们为具有高置信度的伪标签赋予高权重,为低置信度赋予低权重。 因此,性能对阈值变得不那么敏感,从而避免了对适当阈值进行详尽搜索的需要。 此外,所提出的自适应阈值调整方法根据网络对目标域的适应程度来选择阈值。 阈值变得依赖于目标域,奖励目标域以在整个训练过程中生成足够和准确的伪标签。 通过所提出的方法,网络能够以自适应方式调整阈值,而无需穷举搜索。
3 方法
整体框架:
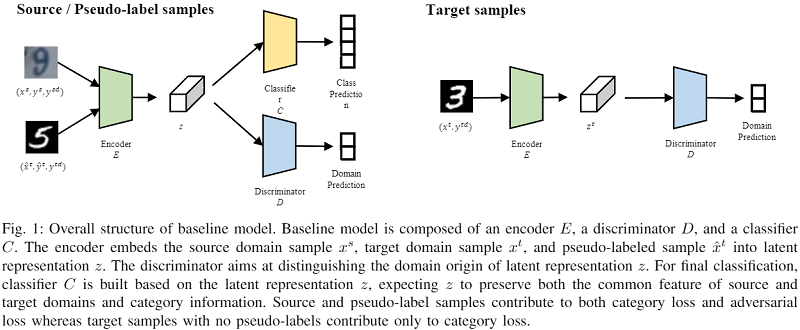
判别器的目标函数:
LD=minWD(∑xs∈XsH(D(zs),ysd)+∑xt∈XtH(D(zt),ytd))(1)LD=minWD(∑xs∈XsH(D(zs),ysd)+∑xt∈XtH(D(zt),ytd))(1)
其中,ysdysd 和 ytdytd 是二分类域标签;
编码器的目标函数:
LG=minWE(∑xt∈XtH(D(zt),ysd))(2)LG=minWE(∑xt∈XtH(D(zt),ysd))(2)
编码器 EE 和分类器 CC 的目标函数:
LC=minWE,WC(∑xs∈XsH(C(zs),ys)+∑x^t∈X^tH(C(z^t),y^t))(3)LC=minWE,WC(∑xs∈XsH(C(zs),ys)+∑x^t∈X^tH(C(z^t),y^t))(3)
4.1 基于置信度的加权方案
当通过类别损失训练分类器时,先前的工作 [18]-[20] 对每个伪标记样本的类别损失给出了相同的贡献,即使样本的置信度不同。 在高度置信度伪标签大多正确的前提下[22],[23],具有不同置信度的伪标签对类别损失的贡献应该不同。 具有高置信度的伪标签意味着匹配真实标签的概率很高,这应该对类别损失有很大贡献。 相反,低置信度的伪标签有被错误标记的风险,这意味着应该对类别损失给予低贡献以抑制风险。 因此,我们建议赋予伪标签与其置信度成正比的权重。
本文将完全置信的伪标签(置信度为 1.0 的标签)设置为 1.0 的权重,而根据经验将置信度为阈值的伪标签设置为与完全置信的伪标签相比具有一半的贡献。 也就是说,为伪标签分配权重为 0.5 的阈值置信度。 本文将伪标签的权重设置为与伪标签的置信度成线性比例:
w(xt)=0.51−thconf(xt)+0.5−th1−th(4)w(xt)=0.51−thconf(xt)+0.5−th1−th(4)
其中 conf(xt)conf(xt) 表示从分类器导出的目标样本 xtxt 的置信度,thth 表示阈值。
考虑到伪标签的置信度,我们可以通过应用 Eq.4Eq.4 来修改等式 Eq.3Eq.3 以重新制定新的类别损失:
LC=minWE,WC(∑xs∈XsH(C(zs),ys)+∑x^t∈X^tw(x^t)H(C(z^t),y^t)⎞⎠⎟(5)LC=minWE,WC(∑xs∈XsH(C(zs),ys)+∑x^t∈X^tw(x^t)H(C(z^t),y^t))(5)
通过伪标签的基于置信度的加权方案,我们能够减少低阈值和高阈值的缺点。 由低阈值生成的不准确的伪标签被赋予较小的权重,因此分类器受到的不准确性影响较小。 高阈值经历了伪标签的不足,由低阈值提供的伪标签补偿。 结果,网络的性能不会因伪标签的不准确和不足而显着下降,这意味着性能对阈值变得不那么敏感。
4.2 自适应阈值调整
为了关注训练早期伪标签的缺乏和后期伪标签的准确性,许多研究根据训练的进展增加阈值[19],[20]。 训练的进度由当前纪元或网络在源域样本上的准确性决定。 然而,这些术语不依赖于目标域,因此不能完全反映训练的进度。 因此,我们提出自适应阈值调整策略,根据模型对目标域的适应程度来设置阈值。 对目标域适应性低的模型不能对目标样本进行分类,这会导致输出置信度低,而适应性好的模型则输出置信度高。 因此,我们将模型对目标域的适应程度视为目标样本的平均置信度输出。 基于模型对目标域的置信度的修改阈值表示为:
th=max(∑xt∈Xtconf(xt)nt,α)(6)th=max(∑xt∈Xtconf(xt)nt,α)(6)
其中 ntnt 表示目标样本的数量,α=0.7α=0.7 表示最小阈值。 确定一个最小阈值,以防止在训练初期模型对目标域没有适应性时阈值过低。 太低的阈值会产生许多不准确的伪标签,这会阻止网络学习目标区分表示。 通过所提出的方法,网络可以自适应地选择合适的阈值,以在整个训练过程中保持伪标签的充分性和准确性。 结果,模型可以对各种数据集和模型容量具有鲁棒性。
4.3 总体目标函数
总体目标函数可以表示为
L=minWE,WD,WC(LE+LD+βLC)(7)L=minWE,WD,WC(LE+LD+βLC)(7)
其中 β 是平衡参数。 编码器和鉴别器以对抗方式进行优化,将源样本和目标样本映射到公共域表示中。 编码器和分类器使用源和伪标记样本进行优化,以实现高分类性能。 详细的优化过程如算法 1 所示。
算法总结:

5 实验
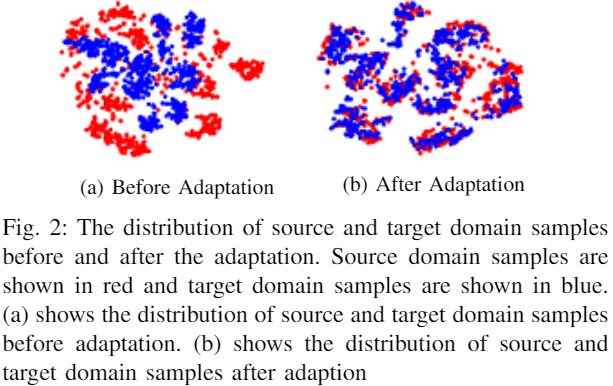
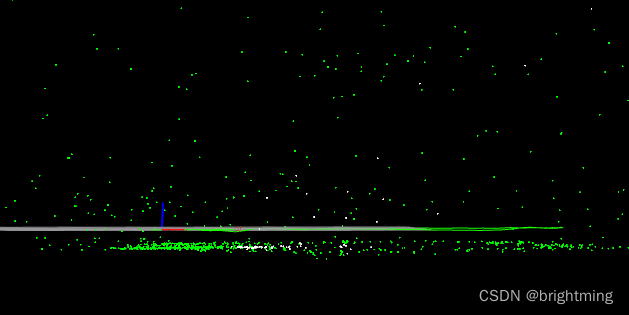
可视化: