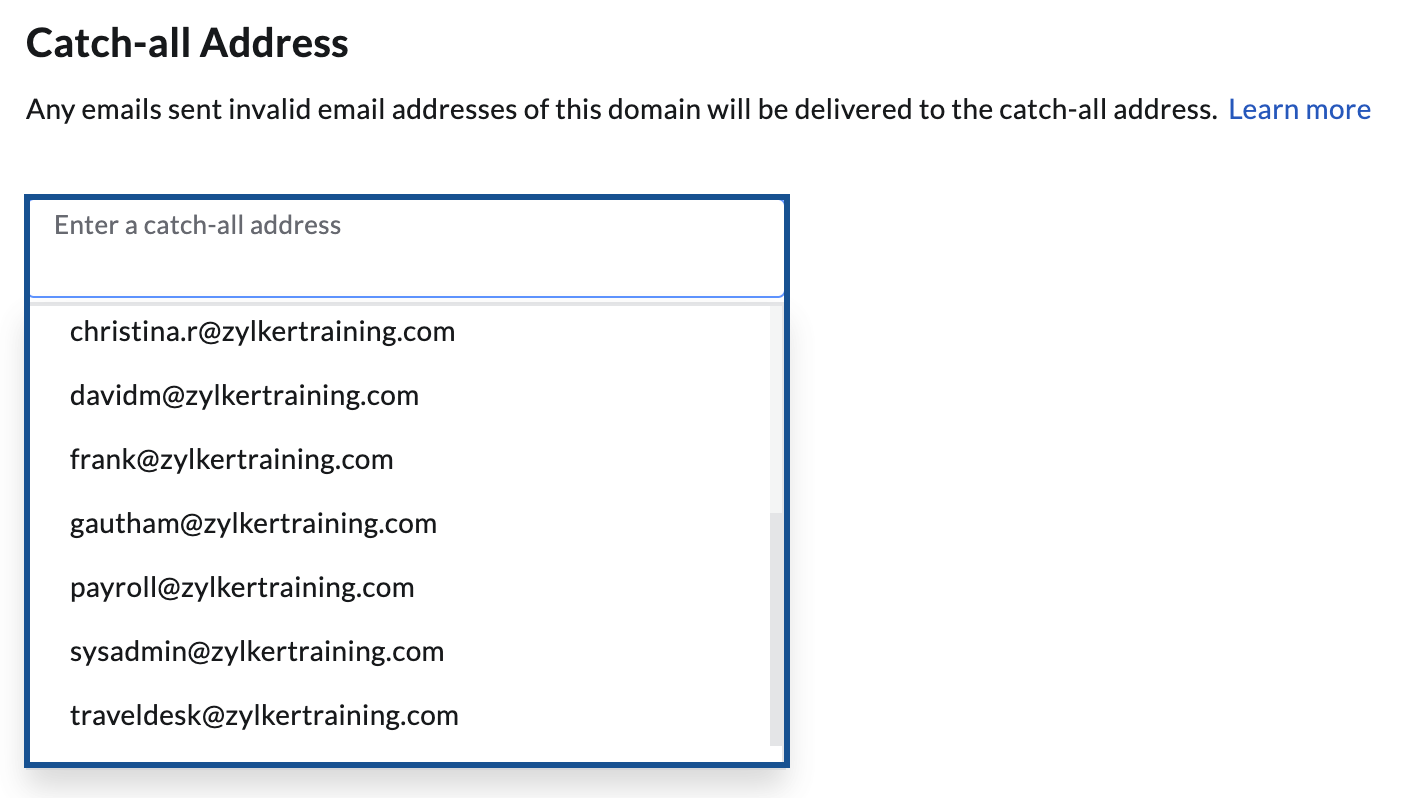
Self2Self With Dropout: Learning Self-Supervised Denoising From Single Image

- 文章地址:https://ieeexplore.ieee.org/document/9157420
- 原始代码:https://github.com/scut-mingqinchen/self2self
- 本文参考代码: https://github.com/JinYize/self2self_pytorch
- 本文参考博客: https://zhuanlan.zhihu.com/p/361472663
- website:https://csyhquan.github.io/
文章目录
- Self2Self With Dropout: Learning Self-Supervised Denoising From Single Image
- 1. 原理简介
- 2. 网络结构
- 3. Pytorch实现
- (1)Partial convolution 结构
- (2) U-net 网络结构
- (3)网络训练
- (4)迭代结果
- 总结
1. 原理简介
噪声图片 y 可以表示为 干净图片 x 和噪声 n的叠加
y
=
x
+
n
y = x + n
y=x+n
使用单个输入进行预测 的原理是:
F
θ
(
.
)
:
y
→
x
F_{\theta}(.) \; : \; y \rightarrow x
Fθ(.):y→x
常规监督神经网络训练
m
i
n
θ
∑
i
L
(
F
θ
(
x
(
i
)
)
,
y
(
i
)
)
\underset{\theta}{min} \sum_i L(F_{\theta}(x^{(i)}),y^{(i)})
θmini∑L(Fθ(x(i)),y(i))
其中
F
θ
F_{\theta}
Fθ是神经网络,
θ
\theta
θ是网络参数;但是就从一个神经网络训练的过程来看
M
S
E
=
b
i
a
s
2
+
v
a
r
i
a
n
c
e
MSE = bias ^2 + variance
MSE=bias2+variance
当训练数据减少的时候,variance会极剧增加。blind-spot技术可以用来阻止这种过拟合现象,但单个样本训练带来的大的variance是无法解决的。这也是基于blind-spot的神经网络 N2V和N2S在单个图片上效果不好的原因。
Dropout技术是一种广泛应用的正则化技术,同时其可以提供一定程度的不确定性估计,避免出现恒等映射。盲点策略通过对噪声数据随机采样合成多个不同的噪声数据版本,并在这些替换样本上计算损失。因此本文提出的一个策略就变为了:在输入图像的伯努利采样实例上定义自预测损失函数
y
^
[
k
]
=
{
y
[
k
]
,
w
i
t
h
p
r
o
b
a
b
i
l
i
t
y
p
;
0
,
w
i
t
h
p
r
o
b
a
b
i
l
i
t
y
1
−
p
\hat{y}[k] = \begin{cases} y[k] &,with \; probability \; p; \\ 0 &,with \; probability \; 1-p \end{cases}
y^[k]={y[k]0,withprobabilityp;,withprobability1−p
采样两个 Bernoulli 采样实例数据集 y ^ m {\hat{y}_m} y^m和 y n ^ \hat{y_n} yn^
-
训练过程,最小化下面这个损失
m i n θ ∑ m L ( F θ ( y ^ m ) , y − y ^ m ) \underset{\theta}{min} \sum_m L(F_{\theta}(\hat{y}_m),y-\hat{y}_m) θminm∑L(Fθ(y^m),y−y^m) -
测试过程:在另一个采样数据集上, 得到每一个 y n y_n yn对应的预测结果,然后求一个平均值得到最后的去噪数据
2. 网络结构
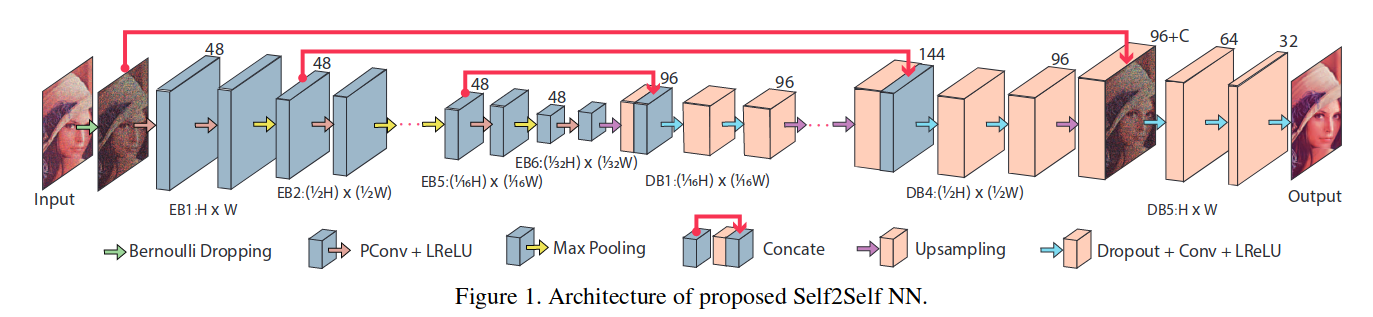
-
Encoder结构
- 输入大小 H × W × C H \times W \times C H×W×C
- 使用 partial convolution layer(Pconv)将输入变为 H × W × 48 H \times W \times 48 H×W×48
- 然后使用六个 encoder block(EBs):
- 前五个包含 Pconv层,1个 Leakey ReLu激活函数,一个最大池化层(2*2感受野、stride为2)
- 最后一层只有 Pconv层和 一个 Leakey ReLU激活函数
- 通道固定为48
- 编码器的输出为 H / 32 × W / 32 × 48 H/32 \times W/32 \times 48 H/32×W/32×48
-
Decoder 结构:
- 包含五个decoder blocks
- 前四个blcok每一个包含一个上采样参数为2的上采样层,一个concate操作,两个标准的Conv层和 Leakey Relu激活。concate操作是将上采样得到的结果进行了聚集。
- 前四个block都有96个输出通道
- 最后一个decoder block有三个dropout层,使用LeakeyReLU激活函数。最后将输出恢复为 H × W × C H \times W \times C H×W×C的大小
- 包含五个decoder blocks
部分细节:
- 所有的PConv层和Conv层都使用kernel size 3*3,strid = 1,padding = 2
- Leakdy ReLU的斜率为 0.1
- droupouts的概率为0.3
- bernoulli sampling的概率为 0.3
- 使用Adam优化器,学习率 1 0 − 5 10^{-5} 10−5,迭代450000次
结构和 Noise2Noise结构基本相似,不同点在于:
- 在Decoder中加入了dropout (不确定性估计和稳定性)
- 在Encoder中使用部分卷积替代标准卷积
3. Pytorch实现
(1)Partial convolution 结构
注意,这里是使用的 部分卷积网络,所以使用了 NVIDIA的实现,
- 具体代码参考 https://github.com/NVIDIA/partialconv
- 解释说明参考 https://zhuanlan.zhihu.com/p/519664740
import torch
import torch.nn.functional as F
from torch import nn, cuda
from torch.autograd import Variable
class PartialConv2d(nn.Conv2d):
def __init__(self, *args, **kwargs):
