一、CFS调度器-基本原理
首先需要思考的问题是:什么是调度器(scheduler)?调度器的作用是什么?调度器是一个操作系统的核心部分。可以比作是CPU时间的管理员。调度器主要负责选择某些就绪的进程来执行。不同的调度器根据不同的方法挑选出最适合运行的进程。目前Linux支持的调度器就有RT scheduler、Deadline scheduler、CFS scheduler及Idle scheduler等。
1、什么是调度类
从Linux 2.6.23开始,Linux引入scheduling class的概念,目的是将调度器模块化。这样提高了扩展性,添加一个新的调度器也变得简单起来。一个系统中还可以共存多个调度器。在Linux中,将调度器公共的部分抽象,使用struct sched_class结构体描述一个具体的调度类。系统核心调度代码会通过struct sched_class结构体的成员调用具体调度类的核心算法。先简单的介绍下struct sched_class部分成员作用。
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
/* ... */
};
- next:next成员指向下一个调度类(比自己低一个优先级)。在Linux中,每一个调度类都是有明确的优先级关系,高优先级调度类管理的进程会优先获得cpu使用权。
- enqueue_task:向该调度器管理的runqueue中添加一个进程。我们把这个操作称为入队。
- dequeue_task:向该调度器管理的runqueue中删除一个进程。我们把这个操作称为出队。
- check_preempt_curr:当一个进程被唤醒或者创建的时候,需要检查当前进程是否可以抢占当前cpu上正在运行的进程,如果可以抢占需要标记TIF_NEED_RESCHED flag。
- pick_next_task:从runqueue中选择一个最适合运行的task。这也算是调度器比较核心的一个操作。例如,我们依据什么挑选最适合运行的进程呢?这就是每一个调度器需要关注的问题。
2、Linux中有哪些调度类
Linux中主要包含dl_sched_class、rt_sched_class、fair_sched_class及idle_sched_class等调度类。每一个进程都对应一种调度策略,每一种调度策略又对应一种调度类(每一个调度类可以对应多种调度策略)。例如实时调度器以优先级为导向选择优先级最高的进程运行。每一个进程在创建之后,总是要选择一种调度策略。针对不同的调度策略,选择的调度器也是不一样的。不同的调度策略对应的调度类如下表。
| 调度类 | 描述 | 调度策略 |
| dl_sched_class | deadline调度器 | SCHED_DEADLINE |
| rt_sched_class | 实时调度器 | SCHED_FIFO、SCHED_RR |
| fair_sched_class | 完全公平调度器 | SCHED_NORMAL、SCHED_BATCH |
| idle_sched_class | idle task | SCHED_IDLE |
针对以上调度类,系统中有明确的优先级概念。每一个调度类利用next成员构建单项链表。优先级从高到低示意图如下:
sched_class_highest----->stop_sched_class
.next---------->dl_sched_class
.next---------->rt_sched_class
.next--------->fair_sched_class
.next----------->idle_sched_class
.next = NULL
Linux调度核心在选择下一个合适的task运行的时候,会按照优先级的顺序便利调度类的pick_next_task函数。因此,SCHED_FIFO调度策略的实时进程永远比SCHED_NORMAL调度策略的普通进程优先运行。代码中pick_next_task函数也有体现。pick_next_task函数就是负责选择一个即将运行的进程,以下贴出省略版代码。
static inline struct task_struct *pick_next_task(struct rq *rq,
struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
for_each_class(class) { /* 按照优先级顺序便利所有的调度类,通过next指针便利单链表 */
p = class->pick_next_task(rq, prev, rf);
if (p)
return p;
}
}
针对CFS调度器,管理的进程都属于SCHED_NORMAL或者SCHED_BATCH策略。后面的部分主要针对CFS调度器讲解。
3、普通进程的优先级
CFS是Completely Fair Scheduler简称,即完全公平调度器。CFS的设计理念是在真实硬件上实现理想的、精确的多任务CPU。CFS调度器和以往的调度器不同之处在于没有时间片的概念,而是分配cpu使用时间的比例。例如:2个相同优先级的进程在一个cpu上运行,那么每个进程都将会分配50%的cpu运行时间。这就是要实现的公平。
以上举例是基于同等优先级的情况下。但是现实却并非如此,有些任务优先级就是比较高。那么CFS调度器的优先级是如何实现的呢?首先,我们引入权重的概念,权重代表着进程的优先级。各个进程之间按照权重的比例分配cpu时间。例如:2个进程A和B。A的权重是1024,B的权重是2048。那么A获得cpu的时间比例是1024/(1024+2048) = 33.3%。B进程获得的cpu时间比例是2048/(1024+2048)=66.7%。我们可以看出,权重越大分配的时间比例越大,相当于优先级越高。在引入权重之后,分配给进程的时间计算公式如下:
分配给进程的时间 = 总的cpu时间 * 进程的权重/就绪队列(runqueue)所有进程权重之和
CFS调度器针对优先级又提出了nice值的概念,其实和权重是一一对应的关系。nice值就是一个具体的数字,取值范围是[-20, 19]。数值越小代表优先级越大,同时也意味着权重值越大,nice值和权重之间可以互相转换。内核提供了一个表格转换nice值和权重。
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
数组的值可以看作是公式:weight = 1024 / 1.25nice计算得到。公式中的1.25取值依据是:进程每降低一个nice值,将多获得10% cpu的时间。公式中以1024权重为基准值计算得来,1024权重对应nice值为0,其权重被称为NICE_0_LOAD。默认情况下,大部分进程的权重基本都是NICE_0_LOAD。
4、调度延迟
什么是调度延迟?调度延迟就是保证每一个可运行进程都至少运行一次的时间间隔。例如,每个进程都运行10ms,系统中总共有2个进程,那么调度延迟就是20ms。如果有5个进程,那么调度延迟就是50ms。如果现在保证调度延迟不变,固定是6ms,那么系统中如果有2个进程,那么每个进程运行3ms。如果有6个进程,那么每个进程运行1ms。如果有100个进程,那么每个进程分配到的时间就是0.06ms。随着进程的增加,每个进程分配的时间在减少,进程调度过于频繁,上下文切换时间开销就会变大。因此,CFS调度器的调度延迟时间的设定并不是固定的。当系统处于就绪态的进程少于一个定值(默认值8)的时候,调度延迟也是固定一个值不变(默认值6ms)。当系统就绪态进程个数超过这个值时,我们保证每个进程至少运行一定的时间才让出cpu。这个“至少一定的时间”被称为最小粒度时间。在CFS默认设置中,最小粒度时间是0.75ms。用变量sysctl_sched_min_granularity记录。因此,调度周期是一个动态变化的值。调度周期计算函数是__sched_period()。
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
nr_running是系统中就绪进程数量,当超过sched_nr_latency时,我们无法保证调度延迟,因此转为保证调度最小粒度。如果nr_running并没有超过sched_nr_latency,那么调度周期就等于调度延迟sysctl_sched_latency(6ms)。
5、虚拟时间(virtual time)
CFS调度器的目标是保证每一个进程的完全公平调度。CFS调度器就像是一个母亲,她有很多个孩子(进程)。但是,手上只有一个玩具(cpu)需要公平的分配给孩子玩。假设有2个孩子,那么一个玩具怎么才可以公平让2个孩子玩呢?简单点的思路就是第一个孩子玩10分钟,然后第二个孩子玩10分钟,以此循环下去。CFS调度器也是这样记录每一个进程的执行时间,保证每个进程获取CPU执行时间的公平。因此,哪个进程运行的时间最少,应该让哪个进程运行。
例如,调度周期是6ms,系统一共2个相同优先级的进程A和B,那么每个进程都将在6ms周期时间内内各运行3ms。如果进程A和B,他们的权重分别是1024和820(nice值分别是0和1)。进程A获得的运行时间是6x1024/(1024+820)=3.3ms,进程B获得的执行时间是6x820/(1024+820)=2.7ms。进程A的cpu使用比例是3.3/6x100%=55%,进程B的cpu使用比例是2.7/6x100%=45%。计算结果也符合上面说的“进程每降低一个nice值,将多获得10% CPU的时间”。很明显,2个进程的实际执行时间是不相等的,但是CFS想保证每个进程运行时间相等。因此CFS引入了虚拟时间的概念,也就是说上面的2.7ms和3.3ms经过一个公式的转换可以得到一样的值,这个转换后的值称作虚拟时间。这样的话,CFS只需要保证每个进程运行的虚拟时间是相等的即可。虚拟时间vriture_runtime和实际时间(wall time)转换公式如下:
NICE_0_LOAD
vriture_runtime = wall_time * ----------------
weight
进程A的虚拟时间3.3 * 1024 / 1024 = 3.3ms,我们可以看出nice值为0的进程的虚拟时间和实际时间是相等的。进程B的虚拟时间是2.7 * 1024 / 820 = 3.3ms。我们可以看出尽管A和B进程的权重值不一样,但是计算得到的虚拟时间是一样的。因此CFS主要保证每一个进程获得执行的虚拟时间一致即可。在选择下一个即将运行的进程的时候,只需要找到虚拟时间最小的进程即可。为了避免浮点数运算,因此我们采用先放大再缩小的方法以保证计算精度。内核又对公式做了如下转换。
NICE_0_LOAD
vriture_runtime = wall_time * ----------------
weight
NICE_0_LOAD * 2^32
= (wall_time * -------------------------) >> 32
weight
2^32
= (wall_time * NICE_0_LOAD * inv_weight) >> 32 (inv_weight = ------------ )
weight
权重的值已经计算保存到sched_prio_to_weight数组中,根据这个数组我们可以很容易计算inv_weight的值。内核中使用sched_prio_to_wmult数组保存inv_weight的值。计算公式是:sched_prio_to_wmult[i] = 232/sched_prio_to_weight[i]。
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
系统中使用struct load_weight结构体描述进程的权重信息。weight代表进程的权重,inv_weight等于232/weight。
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
将实际时间转换成虚拟时间的实现函数是calc_delta_fair()。calc_delta_fair()调用__calc_delta()函数,__calc_delta()主要功能是实现如下公式的计算。
__calc_delta() = (delta_exec * weight * lw->inv_weight) >> 32
weight 2^32
= delta_exec * ---------------- (lw->inv_weight = --------------- )
lw->weight lw->weight
和上面计算虚拟时间计算公式对比发现。如果需要计算进程的虚拟时间,这里的weight只需要传递参数NICE_0_LOAD,lw参数是进程对应的struct load_weight结构体。
