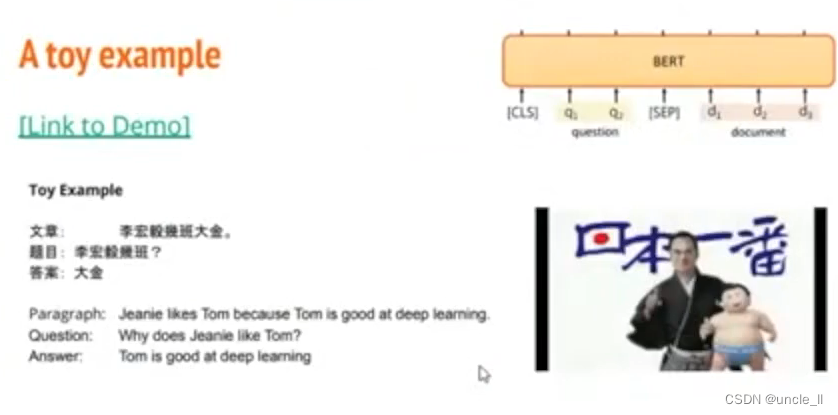
模型BERT
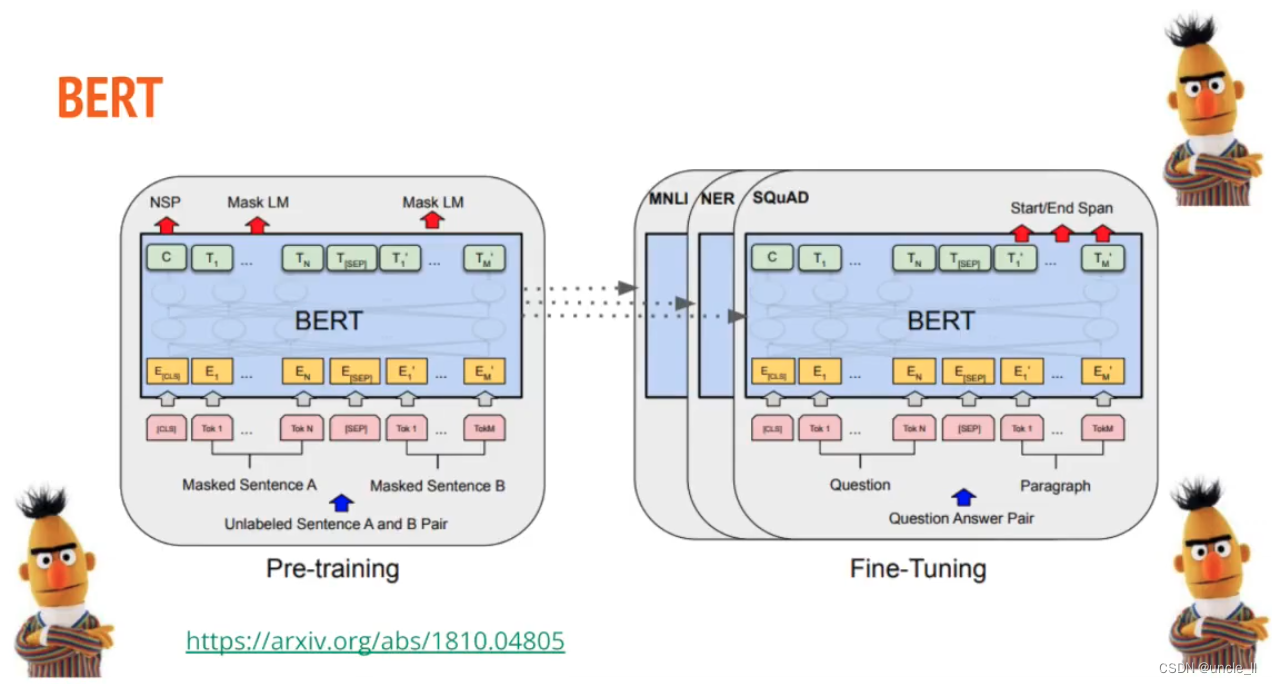
任务:提取问题和答案

问题的起始位置和结束位置。
数据集

数据集 DRCD+ODSQA




先分词,然后tokenize
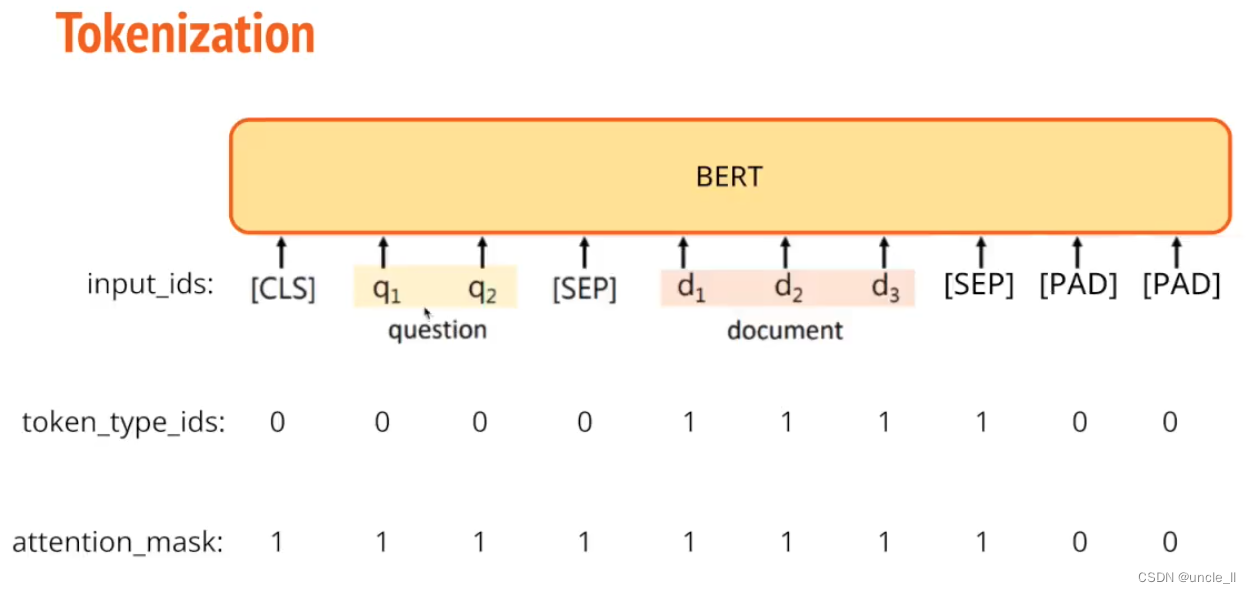

文章长度是不同的,bert的token的长度有限制,一般是512, self-attention的计算量是
O
(
n
2
)
O(n^2)
O(n2),所以无法将长的整篇文章送进去处理。
Train

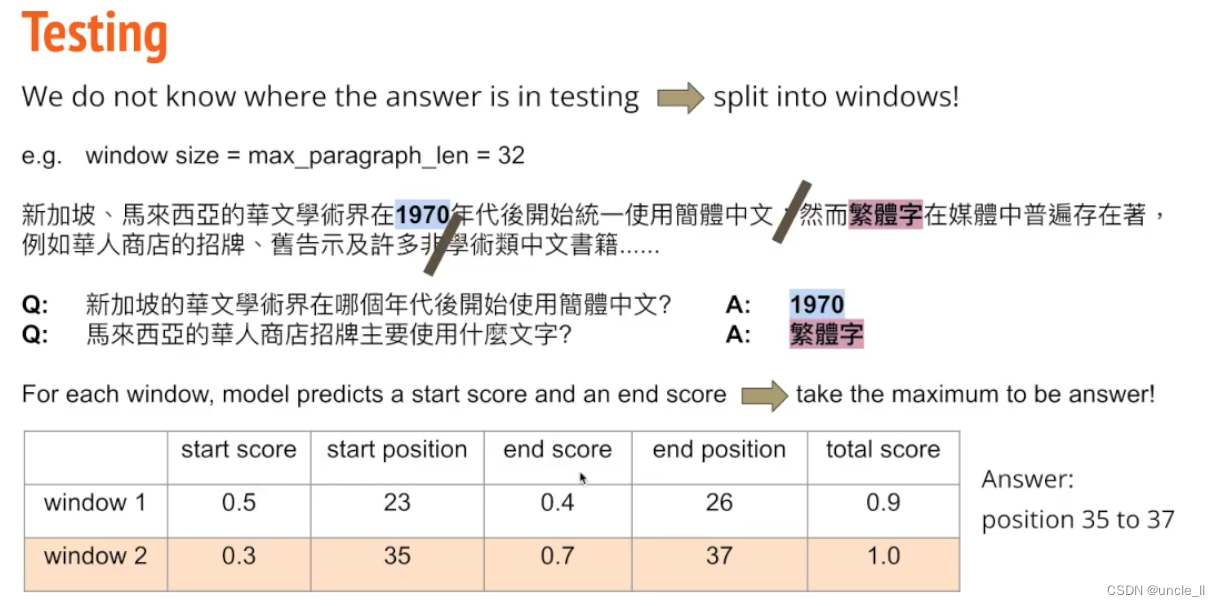
以正确答案为中心,以固定长度的windows去找问题。关键字,答案一般在关键字附近,在答案的附近画一个window,越大越好。然后将这些片段进行tokenizer,再去训练。
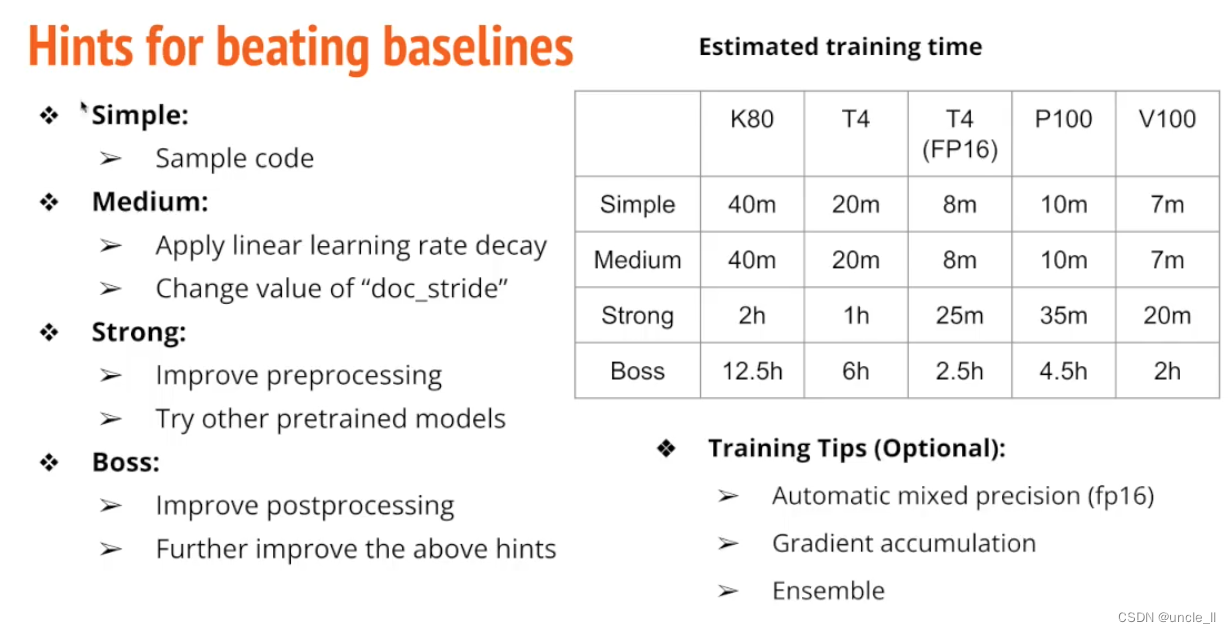
Hints

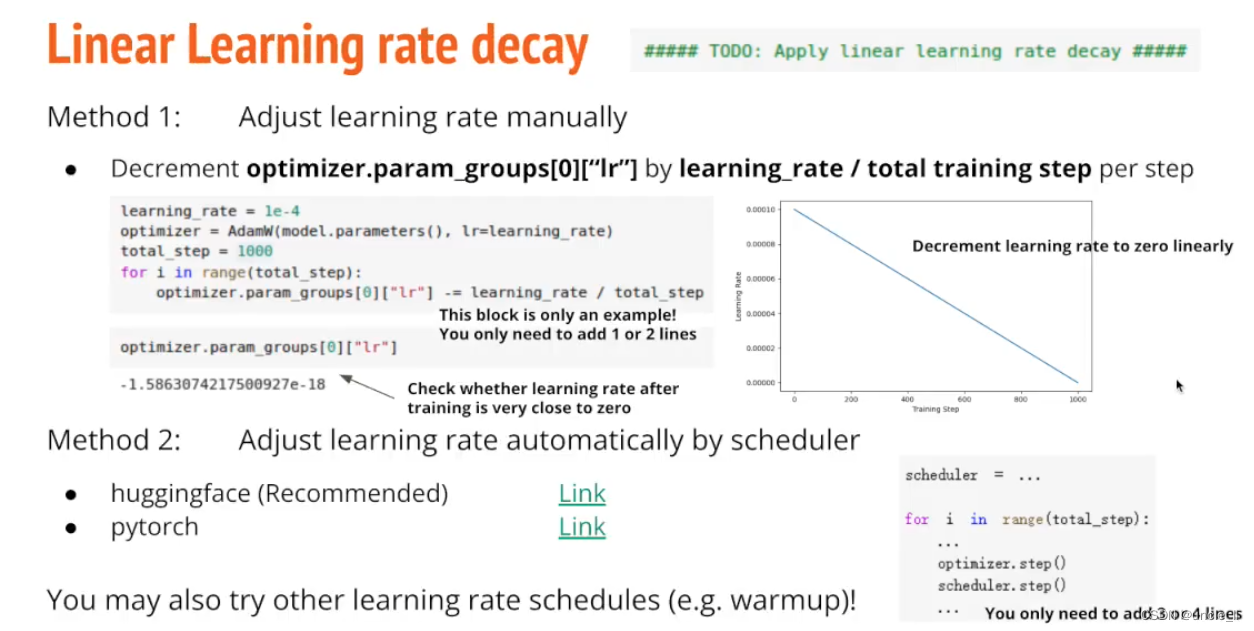
- Linear Learning rate decay