# whether the mask is multi-channel or not
if 'multi_channel' in kwargs:
self.multi_channel = kwargs['multi_channel']
kwargs.pop('multi_channel')
else:
self.multi_channel = False
if 'return_mask' in kwargs:
self.return_mask = kwargs['return_mask']
kwargs.pop('return_mask')
else:
self.return_mask = False
#####Yize's fixes
self.multi_channel = True
self.return_mask = True
super(PartialConv2d, self).__init__(*args, **kwargs)
if self.multi_channel:
self.weight_maskUpdater = torch.ones(self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1])
else:
self.weight_maskUpdater = torch.ones(1, 1, self.kernel_size[0], self.kernel_size[1])
self.slide_winsize = self.weight_maskUpdater.shape[1] * self.weight_maskUpdater.shape[2] * self.weight_maskUpdater.shape[3]
self.last_size = (None, None, None, None)
self.update_mask = None
self.mask_ratio = None
def forward(self, input, mask_in=None):
assert len(input.shape) == 4
if mask_in is not None or self.last_size != tuple(input.shape):
self.last_size = tuple(input.shape)
with torch.no_grad():
if self.weight_maskUpdater.type() != input.type():
self.weight_maskUpdater = self.weight_maskUpdater.to(input)
if mask_in is None:
# if mask is not provided, create a mask
if self.multi_channel:
mask = torch.ones(input.data.shape[0], input.data.shape[1], input.data.shape[2], input.data.shape[3]).to(input)
else:
mask = torch.ones(1, 1, input.data.shape[2], input.data.shape[3]).to(input)
else:
mask = mask_in
self.update_mask = F.conv2d(mask, self.weight_maskUpdater, bias=None, stride=self.stride, padding=self.padding, dilation=self.dilation, groups=1)
# for mixed precision training, change 1e-8 to 1e-6
self.mask_ratio = self.slide_winsize/(self.update_mask + 1e-8)
# self.mask_ratio = torch.max(self.update_mask)/(self.update_mask + 1e-8)
self.update_mask = torch.clamp(self.update_mask, 0, 1)
self.mask_ratio = torch.mul(self.mask_ratio, self.update_mask)
raw_out = super(PartialConv2d, self).forward(torch.mul(input, mask) if mask_in is not None else input)
if self.bias is not None:
bias_view = self.bias.view(1, self.out_channels, 1, 1)
output = torch.mul(raw_out - bias_view, self.mask_ratio) + bias_view
output = torch.mul(output, self.update_mask)
else:
output = torch.mul(raw_out, self.mask_ratio)
if self.return_mask:
return output, self.update_mask
else:
return output
(2) U-net 网络结构
class EncodeBlock(nn.Module):
def __init__(self,in_channel,out_channel,flag):
super(EncodeBlock,self).__init__()