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);
int shift = 32;
__update_inv_weight(lw);
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
按照上面说的理论,calc_delta_fair()函数调用__calc_delta()的时候传递的weight参数是NICE_0_LOAD,lw参数是进程对应的struct load_weight结构体。
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD)) /* 1 */
delta = __calc_delta(delta, NICE_0_LOAD, &se->load); /* 2 */
return delta;
}
- 按照之前的理论,nice值为0(权重是NICE_0_LOAD)的进程的虚拟时间和实际时间是相等的。因此如果进程的权重是NICE_0_LOAD,进程对应的虚拟时间就不用计算。
- 调用__calc_delta()函数。
Linux通过struct task_struct结构体描述每一个进程。但是调度类管理和调度的单位是调度实体,并不是task_struct。在支持组调度的时候,一个组也会抽象成一个调度实体,它并不是一个task。所以,我们在struct task_struct结构体中可以找到以下不同调度类的调度实体。
struct task_struct {
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
/* ... */
}
se、rt、dl分别对应CFS调度器、RT调度器、Deadline调度器的调度实体。
struct sched_entity结构体描述调度实体,包括struct load_weight用来记录权重信息。除此以外我们一直关心的时间信息,肯定也要一起记录。struct sched_entity结构体简化后如下:
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
unsigned int on_rq;
u64 sum_exec_runtime;
u64 vruntime;
};
- load:权重信息,在计算虚拟时间的时候会用到inv_weight成员。
- run_node:CFS调度器的每个就绪队列维护了一颗红黑树,上面挂满了就绪等待执行的task,run_node就是挂载点。
- on_rq:调度实体se加入就绪队列后,on_rq置1。从就绪队列删除后,on_rq置0。
- sum_exec_runtime:调度实体已经运行实际时间总合。
- vruntime:调度实体已经运行的虚拟时间总合。
6、就绪队列(runqueue)
系统中每个CPU都会有一个全局的就绪队列(cpu runqueue),使用struct rq结构体描述,它是per-cpu类型,即每个cpu上都会有一个struct rq结构体。每一个调度类也有属于自己管理的就绪队列。例如,struct cfs_rq是CFS调度类的就绪队列,管理就绪态的struct sched_entity调度实体,后续通过pick_next_task接口从就绪队列中选择最适合运行的调度实体(虚拟时间最小的调度实体)。struct rt_rq是实时调度器就绪队列。struct dl_rq是Deadline调度器就绪队列。
struct rq {
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
};
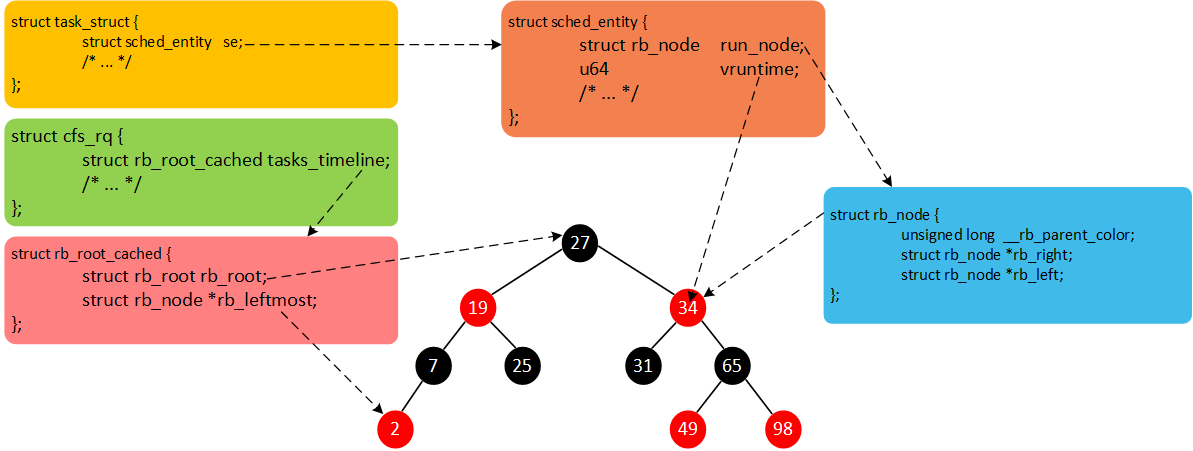
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
struct cfs_rq {
struct load_weight load;
unsigned int nr_running;
u64 min_vruntime;
struct rb_root_cached tasks_timeline;
};
- load:就绪队列权重,就绪队列管理的所有调度实体权重之和。
- nr_running:就绪队列上调度实体的个数。
- min_vruntime:跟踪就绪队列上所有调度实体的最小虚拟时间。
- tasks_timeline:用于跟踪调度实体按虚拟时间大小排序的红黑树的信息(包含红黑树的根以及红黑树中最左边节点)。
CFS维护了一个按照虚拟时间排序的红黑树,所有可运行的调度实体按照p->se.vruntime排序插入红黑树。如下图所示。

CFS选择红黑树最左边的进程运行。随着系统时间的推移,原来左边运行过的进程慢慢的会移动到红黑树的右边,原来右边的进程也会最终跑到最左边。因此红黑树中的每个进程都有机会运行。
现在我们总结一下。Linux中所有的进程使用task_struct描述。task_struct包含很多进程相关的信息(例如,优先级、进程状态以及调度实体等)。但是,每一个调度类并不是直接管理task_struct,而是引入调度实体的概念。CFS调度器使用sched_entity跟踪调度信息。CFS调度器使用cfs_rq跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。tasks_timeline->rb_root是红黑树的根,tasks_timeline->rb_leftmost指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体(为了更快的选择最适合运行的调度实体,因此rb_leftmost相当于一个缓存)。每个就绪态的调度实体sched_entity包含插入红黑树中使用的节点rb_node,同时vruntime成员记录已经运行的虚拟时间。我们将这几个数据结构简单梳理,如下图所示。
二、CFS调度器-源码解析
1、进程的创建
进程的创建是通过do_fork()函数完成。新进程的诞生,我们调度核心层会通知调度类,调用特别的接口函数初始化新生儿。我们一路尾随do_fork()函数。do_fork()---->_do_fork()---->copy_process()---->sched_fork()。针对sched_fork()函数,删减部分代码如下:
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->state = TASK_NEW;
p->prio = current->normal_prio;
p->sched_class = &fair_sched_class; /* 1 */
if (p->sched_class->task_fork)
p->sched_class->task_fork(p); /* 2 */
return 0;
}
- 我们这里以CFS为例,为task选择调度类。fair_sched_class是CFS调度类。
- 调用调度类中的task_fork函数。task_fork方法主要做fork相关的操作。传递的参数p就是创建的task_struct。
CFS调度类fair_sched_class方法如下:
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_common,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
};
task_fork_fair实现如下:
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr; /* 1 */
if (curr) {
update_curr(cfs_rq); /* 2 */
se->vruntime = curr->vruntime; /* 3 */
}
place_entity(cfs_rq, se, 1); /* 4 */
se->vruntime -= cfs_rq->min_vruntime; /* 5 */
rq_unlock(rq, &rf);
}
- cfs_rq是CFS调度器就绪队列,curr指向当前正在cpu上运行的task的调度实体。
- update_curr()函数是比较重要的函数,在很多地方调用,主要是更新当前正在运行的调度实体的运行时间信息。
- 初始化当前创建的新进程的虚拟时间。
- place_entity()函数在进程创建以及唤醒的时候都会调用,创建进程的时候传递参数initial=1。主要目的是更新调度实体得到虚拟时间(se->vruntime成员)。要和cfs_rq->min_vruntime的值保持差别不大,如果非常小的话,岂不是要上天(疯狂占用cpu运行)。
- 这里为什么要减去cfs_rq->min_vruntime呢?因为现在计算进程的vruntime是基于当前cpu上的cfs_rq,并且现在还没有加入当前cfs_rq的就绪队列上。等到当前进程创建完毕开始唤醒的时候,加入的就绪队列就不一定是现在计算基于的cpu。所以,在加入就绪队列的函数中会根据情况加上当前就绪队列cfs_rq->min_vruntime。为什么要“先减后加”处理呢?假设cpu0上的cfs就绪队列的最小虚拟时间min_vruntime的值是1000000,此时创建进程的时候赋予当前进程虚拟时间是1000500。但是,唤醒此进程加入的就绪队列却是cpu1上CFS就绪队列,cpu1上的cfs就绪队列的最小虚拟时间min_vruntime的值如果是9000000。如果不采用“先减后加”的方法,那么该进程在cpu1上运行肯定是“乐坏”了,疯狂的运行。现在的处理计算得到的调度实体的虚拟时间是1000500 - 1000000 + 9000000 = 9000500,因此事情就不是那么的糟糕。
下面就对update_curr()一探究竟。
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start; /* 1 */
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
curr->sum_exec_runtime += delta_exec;
curr->vruntime += calc_delta_fair(delta_exec, curr); /* 2 */
update_min_vruntime(cfs_rq); /* 3 */
}
- delta_exec计算本次更新虚拟时间距离上次更新虚拟时间的差值。
- 更新当前调度实体虚拟时间,calc_delta_fair()函数根据上面说的虚拟时间的计算公式计算虚拟时间(也就是调用__calc_delta()函数)。
- 更新CFS就绪队列的最小虚拟时间min_vruntime。min_vruntime也是不断更新的,主要就是跟踪就绪队列中所有调度实体的最小虚拟时间。如果min_vruntime一直不更新的话,由于min_vruntime太小,导致后面创建的新进程根据这个值来初始化新进程的虚拟时间,岂不是新创建的进程有可能再一次疯狂了。这一次可能就是cpu0创建,在cpu0上面疯狂。
我们就看看update_min_vruntime()是怎么更新min_vruntime的。
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
struct rb_node *leftmost = rb_first_cached(&cfs_rq->tasks_timeline);
u64 vruntime = cfs_rq->min_vruntime;
if (curr) {
if (curr->on_rq)
vruntime = curr->vruntime;
else
curr = NULL;
}
if (leftmost) { /* non-empty tree */
struct sched_entity *se;
se = rb_entry(leftmost, struct sched_entity, run_node);
if (!curr)
vruntime = se->vruntime;
else
vruntime = min_vruntime(vruntime, se->vruntime);
}
/* ensure we never gain time by being placed backwards. */
cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);
}
我们既然要更细就绪队列最小虚拟时间min_vruntime,试想一下,拥有最小虚拟时间的地方有哪些了?
