聚宽
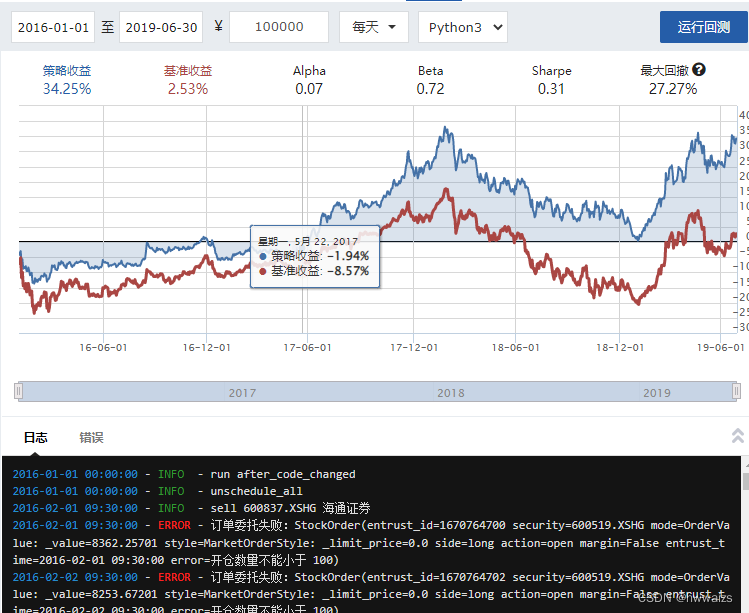
聚宽是一个做金融量化的网站,https://www.joinquant.com,登录注册,如果你写的文章、策略被别人采纳,增加积分,积分用于免费的回测时长。在我的策略,进入策略列表,里面有做好的策略模板可以进行参考和学习,也可以新建策略,选择股票策略,可以更改文件的名称。左边是代码区域,可以点击函数库查看聚宽平台的函数库进行了解和学习,克隆为把打开的代码克隆一份在新的网页打开使用,2to3是将python2的代码转化为python3,API为常见的API开发文档,在聚宽平台上写策略的话需要用的方法,都可以在开发文档中找到相应的说明,如参数、返回值等等;右上方是进行回测的参数设置,如起止日期,投入金额,进行操作的频率;右下方是操作的日志信息和输出的效果。
默认聚宽的代码运行
新建股票策略,默认生成一个代码的框架,包含导入函数库,初始化函数,开盘前、开盘时、收盘后运行的函数,执行相应的操作。
# 导入函数库
from jqdata import *
# 初始化函数,设定基准信息等等,如购买哪支股票
def initialize(context):
# 设定沪深300作为基准,是股票池,具有代表性的300支股票,可以发生变化,从里面挑选股票进行购买
set_benchmark('000300.XSHG')
# 开启动态复权模式(以真实的价格模拟策略的交易)
set_option('use_real_price', True)
# 输出内容到日志 log.info()
log.info('初始函数开始运行且全局只运行一次')
# 过滤掉order系列API产生的比error级别低的log
# log.set_level('order', 'error')
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税(必须要有的), 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
## 运行函数(reference_security为运行时间的参考标的;传入的标的只做种类区分,因此传入'000300.XSHG'或'510300.XSHG'是一样的)
# 开盘前运行
run_daily(before_market_open, time='before_open', reference_security='000300.XSHG')
# 开盘时运行
run_daily(market_open, time='open', reference_security='000300.XSHG')
# 收盘后运行
run_daily(after_market_close, time='after_close', reference_security='000300.XSHG')
## 开盘前运行函数
def before_market_open(context):
# 输出运行时间
log.info('函数运行时间(before_market_open):'+str(context.current_dt.time()))
# 给微信发送消息(添加模拟交易,并绑定微信生效)
# send_message('美好的一天~')
# 要操作的股票:平安银行(g.为全局变量)
g.security = '000001.XSHE'
## 开盘时运行函数
def market_open(context):
log.info('函数运行时间(market_open):'+str(context.current_dt.time()))
security = g.security
# 获取股票的收盘价
close_data = get_bars(security, count=5, unit='1d', fields=['close'])
# 取得过去五天的平均价格
MA5 = close_data['close'].mean()
# 取得上一时间点价格
current_price = close_data['close'][-1]
# 取得当前的现金
cash = context.portfolio.available_cash
# 如果上一时间点价格高出五天平均价1%, 则全仓买入
if (current_price > 1.01*MA5) and (cash > 0):
# 记录这次买入
log.info("价格高于均价 1%%, 买入 %s" % (security))
# 用所有 cash 买入股票
order_value(security, cash)
