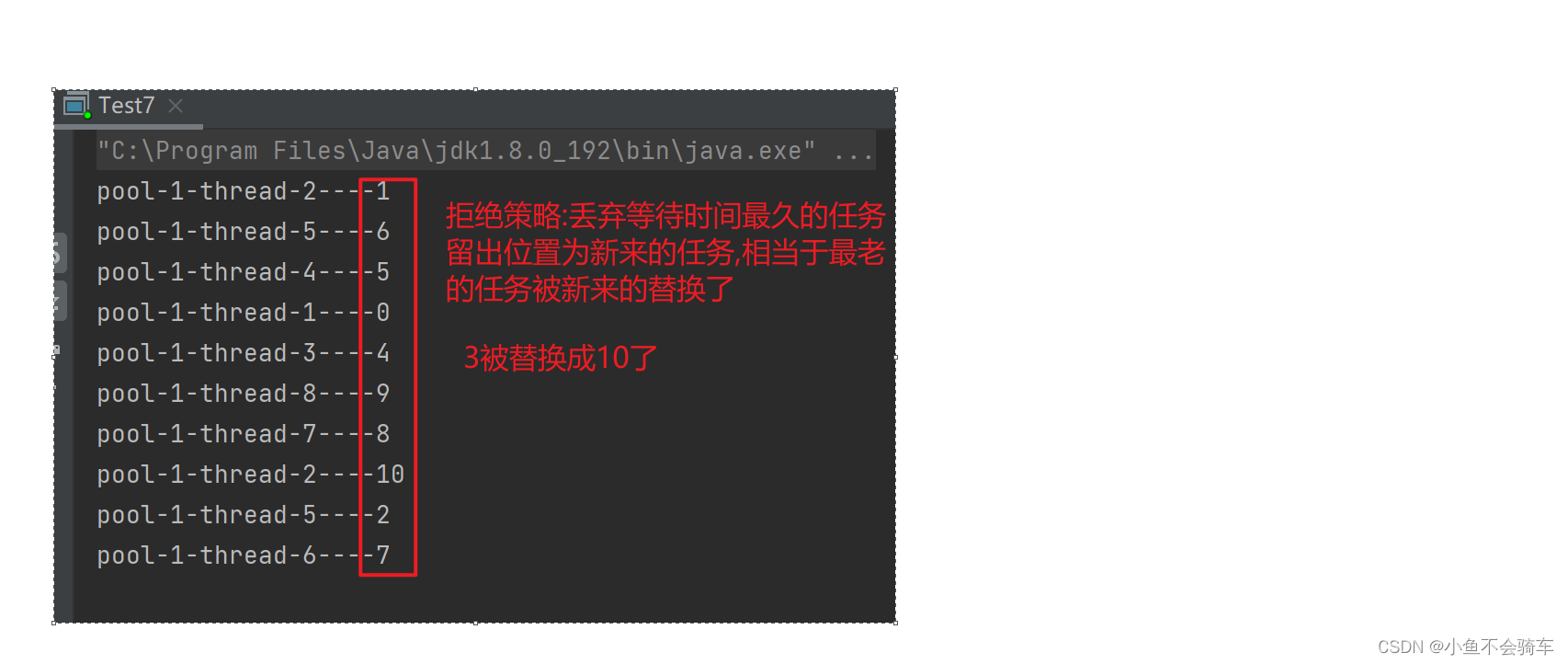
“ 在使用ChatGPT的神奇提示词Prompt时,或许你会发现它的效果并不总是如人所愿。让我们看看其中的原因,以及如何避免这类问题。”

01
—
最近继续在研究以大模型人工智能LLM为大脑的专属知识库的开发技术。偶然看到这么一个智力游戏题目,让大模型回答,检验模型的推理能力。
“You've got to defuse a bomb by placing exactly 5 gallons of water on a sensor.
The problem is, you only have a 4 gallon jug and a 3 gallons jug on hand! How can you achieve this task?“(你必须在传感器上放5加仑的水来拆除炸弹。问题是,你手头只有一个4加仑的罐子和一个3加仑的罐子!你怎样才能完成这项任务?)
照例扔给 ChatALL 这个工具,它会自动将一个问题发给多个大语言模型。工具的介绍、安装使用过程见文章《ChatALL:发现最佳答案的神奇AI机器人!》
ChatGPT3.5