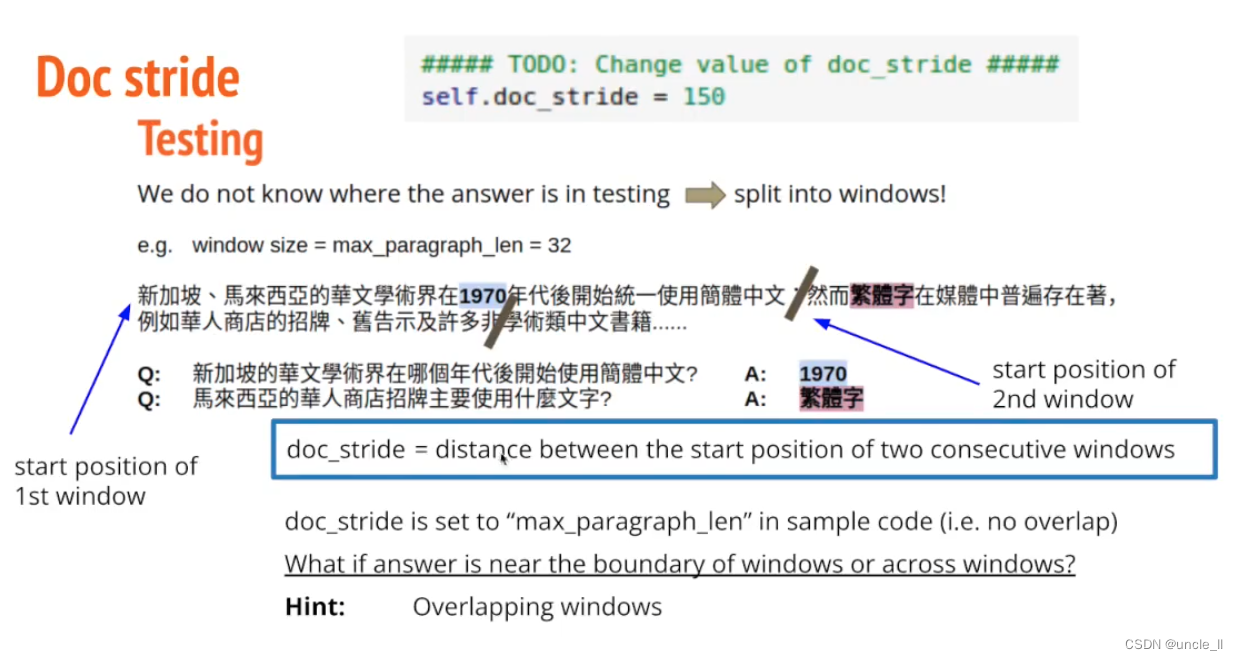
overlapping window, 因为分割可能会看不到,重叠一些部分。 修改doc stride参数。
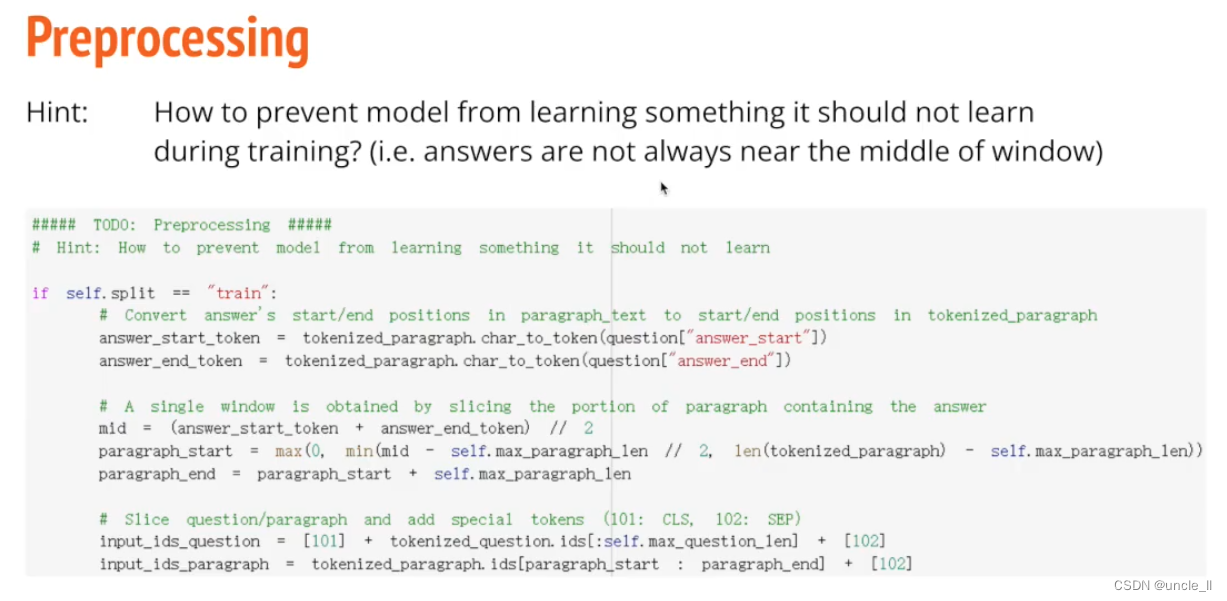
正确答案不一定是在窗户正中心。