- 就绪队列本身的cfs_rq->min_vruntime成员。
- 当前正在运行的进程的最下虚拟时间,因为CFS调度器选择最适合运行的进程是选择维护的红黑树中虚拟时间最小的进程。
- 如果在当前进程运行的过程中,有进程加入就绪队列,那么红黑树最左边的进程的虚拟时间同样也有可能是最小的虚拟时间。
因此,update_min_vruntime()函数根据以上种种可能判断,并且保证就绪队列的最小虚拟时间min_vruntime单调递增的特性,更新最小虚拟时间。
我们继续place_entity()函数。
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se); /* 1 */
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh; /* 2 */
}
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime); /* 3 */
}
- 如果是创建进程调用该函数的话,参数initial参数是1。因此这里是处理创建的进程,针对刚创建的进程会进行一定的惩罚,将虚拟时间加上一个值就是惩罚,毕竟虚拟时间越小越容易被调度执行。惩罚的时间由sched_vslice()计算。
- 这里主要是针对唤醒的进程,针对睡眠很久的的进程,我们总是期望它很快得到调度执行,毕竟人家睡了那么久。所以这里减去一定的虚拟时间作为补偿。
- 我们保证调度实体的虚拟时间不能倒退。为何呢?可以想一下,如果一个进程刚睡眠1ms,然后醒来后你却要奖励3ms(虚拟时间减去3ms),然后他竟然赚了2ms。作为调度器,我们不做亏本生意。你睡眠100ms,奖励你3ms,那就是没问题的。
新创建的进程惩罚的时间是多少
有上面可知,惩罚的时间计算函数是sched_vslice()函数。
static u64 sched_vslice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
return calc_delta_fair(sched_slice(cfs_rq, se), se);
}
calc_delta_fair()函数上面已经分析过,计算实际运行时间delta对应的虚拟时间。这里的delta是sched_slice()函数计算。
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq); /* 1 */
for_each_sched_entity(se) { /* 2 */
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load; /* 3 */
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load); /* 4 */
}
return slice;
}
- __sched_period()前面已经提到了,根据就绪队列调度实体个数计算调度周期。
- 针对没有使能组调度的情况下,for_each_sched_entity(se)就是for (; se; se = NULL),循环一次。
- 得到就绪队列的权重,也就是就绪队列上所有调度实体权重之和。
- __calc_delta()函数有两个功能,除了上面说的可以计算进程运行时间转换成虚拟时间以外,还有第二个功能:计算调度实体se的权重占整个就绪队列权重的比例,然后乘以调度周期时间即可得到当前调度实体应该运行的时间(参数weught传递调度实体se权重,参数lw传递就绪队列权重cfs_rq->load)。例如,就绪队列权重是3072,当前调度实体se权重是1024,调度周期是6ms,那么调度实体应该得到的时间是6*1024/3072=2ms。
2、新进程加入就绪队列
经过do_fork()的大部分初始化工作完成之后,我们就可以唤醒新进程准别运行。也就是将新进程加入就绪队列准备调度。唤醒新进程的流程如下图。
do_fork()--->_do_fork()--->wake_up_new_task()--->activate_task()--->enqueue_task()--->enqueue_task_fair()
|
+------------>check_preempt_curr()--->check_preempt_wakeup()
wake_up_new_task()负责唤醒新创建的进程。简化一下函数如下。
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
p->state = TASK_RUNNING;
#ifdef CONFIG_SMP
p->recent_used_cpu = task_cpu(p);
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0)); /* 1 */
#endif
rq = __task_rq_lock(p, &rf);
activate_task(rq, p, ENQUEUE_NOCLOCK); /* 2 */
p->on_rq = TASK_ON_RQ_QUEUED;
check_preempt_curr(rq, p, WF_FORK); /* 3 */
}
- 通过调用select_task_rq()函数重新选择cpu,通过调用调度类中select_task_rq方法选择调度类中最空闲的cpu。
- 将进程加入就绪队列,通过调用调度类中enqueue_task方法。
- 既然新进程已经准备就绪,那么此时需要检查新进程是否满足抢占当前正在运行进程的条件,如果满足抢占条件需要设置TIF_NEED_RESCHED标志位。
CFS调度类对应的enqueue_task方法函数是enqueue_task_fair(),我们将部分和组调度相关的代码删除,简洁的代码看起来才赏心悦目。
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se) { /* 1 */
if (se->on_rq) /* 2 */
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags); /* 3 */
}
if (!se)
add_nr_running(rq, 1);
hrtick_update(rq);
}
- 组调度关闭的时候,这里就是循环一次,不用纠结。
- on_rq成员代表调度实体是否已经在就绪队列中。值为1代表在就绪队列中,当然就不需要继续添加就绪队列了。
- enqueue_entity,从名字就可以看得出来是将调度实体加入就绪队列,我们称之为入队(enqueue)。
enqueue_entity()代码如下,删除了一些暂时不需要关注的部分代码。
static void enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED);
bool curr = cfs_rq->curr == se;
/*
* If we're the current task, we must renormalise before calling
* update_curr().
*/
if (renorm && curr)
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq); /* 1 */
if (renorm && !curr)
se->vruntime += cfs_rq->min_vruntime; /* 2 */
account_entity_enqueue(cfs_rq, se); /* 3 */
if (flags & ENQUEUE_WAKEUP)
place_entity(cfs_rq, se, 0); /* 4 */
if (!curr)
__enqueue_entity(cfs_rq, se); /* 5 */
se->on_rq = 1; /* 6 */
}
- update_curr()顺便更新当前运行调度实体的虚拟时间信息。
- 还记得之前在task_fork_fair()函数最后减去的min_vruntime吗?现在是时候加回来了。
- 更新就绪队列相关信息,例如就绪队列的权。
- 针对唤醒的进程(flag有ENQUEUE_WAKEUP标识),我们是需要根据情况给予一定的补偿。之前也说了place_entity()函数的两种情况下的作用。当然这里针对新进程第一次加入就绪队列是不需要调用的。
- __enqueue_entity()才是将se加入就绪队列维护的红黑树中,所有的se以vruntime为key。
- 所有的操作完毕也意味着se已经加入就绪队列,置位on_rq成员。
account_entity_enqueue()函数到底更新了就绪队列哪些信息呢?
static void account_entity_enqueue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_add(&cfs_rq->load, se->load.weight); /* 1 */
if (!parent_entity(se))
update_load_add(&rq_of(cfs_rq)->load, se->load.weight); /* 2 */
#ifdef CONFIG_SMP
if (entity_is_task(se)) {
struct rq *rq = rq_of(cfs_rq);
account_numa_enqueue(rq, task_of(se));
list_add(&se->group_node, &rq->cfs_tasks); /* 3 */
}
#endif
cfs_rq->nr_running++; /* 4 */
}
- 更新就绪队列权重,就是将se权重加在就绪队列权重上面。
- cpu就绪队列struct rq同样也需要更新权重信息。
- 将调度实体se加入链表。
- nr_running成员是就绪队列中所有调度实体的个数。
vruntime溢出怎么办
虽然调度实体se的vruntime成员是u64类型,可以保存非常大的数。但是当达到264ns后就溢出了。那么溢出会有问题吗?我们先看看__enqueue_entity()函数加入就绪队列的代码。
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
bool leftmost = true;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = false;
}
}
rb_link_node(&se->run_node, parent, link);
rb_insert_color_cached(&se->run_node, &cfs_rq->tasks_timeline, leftmost);
}
我们通过便利红黑树查找符合插入节点的位置。利用entity_before()函数比较两个调度实体se的vruntime值大小,以确定搜索方向。
static inline int entity_before(struct sched_entity *a, struct sched_entity *b)
{
return (s64)(a->vruntime - b->vruntime) < 0;
}
假设要插入a的vruntime是101,b的vruntime是100,那么entity_before()函数返回0。现在假设a的vruntime溢出了,vruntime是5(我们期望是264 + 5,但是很遗憾溢出结果是5),b的vruntime即将溢出,vruntime的值是264 - 2。那么调度实体a的vruntime无论是5还是264 + 5,entity_before()函数都会返回0。因此计算结果保持了一致性,所以溢出是没有任何问题的。要看懂这里的代码,需要对负数在计算机中表示形式有所了解。
同样样的C语言技巧还应用在就绪队列min_vruntime成员,试想min_vruntime同样式u64类型也是存在溢出的时候。min_vruntime的溢出是否会有问题呢?其实也不会,我们继续看一下update_min_vruntime函数最后一条代码,cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);max_vruntime()函数也利用了类似entity_before()函数的技巧。所以min_vruntime溢出也不会有问题。max_vruntime()依然可以返回正确的结果。
static inline u64 max_vruntime(u64 max_vruntime, u64 vruntime)
{
s64 delta = (s64)(vruntime - max_vruntime);
if (delta > 0)
max_vruntime = vruntime;
return max_vruntime;
}
抢占当前进程条件
当唤醒一个新进程的时候,此时也是一个检测抢占的机会。因为唤醒的进程有可能具有更高的优先级或者更小的虚拟时间。紧接上节唤醒新进程后调用check_preempt_curr()函数检查是否满足抢占条件。
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
if (p->sched_class == rq->curr->sched_class) {
rq->curr->sched_class->check_preempt_curr(rq, p, flags); /* 1 */
} else {
for_each_class(class) { /* 2 */
if (class == rq->curr->sched_class)
break;
if (class == p->sched_class) {
resched_curr(rq);
break;
}
}
}
}
- 唤醒的进程和当前的进程同属于一个调度类,直接调用调度类的check_preempt_curr方法检查抢占条件。毕竟调度器自己管理的进程,自己最清楚是否适合抢占当前进程。
- 如果唤醒的进程和当前进程不属于一个调度类,就需要比较调度类的优先级。例如,当期进程是CFS调度类,唤醒的进程是RT调度类,自然实时进程是需要抢占当前进程的,因为优先级更高。
现在考虑唤醒的进程和当前的进程同属于一个CFS调度类的情况。自然调用的就是check_preempt_wakeup()函数。
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
if (wakeup_preempt_entity(se, pse) == 1) /* 1 */
goto preempt;
return;
preempt:
resched_curr(rq); /* 2 */
}
- 检查唤醒的进程是否满足抢占当前进程的条件。
- 如果可以抢占当前进程,设置TIF_NEED_RESCHED flag。
wakeup_preempt_entity()函数如下。
/*
* Should 'se' preempt 'curr'.
