引言
主要是介绍一篇引用800+的论文 CTRL: A Conditional Transformer Language Model for Controllable Generation
它的Pytorch源码在 https://huggingface.co/transformers/v3.1.0/_modules/transformers/modeling_ctrl.html
主要思想是通过加入控制代码(control code)来控制文本生成的风格/内容。
基于GPT的文本生成大家认为生成的内容是无用的废话,通常是基于prompt去生成的。那么如何控制文本生成的质量和内容是本篇论文思考的一个点。
这些控制代码可以代表领域、风格、主题、内容等。这些控制代码是预定好的,在训练的时候把控制代码和相关的文本放在一起进行训练。
LANGUAGE MODELING
先回顾下语言模型
p
(
x
)
=
∏
i
=
1
n
p
(
x
i
∣
x
<
i
)
p(x) = \prod_{i=1}^n p(x_i|x_{<i})
p(x)=i=1∏np(xi∣x<i)
当前SOTA模型(transformer-xl)通过训练一个神经网络
θ
\theta
θ去最小化一个数据集
D
=
{
x
1
,
⋯
,
x
∣
D
∣
}
D=\{x^1,\cdots,x^{|D|}\}
D={x1,⋯,x∣D∣}负对数似然的方法:
L
=
−
∑
k
=
1
∣
D
∣
log
p
θ
(
x
i
k
∣
x
<
i
k
)
\mathcal{L} = -\sum_{k=1}^{|D|} \log p_\theta(x_i^k|x^k_{<i})
L=−k=1∑∣D∣logpθ(xik∣x<ik)
基于语言模型学习的 p θ ( x i ∣ x < i ) p_\theta(x_i|x_{<i}) pθ(xi∣x<i),一个新的长为 m m m的序列 x ~ \tilde x x~可以被依次生成: p θ ( x 0 ) , p θ ( x 1 ∣ x ~ 0 ) , ⋯ , p θ ( x m ∣ x ~ < m ) p_\theta(x_0),p_\theta(x_1|\tilde x_0),\cdots, p_\theta(x_m|\tilde x_{<m}) pθ(x0),pθ(x1∣x~0),⋯,pθ(xm∣x~<m)。
LANGUAGE MODELING WITH CTRL
CTRL是一个条件语言模型,引入了控制编码,基于一个控制编码
c
c
c学习分布
p
(
x
∣
c
)
p(x|c)
p(x∣c)。该分布可以用链式法则来分解,同时用一个考了了控制代码的损失来训练:
p
(
x
∣
c
)
=
∏
i
=
1
n
p
(
x
i
∣
x
<
i
,
c
)
L
=
−
∑
k
=
1
∣
D
∣
log
p
θ
(
x
i
k
∣
x
<
i
k
,
c
k
)
p(x|c) = \prod_{i=1}^n p(x_i|x_{<i,c}) \quad \mathcal{L} = -\sum_{k=1}^{|D|} \log p_\theta(x_i^k|x^k_{<i},c^k)
p(x∣c)=i=1∏np(xi∣x<i,c)L=−k=1∑∣D∣logpθ(xik∣x<ik,ck)
在Transformer中,第一个block的核心是有
k
k
k个头的多头注意力,使用一个causal mask来预测未来的token:
Attention
(
X
,
Y
,
Z
)
=
softmax
(
mask
(
X
Y
T
)
d
)
Z
MultiHead
(
X
,
k
)
=
[
h
1
;
⋯
;
h
k
]
W
o
\begin{aligned} \text{Attention}(X,Y,Z) &= \text{softmax} \left( \frac{\text{mask} (XY^T)}{\sqrt d} \right) Z \\ \text{MultiHead} (X,k) &= [h_1;\cdots;h_k]W_o \\ \end{aligned}
Attention(X,Y,Z)MultiHead(X,k)=softmax(dmask(XYT))Z=[h1;⋯;hk]Wo
其中
h
j
=
Attention
(
X
W
j
1
,
X
W
j
2
,
X
X
W
j
3
)
h_j = \text{Attention}(XW_j^1,XW_j^2,XXW_j^3)
hj=Attention(XWj1,XWj2,XXWj3)。
第二个block的核心是一个ReLU激活函数的前馈网络:
F
F
(
X
)
=
max
(
0
,
X
U
)
V
FF(X) =\max(0,XU)V
FF(X)=max(0,XU)V
每个block都有一个层归一化和残差连接,它们一起生成
X
i
+
1
X_{i+1}
Xi+1:
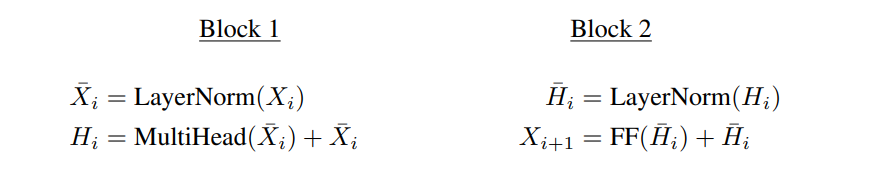
每个token的得分通过最后一层的输出计算:
Scores
(
X
0
)
=
LayerNorm
(
X
l
)
W
v
o
c
a
b
\text{Scores}(X_0) = \text{LayerNorm}(X_l)W_{vocab}
Scores(X0)=LayerNorm(Xl)Wvocab
Data

