- 论文地址:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- 源码地址:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- 复现代码:https://github.com/kazuto1011/deeplab-pytorch
这是一篇于 2016 年发布在 CVPR 上的文章。接着上一篇 DeepLab V1 网络简介,本文对 DeepLab V2 网络进行简单介绍。DeepLab V1 相比 DeepLab V2 就是换了个 Backbone(VGG → ResNet,简单换个 Backbone 就能涨大概 3 个点)然后引入了一个新的模块 ASPP(Atros Spatial Pyramid Pooling,空洞空间金字塔池化),其他的没太大区别。

DeepLab v2 概况
DeepLab v2是一个语义分割模型,旨在对图像进行像素级别的分类,将每个像素分配到其对应的语义类别。它是DeepLab系列的第二个版本,在2016年由Chen等人提出,并取得了令人印象深刻的结果。
DeepLab v2的核心思想是使用深度卷积神经网络(DCNN)来解决语义分割问题,并在此基础上引入了一些关键技术来提高性能。其主要的核心思想包括:
-
空洞卷积(Atrous Convolution):传统的卷积操作具有固定的感受野大小,但在语义分割任务中,需要考虑不同尺度的上下文信息。为了实现这一点,DeepLab v2采用了空洞卷积,也称为扩张卷积。通过在卷积操作中引入可调节的空洞率(或称为膨胀率),可以在不增加计算量的情况下扩大感受野,从而捕捉更广泛的上下文信息。
-
多尺度信息融合:为了进一步提高语义分割的性能,DeepLab v2采用了多尺度信息融合的策略。它通过在不同空洞率下进行多尺度的空洞卷积操作,并将这些不同尺度的特征图融合在一起,从而使模型能够同时利用局部和全局的上下文信息。
-
高分辨率分类器:在语义分割任务中,分辨率较低的特征图可能会导致细小目标的信息丢失。为了解决这个问题,DeepLab v2在空洞卷积后使用了一个全局平均池化层,将特征图的尺寸降低到1x1,然后通过一个额外的高分辨率分类器来对原始尺寸的特征图进行上采样,从而恢复细节信息。
-
条件随机场(CRF)后处理:在语义分割中,由于卷积神经网络的输出是逐像素的分类结果,可能存在一些不连续性和噪声。为了优化分割结果并增强空间连续性,DeepLab v2使用了条件随机场(CRF)后处理步骤,以进一步优化像素标签。
总的来说,DeepLab v2通过引入空洞卷积、多尺度信息融合、高分辨率分类器和CRF后处理等技术,显著提高了语义分割任务的性能,成为当时语义分割领域的重要里程碑之一。
Abstract
在这项工作中,我们使用深度学习来解决语义图像分割任务,并做出了三个主要贡献,经实验证明具有实际价值。
- ①首先,我们强调卷积操作与上采样卷积层的结合,或者称为“空洞卷积”,作为密集预测任务中的强大工具。空洞卷积允许我们明确控制在深度卷积神经网络中计算特征响应的分辨率。它还使我们能够有效地扩大卷积层的感受野,以在不增加参数或计算量的情况下纳入更大的上下文信息。
- ②其次,我们提出了空洞空间金字塔池化(ASPP)来在多个尺度上鲁棒地分割对象。ASPP使用多种采样率和有效视野对输入的卷积特征层进行探测,从而捕捉多个尺度上的对象以及图像上下文。
- ③第三,我们通过结合深度卷积神经网络(DCNNs)和概率图模型的方法来改善对象边界的定位。在 DCNNs 中常用的最大池化和降采样组合实现了不变性,但会影响定位的准确性。我们通过将最终 DCNN 层的响应与全连接的条件随机场(CRF)相结合来克服这一问题,定性和定量地证明了它能够改善定位性能。
我们提出的“DeepLab”系统在 PASCAL VOC-2012 语义图像分割任务上取得了新的最高水平,测试集上达到了 79.7% 的 mIOU,并在其他三个数据集(PASCAL-Context,PASCAL-Person-Part 和 Cityscapes)上取得了进展。我们的所有代码都公开在网上可供使用。
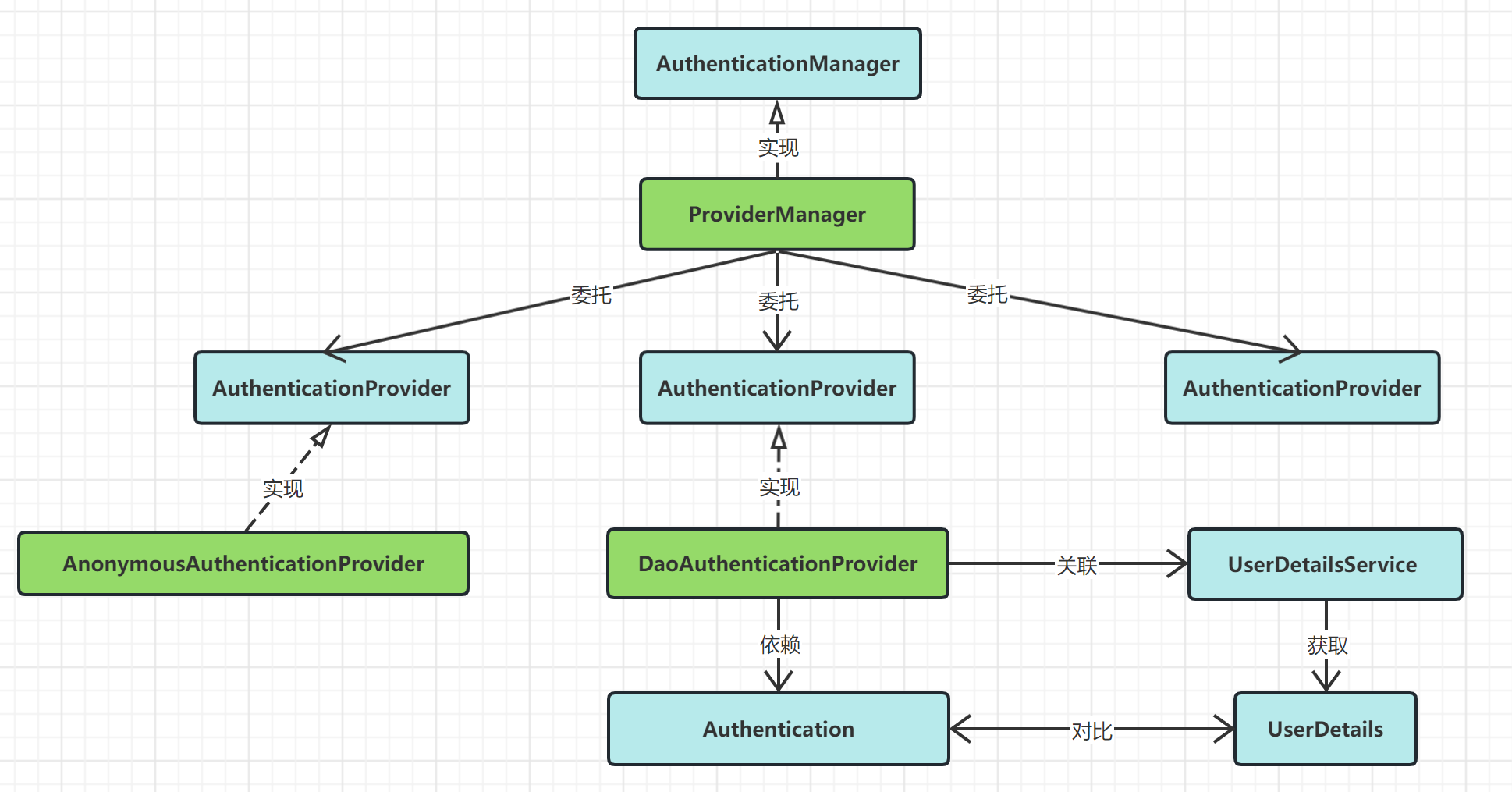
概率图模型(Probabilistic Graphical Model,PGM)是一种用于表示和处理不确定性信息的概率模型。它是概率论和图论的结合,旨在描述变量之间的概率关系,并通过图形的方式展示这些关系。在概率图模型中,节点表示随机变量,边表示随机变量之间的条件依赖关系。
1. CNNs 应用在语义分割任务中存在的问题及解决方案
1.1 CNNs 在语义分割中存在的问题
和上篇文章一样,在文章的引言部分作者提出了DCNNs应用在语义分割任务中遇到的问题。
- 分辨率被降低(主要由于下采样
stride > 1的卷积/池化层导致)—— v1 中已提出 - 目标的多尺度问题
- CNNs 的不变性(Invariance)会降低定位精度 —— v1 中已提出
虽然问题 2 是 v2 中新提出来的问题,但是在 v1 中已经有一个名为 MSc(Multi-Scale) 的trick。
1.2 解决方案
-
分辨率被降低:一般就是将最后的几个 Maxpooling 层的
stride给设置成 1(如果是通过卷积下采样的,比如 ResNet,同样将stride设置成 1 即可),然后在配合使用膨胀卷积。 -
目标多尺度:最容易想到的就是将图像缩放到多个尺度分别通过网络进行推理,最后将多个结果进行融合即可。这样做虽然有用但是计算量太大了。为了解决这个问题,DeepLab V2 中提出了 ASPP 模块(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化),具体结构后面会讲。
-
CNNs 不变性导致定位精度降低:和 DeepLab V1 差不多,还是通过 CRFs 解决,不过这里用的是 fully connected pairwise CRF,相比 V1 里的 fully connected CRF 要更高效点。在 DeepLab V2 中 CRF 涨点就没有 DeepLab V1 猛了,在 DeepLab V1 中大概能提升 4 个点,在 DeepLab V2 中通过 Table4 可以看到大概只能提升 1 个多点了。
pairwise
adv. 对偶(地);成对(双)(地);
adj. 两个两个的;成对的;
2. DeepLab V2 的优势
和 DeepLab V1 中写的一样:
- 速度更快
- 准确率更高(当时的 state-of-the-art)
- 模型结构简单,还是 CNNs 和 CRFs 的联级
3. ASPP(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化)
3.1 ASPP 结构
在 DeepLab V2 中最值得讲的就是 ASPP 模块了,其他的都算不上啥亮点😂。这个 ASPP 模块很像是 DeepLab V1 中 LargeFOV 的升级版(但额外加入了多尺度的特性)。下图是原论文中介绍 ASPP的示意图,就是在 Backbone 输出的 Feature Map 上并联四个分支,每个分支的第一层都是使用的膨胀卷积,但不同的分支使用的膨胀系数不同(即每个分支的感受野不同,从而具有解决目标多尺度的问题)。