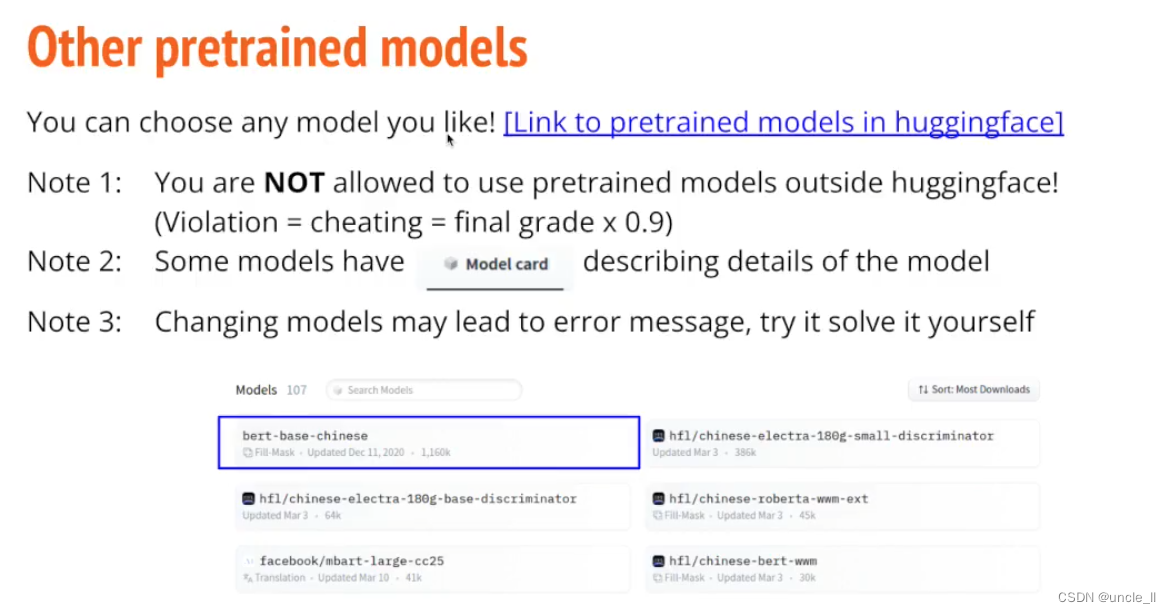
不同的预训练模型,建议使用中文预训练模型。
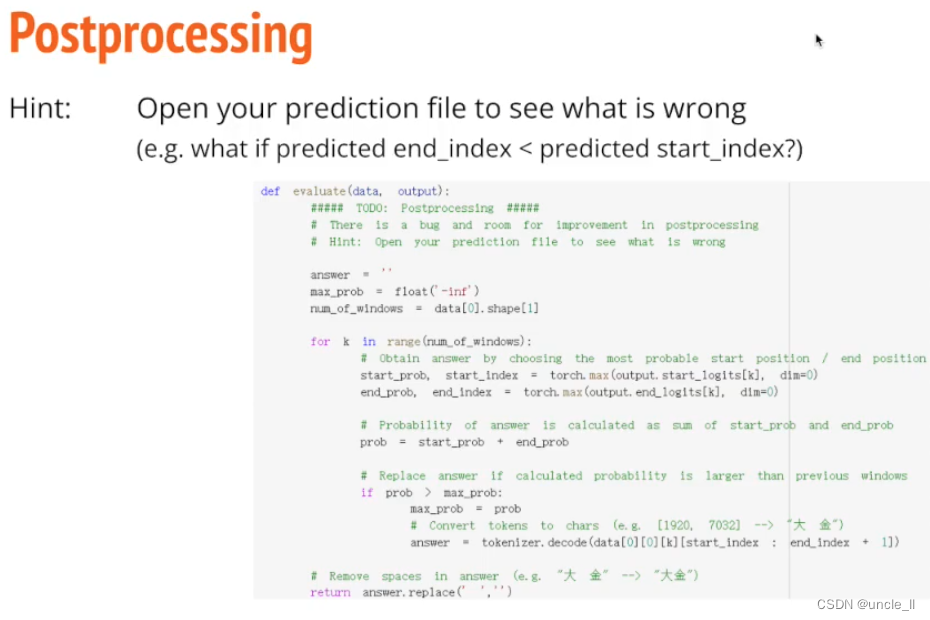


自动混合精度,有的时候不需要那么高的精度Float32,仅部分卡支持,以加速训练。
