聚类任务
聚类任务是一种无监督学习任务,其目的是将一组数据点划分成若干个类别或簇,使得同一个簇内的数据点之间的相似度尽可能高,而不同簇之间的相似度尽可能低。聚类算法可以帮助我们发现数据中的内在结构和模式,发现异常点和离群值,简化数据表示,以及为进一步的分析提供基础。聚类任务在现实世界中有很多应用场景,以下是其中的一些例子:
-
市场细分:聚类可以帮助将市场分成不同的细分市场,以便更好地针对消费者需求制定营销策略。
-
图像分析:聚类可以用于图像分析,例如将相似的图像分组。
-
模式识别:聚类可以用于发现数据中的模式和关系,例如在医疗领域中,可以使用聚类来发现疾病之间的关系。
-
推荐系统:聚类可以用于推荐系统中,以将用户分组并向他们推荐相似的产品或服务。
K-Means算法
K-Means是一种基于聚类的无监督机器学习算法,其目的是将一组数据点分为k个不同的簇,使得每个数据点与其所属簇的中心点(也称质心)的距离最小化。以下是K-Means的工作原理:
-
初始化:随机选择k个数据点作为初始质心。
-
分配:对每个数据点,计算其与每个质心的距离,并将其分配给距离最近的质心所代表的簇。
-
重新计算质心:对于每个簇,重新计算其质心位置,即将该簇中所有数据点的坐标求平均。
-
重复执行第2,3步,直到所有数据点的簇分配不再改变或达到预设的最大迭代次数为止。
下面是用K-Means算法完成聚类的简单Demo,下面的demo中K设置为2.
from sklearn.cluster import KMeans
import numpy as np
# create some sample data
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
# create a KMeans object with 2 clusters
kmeans = KMeans(n_clusters=2, random_state=0)
# fit the KMeans object to the data
kmeans.fit(X)
# print the centroids of the two clusters
print(kmeans.cluster_centers_)
# predict the cluster labels for the data points
labels = kmeans.predict(X)
# print the predicted cluster labels for the data points
print(labels)执行结果:cluster_centers_:[[1. 2.][4. 2.]], labels:[0 0 0 1 1 1]
上面的Demo中使用到KMeans函数,KMeans函数是一种聚类分析算法,用于将数据集分成多个簇。其主要作用是将相似的数据点分到同一个簇中,同时将不同的数据点分到不同的簇中。KMeans算法通过迭代寻找最优的聚类结果,可以对数据进行分组、分类和聚类分析。该函数包含多个输入参数,各个参数含义如下:
-
n_clusters:聚类的数量(簇的个数),即K值。默认值为8。如果知道数据的实际类别数目,可以将其设置为该数目;否则,可以通过手动设置不同的聚类数量来寻找最佳解。 -
init:初始化质心的方法。默认为"k-means++",表示使用一种改进的贪心算法来选取初始质心。也可以设置为随机选择初始质心的"random"方法。 -
max_iter:最大迭代次数。默认值为300。当质心移动的距离小于阈值或达到最大迭代次数时,算法停止。 -
tol:质心移动的阈值。默认值为1e-4。当质心移动的距离小于该阈值时,算法停止。 -
n_init:随机初始化的次数。默认值为10。由于KMeans算法易受初始质心的影响,因此可以通过多次运行算法并选择最好的结果来减少随机性的影响。 -
algorithm:KMeans算法实现的方式。默认为"auto",表示由算法自动选择最佳的实现方式("full"表示使用标准的KMeans算法,"elkan"表示使用改进的Elkan算法)。对于大规模数据集,建议使用"elkan"实现方式。
上面的Demo例子是对List数据进行聚类,接下来看看如何使用K-means方法对足球队进行聚类,下面的例子中读取了csv文件中的原始数据,csv文件中存放了不同球队在三次比赛中的排名。
# coding: utf-8
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
# 输入数据
data = pd.read_csv('./kmeans/data.csv', encoding='gbk')