*/
static int wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;
if (vdiff <= 0) /* 1 */
return -1;
gran = wakeup_gran(se);
if (vdiff > gran) /* 2 */
return 1;
return 0;
}
wakeup_preempt_entity()函数可以返回3种结果。se1、se2、se3及curr调度实体的虚拟时间如下图所示。如果curr虚拟时间比se小,返回-1;如果curr虚拟时间比se大,并且两者差值小于gran,返回0;否则返回1。默认情况下,wakeup_gran()函数返回的值是1ms根据调度实体se的权重计算的虚拟时间。因此,满足抢占的条件就是,唤醒的进程的虚拟时间首先要比正在运行进程的虚拟时间小,并且差值还要大于一定的值才行(这个值是sysctl_sched_wakeup_granularity,称作唤醒抢占粒度)。这样做的目的是避免抢占过于频繁,导致大量上下文切换影响系统性能。
se3 se2 curr se1
------|---------------|------|-----------|--------> vruntime
|<------gran------>|
wakeup_preempt_entity(curr, se1) = -1
wakeup_preempt_entity(curr, se2) = 0
wakeup_preempt_entity(curr, se3) = 1
3、周期性调度
周期性调度是指Linux定时周期性地检查当前任务是否耗尽当前进程的时间片,并检查是否应该抢占当前进程。一般会在定时器的中断函数中,通过一层层函数调用最终到scheduler_tick()函数。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0); /* 1 */
cpu_load_update_active(rq);
calc_global_load_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq); /* 2 */
#endif
}
- 调用调度类对应的task_tick方法,针对CFS调度类该函数是task_tick_fair。
- 触发负载均衡,以后有时间可以详谈。
task_tick_fair()函数如下。
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
}
for循环是针对组调度,组调度未打开的情况下,这里就是一层循环。
entity_tick()是主要干活的。
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq); /* 1 */
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr); /* 2 */
}
- 调用update_curr()更新当前运行的调度实体的虚拟时间等信息。
- 如果就绪队列就绪态的调度实体个数大于1需要检查是否满足抢占条件,如果可以抢占就设置TIF_NEED_RESCHED flag。
check_preempt_tick()函数如下。
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr); /* 1 */
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; /* 2 */
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq)); /* 3 */
clear_buddies(cfs_rq, curr);
return;
}
if (delta_exec < sysctl_sched_min_granularity) /* 4 */
return;
se = __pick_first_entity(cfs_rq); /* 5 */
delta = curr->vruntime - se->vruntime;
if (delta < 0) /* 6 */
return;
if (delta > ideal_runtime) /* 7 */
resched_curr(rq_of(cfs_rq));
}
- sched_slice()函数上面已经分析过,计算curr进程在本次调度周期中应该分配的时间片。时间片用完就应该被抢占。
- delta_exec是当前进程已经运行的实际时间。
- 如果实际运行时间已经超过分配给进程的时间片,自然就需要抢占当前进程。设置TIF_NEED_RESCHED flag。
- 为了防止频繁过度抢占,我们应该保证每个进程运行时间不应该小于最小粒度时间sysctl_sched_min_granularity。因此如果运行时间小于最小粒度时间,不应该抢占。
- 从红黑树中找到虚拟时间最小的调度实体。
- 如果当前进程的虚拟时间仍然比红黑树中最左边调度实体虚拟时间小,也不应该发生调度。
- 这里把虚拟时间和实际时间比较,看起来很奇怪。感觉就像是bug一样,然后经过查看提交记录,作者的意图是:希望权重小的任务更容易被抢占。
针对以上每一次周期调度(scheduling tick )流程可以总结如下。
- 更新当前正在运行进程的虚拟时间。
- 检查当前进程是否满足被抢占的条件。
-
- if (delta_exec > ideal_runtime),然后置位TIF_NEED_RESCHED。
- 检查TIF_NEED_RESCHED flag。
-
- 如果置位,从就绪队列中挑选最小虚拟时间的进程运行。
- 将当前被强占的进程重新加入就绪队列红黑树上(enqueue task)。
- 从就绪队列红黑树上删除即将运行进程的节点(dequeue task)。
4、如何选择下一个合适进程运行
当进程被设置TIF_NEED_RESCHED flag后会在某一时刻触发系统发生调度或者进程调用schedule()函数主动放弃cpu使用权,触发系统调度。我们就以schedule()函数为例分析。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
主要干活的还是__schedule()函数。
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); /* 1 */
prev->on_rq = 0;
}
}
next = pick_next_task(rq, prev, &rf); /* 2 */
clear_tsk_need_resched(prev); /* 3 */
if (likely(prev != next)) {
rq->curr = next;
rq = context_switch(rq, prev, next, &rf); /* 4 */
}
balance_callback(rq);
}
- 针对主动放弃cpu进入睡眠的进程,我们需要从对应的就绪队列上删除该进程。
- 选择下个合适的进程开始运行,该函数前面已经分析过。
- 清除TIF_NEED_RESCHED flag。
- 上下文切换,从prev进程切换到next进程。
CFS调度类pick_next_task方法是pick_next_task_fair()函数。
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
if (!cfs_rq->nr_running)
goto idle;
put_prev_task(rq, prev); /* 1 */
do {
se = pick_next_entity(cfs_rq, NULL); /* 2 */
set_next_entity(cfs_rq, se); /* 3 */
cfs_rq = group_cfs_rq(se);
} while (cfs_rq); /* 4 */
p = task_of(se);
#ifdef CONFIG_SMP
list_move(&p->se.group_node, &rq->cfs_tasks);
#endif
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
return p;
idle:
new_tasks = idle_balance(rq, rf);
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
return NULL;
}
- 主要是处理prev进程的后事,当进程让出cpu时就会调用该函数。
- 选择最适合运行的调度实体。
- 选择出来的调度实体se还需要继续加工一下才能投入运行,加工的活就是由set_next_entity()函数负责。
- 针对没有使能组调度的情况下,循环一次就结束了。
put_prev_task()究竟处理了哪些后事呢?CFS调度类put_prev_task方法的函数是put_prev_task_fair()。
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) { /* 1 */
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se); /* 2 */
}
}
- 针对组调度情况,暂不考虑。
- put_prev_entity()是主要干活的部分。
put_prev_entity()函数如下。
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
/*
* If still on the runqueue then deactivate_task()
* was not called and update_curr() has to be done:
*/
if (prev->on_rq) /* 1 */
update_curr(cfs_rq);
if (prev->on_rq) {
/* Put 'current' back into the tree. */
__enqueue_entity(cfs_rq, prev); /* 2 */
/* in !on_rq case, update occurred at dequeue */
update_load_avg(cfs_rq, prev, 0); /* 3 */
}
cfs_rq->curr = NULL; /* 4 */
}
- 如果prev进程依然在就绪队列上,极有可能是prev进程被强占的情况。在让出cpu之前需要更新进程虚拟时间等信息。如果prev进程不在就绪队列上,这里可以直接跳过更新。因为,prev进程在deactivate_task()中已经调用了update_curr(),所以这里就可以省略了。
- 如果prev进程依然在就绪队列上,我们需要重新将prev进程插入红黑树等待调度。
- update_load_avg()是更新prev进程的负载信息,这些信息在负载均衡的时候会用到。
- 后事已经处理完毕,就绪队列的curr指针也应该指向NULL,代表当前就绪队列上没有正在运行的进程。
prev进程的后事已经处理完毕,接下来继承大统的进程需要借助set_next_entity()函数昭告天下。
static void
set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* 'current' is not kept within the tree. */
if (se->on_rq) {
__dequeue_entity(cfs_rq, se); /* 1 */
update_load_avg(cfs_rq, se, UPDATE_TG); /* 2 */
}
cfs_rq->curr = se; /* 3 */
update_stats_curr_start(cfs_rq, se); /* 4 */
se->prev_sum_exec_runtime = se->sum_exec_runtime; /* 5 */
}
- __dequeue_entity()是将调度实体从红黑树中删除,针对即将运行的进程,我们都会从红黑树中删除当前进程。当进程被强占后,调用put_prev_entity()函数会重新插入红黑树。因此这个地方和put_prev_entity()函数中加入红黑树是个呼应。
- 更新进程的负载信息。负载均衡会使用。
- 更新就绪队列curr成员,昭告天下,“现在我是当前正在运行的进程”。
- update_stats_curr_start()函数就一句话,更新调度实体exec_start成员,为update_curr()函数统计时间做准备。
- check_preempt_tick()函数用到,统计当前进程已经运行的时间,以此判断是否能够被其他进程抢占。