由于每个分支的膨胀系数不同,因此每个分支的感受野是不一样的(膨胀系数越大,感受野越大),最终将 4 个分支的结果进行融合就使得 DeepLab v2 具有了解决多尺度的能力。
3.2 DeepLab-ASPP(以 VGG-16 为例)
下图是更加详细的 ASPP 结构(以 VGG-16 为例)。

图中虽然写着是 FC,但 DeepLab 中并没有 FC,所以都是普通卷积或膨胀卷积。
将 Pool5 输出的特征层并联 4 个分支,每个分支分别通过一个
3
×
3
3\times 3
3×3 的膨胀卷积层、
1
×
1
1\times 1
1×1 的卷积层、
1
×
1
1\times 1
1×1 的卷积层(卷积核的个数等于 num_classes)。最后将四个分支的结果进行
⊕
\oplus
⊕ 融合即可。
如果是以 ResNet-101 做为 Backbone 的话,每个分支只有一个 3 × 3 3\times 3 3×3 的膨胀卷积层,卷积核的个数等于
num_classes(根据源码分析得到)。
3.3 ASPP 不同配置
在论文中有给出两个 ASPP 的配置:
- ASPP-S(四个分支膨胀系数分别为
[2,4,8,12]) - ASPP-L(四个分支膨胀系数分别为
[6,12,18,24])
下表是对比 LargeFOV、ASPP-S 以及 ASPP-L 的效果。这里只看 CRF 之前的(不使用 CRF)对比。

从上表可以看到,ASPP-L > ASPP-S >于LargeFOV。因此我们在使用 DeepLab v2 时一般使用 ASPP-L。
4. DeepLab V2 网络结构
这里以 ResNet-101 作为 Backbone 为例,下图是霹雳吧啦WZ根据官方源码绘制的网络结构(不考虑 MSc 多尺度融合)。