# 如果上一时间点价格低于五天平均价, 则空仓卖出
elif current_price < MA5 and context.portfolio.positions[security].closeable_amount > 0:
# 记录这次卖出
log.info("价格低于均价, 卖出 %s" % (security))
# 卖出所有股票,使这只股票的最终持有量为0
order_target(security, 0)
## 收盘后运行函数
def after_market_close(context):
log.info(str('函数运行时间(after_market_close):'+str(context.current_dt.time())))
#得到当天所有成交记录
trades = get_trades()
for _trade in trades.values():
log.info('成交记录:'+str(_trade))
log.info('一天结束')
log.info('##############################################################')
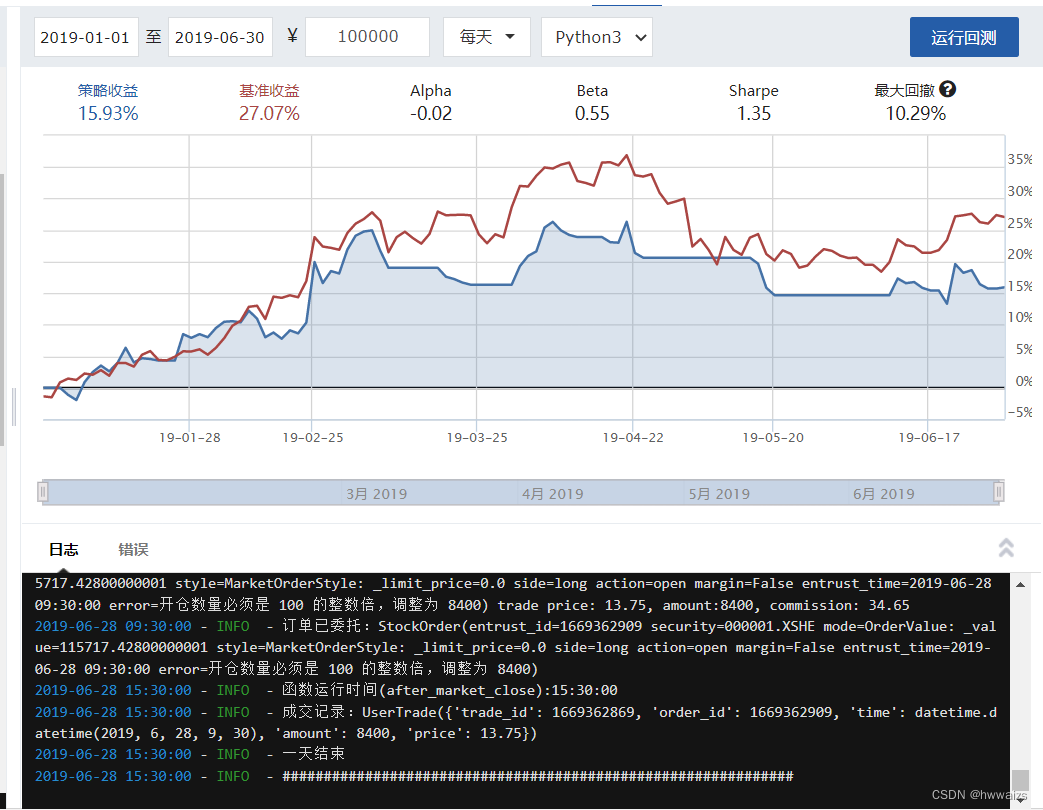
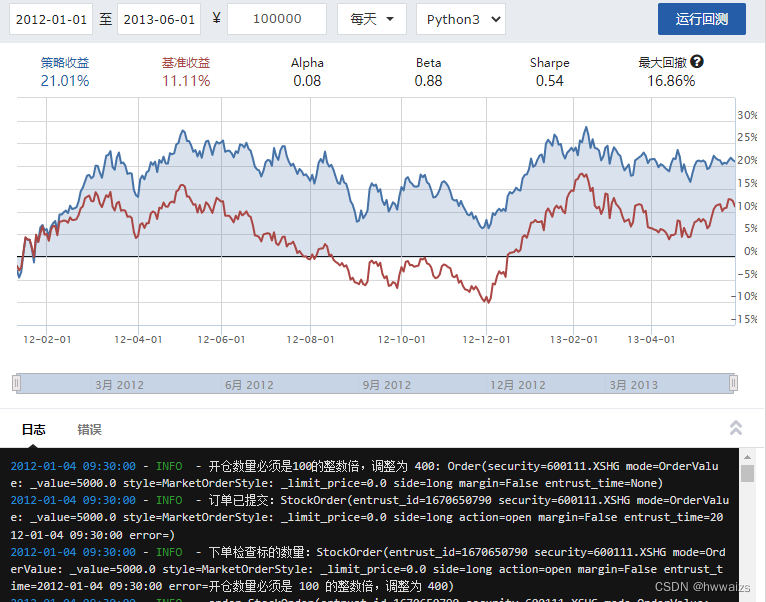
点击编译运行,会得到回测结果。基准收益是指对股票投资按照时间预计能得到的收益,正常买了之后不涉及任何的操作,所得到的收益,策略收益是指投入资金后,对价值的估值,按照策略大致得到的收益。从下图可以看出,模拟的策略低于基准收益。
聚宽基础使用
可以在API里进行函数、方法的查询,在页面上方的数据字典里可以查看给定的数据内容。
get_index_stocks (index_symbol, date=None),获取指数成份股
获取一个指数给定日期在平台可交易的成分股列表。参数:index_symbol: 指数代码;date: 查询日期, 一个字符串(格式类似’2015-10-15’)或者datetime.date/datetime.datetime对象, 可以是None, 使用默认日期. 这个默认日期在回测和研究模块上有点差别:
回测模块: 默认值会随着回测日期变化而变化, 等于context.current_dt
研究模块: 默认是今天
返回:返回股票代码的list。如’000300.XSHG’,指的是选择日期当天的沪深300指的300支股票的列表,是最有代表性的300支股票,并不是固定的,股票随时会变。好比全年级前300名,这300名并不是一成不变的,会随时发生变化。
get_current_data() 获取当前时间数据,获取当前单位时间(当天/当前分钟)的涨跌停价, 是否停牌,当天的开盘价等。不需要传入参数, 即使传入了, 返回的 dict 也是空的, dict 的 value 会按需获取,其中 key 是股票代码, value 是拥有如下属性的对象。
last_price : 最新价
high_limit: 涨停价
low_limit: 跌停价
paused: 是否停止或者暂停了交易, 当停牌、未上市或者退市后返回 True
is_st: 是否是 ST(包括ST, *ST),是则返回 True,否则返回 False
day_open: 当天开盘价
name: 股票现在的名称, 可以用这个来判断股票当天是否是 ST, *ST, 是否快要退市
industry_code: 股票现在所属行业代码,
# 导入函数库
import jqdata
# 初始化函数,设定基准等等,点击编译运行,函数不用调用会自动运行
def initialize(context): # context类似 类里的self
# 定义一个全局变量 保存要操作的股票,可以是列表,存放多支股票
# g.security = '000001.XSHE' # 平安银行
# 获取以往的历史数据,选取沪深300股票
g.security = get_index_stocks('000300.XSHG')
# print(g.security) # 输出 2019-1-1的代表300支股票
# 开启动态复权模式,以真实的价格进行模拟交易
set_option( 'use_real_price',True)
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱,如买入的时候手续费为0,open_tax=0
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
def handle_data(context,data): # 每一天的操作,每天都要显示的内容