self.conv = PartialConv2d(in_channel, out_channel, kernel_size = 3, padding = 1)
self.nonlinear = nn.LeakyReLU(0.1)
self.MaxPool = nn.MaxPool2d(2)
self.flag = flag
def forward(self, x, mask_in):
out1, mask_out = self.conv(x, mask_in = mask_in)
out2 = self.nonlinear(out1)
if self.flag:
out = self.MaxPool(out2)
mask_out = self.MaxPool(mask_out)
else:
out = out2
return out, mask_out
class DecodeBlock(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel, final_channel = 3, p = 0.7, flag = False):
super(DecodeBlock,self).__init__()
self.conv1 = nn.Conv2d(in_channel,mid_channel,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(mid_channel,out_channel,kernel_size=3,padding=1)
self.conv3 = nn.Conv2d(out_channel,final_channel,kernel_size=3,padding=1)
self.nonlinear1 = nn.LeakyReLU(0.1)
self.nonlinear2 = nn.LeakyReLU(0.1)
self.sigmoid = nn.Sigmoid()
self.flag = flag
self.Dropout = nn.Dropout(p)
def forward(self,x):
out1 = self.conv1(self.Dropout(x))
out2 = self.nonlinear1(out1)
out3 = self.conv2(self.Dropout(out2))
out4 = self.nonlinear2(out3)
if self.flag:
out5 = self.conv3(self.Dropout(out4))
out = self.sigmoid(out5)
else:
out = out4
return out
class self2self(nn.Module):
def __init__(self,in_channel,p):
super(self2self,self).__init__()
self.EB0 = EncodeBlock(in_channel,out_channel=48,flag=False)
self.EB1 = EncodeBlock(48,48,flag=True)
self.EB2 = EncodeBlock(48,48,flag=True)
self.EB3 = EncodeBlock(48,48,flag=True)
self.EB4 = EncodeBlock(48,48,flag=True)
self.EB5 = EncodeBlock(48,48,flag=True)
self.EB6 = EncodeBlock(48,48,flag=False)
self.DB1 = DecodeBlock(in_channel=96,mid_channel=96,out_channel=96,p=p)
self.DB2 = DecodeBlock(in_channel=144,mid_channel=96,out_channel=96,p=p)
self.DB3 = DecodeBlock(in_channel=144,mid_channel=96,out_channel=96,p=p)
self.DB4 = DecodeBlock(in_channel=144,mid_channel=96,out_channel=96,p=p)
self.DB5 = DecodeBlock(in_channel=96+in_channel,mid_channel=64,out_channel=32,p=p,flag=True)
self.Upsample = nn.Upsample(scale_factor=2,mode='bilinear')
self.concat_dim = 1
def forward(self,x,mask):
out_EB0,mask = self.EB0(x,mask) # [3,w,h] -> [48,w,h]
out_EB1,mask = self.EB1(out_EB0,mask_in=mask) # [48,w,h] -> [48,w/2,h/2]
out_EB2,mask = self.EB2(out_EB1,mask_in=mask) # [48,w/2,h/2] -> [48,w/4,h/4]
out_EB3,mask = self.EB3(out_EB2,mask_in=mask) # [48,w/4,h/4] -> [48,w/8,h/8]
out_EB4,mask = self.EB4(out_EB3,mask_in=mask) # [48,w/8,h/8] -> [48,w/16,h/16]