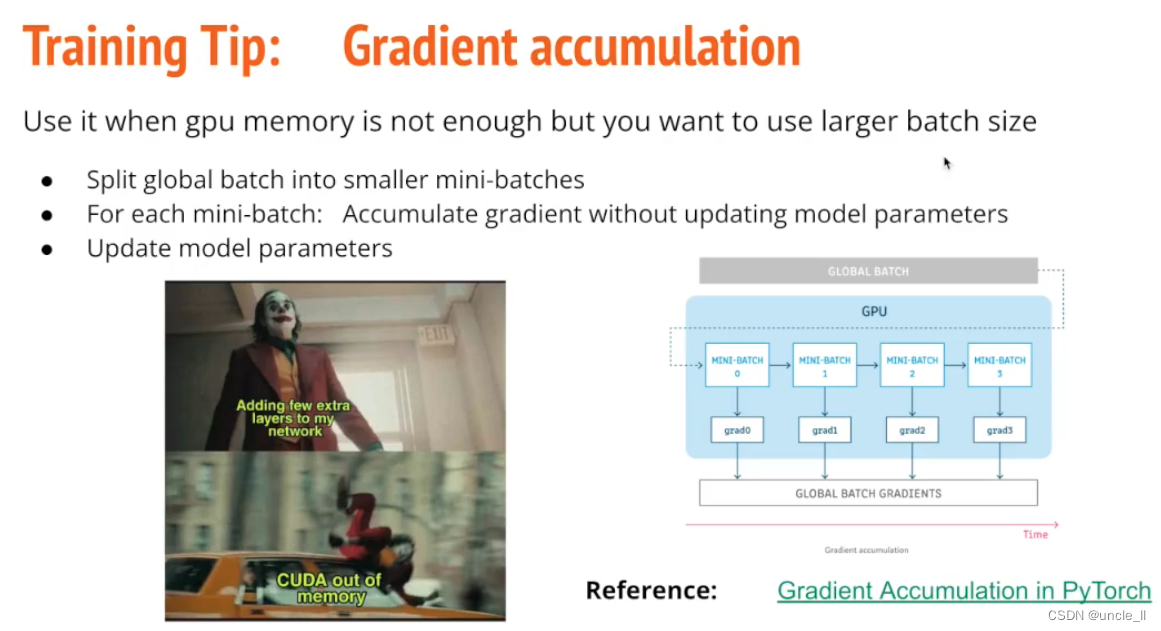
如果GPU内存不够的话,可以使用Gradient accumulation,累计参数一次更新。

Kaggle项目

套件:pip install transformers