使用requests获取当当网榜单中的图书数据
- 使用到的库
- 概述
- 发送请求
- xpath解析提取数据
- tips
- 完整代码
使用到的库
- requests
- etree
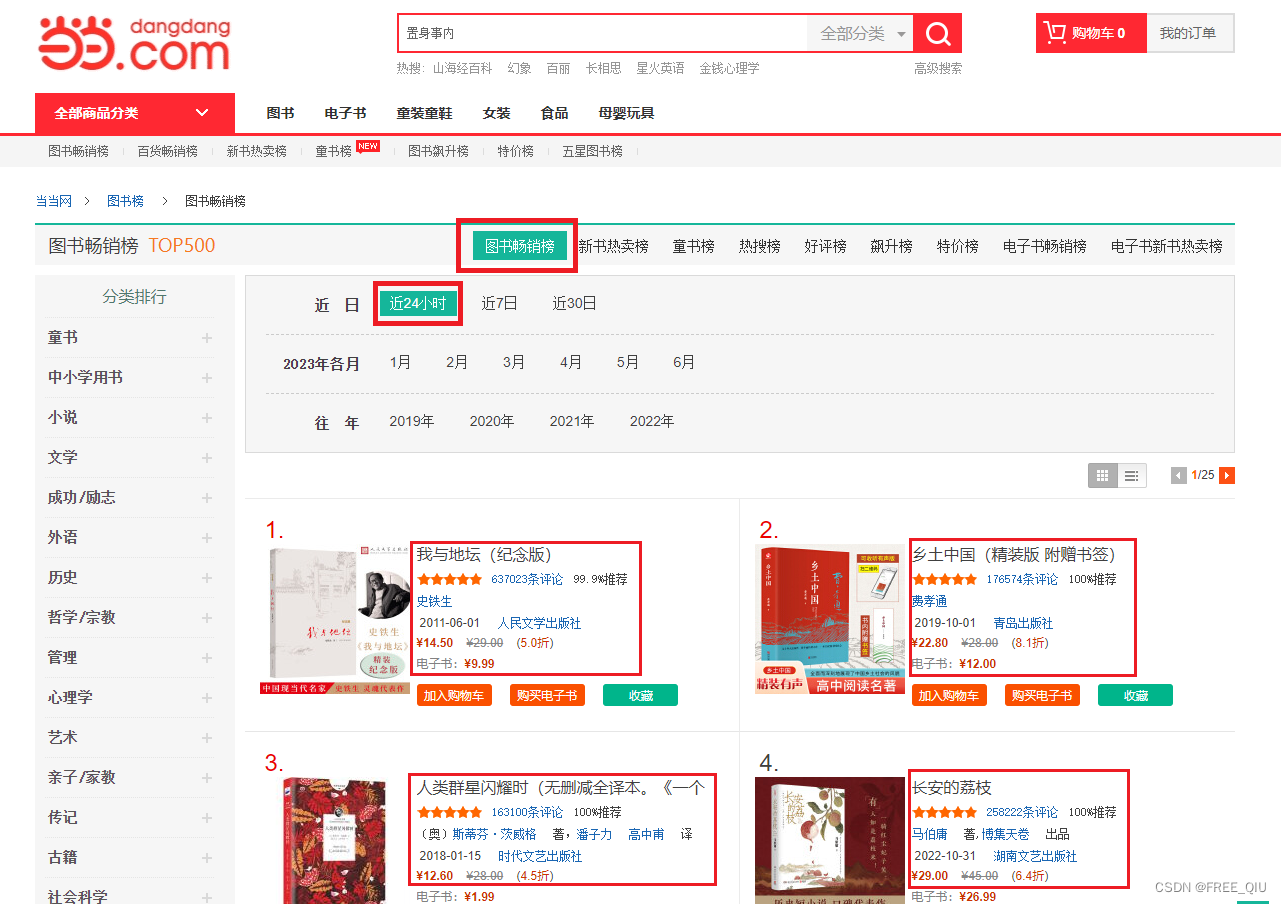
概述
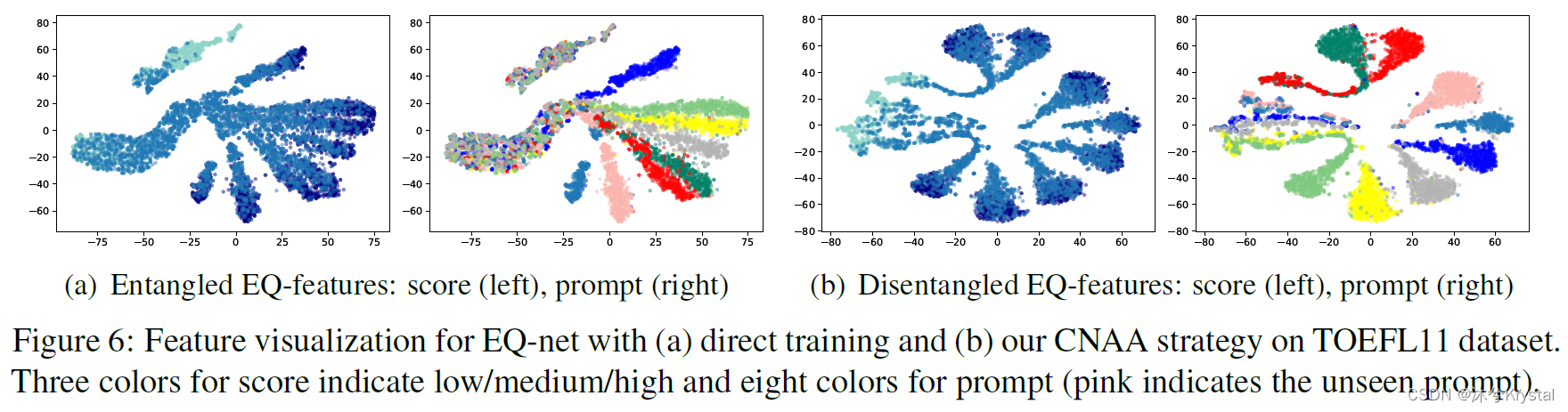
主要抓取目标为
- 当当网图书畅销榜中近24小时畅销的图书信息
主要提取的数据为
- 排名、书名、评论数、推荐度、作者信息、出版时间、出版社、折扣价、原价、折扣率、电子书价格、详情页链接
发送请求
# 设置cookie
cookies = {
'ddscreen': '2',
'dest_area': 'country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0',
'__permanent_id': '20230727111738725280659109780638954',
'__visit_id': '20230727111738728252759597714636934',
'__out_refer': '',
'__trace_id': '20230727111738729253018287016217767'
}
# 设置请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'ddscreen=2; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20230311201918630282239304091816610; __visit_id=20230613202543057355948286659409526; __out_refer=; __rpm=...1686659146436%7C...1686659147726; __trace_id=20230613202548496123352493475398790',
'Pragma': 'no-cache',
'Referer': 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-2-1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
...
# 发送请求
response = requests.get(url, cookies=cookies, headers=headers, verify=False)
xpath解析提取数据
- 本案例中主要使用Xpath来提取数据,也可以使用其他方法提取数据
# 使用XPATH解析提取数据
lists = html.xpath('//div//ul[@class="bang_list clearfix bang_list_mode"]//li')
# 提取:排名、书名、评论数、推荐度、作者信息、出版时间、出版社、折扣价、原价、折扣率、电子书价格
for li in lists:
book_info = {
"排名": "".join(li.xpath('./div[1]/text()')).replace(".", ""),
"书名": "".join(li.xpath('.//div[3]/a/@title')),
"评论数": "".join(li.xpath('.//div[4]/a/text()')).replace("条评论", ""),
"推荐度": "".join(li.xpath('.//div[4]/span/text()')).replace("推荐", ""),
"作者信息": "".join(li.xpath('.//div[5]/a/text()')),
"出版时间": "".join(li.xpath('.//div[6]/span/text()')),
"出版社": "".join(li.xpath('.//div[6]/a/text()')),
"折扣价": "".join(li.xpath('.//div[@class="price"]//span[@class="price_n"]/text()')),
"原价": "".join(li.xpath('.//div[@class="price"]//span[@class="price_r"]/text()')),
"折扣率": "".join(li.xpath('.//div[@class="price"]//span[@class="price_s"]/text()')),
"电子书价格": "".join(li.xpath('.//div[@class="price"]//p[@class="price_e"]/span/text()')),
"详情页链接": "".join(li.xpath('.//div[@class="name"]/a/@href'))
}
tips
- 提取到的数据可变量直接接收然后存放到列表中,如下
# ranking = "".join(li.xpath('./div[1]/text()')).replace(".", "") # name = "".join(li.xpath('.//div[3]/a/@title')) # comments = "".join(li.xpath('.//div[4]/a/text()')).replace("条评论", "") # recommend_level = "".join(li.xpath('.//div[4]/span/text()')).replace("推荐", "") # author = "".join(li.xpath('.//div[5]/a/text()')) # publish_time = "".join(li.xpath('.//div[6]/span/text()')) # press = "".join(li.xpath('.//div[6]/a/text()')) # discount_price = "".join(li.xpath('.//div[@class="price"]//span[@class="price_n"]/text()')) # original_price = "".join(li.xpath('.//div[@class="price"]//span[@class="price_r"]/text()')) # discount_rate = "".join(li.xpath('.//div[@class="price"]//span[@class="price_s"]/text()')) # ebook_Price = "".join(li.xpath('.//div[@class="price"]//p[@class="price_e"]/span/text()')) # details_url = "".join(li.xpath('.//div[@class="name"]/a/@href')) # # result_list = [ranking, name, comments, recommend_level, author, publish_time, press, discount_price, original_price, discount_rate, ebook_Price, details_url]
完整代码
import requests
from lxml import etree
# 获取当当网数据
def crawl_dd():
# 设置cookie
cookies = {
'ddscreen': '2',
'dest_area': 'country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0',
'__permanent_id': '20230727111738725280659109780638954',
'__visit_id': '20230727111738728252759597714636934',
'__out_refer': '',
'__trace_id': '20230727111738729253018287016217767'
}
# 设置请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Referer': 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-2-1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
# url地址
# url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
# 抓取指定页数的数据
for i in range(1, 5):
# 请求地址
url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-{i}'
# 发送请求
response = requests.get(url, cookies=cookies, headers=headers, verify=False)
# 将网页响应结果转换为文本
content = response.text
# 解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象
html = etree.HTML(content)
# 使用XPATH解析提取数据
lists = html.xpath('//div//ul[@class="bang_list clearfix bang_list_mode"]//li')
# 提取:排名、书名、评论数、推荐度、作者信息、出版时间、出版社、折扣价、原价、折扣率、电子书价格
for li in lists:
book_info = {
"排名": "".join(li.xpath('./div[1]/text()')).replace(".", ""),
"书名": "".join(li.xpath('.//div[3]/a/@title')),
"评论数": "".join(li.xpath('.//div[4]/a/text()')).replace("条评论", ""),
"推荐度": "".join(li.xpath('.//div[4]/span/text()')).replace("推荐", ""),
"作者信息": "".join(li.xpath('.//div[5]/a/text()')),
"出版时间": "".join(li.xpath('.//div[6]/span/text()')),
"出版社": "".join(li.xpath('.//div[6]/a/text()')),
"折扣价": "".join(li.xpath('.//div[@class="price"]//span[@class="price_n"]/text()')),
"原价": "".join(li.xpath('.//div[@class="price"]//span[@class="price_r"]/text()')),
"折扣率": "".join(li.xpath('.//div[@class="price"]//span[@class="price_s"]/text()')),
"电子书价格": "".join(li.xpath('.//div[@class="price"]//p[@class="price_e"]/span/text()')),
"详情页链接": "".join(li.xpath('.//div[@class="name"]/a/@href'))
}
# 测试输出
print(book_info)
if __name__ == '__main__':
crawl_dd()