train_x = data[["2019年国际排名", "2018世界杯", "2015亚洲杯"]]
kmeans = KMeans(n_clusters=3)
# 规范化到[0,1]空间
min_max_scaler = preprocessing.MinMaxScaler()
train_x = min_max_scaler.fit_transform(train_x)
# kmeans算法
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x)
# 合并聚类结果,插入到原数据中
result = pd.concat((data, pd.DataFrame(predict_y)), axis=1)
result.rename({0: u'聚类'}, axis=1, inplace=True)
print(result)采用K-means方法进行聚类,假设K=3,聚类后的结果如下所示,可以看到把球队分到了0,1,2三种不同类型中。

对图像进行聚类
上面的例子是对数据进行聚类,下面看看如何对图像进行聚类,下面的Demo例子中将weixin登陆的图标按不同像素下的颜色分成了2类。
# -*- coding: utf-8 -*-
# 使用K-means对图像进行聚类,显示分割标识的可视化
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing
# 加载图像,并对数据进行规范化
def load_data(filePath):
# 读文件
f = open(filePath, 'rb')
data = []
# 得到图像的像素值
img = image.open(f)
# 得到图像尺寸
width, height = img.size
for x in range(width):
for y in range(height):
# 得到点(x,y)的三个通道值
c1, c2, c3 = img.getpixel((x, y))
data.append([c1, c2, c3])
f.close()
# 采用Min-Max规范化
mm = preprocessing.MinMaxScaler()
data = mm.fit_transform(data)
return np.asarray(data), width, height
# 加载图像,得到规范化的结果img,以及图像尺寸
img, width, height = load_data('./kmeans/weixin.jpg')
# 用K-Means对图像进行2聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(img)
label = kmeans.predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像pic_mark,用来保存图像聚类的结果,并设置不同的灰度值
pic_mark = image.new("L", (width, height))
for x in range(width):
for y in range(height):
# 根据类别设置图像灰度, 类别0 灰度值为255, 类别1 灰度值为127
pic_mark.putpixel((x, y), int(256 / (label[x][y] + 1)) - 1)
pic_mark.save("./kmeans/weixin_mark1.jpg", "JPEG")下图中第一张图是原图,第二张图是分类K=2的结果。可以看到,因为只进行了2种类型区分,新生成的图片中,纯白色是原图中深蓝色的代表,黑灰色是原图中白亮色的代表。说明聚类正确。



图三是K=16的分类结果,当分类K=16时,和原图就很接近了,K=16的分类代码细节如下所示:
# -*- coding: utf-8 -*-
# 使用K-means对图像进行聚类,并显示聚类压缩后的图像
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.image as mpimg
# 加载图像,并对数据进行规范化
def load_data(filePath):
# 读文件
f = open(filePath, 'rb')
data = []
# 得到图像的像素值
img = image.open(f)
# 得到图像尺寸
width, height = img.size
for x in range(width):
for y in range(height):