数据集来源如上,来自每个数据集的数据都加上它的来源。比如来自维基百科的会加上Wikipedia,而有些数据集还会有它的子(控制)代码。比如Reviews还有一个Ratting的控制代码,代表从1到5的评分。
CONTROLLABLE GENERATION
SAMPLING
通常用语言模型生成文本的时候,会采用temperature-controlled方法。
即给定一个温度
T
>
0
T > 0
T>0,和词表中每个token的分数
x
i
∈
R
d
x_i \in \Bbb R^d
xi∈Rd,预测第
i
i
i个token的概率计算为:
p
i
=
exp
(
x
i
/
T
)
∑
j
exp
(
x
j
/
T
)
p_i = \frac{\exp(x_i/T)}{\sum_j \exp(x_j/T)}
pi=∑jexp(xj/T)exp(xi/T)
当
T
→
0
T \rightarrow 0
T→0接近一个贪心分布,增强概率分布上的峰值;而当
T
→
∞
T \rightarrow \infty
T→∞拉平分布使得它更均匀,即其他低概率的token更有可能被选到。
然后这篇工作还限制了从top-k个候选中去生成,而不是从整个词表中生成。但这里并不是一个固定的 k k k值,而是通过设定一个概率阈值 p t p_t pt,然后 k k k个token满足 ∑ i sort ( p i ) > p t \sum_i \text{sort}(p_i) > p_t ∑isort(pi)>pt。如果模型预测下一个词的置信度较高,那么 k k k就会小一点,反之亦然。
当面临有多个概率都较高的候选token时,一个直观的方式是贪婪地选择概率最大的那个,但这样的问题是可能会生成很多重复的token,为了解决这个问题,作者提出了一种新的策略。使得既能近似贪婪地选择得分最高的token,又能对重复token进行一个惩罚。对已经生成的token进行打折(discounting)。
同时在生成时加入了惩罚生成,给定一系列生成过的token g g g,判断下个token的概率分布 p i p_i pi为:
p i = exp ( x i / ( T ⋅ I ( i ∈ g ) ) ∑ j exp ( x j / ( T ⋅ I ( i ∈ g ) ) I ( c ) = θ if c is True else 1 p_i = \frac{\exp(x_i/(T\cdot I(i\in g))}{ \sum_j \exp(x_j/(T\cdot I(i\in g))} \quad I(c) = \theta \,\, \text{if c is True else 1} pi=∑jexp(xj/(T⋅I(i∈g))exp(xi/(T⋅I(i∈g))I(c)=θif c is True else 1
变成了能对重复token进行惩罚的temperature controll。
作者实验 θ ≈ 1.2 \theta \approx 1.2 θ≈1.2可以从贪婪选择和重复惩罚中得到一个不错的折中。但注意这个惩罚只用于推理,不用于训练。
CONTROL CODES
Style by domain 大多数控制代码通过指定一个训练集特定的领域为我们模型设定生成的文本风格。