out_EB5,mask = self.EB5(out_EB4,mask_in=mask) # [48,w/16,h/16] -> [48,w/32,h/32]
out_EB6,mask = self.EB6(out_EB5,mask_in=mask) # [48,w/32,h/32] -> [48,w/32,h/32]
out_EB6_up = self.Upsample(out_EB6) # [48,w/32,h/32] -> [48,w/16,h/16]
in_DB1 = torch.cat((out_EB6_up,out_EB4),self.concat_dim) # [48,w/16,h/16] -> [96,w/16,h/16]
out_DB1 = self.DB1((in_DB1)) # [96,w/16,h/16] -> [96,w/16,h/16]
out_DB1_up = self.Upsample(out_DB1) # [96,w/16,h/16] -> [96,w/8,h/8]
in_DB2 = torch.cat((out_DB1_up,out_EB3),self.concat_dim) # [96,w/8,w/8] -> [144,w/8,w/8]
out_DB2 = self.DB2((in_DB2)) # [144,w/8,w/8] -> [96,w/8,w/8]
out_DB2_up = self.Upsample(out_DB2) # [96,w/8,h/8] -> [96,w/4,h/4]
in_DB3 = torch.cat((out_DB2_up,out_EB2),self.concat_dim) # [96,w/4,w/4] -> [144,w/4,w/4]
out_DB3 = self.DB2((in_DB3)) # [144,w/4,w/4] -> [96,w/4,w/4]
out_DB3_up = self.Upsample(out_DB3) # [96,w/4,h/4] -> [96,w/2,h/2]
in_DB4 = torch.cat((out_DB3_up, out_EB1),self.concat_dim) # [96,w/2,w/2] -> [144,w/2,w/2]
out_DB4 = self.DB4((in_DB4)) # [144,w/2,w/2] -> [96,w/2,w/2]
out_DB4_up = self.Upsample(out_DB4) # [96,w/2,h/2] -> [96,w,h]
in_DB5 = torch.cat((out_DB4_up, x),self.concat_dim) # [96,w,h] -> [96+c,w,h]
out_DB5 = self.DB5(in_DB5) # [96+c,w,h] -> [32,w,h]
return out_DB5
model = self2self(3,0.3)
model
(3)网络训练
import numpy as np
import matplotlib.pyplot as plt
import torch.optim as optim
import torchvision.transforms as T
import cv2
from PIL import Image
from tqdm import tqdm
# 图片加载
img = np.array(Image.open("5.png"))
plt.figure()
plt.imshow(img)
plt.show()
img.shape
# 参数设置
##Enable GPU
USE_GPU = True
dtype = torch.float32
if USE_GPU and torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
print('using device:', device)
learning_rate = 1e-4
model = model.cuda()
optimizer = optim.Adam(model.parameters(), lr = learning_rate)
w,h,c = img.shape
p=0.3
NPred=100
slice_avg = torch.tensor([1,3,512,512]).to(device)
# 训练迭代
def image_loader(image, device, p1, p2):
"""
load image and returns cuda tensor
"""
loader = T.Compose([
T.RandomHorizontalFlip(torch.round(torch.tensor(p1))),
T.RandomVerticalFlip(torch.round(torch.tensor(p2))),
T.ToTensor()])
image = Image.fromarray(image.astype(np.uint8))
image = loader(image).float()
if not torch.is_tensor(image):
image = torch.tensor(image)
image = image.unsqueeze(0) #this is for VGG, may not be needed for ResNet
return image.to(device)
pbar = tqdm(range(500000))
for itr in pbar:
# 不知道这个采样是否正确,是不是需要在每一个通道都分别进行均匀采样?
p_mtx = np.random.uniform(size=[img.shape[0],img.shape[1],img.shape[2]])
mask = (p_mtx>p).astype(np.double)
img_input = img
y = img
p1 = np.random.uniform(size=1)
p2 = np.random.uniform(size=1)
# 加载输入图片(根据概率进行翻转)
img_input_tensor = image_loader(img_input, device, p1, p2)
# 对原始图片进行相同操作(翻转)
y = image_loader(y, device, p1, p2)
# mask为伯努利采样结果
mask = np.expand_dims(np.transpose(mask,[2,0,1]),0)
mask = torch.tensor(mask).to(device, dtype=torch.float32)
# 网络推理
model.train()
img_input_tensor = img_input_tensor*mask
output = model(img_input_tensor, mask)
# 损失函数
# loss = torch.sum((output+img_input_tensor-y)*(output+img_input_tensor-y)*(1-mask))/torch.sum(1-mask)
loss = torch.sum((output-y)*(output-y)*(1-mask))/torch.sum(1-mask)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_description("iteration {}, loss = {:.4f}".format(itr+1, loss.item()*100))
if (itr+1)%1000 == 0:
model.eval()
sum_preds = np.zeros((img.shape[0],img.shape[1],img.shape[2]))
for j in range(NPred):
p_mtx = np.random.uniform(size=img.shape)
mask = (p_mtx>p).astype(np.double)
img_input = img*mask
img_input_tensor = image_loader(img_input, device, 0.1, 0.1)
mask = np.expand_dims(np.transpose(mask,[2,0,1]),0)
mask = torch.tensor(mask).to(device, dtype=torch.float32)
output_test = model(img_input_tensor,mask)
sum_preds[:,:,:] += np.transpose(output_test.detach().cpu().numpy(),[2,3,1,0])[:,:,:,0]
avg_preds = np.squeeze(np.uint8(np.clip((sum_preds-np.min(sum_preds)) / (np.max(sum_preds)-np.min(sum_preds)), 0, 1) * 255))
write_img = Image.fromarray(avg_preds)
write_img.save("./examples/images/Self2self-"+str(itr+1)+".png")
torch.save(model.state_dict(),'./examples/models/model-'+str(itr+1))
展示一下这里进行伯努利采样得到的结果和输入的噪声图片的区别
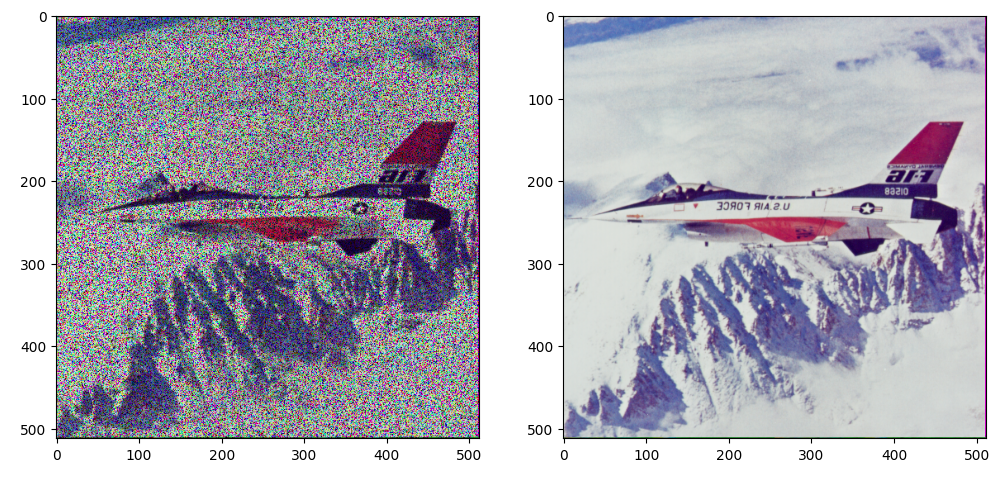
(4)迭代结果
展示不同次数的结果:
1000,10000,20000,30000次迭代




总结
从我自己可能会用到的地方进行 评价 (不是评价啊哈,大佬的工作真的非常棒,就是从我们迁移应用的角度看待)
- 单样本任务,不需要合成特别多的样本
- 使用Dropout引入了模型的不确定性估计,可以使得恢复更加稳定
- 使用部分卷积替代常规卷积,对于图片去噪和恢复有一定的效果
- 和Deep Image Prior相比,二者都不需要多余的样本,但是self2self更加稳定
一些小问题:
- 迭代次数太多,上述操作迭代了500000次
- 如果一张照片去噪需要1小时,那么其应用场景比较有限
- 其实损失函数的设计,对该方法有一定的影响,可以尝试一下不同的损失函数,其结果会有一定的影响