# print('hello') # 每天都打印 'hello'
# 获取当前时间数据
# print(get_current_data()) # 输出的是个空字典
# print(get_current_data()['601318.XSHG'].day_open) # 每一天的开盘价格,用Key,value的形式获取数据
# 获取以往的历史数据
# print(attribute_history('601318.XSHG',5)) # 相当于MA5.历史5天的数据
# 买入多少股,必须是100的倍数
order('601318.XSHG',100)
# 买入多少钱的
order_value('601318.XSHG',10000)
# 从股票池里获取股票
for stock in g.security :
# 获取当前股票的开盘价格
p = get_current_data()[stock].day_open
# 获取当前股票持有股数
amount = context.portfolio.positions[stock].total_amount
运行回测的结果
双均线分析
对于每一个交易日,都可以计算出前N天的移动平均值,然后把这些移动平均值连起来,成为一条线,就叫做N日移动平均线。移动平均线常用:5天,10天,30天,60天,120天和240天的指标
● 5天和10天的是短线操作的参照指标,称做日均线指标;
● 30天和60天的是中期均线指标,称做季均线指标;
● 120天和240天的是长期均线指标,称做年均线指标。
黄金交叉
短期均线上穿长期均线,买入信号
死亡交叉
短期均线下穿长期均线,卖出信号
两个交叉点是交替出现的。
position 持仓标的信息;order 按照股票数下单,要保证有足够的剩余资金进行下单购买;order_value 按照价值下单,参数value= 最新价 * 手数 * 保证金率(股票为1) * 乘数(股票为100),知道当前用户手中的可用资金来判断购买多少股。
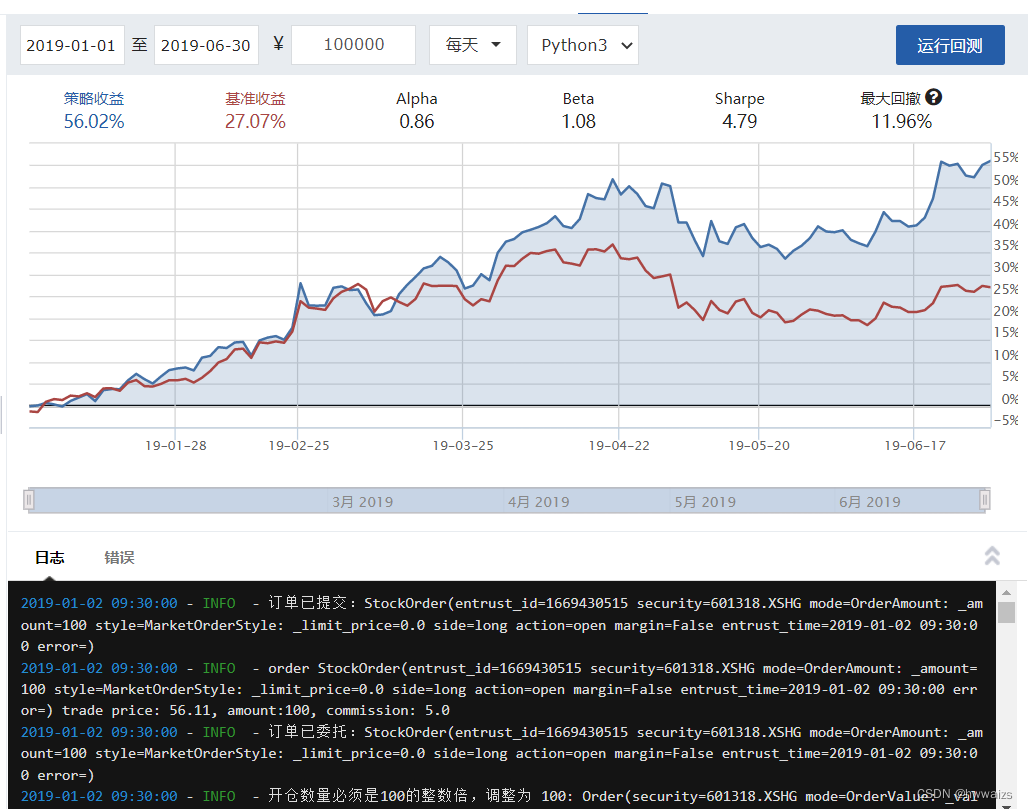
2016-1-1到201-6-1的时间内,购买的是100的整数倍,策略收益高于基准收益。
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
# 输出内容到日志 log.info()
log.info('初始函数开始运行且全局只运行一次')
g.security = ['601318.XSHG'] # 假设只有一种股票
g.d5 = 5
g.d60 = 60
# 在指定日期的工作日内,都会运行一次
def handle_data(context,data): # context 上下文数据(必须得有,相当于类里的self),data可以省略
# print(110) # 每一个交易日都会执行的操作
# 循环遍历股票
for stock in g.security:
# print(stock)
# 金叉:如果5日均线大于60日均线,且不持仓,进行买入
# 死叉:如果5日均线小于60日均线,且持仓,进行卖出
# 方法一:
# df = attribute_history(stock,g.d5) # 获取5天的历史数据
# # print(df) # 打印每个交易日的前5天的数据
# ma5 = df['close'].mean() # ma5的值是收盘价格的平均值
# 方法二:
df = attribute_history(stock,g.d60)
ma5 = df['close'][-5:].mean()
ma60 = df['close'].mean()
# 进行金叉和死叉的判断
# 如果60日均线大于5日均线,且持仓即当前股票在投资组合信息汇总中
if ma60 > ma5 and stock in context.portfolio.positions:
# 进行卖出
order_target(stock,0) # 全仓卖出
if ma60 < ma5 and stock not in context.portfolio.positions:
# 进行买入,按金额买入,可用资金
order_value(stock,context.portfolio.available_cash * 0.8)
# 看一下均线的交叉,找出并分析黄金和死亡交叉点
# 显示线形图
record(ma5=ma5,ma60=ma60) # 自定义参数名称
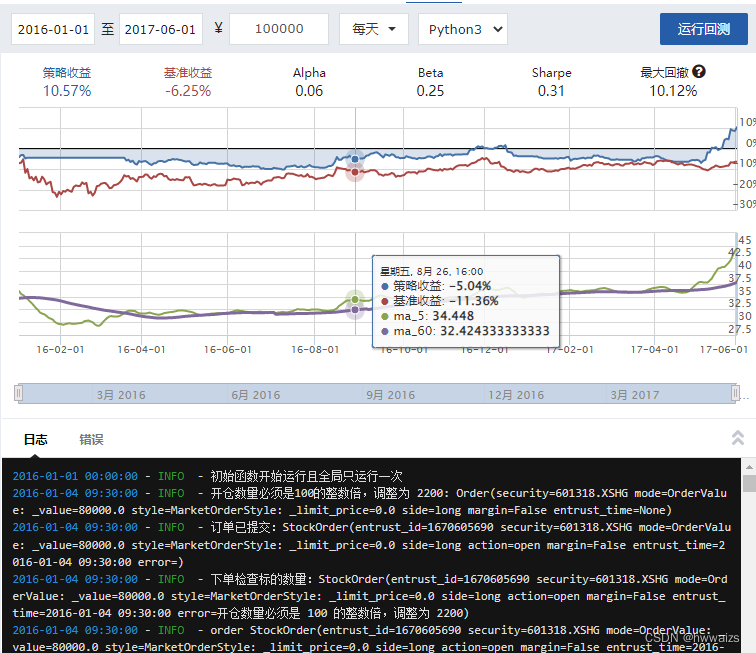
运行回测的结果,上面的图是策略收益线和基准收益线,执行的策略收益大于基准收益,下面的线为ma5和ma60的线,可以找到交叉的点(交叉的日期).