5、进程的睡眠
在__schedule()函数中,如果prev进程主动睡眠。那么会调用deactivate_task()函数。deactivate_task()函数最终会调用调度类dequeue_task方法。CFS调度类对应的函数是dequeue_task_fair(),该函数是enqueue_task_fair()函数反操作。
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int task_sleep = flags & DEQUEUE_SLEEP;
for_each_sched_entity(se) { /* 1 */
cfs_rq = cfs_rq_of(se);
dequeue_entity(cfs_rq, se, flags); /* 2 */
}
if (!se)
sub_nr_running(rq, 1);
}
- 针对组调度操作,没有使能组调度情况下,循环仅一次。
- 将调度实体se从对应的就绪队列cfs_rq上删除。
dequeue_entity()函数如下。
static void dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
update_curr(cfs_rq); /* 1 */
if (se != cfs_rq->curr)
__dequeue_entity(cfs_rq, se); /* 2 */
se->on_rq = 0; /* 3 */
account_entity_dequeue(cfs_rq, se); /* 4 */
if (!(flags & DEQUEUE_SLEEP))
se->vruntime -= cfs_rq->min_vruntime; /* 5 */
}
- 借机更新当前正在运行进程的虚拟时间信息,如果当前dequeue的进程就是当前正在运行的进程的话,那么此次update_curr()就很有必要了。
- 针对当前正在运行的进程来说,其对应的调度实体已经不在红黑树上了,因此不用在调用__dequeue_entity()函数从红黑树上参数对用的节点。
- 调度实体已经从就绪队列的红黑树上删除,因此更新on_rq成员。
- 更新就绪队列相关信息,例如权重信息。稍后介绍。
- 如果进程不是睡眠(例如从一个CPU迁移到另一个CPU),进程最小虚拟时间需要减去当前就绪队列对应的最小虚拟时间,原因之前也说了。迁移之后会在enqueue的时候加上对应的CFS就绪队列最小拟时间。
account_entity_dequeue()和前面说的account_entity_enqueue()操作相反。account_entity_dequeue()函数如下。
static void account_entity_dequeue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_sub(&cfs_rq->load, se->load.weight); /* 1 */
if (!parent_entity(se))
update_load_sub(&rq_of(cfs_rq)->load, se->load.weight);
#ifdef CONFIG_SMP
if (entity_is_task(se)) {
account_numa_dequeue(rq_of(cfs_rq), task_of(se));
list_del_init(&se->group_node); /* 2 */
}
#endif
cfs_rq->nr_running--; /* 3 */
}
- 从就绪队列权重总和中减去当前dequeue调度实体的权重。
- 从链表中删除调度实体se。
- 就绪队列中可运行调度实体计数减1。
三、CFS调度器-组调度
1、前言
现在的计算机基本都支持多用户登陆。如果一台计算机被两个用户A和B使用。假设用户A运行9个进程,用户B只运行1个进程。按照之前文章对CFS调度器的讲解,我们认为用户A获得90% CPU时间,用户B只获得10% CPU时间。随着用户A不停的增加运行进程,用户B可使用的CPU时间越来越少。这显然是不公平的。因此,我们引入组调度(Group Scheduling )的概念。我们以用户组作为调度的单位,这样用户A和用户B各获得50% CPU时间。用户A中的每个进程分别获得5.5%(50%/9)CPU时间。而用户B的进程获取50% CPU时间。这也符合我们的预期。本篇文章讲解CFS组调度实现原理。
2、再谈调度实体
通过之前的文章,我们已经介绍了CFS调度器主要管理的是调度实体。每一个进程通过task_struct描述,task_struct包含调度实体sched_entity参与调度。暂且针对这种调度实体,我们称作task se。现在引入组调度的概念,我们使用task_group描述一个组。在这个组中管理组内的所有进程。因为CFS就绪队列管理的单位是调度实体,因此,task_group也脱离不了sched_entity,所以在task_group结构体也包含调度实体sched_entity,我们称这种调度实体为group se。task_group定义在kernel/sched/sched.h文件。
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se; /* 1 */
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq; /* 2 */
unsigned long shares; /* 3 */
#ifdef CONFIG_SMP
atomic_long_t load_avg ____cacheline_aligned; /* 4 */
#endif
#endif
struct cfs_bandwidth cfs_bandwidth;
/* ... */
};
- 指针数组,数组大小等于CPU数量。现在假设只有一个CPU的系统。我们将一个用户组也用一个调度实体代替,插入对应的红黑树。例如,上面用户组A和用户组B就是两个调度实体se,挂在顶层的就绪队列cfs_rq中。用户组A管理9个可运行的进程,这9个调度实体se作为用户组A调度实体的child。通过se->parent成员建立关系。用户组A也维护一个就绪队列cfs_rq,暂且称之为group cfs_rq,管理的9个进程的调度实体挂在group cfs_rq上。当我们选择进程运行的时候,首先从根就绪队列cfs_rq上选择用户组A,再从用户组A的group cfs_rq上选择其中一个进程运行。现在考虑多核CPU的情况,用户组中的进程可以在多个CPU上运行。因此,我们需要CPU个数的调度实体se,分别挂在每个CPU的根cfs_rq上。
- 上面提到的group cfs_rq,同样是指针数组,大小是CPU的数量。因为每一个CPU上都可以运行进程,因此需要维护CPU个数的group cfs_rq。
- 调度实体有权重的概念,以权重的比例分配CPU时间。用户组同样有权重的概念,share就是task_group的权重。
- 整个用户组的负载贡献总和。
如果我们CPU数量等于2,并且只有一个用户组,那么系统中组调度示意图如下。

系统中一共运行8个进程。CPU0上运行3个进程,CPU1上运行5个进程。其中包含一个用户组A,用户组A中包含5个进程。CPU0上group se获得的CPU时间为group se对应的group cfs_rq管理的所有进程获得CPU时间之和。系统启动后默认有一个root_task_group,管理系统中最顶层CFS就绪队列cfs_rq。在2个CPU的系统上,task_group结构体se和cfs_rq成员数组长度是2,每个group se都对应一个group cfs_rq。
3、数据结构之间的关系
假设系统包含4个CPU,组调度的打开的情况下,各种结构体之间的关系如下图。
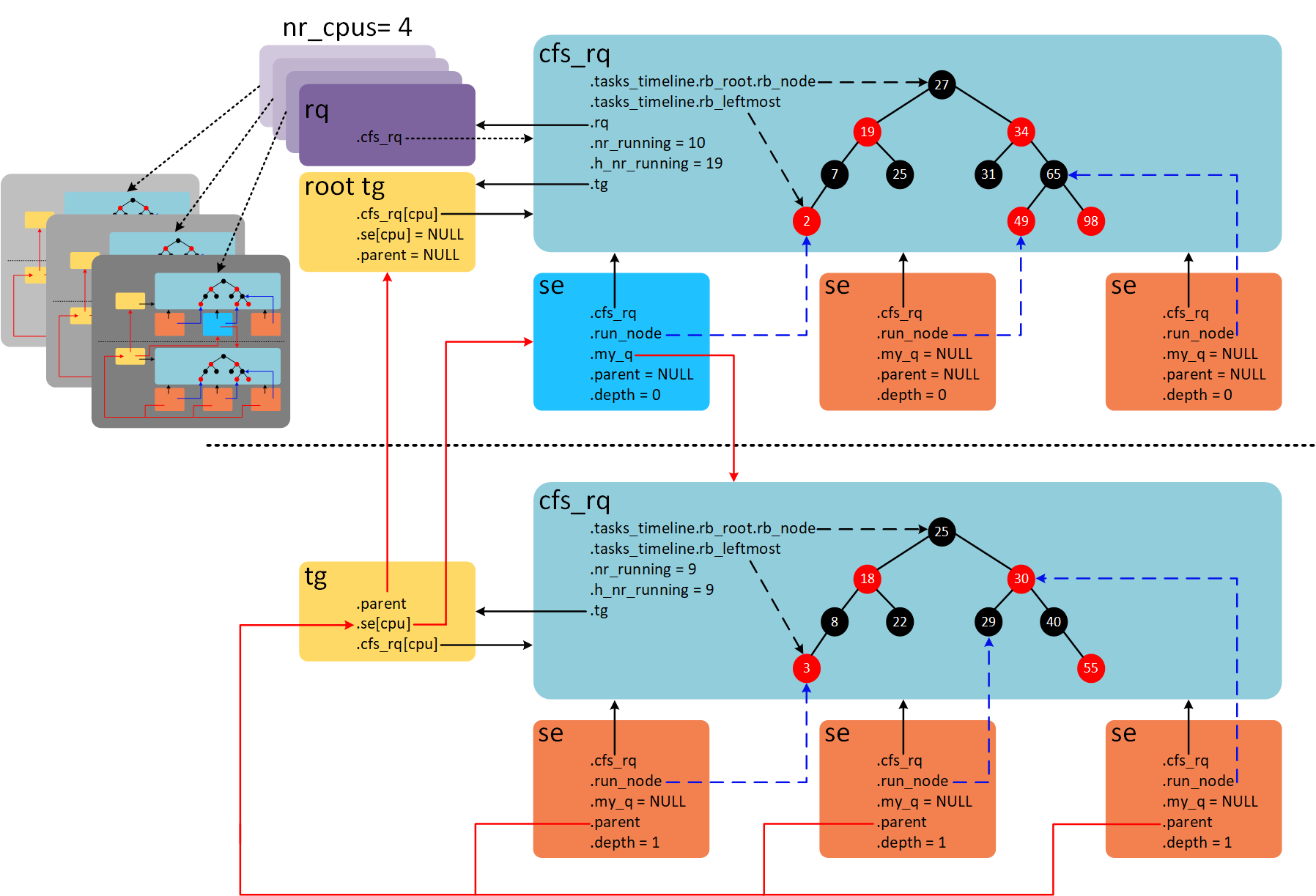
在每个CPU上都有一个全局的就绪队列struct rq,在4个CPU的系统上会有4个全局就绪队列,如图中紫色结构体。系统默认只有一个根task_group叫做root_task_group。rq->cfs_rq指向系统根CFS就绪队列。根CFS就绪队列维护一棵红黑树,红黑树上一共10个就绪态调度实体,其中9个是task se,1个group se(图上蓝色se)。group se的my_q成员指向自己的就绪队列。该就绪队列的红黑树上共9个task se。其中parent成员指向group se。每个group se对应一个group cfs_rq。4个CPU会对应4个group se和group cfs_rq,分别存储在task_group结构体se和cfs_rq成员。se->depth成员记录se嵌套深度。最顶层CFS就绪队列下的se的深度为0,group se往下一层层递增。cfs_rq->nr_runing成员记录CFS就绪队列所有调度实体个数,不包含子就绪队列。cfs_rq->h_nr_running成员记录就绪队列层级上所有调度实体的个数,包含group se对应group cfs_rq上的调度实体。例如,图中上半部,nr_runing和h_nr_running的值分别等于10和19,多出的9是group cfs_rq的h_nr_running。group cfs_rq由于没有group se,因此nr_runing和h_nr_running的值都等于9。
4、组进程调度
用户组内的进程该如何调度呢?通过上面的分析,我们可以通过根CFS就绪队列一层层往下便利选择合适进程。例如,先从根就绪队列选择适合运行的group se,然后找到对应的group cfs_rq,再从group cfs_rq上选择task se。在CFS调度类中,选择进程的函数是pick_next_task_fair()。
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs; /* 1 */
struct sched_entity *se;
struct task_struct *p;
put_prev_task(rq, prev);
do {
se = pick_next_entity(cfs_rq, NULL); /* 2 */
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se); /* 3 */
} while (cfs_rq); /* 4 */
p = task_of(se);
return p;
}
- 从根CFS就绪队列开始便利。
- 从就绪队列cfs_rq的红黑树中选择虚拟时间最小的se。
- group_cfs_rq()返回se->my_q成员。如果是task se,那么group_cfs_rq()返回NULL。如果是group se,那么group_cfs_rq()返回group se对应的group cfs_rq。
- 如果是group se,我们需要从group cfs_rq上的红黑树选择下一个虚拟时间最小的se,以此循环直到最底层的task se。
5、组进程抢占
周期性调度会调用task_tick_fair()函数。
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
}
for_each_sched_entity()是一个宏定义for (; se; se = se->parent),顺着se的parent链表往上走。entity_tick()函数继续调用check_preempt_tick()函数,这部分在之前的文章已经说过了。check_preempt_tick()函数会根据满足抢占当前进程的条件下设置TIF_NEED_RESCHED标志位。满足抢占条件也很简单,只要顺着se->parent这条链表便利下去,如果有一个se运行时间超过分配限额时间就需要重新调度。
6、用户组的权重
每一个进程都会有一个权重,CFS调度器依据权重的大小分配CPU时间。同样task_group也不例外,前面已经提到使用share成员记录。按照前面的举例,系统有2个CPU,task_group中势必包含两个group se和与之对应的group cfs_rq。这2个group se的权重按照比例分配task_group权重。如下图所示。

CPU0上group se下有2个task se,权重和是3072。CPU1上group se下有3个task se,权重和是4096。task_group权重是1024。因此,CPU0上group se权重是439(1024*3072/(3072+4096)),CPU1上group se权重是585(1024-439)。当然这里的计算group se权重的方法是最简单的方式,代码中实际计算公式是考虑每个group cfs_rq的负载贡献比例,而不是简单的考虑权重比例。
7、用户组时间限额分配
分配给每个进程时间计算函数是sched_slice(),之前的分析都是基于不考虑组调度的情况下。现在考虑组调度的情况下进程应该分配的时间如何调整呢?先举个简单不考虑组调度的例子,在一个单核系统上2个进程,权重都是1024。在不考虑组调度的情况下,调度实体se分配的时间限额计算公式如下:
se->load.weight
time = sched_period * -------------------------
cfs_rq->load.weight
我们还需要计算se的权重占整个CFS就绪队列权重的比例乘以调度周期时间即可。2个进程根据之前文章的分析,调度周期是6ms,那么每个进程分配的时间是6ms*1024/(1024+1024)=3ms。
现在考虑组调度的情况。系统依然是单核,存在一个task_group,所有的进程权重是1024。task_group权重也是1024(即share值)。如下图所示。
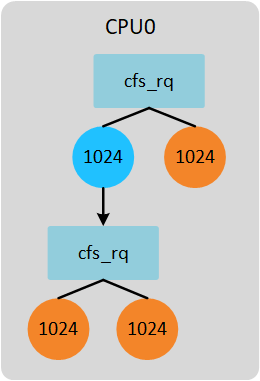
group cfs_rq下的进程分配时间计算公式如下(gse := group se; gcfs_rq := group cfs_rq):
se->load.weight gse->load.weight
time = sched_period * ------------------------- * ------------------------
gcfs_rq->load.weight cfs_rq->load.weight
根据公式,计算group cfs_rq下进程的配时间如下:
1024 1024
time = 6ms * --------------- * ---------------- = 1.5ms
1024 + 1024 1024 + 1024
依据上面的2个计算公式,我们可以计算上面例子中每个进程分配的时间如下图所示。

以上简单介绍了task_group嵌套一层的情况,如果task_group下面继续包含task_group,那么上面的计算公式就要再往上计算一层比例。实现该计算公式的函数是sched_slice()。
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq); /* 1 */
for_each_sched_entity(se) { /* 2 */
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load; /* 3 */
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load); /* 4 */
}
return slice;
}
- 根据当前就绪进程个数计算调度周期,默认情况下,进程不超过8个情况下,调度周期默认6ms。
- for循环根据se->parent链表往上计算比例。
- 获得se依附的cfs_rq的负载信息。
- 计算slice = slice * se->load.weight / cfs_rq->load.weight的值。
8、Group Se权重计算
上面举例说到group se的权重计算是根据权重比例计算。但是,实际的代码并不是。当我们dequeue task、enqueue task以及task tick的时候会通过update_cfs_group()函数更新group se的权重信息。
static void update_cfs_group(struct sched_entity *se)
{
struct cfs_rq *gcfs_rq = group_cfs_rq(se); /* 1 */
long shares, runnable;
if (!gcfs_rq)
return;
shares = calc_group_shares(gcfs_rq); /* 2 */
runnable = calc_group_runnable(gcfs_rq, shares);
reweight_entity(cfs_rq_of(se), se, shares, runnable); /* 3 */
}
- 获得group se对应的group cfs_rq。
- 计算新的权重值。
- 更新group se的权重值为shares。
calc_group_shares()根据当前group cfs_rq负载情况计算新的权重。
static long calc_group_shares(struct cfs_rq *cfs_rq)
{
long tg_weight, tg_shares, load, shares;
struct task_group *tg = cfs_rq->tg;
tg_shares = READ_ONCE(tg->shares);
load = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg);
tg_weight = atomic_long_read(&tg->load_avg);
/* Ensure tg_weight >= load */
tg_weight -= cfs_rq->tg_load_avg_contrib;
tg_weight += load;
shares = (tg_shares * load);
if (tg_weight)
shares /= tg_weight;
return clamp_t(long, shares, MIN_SHARES, tg_shares);
}
根据calc_group_shares()函数,我们可以得到权重计算公式如下(grq := group cfs_rq):
tg->shares * load
ge->load.weight = -------------------------------------------------
tg->load_avg - grq->tg_load_avg_contrib + load
load = max(grq->load.weight, grq->avg.load_avg)
tg->load_avg指所有的group cfs_rq负载贡献和。grq->tg_load_avg_contrib是指该group cfs_rq已经向tg->load_avg贡献的负载。因为tg是一个全局共享变量,多个CPU可能同时访问,为了避免严重的资源抢占。group cfs_rq负载贡献更新的值并不会立刻加到tg->load_avg上,而是等到负载贡献大于tg_load_avg_contrib一定差值后,再加到tg->load_avg上。例如,2个CPU的系统。CPU0上group cfs_rq初始值tg_load_avg_contrib为0,当group cfs_rq每次定时器更新负载的时候并不会访问tg变量,而是等到group cfs_rq的负载grp->avg.load_avg大于tg_load_avg_contrib很多的时候,这个差值达到一个数值(假设是2000),才会更新tg->load_avg为2000。然后,tg_load_avg_contrib的值赋值2000。又经过很多个周期后,grp->avg.load_avg和tg_load_avg_contrib的差值又等于2000,那么再一次更新tg->load_avg的值为4000。这样就避免了频繁访问tg变量。
但是上面的计算公式的依据是什么呢?如何得到的?首先我觉得我们能介绍的计算方法是上一节《用户组的权重》说的方法,计算group cfs_rq的权重占的比例。公式如下。
tg->shares * grq->load.weight ge->load.weight = ------------------------------- (1) \Sum grq->load.weight
由于计算\Sum grq->load.weight这个总和开销太大(原因可能是CPU数量比较大的系统,访问其他CPU group cfs_rq造成数据访问竞争激烈)。因此我们使用平均负载来近似处理,平均负载值变化缓慢,因此近似后的值更容易计算且更稳定。近似处理条件如下,将权重和平均负载近似处理。
grq->load.weight -> grq->avg.load_avg (2)
经过近似处理后的公式(1)变换如下:
tg->shares * grq->avg.load_avg ge->load.weight = ------------------------------ (3) tg->load_avg Where: tg->load_avg ~= \Sum grq->avg.load_avg
公式(3)问题在于,因为平均负载值变化很慢 (它的设计正是如此) ,这会导致在边界条件的时候的瞬变。 具体而言,当空闲group开始运行一个进程的时候。 我们的CPU的grq->avg.load_avg需要花费时间来慢慢变化,产生不良的延迟。在这种特殊情况下(单核CPU也是这种情况),公式(1)计算如下:
tg->shares * grq->load.weight ge->load.weight = ------------------------------- = tg->shares (4) grq->load.weight
我们的目标就是将近似公式(3)在UP情景时修改成公式(4)的情况。
ge->load.weight =
tg->shares * grq->load.weight
--------------------------------------------------- (5)
tg->load_avg - grq->avg.load_avg + grq->load.weight
但是因为grq->load.weight可以降到0,导致除数是0。因此我们需要使用grq->avg.load_avg作为其下限,然后给出:
tg->shares * grq->load.weight
ge->load.weight = ----------------------------- (6)
tg_load_avg'
Where: tg_load_avg' = tg->load_avg - grq->avg.load_avg +
max(grq->load.weight, grq->avg.load_avg)
在UP系统上,公式(6)和公式(4)相似。在正常情况下,公式(6)和公式(3)相似。
说实话,真的是一大堆的公式,而且是各种近似处理和怼参数。一下看到公式的结果总是一头雾水,因为这可能涉及多次不同的优化修改,有些可能是经验总结,有些可能是实际环境测试。当你看不懂公式的时候,不妨会退到这个功能刚刚添加时候的样子,最初的版本总是让人容易接受。然后,顺着每一笔提交记录查看优化代码的原因,一步一个脚印,或许“面向大海春暖花开”。
四、CFS调度器-PELT(per entity load tracking)
1、为什么需要PELT?
为了让调度器更加的聪明,我们总是希望系统满足最大吞吐量同时又最大限度的降低功耗。虽然可能有些矛盾,但是现实总是这样。PELT算法是Linux 3.8合入的,那么在此之前,我们存在什么问题才引入PELT算法呢?在Linux 3.8之前,CFS以每个运行队列(runqueue,简称rq)为基础跟踪负载。但是这种方法,我们无法确定当前负载的来源。同时,即使工作负载相对稳定的情况下,在rq级别跟踪负载,其值也会产生很大变化。为了解决以上的问题,PELT算法会跟踪每个调度实体(per-scheduling entity)的负载情况。
2、如何进行PELT
具体原理的东西可以参考这篇文章《per-entity load tracking》。我就无耻的从这篇文章中摘录一段话吧。为了做到Per-entity的负载跟踪,时间(物理时间,不是虚拟时间)被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。如果在该周期内,runnable的时间是x,那么对系统负载的贡献就是(x/1024)。当然,一个实体在一个计算周期内的负载可能会超过1024us,这是因为我们会累积在过去周期中的负载,当然,对于过去的负载我们在计算的时候需要乘一个衰减因子。如果我们让Li表示在周期pi中该调度实体的对系统负载贡献,那么一个调度实体对系统负荷的总贡献可以表示为:
L = L0 + L1 * y + L2 * y2 + L3 * y3 + ... + Ln * yn
- y32 = 0.5, y = 0.97857206
初次看到以上公式,不知道你是否在想这都是什么玩意!举个例子,如何计算一个se的负载贡献。如果有一个task,从第一次加入rq后开始一直运行4096us后一直睡眠,那么在1023us、2047us、3071us、4095us、5119us、6143us、7167us和8191us时间的每一个时刻负载贡献分别是多少呢?