需要注意的点❗️
- 在 ResNet 的 Layer3 中的 Bottleneck1 中原本是需要下采样的(
3
×
3
3\times 3
3×3 的卷积层
stride=2),但在 DeepLab V2 中将stride设置为 1,即不在进行下采样。而且 3 × 3 3\times 3 3×3 卷积层全部采用膨胀卷积膨胀系数为 2。 - 在 Layer4 中也是一样,取消了下采样,所有的 3 × 3 3\times 3 3×3 卷积层全部采用膨胀卷积膨胀系数为 4。
- 最后需要注意的是 ASPP 模块,在以 ResNet-101 做为 Backbone 时,每个分支只有一个
3
×
3
3\times 3
3×3 的膨胀卷积层,且卷积核的个数都等于
num_classes。
5. Learning Rate Policy(学习率策略)
5.1 普通的 step 学习率变化策略
学习率策略是指在训练过程中调整学习率的方式。Step策略是一种常见的学习率策略之一。在Step策略中,学习率在训练的特定步骤(epoch或者迭代次数)时会进行调整。Step策略的学习率更新公式为:
学习率 = 初始学习率 × γ ( 当前步骤数 / / s t e p _ s i z e ) l r i = l r i n i t × γ s t e p i / / s t e p _ s i z e \begin{aligned} & 学习率 = 初始学习率 \times \gamma ^{ (当前步骤数 // \mathrm{step\_size})}\\ & \mathrm{lr}_i = \mathrm{lr_{init}} \times \gamma^{\mathrm{step}_i // \mathrm{step\_size}} \end{aligned} 学习率=初始学习率×γ(当前步骤数//step_size)lri=lrinit×γstepi//step_size
其中:
- 初始学习率 l r i n i t \mathrm{lr_{init}} lrinit 是训练开始时设置的学习率
-
γ
\gamma
γ 是一个介于 0 和 1 之间的超参数,用于控制学习率的下降速度
- γ \gamma γ 越大,学习率下降越慢
- γ \gamma γ 越小,学习率下降越快
- 当前步骤数 s t e p i \mathrm{step}_i stepi 是指训练进行到的当前步骤
-
s
t
e
p
s
i
z
e
\mathrm{step_size}
stepsize 是调整学习率的步长:
- s t e p s i z e \mathrm{step_size} stepsize 越大,学习率的调整频率越低,学习率下降速度越慢
- s t e p s i z e \mathrm{step_size} stepsize 越小,学习率的调整频率越高,学习率下降速度越快
注意❗️
- 当当前步骤数 s t e p i \mathrm{step}_i stepi 是调整学习率的步长 s t e p s i z e \mathrm{step_size} stepsize 的倍数时,会进行学习率的调整
- / / // // 表示整除
在 DeepLab v2 中,Poly 学习率策略的默认幂指数(power)值为 0.9。
import matplotlib.pyplot as plt
def step_learning_rate(initial_lr, gamma, step_size, total_steps):
learning_rates = [initial_lr * (gamma ** (step // step_size)) for step in range(total_steps)]
return learning_rates
# 设置初始学习率、gamma、step_size和总迭代次数
initial_lr = 0.1
gamma_lst = [0.01, 0.1, 0.25, 0.5, 0.8]
# step_size_lst = [5, 10, 20, 50]
step_size = 10
total_steps = 100
# 获取学习率变化曲线数据
for gamma in gamma_lst:
learning_rates = step_learning_rate(initial_lr, gamma, step_size, total_steps)
# 绘制学习率变化曲线
plt.plot(range(total_steps), learning_rates, label=f"$gamma={gamma}$")
plt.xlabel('Step')
plt.ylabel('Learning Rate')
plt.title('Step Learning Rate Schedule')
plt.grid(True)
plt.legend()
plt.savefig("step learning rate strategy", dpi=300)