因子选股策略
● 因子:选择股票的某种标准,选择股票的策略;双均线分析是选择买入股票的时机,择时的股票策略。购买股票不光是买入的时机要好,买入的股票表现也要好,股票挑选的不好,不管怎么使用策略,股票本身上涨空间有限。
选择股票的标准:增长率、市值、市盈率、ROE(净资产收益率),公司的财报数据中一般都会包含这些内容。市值一般是估算,并不是说公司市值多少,价值就是多少,一般公司的资产要比市值要低,比如上市公司市值多少亿,其实公司的资金并没有那么多。
● 选股策略:根据选择股票的标准来选择股票,如相亲的标准
1.对于某个因子,选取表现最好(因子最大或最小)的N支股票持仓,因子最大或者最小,市盈率越高越好,增长率越大越好,亏损率越小越好。
2.每隔一段时间调仓一次,买了不建议一直放在手里,根据股票的走势适时调整选择的股票。
3.选股策略一般都是长期的投资,因为不是一天交易一次,而是几个月交易一次
● 小市值策略:市值为因子选股的因子选取股票池中市值最小的N只股票持仓,比如古代富人家对进京赶考秀才的资助,可以资助多个秀才,增加自己投资的几率,远比直接攀大官要现实的多。
聚宽平台上默认的小市值策略
'''
筛选出市值介于20-30亿的股票,选取其中市值最小的三只股票,
每天开盘买入,持有五个交易日,然后调仓。
'''
## 初始化函数,设定要操作的股票、基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# True为开启动态复权模式,使用真实价格交易
set_option('use_real_price', True)
# 设定成交量比例
set_option('order_volume_ratio', 1)
# 股票类交易手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(open_tax=0, close_tax=0.001, \
open_commission=0.0003, close_commission=0.0003,\
close_today_commission=0, min_commission=5), type='stock')
# 持仓数量
g.stocknum = 3
# 交易日计时器
g.days = 0
# 调仓频率
g.refresh_rate = 5
# 运行函数
run_daily(trade, 'every_bar')
## 选出小市值股票
def check_stocks(context):
# 设定查询条件
q = query(
valuation.code,
valuation.market_cap
).filter(
valuation.market_cap.between(20,30)
).order_by(
valuation.market_cap.asc()
)
# 选出低市值的股票,构成buylist
df = get_fundamentals(q)
buylist =list(df['code'])
# 过滤停牌股票
buylist = filter_paused_stock(buylist)
return buylist[:g.stocknum]
## 交易函数
def trade(context):
if g.days%g.refresh_rate == 0:
## 获取持仓列表
sell_list = list(context.portfolio.positions.keys())
# 如果有持仓,则卖出
if len(sell_list) > 0 :
for stock in sell_list:
order_target_value(stock, 0)
## 分配资金
if len(context.portfolio.positions) < g.stocknum :
Num = g.stocknum - len(context.portfolio.positions)
Cash = context.portfolio.cash/Num
else:
Cash = 0
## 选股
stock_list = check_stocks(context)
## 买入股票
for stock in stock_list:
if len(context.portfolio.positions.keys()) < g.stocknum:
order_value(stock, Cash)
# 天计数加一
g.days = 1
else:
g.days += 1
# 过滤停牌股票
def filter_paused_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not current_data[stock].paused]
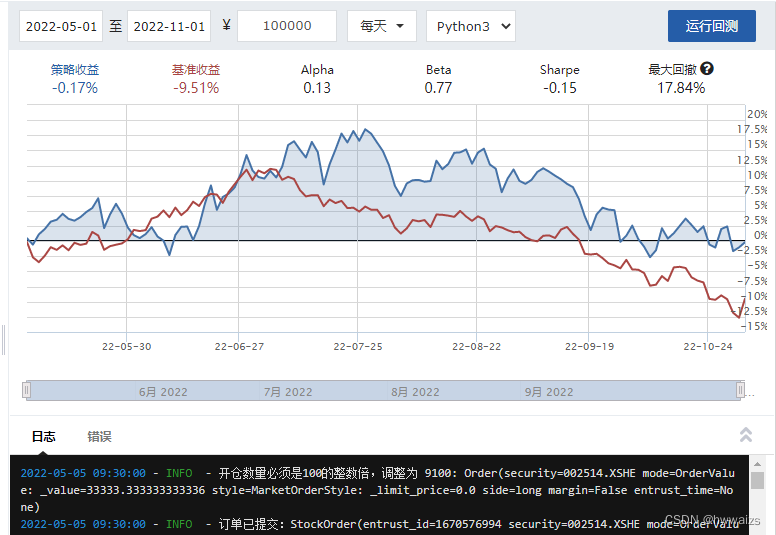
对比代码进行仿写
新建策略–股票策略,同一个策略在不同时期的收益是不一样的
选择沪深300中市值最小的前20支股票,在每个月的第一个交易日进行股票的筛选进行交易
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
# 定义全局变量
g.security = get_index_stocks('000300.XSHG') # 从沪深300里面去选择
# 查询市值比较小的股票
g.q = query(valuation).filter(valuation.code.in_(g.security))
# 选择其中的20支股票
g.N = 20
# 每月执行一次,1为第一个交易日
run_monthly(handle,1)
# 定义函数,每个月第一个交易日调用一次,并不是hand_data函数
def handle(context):
# 1.获取市值最小的20支股票,
# 获取对应股票的交易代码和总市值market_cap
df = get_fundamentals(g.q)[['code','market_cap']]
# 对20支股票进行排序操作,[:g.N,:]从小到大排列取前20,取所有的列
df = df.sort_values('market_cap').iloc[:g.N,:]
print(df) # 每次取出的前20支股票不一定都一样