1023us: L0 = 1023 2047us: L1 = 1023 + 1024 * y = 1023 + (L0 + 1) * y = 2025 3071us: L2 = 1023 + 1024 * y + 1024 * y2 = 1023 + (L1 + 1) * y = 3005 4095us: L3 = 1023 + 1024 * y + 1024 * y2 + 1024 * y3 = 1023 + (L2 + 1) * y = 3963 5119us: L4 = 0 + 1024 * y + 1024 * y2 + 1024 * y3 + 1024 * y4 = 0 + (L3 + 1) * y = 3877 6143us: L5 = 0 + 0 + 1024 * y2 + 1024 * y3 + 1024 * y4 + 1024 * y5 = 0 + L4 * y = 3792 7167us: L6 = 0 + L5 * y = L4 * y2 = 3709 8191us: L7 = 0 + L6 * y = L5 * y2 = L4 * y3 = 3627
经过以上的举例,我们不难发现一个规律,计算当前时间的负载只需要上个周期负载贡献总和乘以衰减系数y,并加上当前时间点的负载即可。
从上面的计算公式我们也可以看出,经常需要计算val*yn的值,因此内核提供decay_load()函数用于计算第n个周期的衰减值。为了避免浮点数运算,采用移位和乘法运算提高计算速度。decay_load(val, n) = val*yn*232>>32。我们将yn*232的值提前计算出来保存在数组runnable_avg_yN_inv中。
runnable_avg_yN_inv[n] = yn*232, n > 0 && n < 32
runnable_avg_yN_inv的计算可以参考/Documentation/scheduler/sched-pelt.c文件calc_runnable_avg_yN_inv()函数。由于y32=0.5,因此我们只需要计算y*232~y31*232的值保存到数组中即可。当n大于31的时候,为了计算yn*232我们可以借助y32=0.5公式间接计算。例如y33*232=y32*y*232=0.5*y*232=0.5*runnable_avg_yN_inv[1]。calc_runnable_avg_yN_inv()函数简单归纳就是:runnable_avg_yN_inv[i] = ((1UL << 32) - 1) * pow(0.97857206, i),i>=0 && i<32。pow(x, y)是求xy的值。计算得到runnable_avg_yN_inv数组的值如下:
static const u32 runnable_avg_yN_inv[] = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
根据runnable_avg_yN_inv数组的值,我们就方便实现decay_load()函数。
/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (unlikely(n > LOAD_AVG_PERIOD * 63)) /* 1 */
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
if (unlikely(local_n >= LOAD_AVG_PERIOD)) { /* 2 */
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32); /* 2 */
return val;
}
- LOAD_AVG_PERIOD的值为32,我们认为当时间经过2016个周期后,衰减后的值为0。即val*yn=0, n > 2016。
- 当n大于等于32的时候,就需要根据y32=0.5条件计算yn的值。yn*232 = 1/2n/32 * yn%32*232=1/2n/32 * runnable_avg_yN_inv[n%32]。
3、如何计算当前负载贡献
经过上面举例,我们可以知道计算当前负载贡献并不需要记录所有历史负载贡献。我们只需要知道上一刻负载贡献就可以计算当前负载贡献,这大大降低了代码实现复杂度。我们继续上面举例问题的思考,我们依然假设一个task开始从0时刻运行,那么1022us后的负载贡献自然就是1022。当task经过10us之后,此时(现在时刻是1032us)的负载贡献又是多少呢?很简单,10us中的2us和之前的1022us可以凑成一个周期1024us。这个1024us需要进行一次衰减,即现在的负载贡献是:(1024 - 1022 + 1022)y + 10 - (1024 - 1022) = 1022y + 2y + 8 = 1010。1022y可以理解成由于经历了一个周期,因此上一时刻的负载需要衰减一次,因此1022需要乘以衰减系数y,2y可以理解成,2us属于上一个负载计算时距离一个周期1024us的差值,由于2是上一个周期的时间,因此也需要衰减一次,8是当前周期时间,不需要衰减。又经过了2124us,此时(现在时刻是3156us)负载贡献又是多少呢?即:(1024 - 8 + 1010)y2 + 1024y + 2124 - 1024 - (1024 - 8) = 1010y2 + 1016y2 + 1024y + 84 = 3024。2124us可以分解成3部分:1016us补齐上一时刻不足1024us部分,凑成一个周期;1024us一个整周期;当前时刻不足一个周期的剩余84us部分。相当于我们经过了2个周期,因此针对上一次的负载贡献需要衰减2次,也就是1010y2部分,1016us是补齐上一次不足一个周期的部分,因此也需要衰减2次,所以公式中还有1016y2 部分。1024us部分相当于距离当前时刻是一个周期,所以需要衰减1次,最后84部分是当前剩余时间,不需要衰减。
针对以上事例,我们可以得到一个更通用情况下的计算公式。假设上一时刻负载贡献是u,经历d时间后的负载贡献如何计算呢?根据上面的例子,我们可以把时间d分成3和部分:d1是离当前时间最远(不完整的)period 的剩余部分,d2 是完整period时间,而d3是(不完整的)当前 period 的剩余部分。假设时间d是经过p个周期(d=d1+d2+d3, p=1+d2/1024)。d1,d2,d3 的示意图如下:
d1 d2 d3
^ ^ ^
| | |
|<->|<----------------->|<--->|
|---x---|------| ... |------|-----x (now)
p-1
u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
n=1
p-1
= u y^p + d1 y^p + 1024 \Sum y^n + d3 y^0
n=1
上面的例子现在就可以套用上面的公式计算。例如,上一次的负载贡献u=1010,经过时间d=2124us,可以分解成3部分,d1=1016us,d2=1024,d3=84。经历的周期p=2。所以当前时刻负载贡献u'=1010y2 + 1016y2 + 1024y + 84,与上面计算结果一致。
4、如何记录负载信息
Linux中使用struct sched_avg结构体记录调度实体se或者就绪队列cfs rq负载信息。每个调度实体se以及cfs就绪队列结构体中都包含一个struct sched_avg结构体用于记录负载信息。struct sched_avg定义如下。
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_load_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_load_avg;
unsigned long util_avg;
};
- last_update_time:上一次负载更新时间。用于计算时间间隔。
- load_sum:基于可运行(runnable)时间的负载贡献总和。runnable时间包含两部分:一是在rq中等待cpu调度运行的时间,二是正在cpu上运行的时间。
- util_sum:基于正在运行(running)时间的负载贡献总和。running时间是指调度实体se正在cpu上执行时间。
- load_avg:基于可运行(runnable)时间的平均负载贡献。
- util_avg:基于正在运行(running)时间的平均负载贡献。
一个调度实体se可能属于task,也有可能属于group(Linux支持组调度,需要配置CONFIG_FAIR_GROUP_SCHED)。调度实体se的初始化针对task se和group se也就有所区别。调度实体使用struct sched_entity描述如下。
struct sched_entity {
struct load_weight load;
unsigned long runnable_weight;
#ifdef CONFIG_SMP
struct sched_avg avg;
#endif
};
调度实体se初始化函数是init_entity_runnable_average(),代码如下。
void init_entity_runnable_average(struct sched_entity *se)
{
struct sched_avg *sa = &se->avg;
memset(sa, 0, sizeof(*sa));
/*
* Tasks are intialized with full load to be seen as heavy tasks until
* they get a chance to stabilize to their real load level.
* Group entities are intialized with zero load to reflect the fact that
* nothing has been attached to the task group yet.
*/
if (entity_is_task(se))
sa->runnable_load_avg = sa->load_avg = scale_load_down(se->load.weight);
se->runnable_weight = se->load.weight;
/* when this task enqueue'ed, it will contribute to its cfs_rq's load_avg */
}
针对task se初始化,runnable_load_avg和load_avg的值是和se的权重(se->load.weight)相等。而且根据注释其实也可以知道,runnable_load_avg和load_avg在后续的负载计算中累加的最大值其实就是se的权重值。也就意味着,runnable_load_avg和load_avg的值可以间接的表明task的繁重程度。runnable_weight成员主要是针对group se提出的。对于task se来说,runnable_weight就是se的weight,二者的值完全一样。
针对group se,runnable_load_avg和load_avg的值初始化为0。这也意味着当前task group中没有任何task需要调度。runnable_weight虽然现在初始化为se的权重值,但是在后续的代码中会不断的更新runnable_weight的值。runnable_weight是实体权重的一部分,表示组runqueue的可运行部分。
5、负载计算代码实现
在了解了以上信息后,可以开始研究上一节中计算负载贡献的公式的源码实现。
p-1
u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
n=1
= u y^p + (Step 1)
p-1
d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2)
n=1
以上公式在代码中由两部实现,accumulate_sum()函数计算step1部分,然后调用__accumulate_pelt_segments()函数计算step2部分。
static __always_inline u32
accumulate_sum(u64 delta, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
unsigned long scale_freq, scale_cpu;
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
scale_freq = arch_scale_freq_capacity(cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
delta += sa->period_contrib; /* 1 */
periods = delta / 1024; /* A period is 1024us (~1ms) */ /* 2 */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods); /* 3 */
sa->runnable_load_sum = decay_load(sa->runnable_load_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
contrib = __accumulate_pelt_segments(periods, /* 4 */
1024 - sa->period_contrib, delta);
}
sa->period_contrib = delta; /* 5 */
contrib = cap_scale(contrib, scale_freq);
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_load_sum += runnable * contrib;
if (running)
sa->util_sum += contrib * scale_cpu;
return periods;
}
- period_contrib记录的是上次更新负载不足1024us周期的时间。delta是经过的时间,为了计算经过的周期个数需要加上period_contrib,然后整除1024。
- 计算周期个数。
- 调用decay_load()函数计算公式中的step1部分。
- __accumulate_pelt_segments()负责计算公式step2部分。
- 更新period_contrib为本次不足1024us部分。
下面分析__accumulate_pelt_segments()函数。
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}
__accumulate_pelt_segments()函数主要的关注点应该是这个c2是如何计算的。本来是一个多项式求和,非常巧妙的变成了一个很简单的计算方法。这个转换过程如下。
p-1
c2 = 1024 \Sum y^n
n=1
In terms of our maximum value:
inf inf p-1
max = 1024 \Sum y^n = 1024 ( \Sum y^n + \Sum y^n + y^0 )
n=0 n=p n=1
Further note that:
inf inf inf
( \Sum y^n ) y^p = \Sum y^(n+p) = \Sum y^n
n=0 n=0 n=p
Combined that gives us:
p-1
c2 = 1024 \Sum y^n
n=1
inf inf
= 1024 ( \Sum y^n - \Sum y^n - y^0 )
n=0 n=p
= max - (max y^p) - 1024
LOAD_AVG_MAX其实就是1024(1 + y + y2 + ... + yn)的最大值,计算方法很简单,等比数列求和公式一套,然后n趋向于正无穷即可。最终LOAD_AVG_MAX的值是47742。当然我们使用数学方法计算的数值可能和这个值有点误差,并不是完全相等。那是因为47742这个值是通过代码计算得到的,计算机计算的过程中涉及浮点数运算及取整操作,有误差也是正常的。LOAD_AVG_MAX的计算代码如下。
void calc_converged_max(void)
{
int n = -1;
long max = 1024;
long last = 0, y_inv = ((1UL << 32) - 1) * y;
for (; ; n++) {
if (n > -1)
max = ((max * y_inv) >> 32) + 1024;
/*
* This is the same as:
* max = max*y + 1024;
*/
if (last == max)
break;
last = max;
}
printf("#define LOAD_AVG_MAX %ld\n", max);
}
6、调度实体更新负载贡献
更新调度实体负载的函数是update_load_avg()。该函数会在以下情况调用。
- 向就绪队列中添加一个进程,在CFS中就是enqueue_entity操作。
- 从就绪队列中删除一个进程,在CFS中就是dequeue_entity操作。
- scheduler tick,周期性调用更新负载信息。
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_task(cfs_rq);
struct rq *rq = rq_of(cfs_rq);
int cpu = cpu_of(rq);
int decayed;
/*
* Track task load average for carrying it to new CPU after migrated, and
* track group sched_entity load average for task_h_load calc in migration
*/
if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD))
__update_load_avg_se(now, cpu, cfs_rq, se); /* 1 */
decayed = update_cfs_rq_load_avg(now, cfs_rq); /* 2 */
/* ...... */
}
- __update_load_avg_se()负责更新调度实体se的负载信息。
- 在更新se负载后,顺便更新se attach的cfs就绪队列的负载信息。runqueue的负载就是该runqueue下所有的se负载总和。
__update_load_avg_se()代码如下。
static int
__update_load_avg_se(u64 now, int cpu, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (entity_is_task(se))
se->runnable_weight = se->load.weight; /* 1 */
if (___update_load_sum(now, cpu, &se->avg, !!se->on_rq, !!se->on_rq, /* 2 */
cfs_rq->curr == se)) {
___update_load_avg(&se->avg, se_weight(se), se_runnable(se)); /* 3 */
cfs_se_util_change(&se->avg);
return 1;
}
return 0;
}
- runnable_weight称作可运行权重,该概念主要针对group se提出。针对task se来说,runnable_weight的值就是和进程权重weight相等。针对group se,runnable_weight的值总是小于等于weight。
- 通过___update_load_sum()函数计算调度实体se的负载总和信息。
- 更新平均负载信息,例如se->load_avg成员。
___update_load_sum()函数实现如下。
static __always_inline int
___update_load_sum(u64 now, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
delta = now - sa->last_update_time;
delta >>= 10; /* 1 */
if (!delta)
return 0;
sa->last_update_time += delta << 10; /* 2 */
if (!load)
runnable = running = 0;
if (!accumulate_sum(delta, cpu, sa, load, runnable, running)) /* 3 */
return 0;
return 1;
}
- delta是两次负载更新之间时间差,单位是ns。整除1024是将ns转换成us单位。PELT算法最小时间计量单位时us,如果时间差连1us都不到,就没必要衰减计算,直接返回即可。
- 更新last_update_time,方便下次更新负载信息,计算时间差。
- 通过accumulate_sum()进行负载计算,由上面调用地方可知,这里的参数load、runnable及running非0即1。因此,在负载计算中可知,se->load_sum和se->runnable_load_sum最大值就是LOAD_AVG_MAX - 1024 + se->period_contrib。并且,se->load_sum的值和se->runnable_load_sum相等。
继续探究平均负载信息如何更新。___update_load_avg()函数如下。
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load, unsigned long runnable)
{
u32 divider = LOAD_AVG_MAX - 1024 + sa->period_contrib;
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_load_avg = div_u64(runnable * sa->runnable_load_sum, divider);
sa->util_avg = sa->util_sum / divider;
}
由上面的代码可知,load是调度实体se的权重weight,runnable是调度实体se的runnable_weight。因此平均负债计算公式如下。针对task se来说,se->load_avg和se->runnable_load_avg的值是相等的(因为,se->load_sum和se->runnable_load_sum相等,并且se->load.weight和se->runnable_weight相等),并且其值是小于等于se->load.weight。
se->load_sum
se->load_avg = -------------------------------------------- * se->load.weight
LOAD_AVG_MAX - 1024 + sa->period_contrib
se->runnable_load_sum
se->runnable_load_avg = -------------------------------------------- * se->runnable_weight
LOAD_AVG_MAX - 1024 + sa->period_contrib
针对频繁运行的进程,load_avg的值会越来越接近权重weight。例如,权重1024的进程长时间运行,其负载贡献曲线如下。上面的表格是进程运行的时间,下表是负载贡献曲线。

从某一时刻进程开始运行,负载贡献就开始一直增加。现在如果是一个周期运行的进程(每次运行1ms,睡眠9ms),那么负载贡献曲线图如何呢?