前面的推理步骤对了,但是后面没对。
ChatGPT-4

这个回答对了。
讯飞星火

这个家伙在乱答。
谷歌的 Bard


前面推理解题的过程对了,但是下面每个步骤的容器所装的水,有不对的地方。
Claude2

很意外,英文的问题,模型也用了中文回答。个人猜测可能之前都是中文问问题,而且多次要求翻译,模型自动选择了中文回答问题。
但是推理过程也没对。
下面,神奇的地方来了。如果我把问题换成中文:“如何用一个4加仑和3加仑的水壶准确倒出5加仑的水?”,再次挨个提问大模型。
ChatGPT3.5居然挂了。

讯飞星火表现不错,前面推理部分对了,后面出错了。

谷歌的Bard回答跟英文一样,前面对,最后一步没对。


Claude2 表现比英文好

回答的推理过程,到第5步前面部分还是对的。
02
—
结果对比
ChatGPT4:完胜
ChatGPT3.5:英文进行了推理,没对,中文干脆回答不行。
Bard:中英文表现一致,都是前面的推理部分对了,后面不对。
讯飞星火:英文乱答,中文对了前面部分。
Claude2:不论中英文问题,会根据用户的偏好,使用同一种语言回答问题。但是推理过程不论中英文,前面对了部分,后面部分不对。
上面的对比结果,又一次证实了朋友刚刚交流说的“ GPT4确实比我见到的都显著强一些“。确实,要是不强,就对不起后面这句话:“岂止收费,还特别贵“。
在最开始使用 ChatALL 这个工具时,曾经用另外一道逻辑题比较各模型的推理能力:“一个猎人向南走了一英里,向东走了一英里,向北走了一英里,此时恰好回到起点。他看到一只熊,于是开枪打了它。这只熊是什么颜色的?”。比较的细节见文章《ChatALL:发现最佳答案的神奇AI机器人!》。
当时奇怪一点:“ChatGPT 和 Claude 居然挂了,没回答出来。但是通过 Poe 调用的ChatGPT3.5(Sage 也是基于 ChatGPT3.5) 回答了出来,这个就很意外,不知道直接调用,和通过 Poe 调用,是加了提示词的区别?“
通过这次切换提问的语言,确实发现了一个秘密:模型在不同的语言之间的推理能力是不同的。换句话说,ChatGPT 3.5 的英文推理能力比中文推理能力要强。
这也是为什么我最近在学习和研读用大模型做应用系统代码的时候,作者提醒用英文写 Prompt 的缘故。
把用户的提问翻译成英文,然后用英文的提示词 Prompt,获得 ChatGPT 大模型的回答后,再翻译成中文返回给最终用户。
所以,这种开发方案也解释了上面的疑惑。Poe 调用 ChatGPT 回答问题也应该是采用这种方式,所以通过Poe提问时,ChatGPT 3.5 实际用的是英文推理能力,它就能回答出熊是白色的。如果直接提问,因为中文推理能力不够,所以没有回答出来。
但是,ChatGPT 4 目前看起来中/英文推理能力都一样强悍,尚不清楚是在架构上做了调整,还是训练的数据集上加强了。外界只有一些猜测的信息:《Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本》
回到标题说的问题,为什么有时候我们拿到一个据说好用的提示词Prompt,但是效果没有想象中的好呢?两个原因:
大部分情况下,我们接触到的好用的提示词,是英文翻译成中文的。
在ChatGPT3.5上,大模型的英文推理能力比中文强。
例如这篇文章《被卖到 2w 的 ChatGPT 提示词 Prompt 你确定不想要吗?》,这里面提到的,这个被卖到2W的提示词是英文的,国内拿过来后,把它翻译成了英文,自然效果就没英文那么万能,以及效果打了折扣。
以及这篇文章《AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被"提示攻击"攻陷!》,对大模型进行提示攻击的,也是英文提示词。
03
—
熊是什么颜色的?
写到这里,我又好奇的测试了一下各模型,上面推理“熊的颜色”问题。
中文提问

四个模型表现不错,全部回答正确。
英文提问

看来模型们也在进化,至少这个曾经提过的问题,都已经可以正确回答了。
个人推测,模型厂商可能用添加知识库的方法修正了。
阅读推荐:
AI巨头对决:ChatGPT、Bard、Claude 同台竞技:解析一段相同的人工智能代码
教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + LangChain
AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被"提示攻击"攻陷!
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。