# 得到点(x,y)的三个通道值
c1, c2, c3 = img.getpixel((x, y))
data.append([(c1 + 1) / 256.0, (c2 + 1) / 256.0, (c3 + 1) / 256.0])
f.close()
return np.asarray(data), width, height
# 加载图像,得到规范化的结果imgData,以及图像尺寸
img, width, height = load_data('./kmeans/weixin.jpg')
# 用K-Means对图像进行16聚类
kmeans = KMeans(n_clusters=16)
label = kmeans.fit_predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像img,用来保存图像聚类压缩后的结果
img = image.new('RGB', (width, height))
for x in range(width):
for y in range(height):
c1 = kmeans.cluster_centers_[label[x, y], 0]
c2 = kmeans.cluster_centers_[label[x, y], 1]
c3 = kmeans.cluster_centers_[label[x, y], 2]
img.putpixel((x, y),
(int(c1 * 256) - 1, int(c2 * 256) - 1, int(c3 * 256) - 1))
img.save('./kmeans/weixin_new.jpg')上面介绍了如何使用K-Means算法完成文本类或者图片类聚类任务,在实际项目中,K-Means算法应用非常广泛,主要应用在如下的业务场景中。
-
市场营销:K-Means算法可以对市场消费者进行分类,以便公司更好地了解他们的需求和行为,制定更有效的营销策略。
-
图像处理:K-Means算法可以用于对图像像素进行聚类,以实现图像压缩和图像分割等功能。
-
自然语言处理:K-Means算法可以用于对文本数据进行聚类,以实现语义分析和文本分类等功能。
-
生物信息学:K-Means算法可以用于对生物数据进行聚类,以实现基因分类和蛋白质分类等功能。
-
金融领域:K-Means算法可以用于对金融数据进行聚类,以实现风险评估和资产管理等功能。
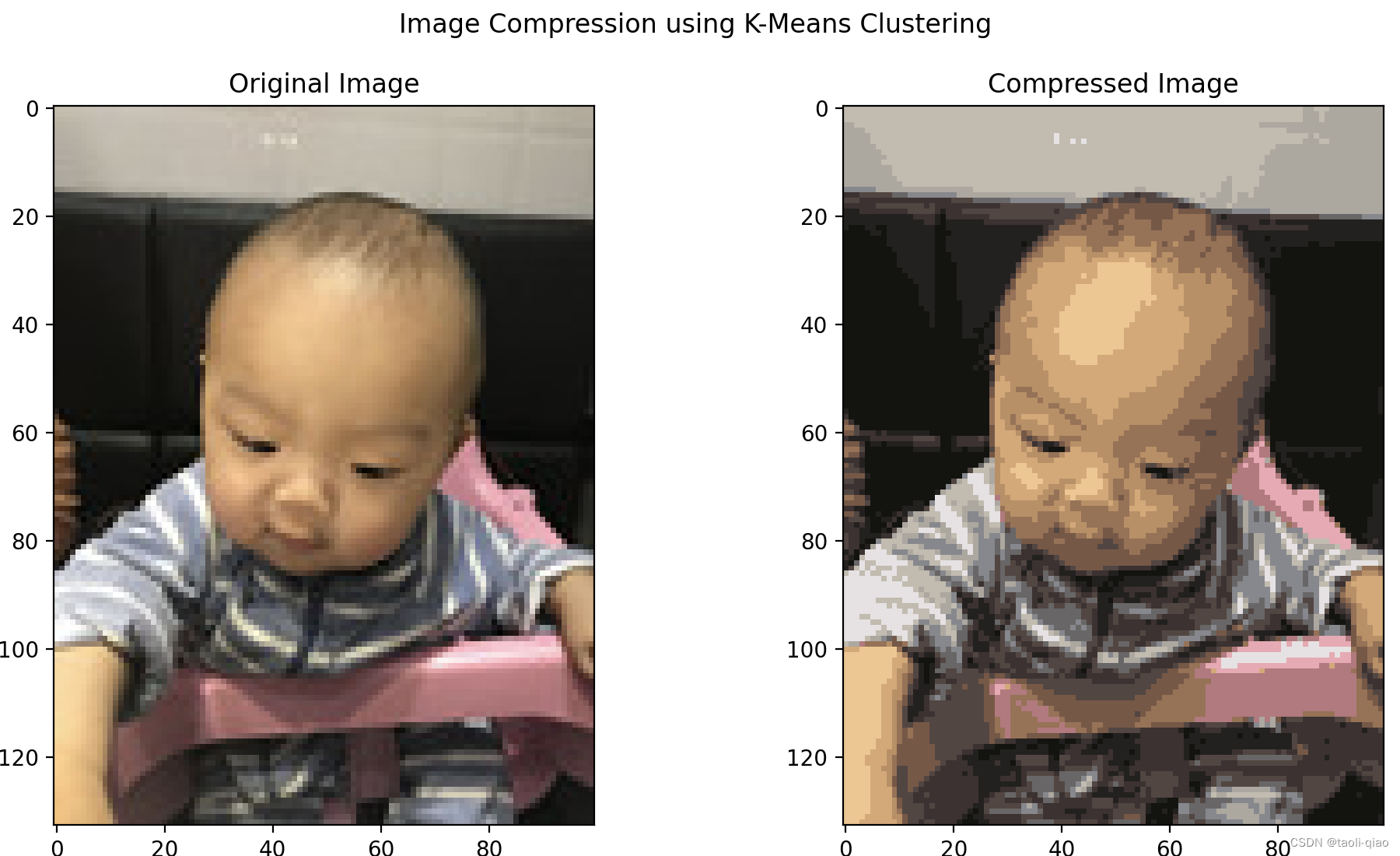
上面提到K-Means算法可以对图像像素进行聚类,以实现图像压缩的功能,下面的例子中就采用K-Means算法对图片像素进行聚类,从而实现压缩的效果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from PIL import Image
# 加载图片
img = Image.open('./kmeans/baby.jpg')
img_data = np.array(img)
# 将三维的图片数组变成二维的像素点数组
pixels = img_data.reshape(
(img_data.shape[0] * img_data.shape[1], img_data.shape[2]))
# 使用K-Means聚类算法对像素点进行聚类
kmeans = KMeans(n_clusters=16, random_state=0)
labels = kmeans.fit_predict(pixels)
# 将每个像素点替换为所属聚类的中心点
new_pixels = kmeans.cluster_centers_[labels]
# 将一维的像素点数组还原为图片数组的形式
new_img_data = new_pixels.reshape(
(img_data.shape[0], img_data.shape[1], img_data.shape[2]))
# 显示原始图片和压缩后的图片
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
fig.suptitle('Image Compression using K-Means Clustering')
ax1.set_title('Original Image')
ax1.imshow(img_data)
ax2.set_title('Compressed Image')
ax2.imshow(new_img_data.astype('uint8'))
plt.show()原图和压缩后的图片结果如下所示: