开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1100人左右 1 + 2 + 3)新人会进入3群
Postgres 16刚刚发布了测试版,我对其中的新功能非常兴奋。该新功能允许从待命服务器进行逻辑复制,用户可以:
从只读的待命服务器创建逻辑解码 减轻主服务器的工作负载 采用新的方式为需要在多个系统之间进行数据同步或审核的应用程序提供高可用性 第二个相关且令人兴奋的新功能是,在给定的待命服务器上的复制槽将持久化到将该待命服务器提升为主服务器。这意味着在主服务器故障并将待命服务器提升为主服务器时,复制槽将持久存在,并且之前的待命服务器订阅者不会受到影响。
这两个功能结合在一起,极大地提高了PostgreSQL在处理大数据操作时的性能。适用于在物理位置之间移动数据的应用程序,以及进行数据仓库、分析、数据集成和业务智能的人员。我将演示一个示例模式和数据库设置,并提供一些用于从待命服务器创建逻辑复制的示例设置和代码。
Background on replication
在高层次上,PostgreSQL支持两种主要类型的复制:流式/物理复制和逻辑复制。Write-Ahead Log(WAL)可以通过连接流式传输整个物理文件集,并表示磁盘上完整的数据库。逻辑复制提供了一种更精细的方法,您可以指定要复制到远程服务器的单个数据库对象,如表甚至特定行。您可以在《Data To Go: Postgres Logical Replication》中了解更多关于逻辑复制基础知识。
PostgreSQL通过对主服务器进行基本备份并持续应用主服务器上的所有更改来创建待命服务器。热待命服务器是可以升级为主服务器的待命服务器。PostgreSQL将修改保存在Write-Ahead Log(WAL)记录中,并将其从主服务器复制到待命服务器。配置参数hot_standby_feedback可以防止主服务器过早删除目录行,以便待命服务器可以使用它们。
逻辑解码从待命服务器开始于2018年。这个过程涉及了许多复杂的细节,需要大量的努力。不容忽视的是,这个过程已经经历了5年的发展,我们非常兴奋地看到它在Postgres 16中发布。
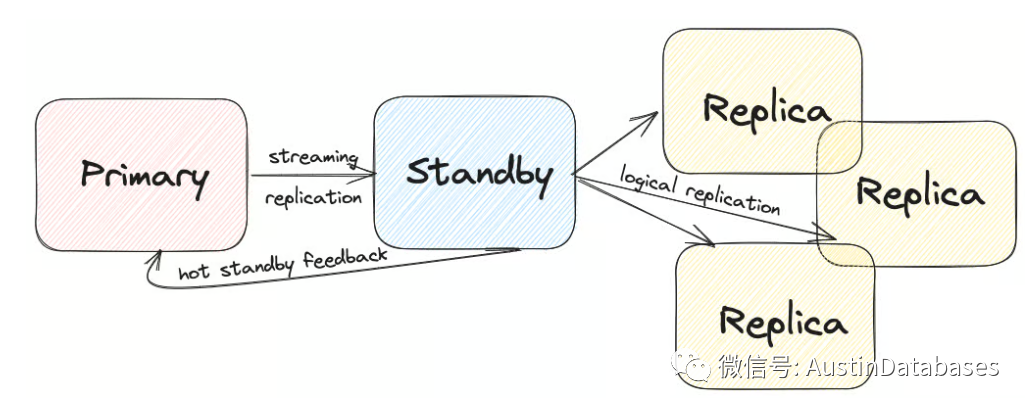
举个例子,我们有三个不同的PostgreSQL服务器,管理着一家全球物流公司在全球各地分布的仓库的库存信息。在主服务器上,我们有仓库和库存信息,备用服务器是一个物理副本高可用性机器,还有一个用于报告目的的第三个服务器,它正在获取特定的更改。
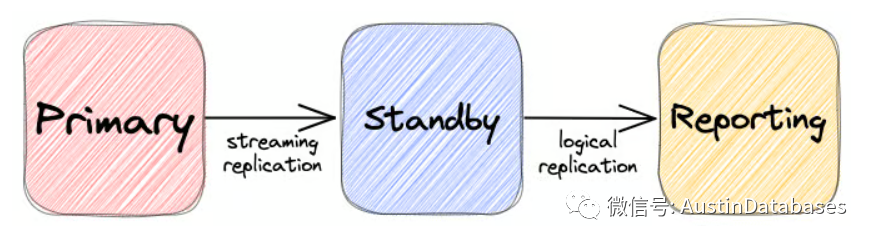
在您的主实例中,您需要具有复制特权的用户。对于这个例子,我创建了一个用户将更改流向备用服务器,另一个用户将更改发布给订阅者。
CREATE ROLE repuser WITH REPLICATION LOGIN ENCRYPTED PASSWORD 'somestrongpassword';
CREATE ROLE pubuser WITH REPLICATION LOGIN ENCRYPTED PASSWORD 'differentstrongpassword';接下来,我创建一个物理插槽来将更改从主服务器复制到备用服务器。严格来说,这并不是必需的,但在实践中真的是必要的。如果没有物理复制插槽,任一节点的重启或连接丢失都会中断复制过程:
SELECT pg_create_physical_replication_slot('hot_standby_1');我们只关心Salt Lake City仓库的库存,其代码为SLC。在主服务器上,我们将创建一个名为inventory_requirements的发布,用于涉及库存表的表,还有一个名为inventory_slc_pub的发布:
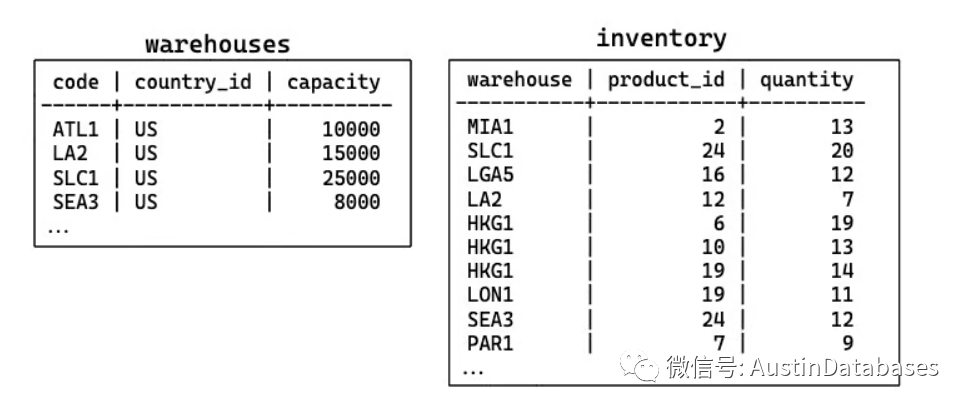
CREATE PUBLICATION inventory_requirements_pub
FOR TABLE regions, countries, warehouses, products;
CREATE PUBLICATION inventory_slc_pub
FOR TABLE inventory WHERE (warehouse = 'SLC1');
GRANT SELECT ON TABLE regions, countries, warehouses, products, inventory
TO pubuser;现在我可以创建我的备用实例。我们将使用pgBackRest(也可以使用pg_basebackup)来初始化备用实例。一旦你的备用数据目录已经恢复,你将需要编辑它的postgresql.conf并确保它有一些参数(如此文档中所述):tream standby about
# queries currently executing on this standby
hot_standby_feedback = on
# Use the physical replication slot we created previously
primary_slot_name = 'hot_standby_1'
hot_standby = on
archive_mode = on
# If level is changed to below logical, slots will be dropped
wal_level = logical
# standby streams changes from the primary
primary_conn_info = 'host=127.0.0.1 port=5432 user=repuser password=somestrongpassword'
max_wal_senders = 10 # max number of walsender processes
max_replication_slots = 10 # max number of replication slots
# If an upstream standby server is promoted to become the new
# primary, downstream servers will continue to stream from
# the new primary
recovery_target_timeline = 'latest'连接到该备用实例将确认它处于只读模式:
SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t此时,我们已经具有一个通过物理插槽从主实例复制到一个设置了hot_standby_feedback = on的工作备用实例。命名为inventory_requirements_pub和inventory_slc_pub的发布。
从standby 中进行逻辑复制
现在,我们可以转到我们的报告 PostgreSQL 实例并从备用实例订阅更改。在 PostgreSQL 16 之前,此操作将失败。
逻辑复制的一个主要优点是您可以从不同版本的 PostgreSQL 服务器订阅更改!这在处理使用不同版本的 PostgreSQL 的应用程序时为您提供了很大的灵活性。
CREATE SUBSCRIPTION inventory_requirements_sub
CONNECTION 'dbname=inventory host=127.0.0.1 port=5434 user=pubuser password=differentstrongpassword'
PUBLICATION inventory_requirements_pub;
CREATE SUBSCRIPTION inventory_slc_sub
CONNECTION 'dbname=inventory host=127.0.0.1 port=5434 user=pubuser password=differentstrongpassword'
PUBLICATION inventory_slc_pub;如果您的主服务器处于空闲状态,此操作将挂起。这是因为备用实例正在等待来自主实例的信息。您可以通过在主实例上调用新函数pg_log_standby_snapshot()来加快创建此信息的速度。在此示例中,我们会调用两次,因为我们要创建两个订阅。
这将允许副本继续,并生成如下的消息,告诉我们在备用实例上创建了一个复制槽。在 PostgreSQL 16 中进行了改进!