# 2.调仓,持有的股票中有前20,就保留,没有持有就买入
# 取出股票代码,看一下当前有无持有这20支股票
# 需要持有的股票代码
to_hold = df['code'].values
# 循环现在所持有的股票,当前投资信息里所持有的股票
for stock in context.portfolio.positions:
# 如果持有股票没有在to_hold列表里,就卖出去
if stock not in to_hold:
order_target(stock,0) # 卖出后,持有为0
# 需要买入的股票列表
# 遍历持有列表里的股票 如果没有在持有股票里,就买入
tobuy = [stock for stock in to_hold if stock not in context.portfolio.positions]
# 计算每支股票可以使用的钱是多少,比如账户里有十万,买9支股票,可以买多少
# 判断,当前是否有需要买入的股票
if len(tobuy) > 0:
# 上下文投资组合信息汇总中可用资金除以当前有多少支股票,十万除以几支股票
# 每支股票花的钱
cash_per_stock = context.portfolio.available_cash // len(tobuy)
for stock in tobuy:
# 每支股票买入的钱
order_value(stock,cash_per_stock)
应用策略得到的结果
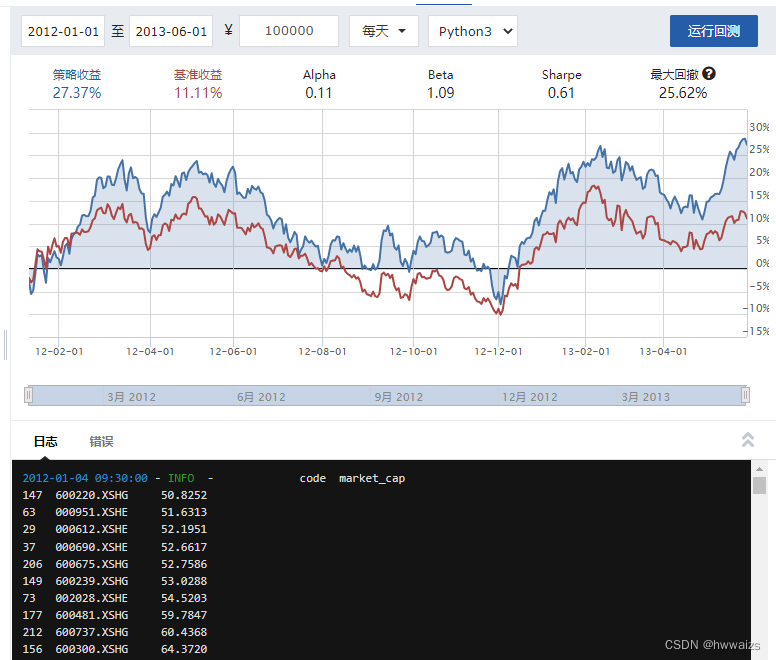
多因子选股策略
单因子是只考虑一个因子的情况,只考虑一个标准。多因子选股可以综合多个因子:市值,市盈率,ROE(净资产收益率)等等,进行策略分析的时候选择两个以上的因子。
评分模型:
● 每个股票针对每个因子进行评分,将评分相加,获取每支股票在不同标准下的评分,进行相加,选出评分最高的进行股票进行持仓。
● 选出总评分最大的N只股票持仓。考察学生的学习成绩,单因子的话只考虑一门课的成绩,多因子要考虑多门学科的综合成绩
● 如何计算股票在某个因子下的评分:归一化(标准化),不同的数据指标标准不一样,比如语文成绩的80分跟理科综合的80分评分标准是不一样的, 归一化操作是为了减轻差异化数据带来的影响。
标准化(归一化:数据预处理)
机器学习用到的数据预处理的特征工程,创建模型要考虑到数据差异化的影响。
min-max标准化:x* = (x-min)/(max-min)
没有新数据加入,这种方法相对比较简单。
● 将原始数据转化为一个0到1的数,映射到0-1的范围内,比如70,80,90,映射后为0.7,0.8,0.9
● 缺点:如果有新数据加入,可能导致min和max的变化,从而求得的映射值也会发生变化。比如之前的值是0-100,突然加入了1000,整个数据的映射值也会发生变化
我的策略–进入策略列表–新建策略–股票策略
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 初始化股票池
g.security = get_index_stocks('000300.XSHG')
# 得到数据查询对象,查询公司的财务指标,如市值、净资产的盈利率、增长率等
g.q = query(valuation,indicator).filter(valuation.code.in_(g.security))
# 每个月运行一次,第1个工作日
run_monthly(handle_month,1)
# 定义每个月运行一次的函数
def handle_month(context):
# 得到表对象,获取代码,市值,净资产
df = get_fundamentals(g.q)[['code','market_cap','roe']]
print(df)
正常情况下的市值、净资产值为:
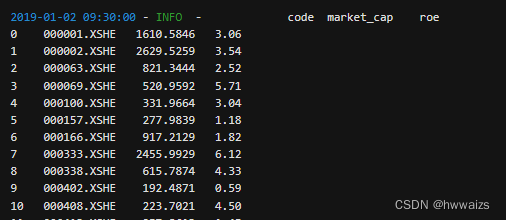
对市值和净资产进行归一化操作
# 导入函数库
# 定义每个月运行一次的函数
def handle_month(context):
# 得到表对象,获取代码,市值,净资产
df = get_fundamentals(g.q)[['code','market_cap','roe']]
# print(df)
# 归一化处理 映射的值 (x-min)/(max-min)
# 市值归一化
df['market_cap'] = (df['market_cap']-df['market_cap'].min())/(df['market_cap'].max()-df['market_cap'].min())
# 净资产归一化
df['roe'] = (df['roe']-df['roe'].min())/(df['roe'].max()-df['roe'].min())
print(df)
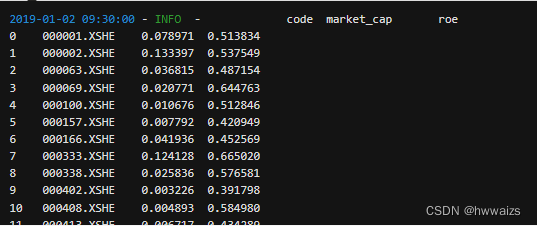
进行归一化处理后,再进行买入卖出的操作
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 初始化股票池
g.security = get_index_stocks('000300.XSHG')
# 得到数据查询对象,查询公司的财务指标,如市值、净资产的盈利率、增长率等
g.q = query(valuation,indicator).filter(valuation.code.in_(g.security))
# 每个月运行一次,第1个工作日
run_monthly(handle_month,1)
# 定义每个月运行一次的函数
def handle_month(context):
# 得到表对象,获取代码,市值,净资产的收益率
df = get_fundamentals(g.q)[['code','market_cap','roe']]
# print(df)
# 归一化处理 映射的值 (x-min)/(max-min)
# 市值归一化
df['market_cap'] = (df['market_cap']-df['market_cap'].min())/(df['market_cap'].max()-df['market_cap'].min())
# 净资产归一化
df['roe'] = (df['roe']-df['roe'].min())/(df['roe'].max()-df['roe'].min())
# print(df)
# 选出评分最大的股票,选择前20支股票的全部列
df['score'] = df['roe'] - df['market_cap']
df = df.sort_values('score',ascending=False).iloc[:20,:]
# print(df) # 从大到小排列
# 获取需要持有的股票代码
# 需要买入的股票代码
to_hold = df['code'].values
# 循环现在持有的股票,当前投资信息里所持有的股
for stock in context.portfolio.positions:
# 如果持有股票没有在to_hold列表里,就卖出去
if stock not in to_hold:
order_target(stock,0) # 卖出后,持有为0
# 需要买入的股票列表
# 遍历持有列表里的股票 如果没有在持有股票里,就买入
tobuy = [stock for stock in to_hold if stock not in context.portfolio.positions]
# 计算每支股票可以使用的钱是多少,比如账户里有十万,买9支股票,可以买多少
# 判断,当前是否有需要买入的股票
if len(tobuy) > 0:
# 上下文投资组合信息汇总中可用资金除以当前有多少支股票,十万除以几支股票
# 每支股票花的钱
cash_per_stock = context.portfolio.available_cash // len(tobuy)
for stock in tobuy:
# 每支股票买入的钱
order_value(stock,cash_per_stock)
归一化处理后得到的收益如下图所以,在不同的时期,同一个策略考虑因子的多少也会影响收益的效果。如果建立比较适宜的模型,考虑多因子的策略应该高于单子策略的收益。
建立模型的时候,比较重要的因子(如市值)设置的评分比重应该高一点,roe的比重低一点。好比评分的第一标准,第二标准等,多因子策略(多条标准)要考虑首要条件,比如有钱可以占100分,但是只占0.8的比例,算是主要的因素,但不是完全所有的因素,还要考虑其他的因素(性格占0.2的比例)。要看策略的完善情况,有些比较好的策略能应对绝大多数股市变化的情况,但也不可能考虑股市各种各样的情况,看的是整体策略的收益情况。
Z-score标准化:x* = (x-μ)/σ
如果需要增加新数据,此种方法更适合。
● μ一组数的平均值 σ为标准差
● 将原始数据转化为均值为0,标准差为1的正态分布的随机变量
均值回归理论
均值回归:核心内容就是 “跌下去的迟早要涨上来”
均值回归的理论基于以下观测
价格的波动一般会以它的均线为中心。也就是说,当标的价格由于波动而偏离移动均线时,它将调整并重归于均线。涨到最高点势必会下降,降到最低点就会再上升,具体是下跌到什么程度才会买入,就要引入定义偏离程度。
定义偏离程度:(MA-P)/MA,MA为移动平均线,如MA5,MA30等等,P为收盘时候的价格,价格的波动超出平均线的范围,结果为正数即是向上偏移,为负数是向下偏移。
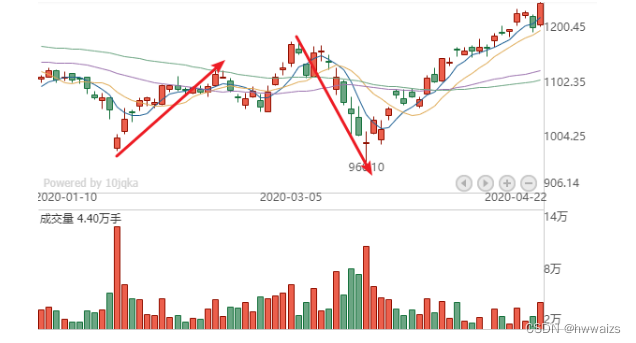
均值回归策略执行
● 计算股票池中所有股票的N日均线,可以是5日、30日等等
● 计算股票池中所有股票与均线的偏离度,价格与平均线偏离的程度
● 选取偏离度最高(价格波动比较大)的M支股票并调仓(调大或者调小,判断是否风险最大)
主页–进入策略列表–新建策略–股票策略,进行均值回归策略的实现。设定沪深300为基准,开启动态复权模式以及手续费的设置,先建立一个Series对象,索引是沪深300的股票代码,遍历这300支股票求出每支股票ma30和p的数据,然后求出偏离程度,取出偏离程度最大(比正常的价格要低)的10支股票进行调仓,然后看一下目前账户里持有的股票,有不在这10支股票里的就卖掉,创建买入的列表,只要有需要买入的股票,就看一下当期资金的剩余情况除以需要买入股票的数量得到 每支股票要买多少钱的,进行买入的操作。
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
# 设置全局变量,股票池
g.security = get_index_stocks('000300.XSHG')
# MA30,30天一交易,5天的话时间间隔短,交易太频繁
g.ma_days = 30
# 选择10支股票
g.stock_num = 10
#每个月执行一次,第一个交易日执行操作
run_monthly(handle,1)
def handle(context):
# 把选择的沪深300的股票作为索引对象
sr = pd.Series(index=g.security)
for stock in sr.index:
#获取每支股票的前30天的历史数据,收盘价格的平均值
ma = attribute_history(stock,g.ma_days)['close'].mean()
#获取当前股票的开盘价格
p = get_current_data()[stock].day_open
# 计算偏离程度
ratio = (ma - p)/ ma
# 把偏离程度赋值给Series对象,创建的时候只有索引,没有对应的内容
sr[stock] = ratio
# print(sr)
# 选择偏离程度最高(value值最大)的10支股票
to_hold = sr.nlargest(g.stock_num).index.values
# print(to_hold) # 每个月建议持有的10支股票
# 查看目前账户里持有的股票
for stock in context.portfolio.positions:
# 如果不在to_hold列表里,就卖出
if stock not in to_hold:
order_target(stock,0) # 卖出,持有为0
# 买入股票,在to_hold列表,不在我持有的股票列表里
to_buy = [stock for stock in to_hold if stock not in context.portfolio.positions]
# 如果当前列表不为空,就应该有买入的操作
if len(to_buy) > 0:
# 每支股票买入的金额 当前账户的可用资金除以买入股票的数量,每支股票买入多少钱的
cash_per_stock = context.portfolio.available_cash / len(to_buy)
# 每支股票买入这么多金额的数量
for stock in to_buy:
order_value(stock,cash_per_stock)
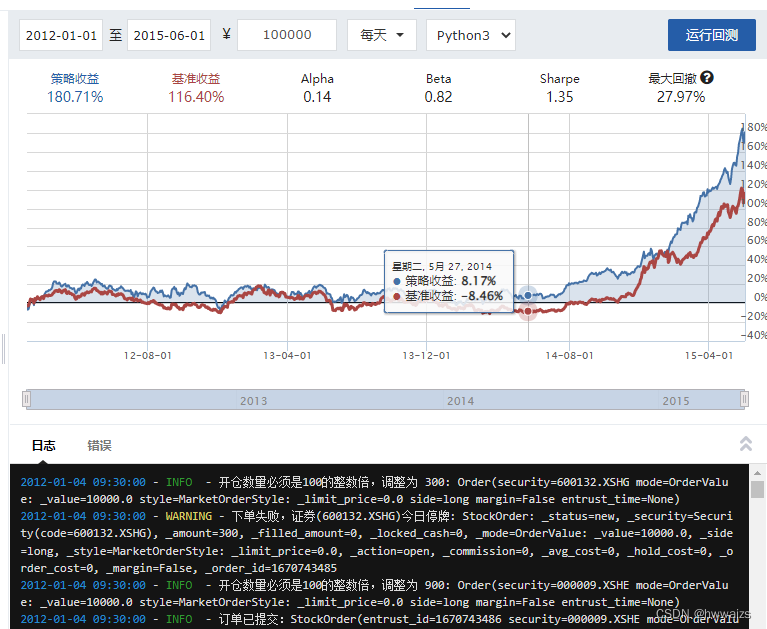
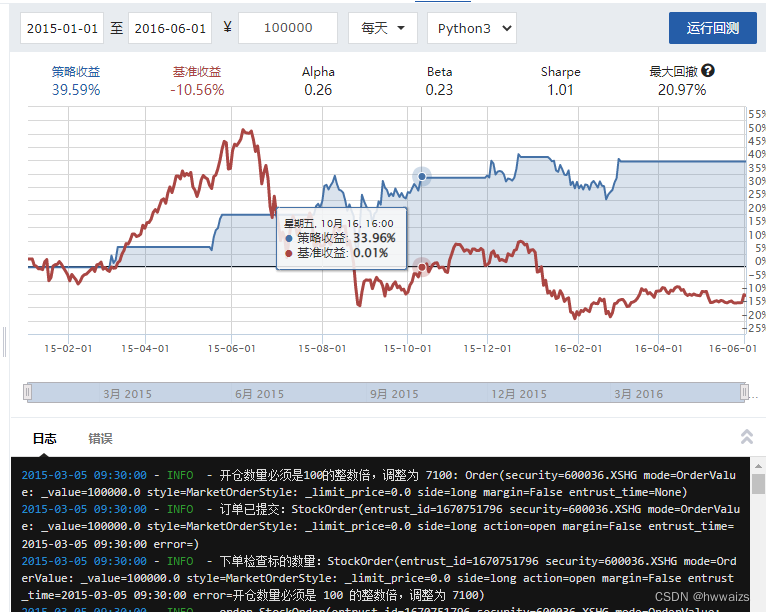
运行回测的结果,策略收益比基准收益要高点,应用策略的时候最好时间长一点。
布林带策略
布林带策略定义
布林是个人名,布林带/布林线/保利加(Bollinger Band)通道策略:由三条轨道线组成,其中上下两条线分别可以看成是价格的压力线和支撑线,在两条线之间是一条价格平均线。当价格突破压力线的时候,意味着价格肯定会下降,当价格跌破了支撑线就会上涨。压力线和支撑线好比路两边的马路牙子,撞到了就要返回。
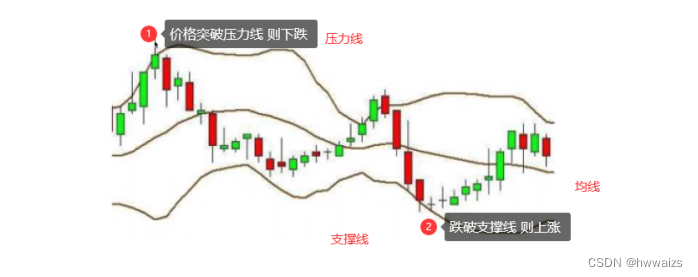
正常情况下,支撑线到均线的距离比压力线到均线的距离要短一些,越靠近均线,交易次数会越频繁
计算公式
● 压力线 = M日均线 + NSTD
● 支撑线 = M日均线 - NSTD
○ STD为标准差
○ N为参数,意味着布林带宽度
新建策略–股票策略
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
g.security = '600036.XSHG'
g.M = 20
g.k = 2
def handle_data(context,data):
sr = attribute_history(g.security,g.M)['close']
ma = sr.mean()
# 压力线
up = ma + g.k*sr.std()
# 支撑线
down = ma - g.k*sr.std()
# 选择对应股票的数据
p = get_current_data()[g.security].day_open
# 每一天花多少钱买股票,看一下账户里的可用资金
cash = context.portfolio.available_cash
# 当前的开盘价格小于支撑线,并且这支股票并没有在我当前的账户信息里,就可以进行买入
if p < down and g.security not in context.portfolio.positions:
# 买入
order_value(g.security,cash)
elif p > up and g.security in context.portfolio.positions:
# 卖出
order_target(g.security,0)
PEG策略
彼得林奇:任何一家公司股票如果定价合理的话,市盈率就会与收益增长率相等。这就是PEG估值法。
市盈率
市盈率是当前股价§相对每股收益(EPS)的比值
P
E
=
P
E
P
S
PE = \frac{P}{EPS}
PE=EPSP
● 市盈率(PE) = 股价§ / 每股收益 (EPS)
○ 股价*股数 ≈ 市值,并不是完全相等
○ 每股收益*股数 ≈ 净收益
● 市盈率 ≈ 市值 / 净收益
比如一家店市值30万,每年会有10万的盈利,PE=30万/10万 =3,在不考虑其他因素的情况下,3年就能回本。
收益增长率
G
=
E
P
S
t
h
i
s
y
e
a
r
−
E
P
S
l
a
s
t
y
e
a
r
E
P
S
l
a
s
t
y
e
a
r
G = \frac{EPS\ this\ year - EPS\ last\ year}{EPS\ last\ year}
G=EPS last yearEPS this year−EPS last year
第一年盈利10万,第二年盈利12万,G = (12-10)/10,即为20%
PEG策略
PEG策略重要条件为:市盈率会与收益增长率相等。也就是PE = G,则得出公式:
P
E
G
=
P
E
G
∗
100
PEG = \frac{PE}{G*100}
PEG=G∗100PE
PEG = 3/(0.2*100) = 0.15
由此可以得出结论:
● PEG越低,代表股价被低估的可能性越大,股价会涨的可能性越大。小于1就是被低估了,大于1就是被高估了
● PEG是一个综合指标,既考察价值,又兼顾成长性。PEG估值法适合应用于成长型的公司,财务比较稳定的公司,周期类、项目性的公司就不适合,剔除掉增长超过50的股票,大多数的股票不可能持续的高增长,有些A股公司常年会有补贴,卖股权等收入来源,这类公司在计算的时候PE和G是有出入的
PEG策略执行思路
PEG策略(选股):
● 计算股票池中所有股票的PEG指标
● 选择PEG最小的N只股票调仓(小的买入,大的卖出)
注意:过滤掉市盈率或收益增长率为负的数据。
"""
PEG策略
"""
# 导入函数库
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
# 设定沪深300作为基准
g.security = get_index_stocks("000300.XSHG")
# 市盈率 净利润同比增长率 财务数据 query对象
# pe_ratio 所属表:valuation
# inc_net_profit_year_on_year 所属表:indicator
# 获取相应的数据
g.q = query(valuation.code,valuation.pe_ratio,indicator.inc_net_profit_year_on_year).filter(valuation.code.in_(g.security))
run_monthly(handle_month,1)
def handle_month(context):
# 获取财务数据
df = get_fundamentals(g.q)
# print(df)
# 选出 PE 并且 G 都大于 0 的数据
df = df[(df["pe_ratio"]>0) & (df["inc_net_profit_year_on_year"]>0)]
