ROC曲线(Receiver Operating Characteristic Curve),也称为“接受者操作特性曲线”。它最早应用于雷达信号检测的分析,后来广泛应用于心理学和医学领域。
ROC分析是进行临床诊断试验评价最常用的方法。诊断试验是指评价某种疾病诊断方法的临床试验,主要应用于疾病诊断、疾病随访、疗效考核,以及药物毒副作用的监测。医生常通过对同一疾病的多种诊断试验进行分析比较,以便筛选出最佳诊断方案。
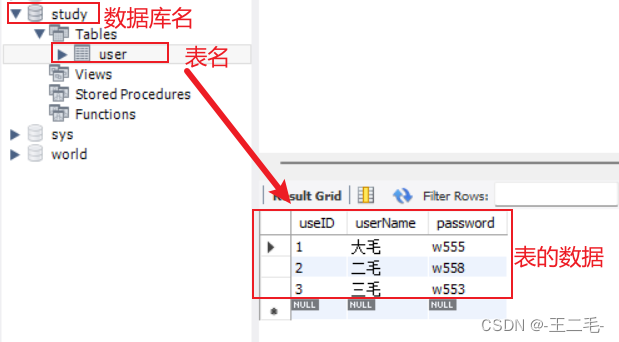
同样,在日常的工作和生活中,我们也经常需要进行预测,且总希望预测结果的准确性尽可能高。一个完美的分类模型是,我们可以将实际上属于类别1的也预测成1,属于类别0的也都预测成0。但实际的预测模型往往没有那么准确,一些实际属于类别1 的样本,根据我们的模型,却被预测为了0;而一些原本类别是0的样本,却被预测为了1。正如下图中的混淆矩阵所示:
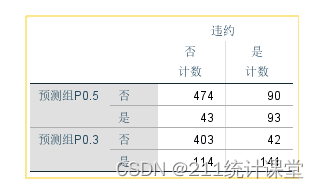
通过上面的这个混淆矩阵,我们可以知道这个模型到底预测对了多少,预测错了多少;并且,还可以计算出与它相关的一系列分类性能评估指标:
正确率= 正确预测的正反例数 / 总数
误分类率= 错误预测的正反例数 / 总数
覆盖率/敏感度(Sensitivity) = 正确预测到的正例数 / 实际正例总数
负例的覆盖率/特异性(Specificity) = 正确预测到的负例个数 / 实际负例总数
命中率= 正确预测到的正例数 / 预测正例总数
负例的命中率= 正确预测到的负例个数 / 预测负例总数
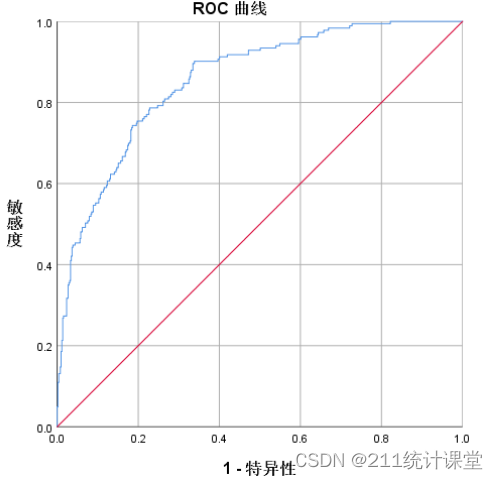
ROC曲线是以1-Specificity(1-特异性)为横轴,Sensitivity(灵敏度)为纵轴所绘制的曲线。随着分类的概率阈值的减少,Sensitivity和1-Specificity也相应增加(也即Specificity相应减少),所以ROC曲线呈从左下角垂直上升到顶线,水平方向向右延伸到右上角的递增态势。
我们可以通过ROC曲线来判断模型效果的好坏,并以此标准比较不同模型的预测准确性。
ROC曲线好坏标准的参照是45度线,即对角线。如果ROC曲线沿着对角线方向分布,表示分类是随机造成的,该曲线表现不佳;而曲线越向左上方靠拢,越远离对角线,说明该曲线的灵敏度和特异性越高。
ROC曲线根据与45度线的偏离来判断模型好坏的好处是直观,缺点是不够精确。到底好在哪里,好了多少?这就要涉及到AUC(Area Under the ROC Curve,ROC曲线下的面积)。
ROC曲线图中45度线下的面积是0.5,ROC曲线与它偏离越大,越向左上方靠拢,它下方的面积(AUC)就越大,其AUC值也越接近于1。因此,我们可以根据AUC的值来判断一个分类模型的预测效果。
AUC在0.5~0.7之间,说明模型效果较差;AUC在0.7~0.9之间,说明模型效果中等;AUC在0.9以上,说明模型效果佳。一般来说,AUC大于0.8,就可以认为模型效果较好。
案例分析
接下来我将用SPSS中的自带数据集bankloan.sav向大家介绍曲线分析方法。
这个数据集中包含了850位客户的财务和人口统计信息。前700个案例是以前获得贷款的客户,这些客户的违约情况是已知的。后150个案例还没有获得贷款,银行需要对他们进行建模预测,判断他们是否存在信用风险,即判断他们是否会产生违约。
在这个数据集中自带了3个违约概率预测变量(preddef1~3),即银行已经使用了3种不同方法进行了建模预测,接下来,我们需要通过ROC曲线分析来判断哪种模型预测的准确性最高。
打开数据集:
选择文件 -> “欢迎”对话框,在欢迎对话框中选择样本文件,选择bankloan.sav,选择打开。SPSS会自动打开这份数据文件。

该数据集的部分数据截图如下所示:
数据分析:
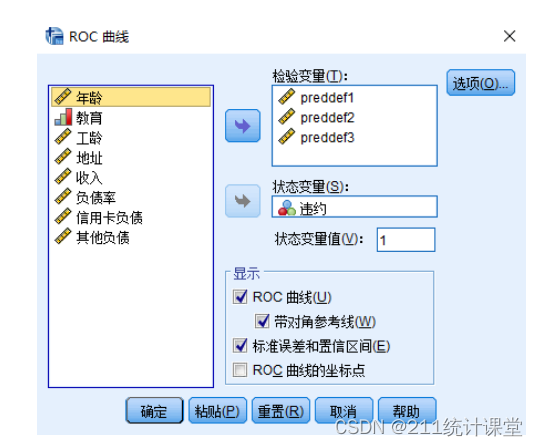
选择分析 -> ROC曲线;
将preddef1、preddef2、preddef3这3个变量选入检验变量(这3个变量是分别用3种模型得到的违约概率值);
将违约变量选入状态变量;
因为在该案例的违约变量中违约编码为1,没有违约编码为0,所以在状态变量值中填入1;
勾选ROC曲线、带对角参考线,以及标准误差和置信区间;
完成后,点击确定。对话框如下所示:
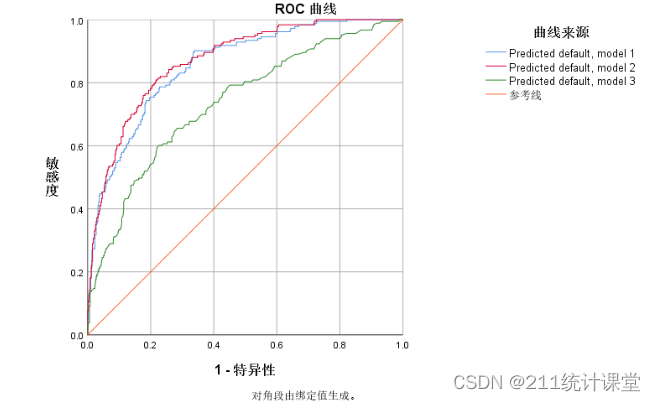
得到的分析结果如下所示:
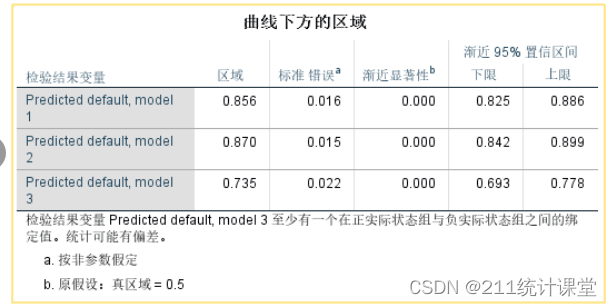
分析结果详解:
从分析结果来看,preddef1和preddef2的效果要好于preddef3。preddef1和preddef2的效果相近,但似乎preddef2离对角线更远一些。
preddef1的ROC曲线下的区域面积(AUC)是0.856,标准误为0.016,其95%的置信区间是0.825~0.886;
preddef2的ROC曲线下的区域面积(AUC)是0.870,标准误为0.015,其95%的置信区间是0.842~0.899;
preddef3的ROC曲线下的区域面积(AUC)是0.735,标准误为0.022,其95%的置信区间是0.693~0.778;
因此,preddef2比preddef1的AUC值略大,但它们的95%的置信区间存在交叉,因此可以认为它们的预测效果不存在显著差异。
以上就是在SPSS中进行ROC分析的详细过程,大家可以打开SPSS自行操作练习哦~