我们可以在备用实例上通过访问pg_stat_replication系统视图来验证这一点。
一旦更改被复制到备用实例,它们将被下游复制到报告服务器,并且我们将在那里看到这些更改。请注意,只有SLC1的记录会被复制。
SELECT pg_log_standby_snapshot();
pg_log_standby_snapshot
-------------------------
0/23000180
NOTICE: created replication slot "inventory_requirements_sub" on publisher
CREATE SUBSCRIPTIONSELECT pid, application_name, state, sync_state FROM pg_stat_replication;
pid | application_name | state | sync_state
-------+----------------------------+-----------+------------
23265 | inventory_slc_sub | streaming | async
23251 | inventory_requirements_sub | streaming | async
(2 rows)SELECT * FROM inventory ORDER BY product_id;
warehouse | product_id | quantity
-----------+------------+----------
SLC1 | 11 | 7
SLC1 | 13 | 13
SLC1 | 15 | 18
SLC1 | 22 | 15
SLC1 | 24 | 20从这里,如果需要的话,我可以创建多个逻辑复制副本,用于不同的位置和仓库。
正如我们之前所看到的,当我们创建订阅连接到备用服务器时,它会在不可写的备用服务器上创建复制槽。如果我们的主服务器发生灾难性故障,备用服务器被提升为主服务器,那么会发生什么情况呢?不同的仓库会停止接收更改,因为无法再从原本的备用服务器上获取更改,它无法与新的主服务器进行通信。
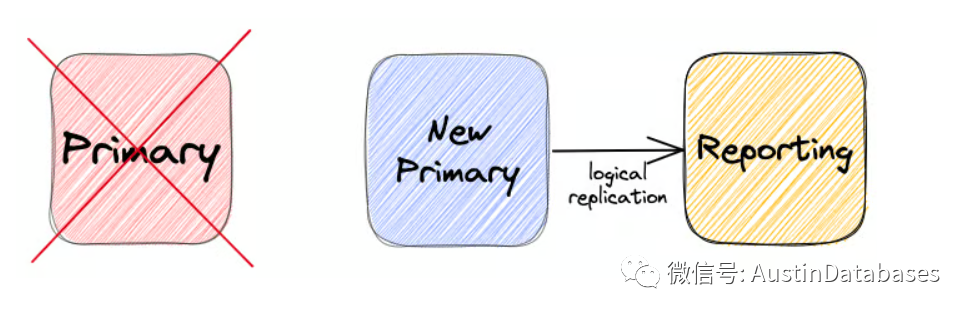
在Postgres 16中,复制槽在故障切换后是持久化的,这非常令人兴奋!我们之前的备用服务器被提升为主服务器,复制槽的故障切换被保留下来,我们的订阅者继续接收更改,就好像什么都没有发生过一样!
在我们的数据仓库报表PostgreSQL服务器上,订阅了我们现在的主服务器,对库存表的更改出现了,而不需要采取任何其他操作(确保您要逻辑复制的表设置了REPLICA IDENTITY):
SELECT pg_promote();
pg_promote
------------
t
(1 row)
SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)
UPDATE inventory SET quantity = 2
WHERE warehouse = 'SLC1' and product_id = 11;
UPDATE 1SELECT * FROM inventory WHERE warehouse = 'SLC1' order by product_id;
warehouse | product_id | quantity
-----------+------------+----------
SLC1 | 11 | 2
SLC1 | 13 | 13
SLC1 | 15 | 18
SLC1 | 22 | 15
SLC1 | 24 | 20随着越来越多的人选择使用Postgres作为数据库,支持更丰富的数据流选项在Postgres中继续出现是有道理的。从几年前开始,逻辑复制从备库中继续建立,经过多次增强。由于PostgreSQL社区的出色工作,在PG 16中,备服用户将能够:
创建逻辑复制槽 启动逻辑解码 订阅备库的更改 故障切换后持久化逻辑复制槽 备库将能够作为逻辑复制订阅者的源进行服务,只需进行很少的更改:
开启hot_standby_feedback = on 使用物理复制槽从上游复制到备库 如果订阅者在向备库创建订阅时等待更改而发生停顿,则在主服务器上运行pg_log_standby_snapshot()。这个新功能的文档仍在编写和改进中,我将利用自己的所学来提交改进。