5.2 DeepLab v2 的 poly 学习率变化策略
在 DeepLab V2 中训练时采用的学习率策略叫 poly,相比普通的 step 策略(即每间隔一定步数就降低一次学习率)效果要更好。文中说最高提升了 3.63 个点,真是炼丹大师😂。poly 学习率变化策略公式如下:
l r i = 初始学习率 × ( 1 − 当前迭代次数 总迭代次数 ) 幂指数 = l r i n i t × ( 1 − i t e r i m a x _ i t e r ) p o w e r \begin{aligned} \mathrm{lr}_i & = 初始学习率 × (1 - \frac{当前迭代次数}{总迭代次数}) ^{幂指数}\\ & = \mathrm{lr_{init}} \times (1 - \frac{\mathrm{iter}_i}{\mathrm{max\_iter}})^{\mathrm{power}} \end{aligned} lri=初始学习率×(1−总迭代次数当前迭代次数)幂指数=lrinit×(1−max_iteriteri)power
其中:
- l r i \mathrm{lr}_i lri 表示第 i i i 次迭代的学习率(当前学习率)
- l r i n i t \mathrm{lr_{init}} lrinit 是初始学习率
- i t e r i \mathrm{iter}_i iteri 是当前迭代次数
- m a x _ i t e r \mathrm{max\_iter} max_iter 是总迭代次数
-
p
o
w
e
r
\mathrm{power}
power 是幂指数:幂指数是一个超参数,用于控制学习率下降的速度。通常情况下:
- 它可以设为 1,表示线性减小学习率
- 或者设为其他小于 1 的值,以实现更激进的学习率下降
- p o w e r \mathrm{power} power 越小,学习率下降越慢
- p o w e r \mathrm{power} power 越大,学习率下降越快
import matplotlib.pyplot as plt
def poly_learning_rate(initial_lr, power, total_steps):
learning_rates = [initial_lr * (1 - step / total_steps) ** power for step in range(total_steps)]
return learning_rates
# 设置初始学习率、幂指数和总迭代次数
initial_lr = 0.1
power_lst = [1.0, 0.9, 0.5, 0.1]
total_steps = 100
# 获取学习率变化曲线数据
for power in power_lst:
learning_rates = poly_learning_rate(initial_lr, power, total_steps)
# 绘制学习率变化曲线
plt.plot(range(total_steps), learning_rates, label=f"$power={power}$")
plt.xlabel('Step')
plt.ylabel('Learning Rate')
plt.title('Poly Learning Rate Schedule')
plt.legend()
plt.grid(True)
plt.savefig("poly learning rate strategy", dpi=300)

5.3 Step v.s. Poly 学习率策略效果对比

从上表数据可以看到,Poly 学习率变化策略对 mean IoU 的提升较为明显!
6. 消融实验
下表是原论文中给出的一些消融实验对比:

我们评估了每个因素以及 LargeFOV 和 Atrous Spatial Pyramid Pooling (ASPP) 对验证集性能的影响。将 ResNet-101 用于替代 VGG-16 显著提高了 DeepLab 的性能(例如,我们最简单的基于 ResNet-101 的模型达到了 68.72%,而我们基于 DeepLab-LargeFOV VGG-16 的变体在 CRF 之前为 65.76%)。多尺度融合 [ 17 ] ^{[17]} [17]带来额外的 2.55% 的改进,而在 MS-COCO 上预训练模型又带来了额外的 2.01% 的提升。训练过程中的数据增强是有效的(大约提升了 1.6%)。采用 LargeFOV(在 ResNet 的顶部添加一个具有 3 × 3 3\times 3 3×3 的内核和
r = 12的空洞卷积层)是有益的(大约提升了 0.6%)。而通过 Atrous Spatial Pyramid Pooling (ASPP) 进一步提高了 0.8%。通过密集条件随机场(dense CRF)后处理我们的最佳模型,性能达到了 77.69%。
- MSC:表示多尺度输入,先将图像缩放到 0.5、0.7 和 1.0 三个尺度,然后分别送入网络预测得到 score maps,最后融合这三个 score maps(对每个位置取三个 score maps 的最大值,而非我们常见的 ⊕ \oplus ⊕) —— 提升较大!
- COCO:是否使用在 MS-COCO 上预训练的模型 —— 提升较大!
- Aug:代表数据增强,这里就是对输入的图片在 0.5 到 1.5 之间进行随机缩放 —— 一般提升!
- LargeFOV 是在 DeepLab V1 中讲到过的结构 —— 提升不如在 v1 时的表现!
- ASPP 前面讲过了 —— 一般提升!
- CRF 前面也提到过了 —— 一般提升!
知识来源
- https://blog.csdn.net/qq_37541097/article/details/121752679
- https://www.bilibili.com/video/BV1gP4y1G7TC