目录
- 前言
- 一、调度问题介绍
- 二、案例分析
- 2-1、护士调度问题
- 2-2、作业车间调度问题
- 三、知识库
- 3-1、collection
- 3-2、CpModel().AddNoOverlap()
- 3-3、CpModel().AddMaxEquality()
- 3-4、cp_model.CpModel().NewIntVar()
- 3-5、cp_model.CpModel().NewIntervalVar
- 总结
前言
调度问题是一类重要且常见的组合优化问题,涉及在有限资源和时间约束下,合理地安排任务或活动的顺序和时间,以优化某种目标函数。调度问题广泛应用于生产制造、物流运输、项目管理、计算机任务调度、作业调度等领域。一、调度问题介绍
调度问题是一类重要且常见的组合优化问题,涉及在有限资源和时间约束下,合理地安排任务或活动的顺序和时间,以优化某种目标函数。调度问题广泛应用于生产制造、物流运输、项目管理、计算机任务调度、作业调度等领域。
常见的调度问题包括:
- 作业车间调度问题(Job Shop Scheduling Problem):给定一组作业和一组可并行执行的机器,每个作业需要在不同的机器上按照特定的顺序完成。目标是最小化完成所有作业所需的时间或最大化生产效率。
- 流水线调度问题(Flow Shop Scheduling Problem):类似于作业车间调度问题,但在流水线调度问题中,每个作业需要按照相同的顺序通过一组机器。
- 车辆路径问题(Vehicle Routing Problem):给定一组客户点和一组配送车辆,车辆需要从一个中心出发,访问每个客户点,并返回中心,以最小化总配送成本或最小化车辆的总行驶距离。
- 资源约束项目调度问题(Resource-Constrained Project Scheduling Problem):在项目中有多个任务,每个任务需要特定的资源和时间才能完成。目标是在满足资源和时间约束的情况下,最小化项目的总工期或最大化资源利用率。
- 多处理器任务调度问题(Multiprocessor Task Scheduling Problem):将一组任务分配给多个处理器,并尽量平衡负载,以最小化任务完成时间或最大化处理器利用率。
- 工人任务调度问题(Job Allocation Problem):在工人和任务之间建立对应关系,以最大化完成任务的总价值或最小化工人的总工作时间。
解决调度问题的方法通常包括贪心算法、启发式算法、精确的优化算法(如整数线性规划和约束编程)以及元启发式算法(如遗传算法和模拟退火算法)。调度问题的复杂性通常取决于任务和资源之间的约束条件,有些调度问题是 NP-hard 问题,意味着找到最优解可能需要指数级的时间。
二、案例分析
2-1、护士调度问题
护士调度问题: 员工轮班多次轮班的组织需要为每天的轮班安排足够的工作器。通常,时间表会有一些限制,例如“任何员工都不应在一个班次中连续两次班次”。查找满足所有约束的时间表可能在计算上很困难。
护士调度问题:
在下一个示例中,医院主管需要根据 3 天条件为 4 位护士创建时间表:
- 一天每天轮班,一天三次。
- 每天,每个班次都会分配给一位护士,没有超过一个班次的护士工作。
- 在这 3 天里,每位护士都至少分配到两个班次。
接下来,我们将展示根据以下约束条件为护士的轮班分配护士:
- 每个班次分配给每天一名护士。
- 一名护士每天最多只会轮班一次。
代码中的约束条件图解:


具体代码如下:
#导入所需库,定义护士数量、轮班次数、天数
from ortools.sat.python import cp_model
num_nurses = 4
num_shifts = 3
num_days = 3
all_nurses = range(num_nurses)
all_shifts = range(num_shifts)
all_days = range(num_days)
# 创建模型、创建Bool类型变量数组(n, d, s)-->(护士编号,哪一天,哪一个轮班),定义了针对护士的轮班分配。
#即如果将 shift s 分配给 d 天中的护士 n,shifts[(n, d, s)] 的值为 1,否则为 0。
model = cp_model.CpModel()
shifts = {}
for n in all_nurses:
for d in all_days:
for s in all_shifts:
shifts[(n, d, s)] = model.NewBoolVar('shift_n%id%is%i' % (n, d, s))
# 确保每一天的每一个轮班只有一个护士
for d in all_days:
for s in all_shifts:
model.AddExactlyOne(shifts[(n, d, s)] for n in all_nurses)
# 确保每一名护士每天最多轮班一次。
for n in all_nurses:
for d in all_days:
model.AddAtMostOne(shifts[(n, d, s)] for s in all_shifts)
# 尽量分配均匀,设定每个护士应该上的最小轮班次数和最大轮班次数。
min_shifts_per_nurse = (num_shifts * num_days) // num_nurses
if num_shifts * num_days % num_nurses == 0:
max_shifts_per_nurse = min_shifts_per_nurse
else:
max_shifts_per_nurse = min_shifts_per_nurse + 1
# 指定每一个护士的最小轮班数为2,最大轮班数为3。
for n in all_nurses:
shifts_worked = []
for d in all_days:
for s in all_shifts:
shifts_worked.append(shifts[(n, d, s)])
model.Add(min_shifts_per_nurse <= sum(shifts_worked))
model.Add(sum(shifts_worked) <= max_shifts_per_nurse)
solver = cp_model.CpSolver()
solver.parameters.linearization_level = 0
# Enumerate all solutions.
solver.parameters.enumerate_all_solutions = True
# 在求解器上注册一个回调,系统会在每个解决方案中调用该回调函数。
class NursesPartialSolutionPrinter(cp_model.CpSolverSolutionCallback):
"""Print intermediate solutions."""
def __init__(self, shifts, num_nurses, num_days, num_shifts, limit):
cp_model.CpSolverSolutionCallback.__init__(self)
self._shifts = shifts
self._num_nurses = num_nurses
self._num_days = num_days
self._num_shifts = num_shifts
self._solution_count = 0
self._solution_limit = limit
def on_solution_callback(self):
self._solution_count += 1
print('Solution %i' % self._solution_count)
for d in range(self._num_days):
print('Day %i' % d)
for n in range(self._num_nurses):
is_working = False
for s in range(self._num_shifts):
if self.Value(self._shifts[(n, d, s)]):
is_working = True
print(' Nurse %i works shift %i' % (n, s))
if not is_working:
print(' Nurse {} does not work'.format(n))
if self._solution_count >= self._solution_limit:
print('Stop search after %i solutions' % self._solution_limit)
self.StopSearch()
def solution_count(self):
return self._solution_count
# Display the first five solutions.
solution_limit = 5
solution_printer = NursesPartialSolutionPrinter(shifts, num_nurses,
num_days, num_shifts,
solution_limit)
#调用求解器,并显示前五个解决方案
solver.Solve(model, solution_printer)
输出:
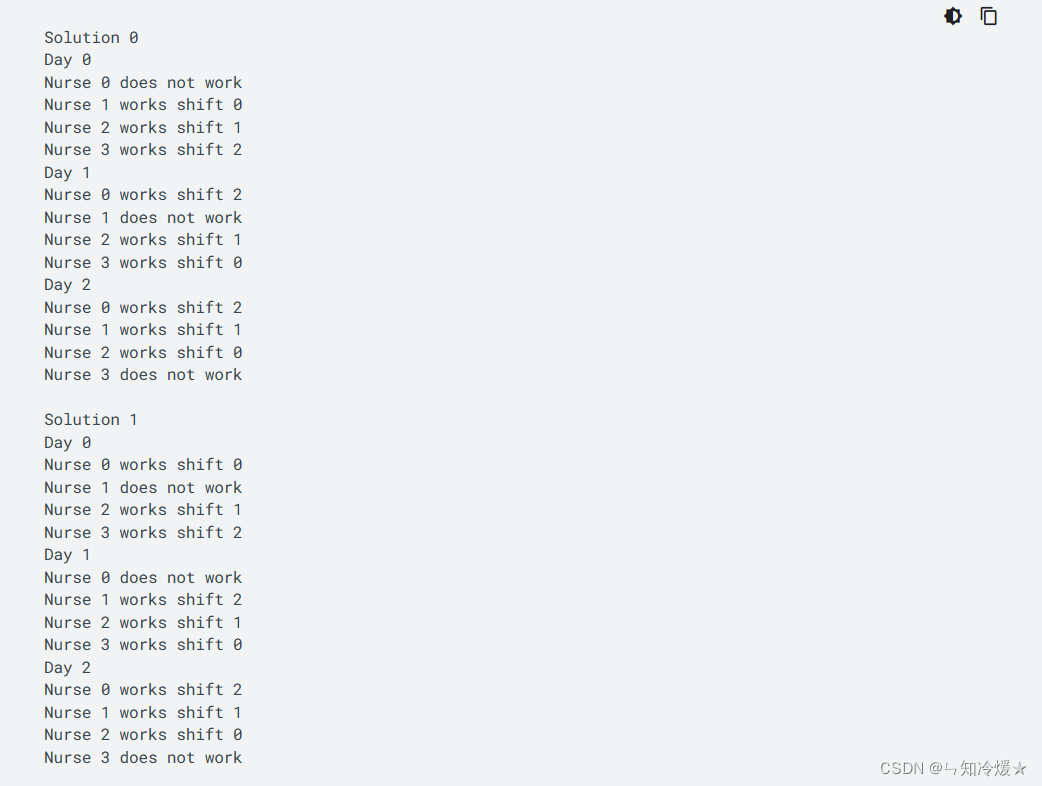
2-2、作业车间调度问题
作业车间调度问题: 每个作业都包含一系列任务,这些任务必须按给定顺序执行,并且每个任务都必须在特定的机器上处理。例如,该职位可以是汽车等单一消费品的制造商。问题在于,在机器上调度任务,以最大限度地减少调度的 length,即完成所有作业所需的时间。
该问题有以下几种限制条件:
- 在完成上一个作业任务之前,无法启动该作业的任何任务。
- 一台机器一次只能处理一项任务。
- 任务开始后必须运行以完成。
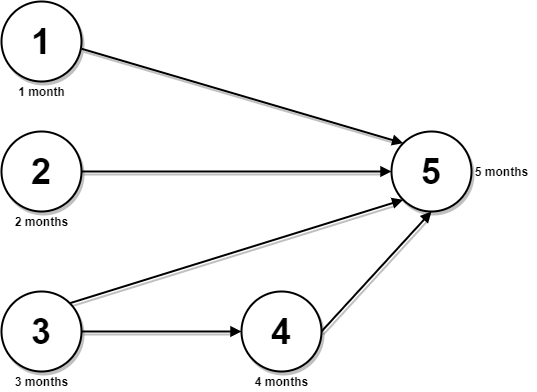
下面是一个简单的作业车间调度问题示例,其中每个任务都由一对数字 (m, p) 进行标记,其中 m 是必须在其上处理任务的机器数量,p 是任务的处理时间(即所需时间)。(作业和机器的编号从 0 开始。)
- 作业 0 = [(0, 3), (1, 2), (2, 2)]
- 作业 1 = [(0, 2), (2, 1), (1, 4)]
- 作业 2 = [(1, 4), (2, 3)]
在示例中,作业 0 有 3 个任务。第一个 (0, 3) 必须在机器 0 上以 3 个单位的时间进行处理。第二个 (1, 2) 必须在机器 1 上以 2 个单位的时间进行处理,依此类推。总共有八个任务。
下边是一个可能的解决方案:

问题的变量和限制条件
本部分介绍如何设置问题的变量和约束条件。首先,让 task(i, j) 表示作业 i 中的第 j 个任务。例如,task(0, 2) 表示作业 0 的第二个任务,对应于问题说明中的 (1, 2) 对。
接下来,将 t i , j t_{i, j} ti,j 定义为 task(i, j) 的开始时间。 t i , j t_{i, j} ti,j是求解作业问题中的变量。解决方案需要确定这些变量满足问题要求的值。
作业车间调度问题有两种限制条件:
- 优先级限制条件 - 源自以下作业的条件:对于同一作业中的任何两个连续任务,必须先完成第一个任务,然后才能启动第二个任务。例如,task(0, 2) 和 task(0, 3) 是作业 0 的连续任务。由于 task(0, 2) 的处理时间为 2,因此 task(0, 3) 的开始时间必须至少比任务 2 的开始时间晚 2 个单位。(任务 2 或许正在为一扇门着色,需要 2 个小时才能喷漆。)因此,您会受到以下约束:
t 0 , 2 t_{0, 2} t0,2 + 2 <= t 0 , 3 t_{0, 3} t0,3 - 无重叠约束 - 存在机器不能同时处理两个任务的限制。例如,任务(0, 2) 和任务(2, 1) 均在机器 1 上进行处理。 由于处理时间分别为 2 和 4,因此必须满足以下约束条件之一:
t 0 , 2 t_{0, 2} t0,2 + 2 <= t 2 , 1 t_{2, 1} t2,1(如果 task(0, 2) 的时间安排在 task(2, 1) 之前)或
t 2 , 1 t_{2, 1} t2,1 + 4 <= t 0 , 2 t_{0, 2} t0,2(如果 task(2, 1) 的时间安排在 task(0, 2) 之前)。
问题目标
作业车间调度问题的目标是最大限度地减少 makespan:从作业的最早开始时间到最晚的结束时间之间的时长。
代码如下所示:
"""Minimal jobshop example."""
import collections
from ortools.sat.python import cp_model
def main():
"""Minimal jobshop problem."""
# Data.
# # 定义每一个作业的所有任务,(m,p)m代表的是在哪个机器上处理,p代表的是任务的处理时间(即所需要的时间)
jobs_data = [ # task = (machine_id, processing_time).
[(0, 3), (1, 2), (2, 2)], # Job0
[(0, 2), (2, 1), (1, 4)], # Job1
[(1, 4), (2, 3)] # Job2
]
# 机器数量,得出一共需要的机器数量是多少。
machines_count = 1 + max(task[0] for job in jobs_data for task in job)
all_machines = range(machines_count)
# Computes horizon dynamically as the sum of all durations.
# 处理所有任务的总的时长并实例化模型
horizon = sum(task[1] for job in jobs_data for task in job)
# Create the model.
model = cp_model.CpModel()
# 使用collection来命名元组,详细使用看下边内容
# Named tuple to store information about created variables.
task_type = collections.namedtuple('task_type', 'start end interval')
# Named tuple to manipulate solution information.
assigned_task_type = collections.namedtuple('assigned_task_type',
'start job index duration')
# Creates job intervals and add to the corresponding machine lists.
all_tasks = {}
# 使用collections来创建字典。
machine_to_intervals = collections.defaultdict(list)
# job_id:第几个作业, job: [(0, 3), (1, 2), (2, 2)]
for job_id, job in enumerate(jobs_data):
# task_id: 第几个任务, task: (0, 3)
for task_id, task in enumerate(job):
machine = task[0]
duration = task[1]
# 拼接后缀
suffix = '_%i_%i' % (job_id, task_id)
start_var = model.NewIntVar(0, horizon, 'start' + suffix)
end_var = model.NewIntVar(0, horizon, 'end' + suffix)
# 创建时间区间变量来存储每个任务
interval_var = model.NewIntervalVar(start_var, duration, end_var,
'interval' + suffix)
#
all_tasks[job_id, task_id] = task_type(start=start_var,
end=end_var,
interval=interval_var)
# 在机器上添加每个时间区间变量
machine_to_intervals[machine].append(interval_var)
# Create and add disjunctive constraints.
# 创建每个机器的限制
# # 添加一个“无重叠”约束的方法,通常用于安排一组任务或者活动在时间上不会发生重叠,这可以保证在特定时间段内,只有一个任务或活动会被安排。
for machine in all_machines:
model.AddNoOverlap(machine_to_intervals[machine])
# Precedences inside a job.
# 添加限制条件:后一个任务的起始时间大于等于前一个任务的结束时间
for job_id, job in enumerate(jobs_data):
for task_id in range(len(job) - 1):
model.Add(all_tasks[job_id, task_id +
1].start >= all_tasks[job_id, task_id].end)
# Makespan objective.
# 目标变量:所有作业的最后一个任务的结束时间,作为目标变量的最大值约束
obj_var = model.NewIntVar(0, horizon, 'makespan')
model.AddMaxEquality(obj_var, [
all_tasks[job_id, len(job) - 1].end
for job_id, job in enumerate(jobs_data)
])
# 最小化目标变量
model.Minimize(obj_var)
# Creates the solver and solve.
solver = cp_model.CpSolver()
status = solver.Solve(model)
#
if status == cp_model.OPTIMAL or status == cp_model.FEASIBLE:
print('Solution:')
# 创建每个机器被分配的任务列表
# Create one list of assigned tasks per machine.
assigned_jobs = collections.defaultdict(list)
for job_id, job in enumerate(jobs_data):
for task_id, task in enumerate(job):
machine = task[0]
assigned_jobs[machine].append(
assigned_task_type(start=solver.Value(
all_tasks[job_id, task_id].start),
job=job_id,
index=task_id,
duration=task[1]))
# Create per machine output lines.
output = ''
for machine in all_machines:
# Sort by starting time.
assigned_jobs[machine].sort()
sol_line_tasks = 'Machine ' + str(machine) + ': '
sol_line = ' '
for assigned_task in assigned_jobs[machine]:
name = 'job_%i_task_%i' % (assigned_task.job,
assigned_task.index)
# Add spaces to output to align columns.
sol_line_tasks += '%-15s' % name
start = assigned_task.start
duration = assigned_task.duration
sol_tmp = '[%i,%i]' % (start, start + duration)
# Add spaces to output to align columns.
sol_line += '%-15s' % sol_tmp
sol_line += '\n'
sol_line_tasks += '\n'
output += sol_line_tasks
output += sol_line
# Finally print the solution found.
print(f'Optimal Schedule Length: {solver.ObjectiveValue()}')
print(output)
else:
print('No solution found.')
# Statistics.
print('\nStatistics')
print(' - conflicts: %i' % solver.NumConflicts())
print(' - branches : %i' % solver.NumBranches())
print(' - wall time: %f s' % solver.WallTime())
if __name__ == '__main__':
main()
输出:
*Solution:
Optimal Schedule Length: 11.0
Machine 0: job_1_task_0 job_0_task_0
[0,2] [2,5]
Machine 1: job_2_task_0 job_0_task_1 job_1_task_2
[0,4] [5,7] [7,11]
Machine 2: job_1_task_1 job_2_task_1 job_0_task_2
[2,3] [4,7] [7,9]
Statistics
- conflicts: 0
- branches : 0
- wall time: 0.018851 s*
三、知识库
3-1、collection
在 Python 中,collections 是一个标准库模块,提供了一些有用的数据结构和工具,用于扩展内置数据类型的功能。collections 模块包含了多种集合类型,这些类型可以用于更高效地管理和处理数据。一些常用的集合类型包括:
- namedtuple(命名元组):namedtuple 是一个工厂函数,用于创建一个具名的元组子类。命名元组的每个元素都有自己的字段名,这使得元组的每个位置都有一个易于理解的名称。它可以使代码更具可读性。
- deque(双向队列):deque 是双向队列,支持在队列两端进行高效的插入和删除操作。与列表相比,deque 在头部插入和删除元素的时间复杂度是 O(1),而列表是 O(n)。
- Counter(计数器):Counter 是一个简单的计数器工具,用于统计可哈希对象的出现次数。它可以用于计算列表、字符串等中元素的频率。
- OrderedDict(有序字典):OrderedDict 是一个有序字典类型,它会维护插入元素的顺序,可以按照插入顺序遍历字典。
- defaultdict(默认字典):defaultdict 是一个字典类型,它可以指定默认值,当访问字典中不存在的键时,会返回指定的默认值,而不是抛出异常。
- ChainMap(链式映射):ChainMap 可以将多个字典或映射对象链接在一起,形成一个逻辑上的映射链。
- Counter(计数器):Counter 是一个简单的计数器工具,用于统计可哈希对象的出现次数。它可以用于计算列表、字符串等中元素的频率。
下边以namedtuple(命名元组为例来进行介绍):创建命名元组子类的工厂函数,生成可以使用名字来访问元素内容的tuple子类
参数介绍
namedtuple(typename,field_names,*,verbose=False, rename=False, module=None)
-
typename:该参数指定所创建的tuple子类的类名,相当于用户定义了一个新类。
-
field_names:该参数是一个字符串序列,如 [‘x’,‘y’]。此外,field_names 也可直接使用单个字符串代表所有字段名,多个字段名用空格、逗号隔开,如 ‘x y’ 或 ‘x,y’。任何有效的 Python 标识符都可作为字段名(不能以下画线开头)。有效的标识符可由字母、数字、下画线组成,但不能以数字、下面线开头,也不能是关键字(如 return、global、pass、raise 等)。
-
rename:如果将该参数设为 True,那么无效的字段名将会被自动替换为位置名。例如指定 [‘abc’,‘def’,‘ghi’,‘abc’],它将会被替换为 [‘abc’, ‘_1’,‘ghi’,‘_3’],这是因为 def 字段名是关键字,而 abc 字段名重复了。
-
verbose:如果该参数被设为 True,那么当该子类被创建后,该类定义就被立即打印出来。
-
module:如果设置了该参数,那么该类将位于该模块下,因此该自定义类的 module 属性将被设为该参数值。
案例分析:
from collections import namedtuple
# 定义命名元组类型
task_type = namedtuple('task_type', 'start end interval')
# 创建一个命名元组实例
start_var = 0
end_var = 10
interval_var = 5
task_instance = task_type(start=start_var, end=end_var, interval=interval_var)
# 访问命名元组的字段值
print(task_instance.start) # 输出: 0
print(task_instance.end) # 输出: 10
print(task_instance.interval) # 输出: 5
# 定义了一个命名元组 task_type,它有三个字段:start、end 和 interval。
# 接下来,task_type(start=start_var, end=end_var, interval=interval_var) 这行代码实际上是在创建一个 task_type 命名元组的实例,并将参数 start_var、end_var 和 interval_var 分别赋值给相应的字段。
# 这样的命名元组实例可以像普通的元组一样被访问和操作,但是由于每个字段都有一个名字,所以可以通过字段名来获取元组的值,使得代码更加清晰易读
3-2、CpModel().AddNoOverlap()
含义:是用来添加一个“无重叠”约束的方法。"无重叠"约束通常用于安排一组任务或活动在时间上不会发生重叠。这可以确保在特定时间段内,只有一个任务或活动会被安排。
案例分析:
from ortools.sat.python import cp_model
model = cp_model.CpModel()
# 任务1,开始时间为0,持续时间为2,结束时间为2
start_1 = model.NewIntVar(0, 10, 'start_1')
duration_1 = 2
end_1 = model.NewIntVar(0, 10, 'end_1')
interval_1 = model.NewIntervalVar(start_1, duration_1, end_1, 'interval_1')
# 任务2,开始时间为0,持续时间为2,结束时间为2
start_2 = model.NewIntVar(0, 10, 'start_2')
duration_2 = 2
end_2 = model.NewIntVar(0, 10, 'end_2')
interval_2 = model.NewIntervalVar(start_2, duration_2, end_2, 'interval_2')
# 任务3,开始时间为0,持续时间为2,结束时间为2
start_3 = model.NewIntVar(0, 10, 'start_3')
duration_3 = 2
end_3 = model.NewIntVar(0, 10, 'end_3')
interval_3 = model.NewIntervalVar(start_3, duration_3, end_3, 'interval_3')
model.AddNoOverlap([interval_1, interval_2, interval_3])
solver = cp_model.CpSolver()
status = solver.Solve(model)
if status == cp_model.OPTIMAL:
print('任务1开始于:', solver.Value(start_1))
print('任务2开始于:', solver.Value(start_2))
print('任务3开始于:', solver.Value(start_3))
输出:

3-3、CpModel().AddMaxEquality()
含义:model.AddMaxEquality() 是一个约束编程(Constraint Programming)模块(cp_model)中提供的方法,用于将一组变量的最大值相等的约束添加到模型中。
语法
model.AddMaxEquality(target_var, variable_array)
- target_var:表示目标变量,它是一个整数变量(IntVar),用于存储变量数组中的最大值。
- variable_array:表示变量数组,即需要求最大值的一组整数变量。
- AddMaxEquality() 方法会将目标变量 target_var 的值设置为变量数组 variable_array 中的最大值。
案例如下:
# Import the required module
from ortools.sat.python import cp_model
# Instantiate the CP-SAT model.
model = cp_model.CpModel()
# Define the capacities
br1_cap = 5
br2_cap = 4
br3_cap = 6
# Given tasks
tasks = 10
# Define variables for the tasks assigned to each branch
br1_tasks = model.NewIntVar(0, br1_cap, 'br1')
br2_tasks = model.NewIntVar(0, br2_cap, 'br2')
br3_tasks = model.NewIntVar(0, br3_cap, 'br3')
# Define the variable for the maximum tasks
max_tasks = model.NewIntVar(0, max(br1_cap, br2_cap, br3_cap), 'max_tasks')
# Tell the model that max_tasks is the maximum number of tasks assigned to any branch
model.AddMaxEquality(max_tasks, [br1_tasks, br2_tasks, br3_tasks])
# Add constraints that the tasks assigned to all branches should equal the given tasks
model.Add(br1_tasks + br2_tasks + br3_tasks == tasks)
# Create a solver
solver = cp_model.CpSolver()
status = solver.Solve(model)
# Print the assignments
if status == cp_model.OPTIMAL:
print("Branch 1 tasks: ", solver.Value(br1_tasks))
print("Branch 2 tasks: ", solver.Value(br2_tasks))
print("Branch 3 tasks: ", solver.Value(br3_tasks))
print("Maximum tasks assigned to a branch: ", solver.Value(max_tasks))
输出如下:
Branch 1 tasks: 0
Branch 2 tasks: 4
Branch 3 tasks: 6
Maximum tasks assigned to a branch: 6
3-4、cp_model.CpModel().NewIntVar()
含义:cp_model.CpModel().NewIntVar() 是用于创建一个新的整数变量(IntVar)的方法。整数变量是用于建模整数类型的未知数,可以代表问题中的状态、决策变量或者其他需要求解的值。
语法:
NewIntVar(lb, ub, name)
参数说明:
- lb(lower bound):整数变量的下界,表示整数变量的取值范围最小值。
- ub(upper bound):整数变量的上界,表示整数变量的取值范围最大值。
- name:整数变量的名称(可选),用于在输出中标识和识别变量。
案例分析:
from ortools.sat.python import cp_model
def simple_integer_variable_example():
# 创建约束编程模型
model = cp_model.CpModel()
# 创建整数变量 x,范围为 [0, 10]
x = model.NewIntVar(0, 10, 'x')
# 创建约束条件:x >= 5
model.Add(x >= 5)
# 创建求解器并求解模型
solver = cp_model.CpSolver()
status = solver.Solve(model)
if status == cp_model.OPTIMAL:
print('x 的值:', solver.Value(x))
else:
print('找不到可行解。')
if __name__ == '__main__':
simple_integer_variable_example()
输出的值:
x 的值: 5
3-5、cp_model.CpModel().NewIntervalVar
含义:cp_model.CpModel().NewIntervalVar() 是用于创建一个时间区间变量(IntervalVar)的方法。时间区间变量用于表示任务或活动在时间上的开始和结束。
NewIntervalVar() 方法的语法如下:
NewIntervalVar(start_var, duration, end_var, name)
参数说明:
- start_var:表示任务开始时间的整数变量(IntVar)或整数值。通常为一个整数变量,但也可以是一个固定的整数值,表示任务的开始时间。
- duration:表示任务持续时间的整数值或整数变量。任务持续时间可以是固定的整数值,也可以是一个整数变量,其值在运行时确定。
- end_var:表示任务结束时间的整数变量(IntVar)或整数值。通常为一个整数变量,但也可以是一个固定的整数值,表示任务的结束时间。
- name:时间区间变量的名称(可选),用于在输出中标识和识别变量。
时间区间变量的特点是它们允许任务的开始和结束时间在求解时进行灵活地调整,从而满足给定的约束条件,例如任务之间不重叠、任务的持续时间等。
案例分析:
from ortools.sat.python import cp_model
def simple_interval_variable_example():
# 创建约束编程模型
model = cp_model.CpModel()
# 创建整数变量表示任务的开始时间和结束时间
start_var = model.NewIntVar(0, 100, 'start_var')
end_var = model.NewIntVar(0, 100, 'end_var')
# 创建整数变量表示任务的持续时间
duration = model.NewIntVar(10, 50, 'duration')
# 创建时间区间变量
task_interval = model.NewIntervalVar(start_var, duration, end_var, 'task_interval')
# 创建约束条件:任务的开始时间和结束时间之间存在关系
model.Add(end_var == start_var + duration)
# 创建求解器并求解模型
solver = cp_model.CpSolver()
status = solver.Solve(model)
if status == cp_model.OPTIMAL:
print('任务开始时间:', solver.Value(start_var))
print('任务结束时间:', solver.Value(end_var))
print('任务持续时间:', solver.Value(duration))
else:
print('找不到可行解。')
if __name__ == '__main__':
simple_interval_variable_example()
输出:
任务开始时间: 0
任务结束时间: 10
任务持续时间: 10
参考文章:
OR-Tools官网.
【万字长文详解】Python库collections,让你击败99%的Pythoner.
总结
要经历过多少次,才不会反反复复踏入同一条河流。