# 计算PEG
df["peg"] = df["pe_ratio"]/df["inc_net_profit_year_on_year"]*100
# 排序 选出最小的
df = df.sort_values("peg")
# 取前20支股票的code 放到 tohold 中
to_hold = df["code"][:20].values
# print(to_hold)
# 目前账户所持有的股票
for stock in context.portfolio.positions:
# 不再to_hold 股票 给 卖掉
if stock not in to_hold:
order_target(stock,0)
# 买入 在to_hold里面 但是不在我持有的股票列表里面
tobuy = [stock for stock in to_hold if stock not in context.portfolio.positions]
if len(tobuy) > 0:
cash_per_stock = context.portfolio.available_cash/len(tobuy)
for stock in tobuy:
order_value(stock,cash_per_stock)
运行回测的结果
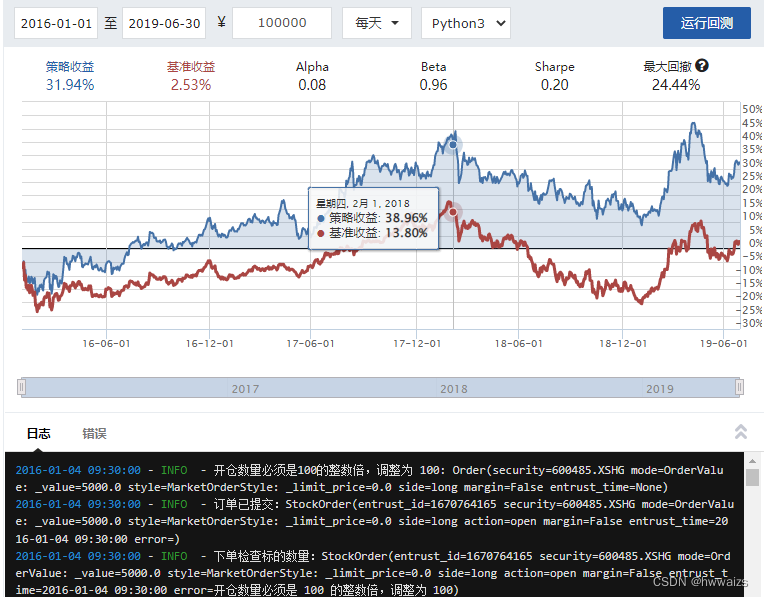
权重收益策略
权重,即为占比,比如公司有50位股东,并不是所有人发表的意见或权利是等效的,持股多的人说话的分类要高于其他人。
"""
每月第一个交易日,筛选出沪深300指数前10的权重股票代码
每个交易日,对持有但不在前10的股票代码进行卖出
再将可用资金,买入前10的股票
"""
import numpy as np
import pandas as pd
from jqdata import *
# 1.初始化函数
def initialize(context):
# 初始化系统
# 1.1 过滤掉order系列API产生的比error级别低的log
log.set_level('order', 'error')
# 1.2 设置动态复权(真实价格)模式
set_option('use_real_price', True)
# 1.3 设置是否开启避免未来数据模式(当天的收盘价)
set_option('avoid_future_data', True)
# 2.模拟盘在每天的交易时间结束后会休眠,第二天开盘时会恢复,
# 如果在恢复时发现代码已经发生了修改,则会在恢复时执行这个函数。
def after_code_changed(context):
# 2.1 初始化
g.index = '000300.XSHG' # 投资指数
g.stocks = [] # 投资组合
# 2.2 设置定时器
# 2.2.1 清除所有定时任务,添加新的
unschedule_all() # 重置,方便代码升级
# 2.2.2 每月第一个(1)交易日,在开盘之前执行handle_prepare
run_monthly(handle_prepare, 1, 'before_open')
# 2.2.3 每天开盘时运行handle_trader
run_daily(handle_trader, 'open')
# 2.2.4 每月最后一个(-1)交易日,在收盘之后执行report_portoflio
# run_monthly(report_portoflio, -1, 'after_close')
# 3. 每月第一个(1)交易日,在开盘之前执行
def handle_prepare(context):
# 3.1 获取指数成分股的权重
weight = get_index_weights(g.index) # 提取指数权重
# print(weight)
# 3.2 给权重进行降序排序,并取出前10支
weight = weight.sort_values(by='weight', ascending=False).head(10)
# print(weight)
# 3.3 获取股票代码列表
g.stocks = weight.index.tolist()
# 4. 每天开盘时运行
def handle_trader(context):
# 4.1 获取当前时间数据
cur_data = get_current_data()
# 4.2 遍历当前账户持仓股票
# 多头卖出
for s in context.portfolio.positions:
# 4.3 如果 当前持仓 不在 大盘权重前10列表中
if s not in g.stocks:
log.info('sell', s, cur_data[s].name)
# 4.4 清仓
order_target(s, 0)
# 4.3 遍历大盘权重前10列表中股票
# 多头买进
for s in g.stocks:
# 0.095 * 总的权益
position = 0.095 * context.portfolio.total_value
# 如果没有持仓 并且 可使用的资金 大于 总权益时
if s not in context.portfolio.positions and\
context.portfolio.available_cash > position:
# 买入
order_value(s, position)
# 5. 每月最后一个(-1)交易日,在收盘之后执行
def report_portoflio(context):
# 报告账户
log.info('total returns', 100*context.portfolio.returns)
log.info('available cash', context.portfolio.available_cash)
log.info('total value', context.subportfolios[0].total_value)
# 分列持仓
cur_data = get_current_data()
for s in context.portfolio.positions:
ps = context.portfolio.positions[s]
log.info('long', s, cur_data[s].name, ps.total_amount, int(ps.value))
# end
运行回测的结果是