如上图所示,红色的单词表示控制代码,蓝色的单词表示文本生成中的提示词(prompt)。可以看到控制代码来自训练数据代表特定的领域,指定了生成文本的整体风格。
可以看到,对于同样的prompt,指定不同控制代码时,能生成与控制代码领域相关的风格文本。
More complex control codes 一些额外的控制代码可以加到领域代码中,为了对生成增加更多的约束。

如上图,首先没有蓝色的prompt,表示这个模型可以在没有prompt的情况下,生成特定领域的内容。同时可以看到这些控制代码更复杂一些,除了领域代码(Politics/Horror/Reviews)之外,还加了子控制代码,比如在Reviews中加了不同的评分,5分好评和1分差评,可以生成对应评分的内容。

上图给出了更加复杂的例子,它的领域控制代码是Links,后面还加了更加细粒度的由URL组成的子控制代码。从上面的同样关于president的例子可以看出,有两篇内容,URL中的日期不同,模型生成的文本有学到不同时期对应的president是谁。
Triggering specific tasks 一小部分控制代码与特定任务有关,像问答和翻译。

比如问答任务通过控制代码Questions指定问题,通过A:让模型回答。
SOURCE ATTRIBUTION
领域控制代码可以用于将训练集拆分到不同的互斥子集中。这可以作为检测给定一个序列模型认为属于哪个训练数据集的子集的简单方法。回顾下语言模型学会了一个分布
p
θ
(
x
∣
c
)
p_\theta(x|c)
pθ(x∣c)。通过指定一个控制代码的先验
p
(
c
)
p(c)
p(c),可以直接计算领域的排名:
p
θ
(
c
∣
x
)
∝
p
θ
(
x
∣
c
)
p
(
c
)
p_\theta(c|x) ∝ p_\theta(x|c)p(c)
pθ(c∣x)∝pθ(x∣c)p(c)
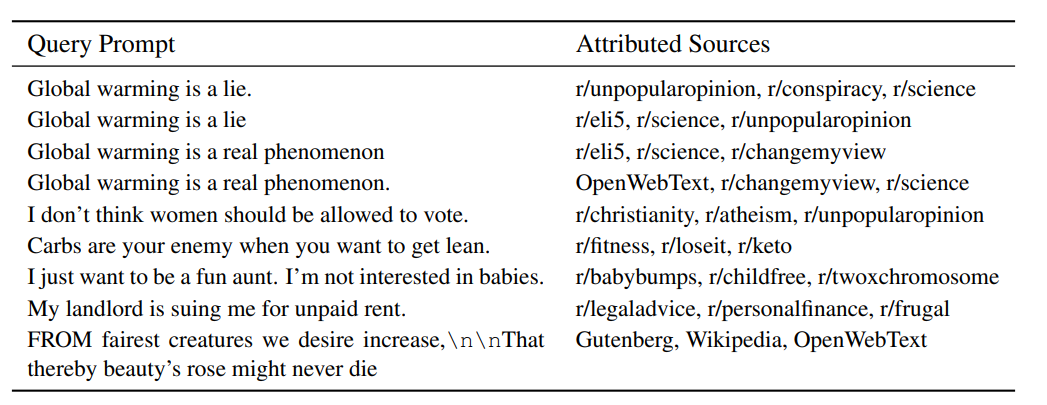
可以一定程度上了解序列和领域之间的关联性,从上图可以看到模型对于prompt的微小变化非常敏感。比如是否有.、大小写、字符变化等。

![[语义分割] DeepLab v2(膨胀卷积、空洞卷积、多尺度信息融合、MSc、ASPP、空洞空间金字塔池化、Step学习率策略、Poly学习率策略)](https://img-blog.csdnimg.cn/526f8d16f5c344dabafa2cb105b7a905.png#pic_center)