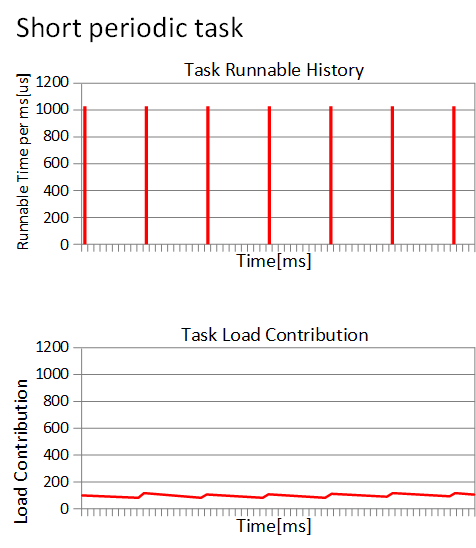
负载贡献的值基本维持在最小值和最大值两个峰值之间。这也符合我们的预期,我们认为负载贡献就是反应进程运行的频繁程度。因此,基于PELT算法,我们在负载均衡的时候,可以更清楚的计算一个进程迁移到其他CPU的影响。
7、就绪队列更新负载信息
前面已经提到更新就绪队列负载信息的函数是update_cfs_rq_load_avg()。
static inline int
update_cfs_rq_load_avg(u64 now, struct cfs_rq *cfs_rq)
{
int decayed = 0;
decayed |= __update_load_avg_cfs_rq(now, cpu_of(rq_of(cfs_rq)), cfs_rq);
return decayed;
}
继续调用__update_load_avg_cfs_rq()更新CFS就绪队列负载信息。该函数和以上更新调度实体se负载信息函数很相似。
static int
__update_load_avg_cfs_rq(u64 now, int cpu, struct cfs_rq *cfs_rq)
{
if (___update_load_sum(now, cpu, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
scale_load_down(cfs_rq->runnable_weight),
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1, 1);
return 1;
}
return 0;
}
struct cfs_rq结构体内嵌struct sched_avg结构体,用于跟踪就绪队列负载信息。___update_load_sum()函数上面已经分析过,这里和更新调度实体se负载的区别是传递的参数不一样。load和runnable分别传递的是CFS就绪队列的权重以及可运行权重。CFS就绪队列的权重是指CFS就绪队列上所有就绪态调度实体权重之和。CFS就绪队列平均负载贡献是指所有调度实体平均负载之和。在每次更新调度实体负载信息时也会同步更新se依附的CFS就绪队列负载信息。
8、runnable_load_avg和load_avg区别
在介绍struct sched_avg结构体的时候,我们只介绍了load_avg成员而忽略了runnable_load_avg成员。那么他们究竟有什么区别呢?我们知道struct sched_avg结构体会被内嵌在调度实体struct sched_entity和就绪队列struct cfs_rq中,分别用来跟踪调度实体和就绪队列的负载信息。针对task se,runnable_load_avg和load_avg的值是没有差别的。但是对于就绪队列负载来说,二者就有不一样的意义。load_avg代表就绪队列平均负载,其包含睡眠进程的负载贡献。runnable_load_avg只包含就绪队列上所有可运行进程的负载贡献。如何体现区别呢?我们看一下在进程加入就绪队列的处理。又是大家熟悉的enqueue_entity()函数。
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* When enqueuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Add its load to cfs_rq->runnable_avg
* - For group_entity, update its weight to reflect the new share of
* its group cfs_rq
* - Add its new weight to cfs_rq->load.weight
*/
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH); /* 1 */
enqueue_runnable_load_avg(cfs_rq, se); /* 2 */
}
- load_avg成员更新信息,传递flag包含DO_ATTACH。当进程创建第一次调用update_load_avg()函数时,这个flag会用上。
- 更新runnable_load_avg信息。
我们熟悉的update_load_avg()函数如下。
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_task(cfs_rq);
struct rq *rq = rq_of(cfs_rq);
int cpu = cpu_of(rq);
int decayed;
if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/*
* DO_ATTACH means we're here from enqueue_entity().
* !last_update_time means we've passed through
* migrate_task_rq_fair() indicating we migrated.
*
* IOW we're enqueueing a task on a new CPU.
*/
attach_entity_load_avg(cfs_rq, se, SCHED_CPUFREQ_MIGRATION); /* 1 */
update_tg_load_avg(cfs_rq, 0);
} else if (decayed && (flags & UPDATE_TG))
update_tg_load_avg(cfs_rq, 0);
}
- 进程第一次被创建之后,se->avg.last_update_time的值为0。因此,attach_entity_load_avg()函数本次会被调用。
attach_entity_load_avg()函数如下。
static void attach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u32 divider = LOAD_AVG_MAX - 1024 + cfs_rq->avg.period_contrib;
se->avg.last_update_time = cfs_rq->avg.last_update_time;
se->avg.period_contrib = cfs_rq->avg.period_contrib;
se->avg.util_sum = se->avg.util_avg * divider;
se->avg.load_sum = divider;
if (se_weight(se)) {
se->avg.load_sum =
div_u64(se->avg.load_avg * se->avg.load_sum, se_weight(se));
}
se->avg.runnable_load_sum = se->avg.load_sum;
enqueue_load_avg(cfs_rq, se);
cfs_rq->avg.util_avg += se->avg.util_avg;
cfs_rq->avg.util_sum += se->avg.util_sum;
add_tg_cfs_propagate(cfs_rq, se->avg.load_sum);
cfs_rq_util_change(cfs_rq, flags);
}
我们可以看到调度室se关于负载的一大堆的初始化。我们现在关注的点是enqueue_load_avg()函数。
enqueue_load_avg()函数如下,很清晰明了直接将调度实体负载信息累加到就绪队列的load_avg成员。
static inline void
enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->avg.load_avg += se->avg.load_avg;
cfs_rq->avg.load_sum += se_weight(se) * se->avg.load_sum;
}
当进程从就绪队列删除的时候,并不会将se的负载从就绪队列的load_avg中删除。因此,load_avg包含了所有调度实体的可运行状态以及阻塞状态的负载信息。
runnable_load_avg是只包含可运行进程的负载信息。我们看下enqueue_runnable_load_avg()函数。很清晰明了,直接将调度实体负载信息累加runnable_load_avg成员。
static inline void
enqueue_runnable_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->runnable_weight += se->runnable_weight;
cfs_rq->avg.runnable_load_avg += se->avg.runnable_load_avg;
cfs_rq->avg.runnable_load_sum += se_runnable(se) * se->avg.runnable_load_sum;
}
下面继续看下dequeue_entity操作。
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* When dequeuing a sched_entity, we must:
* - Update loads to have both entity and cfs_rq synced with now.
* - Substract its load from the cfs_rq->runnable_avg.
* - Substract its previous weight from cfs_rq->load.weight.
* - For group entity, update its weight to reflect the new share
* of its group cfs_rq.
*/
update_load_avg(cfs_rq, se, UPDATE_TG);
account_entity_dequeue(cfs_rq, se);
}
account_entity_dequeue()函数就是减去即将出队的调度实体的负载信息。account_entity_dequeue()函数如下。
static inline void
dequeue_runnable_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->runnable_weight -= se->runnable_weight;
sub_positive(&cfs_rq->avg.runnable_load_avg, se->avg.runnable_load_avg);
sub_positive(&cfs_rq->avg.runnable_load_sum,
se_runnable(se) * se->avg.runnable_load_sum);
}
我们并没有看到load_avg成员减去调度实体的负载信息,只看到runnable_load_avg成员的变化。因此,调度实体入队和出队的操作中会对应增加和减少runnable_load_avg。所以,runnable_load_avg包含的是所有就绪队列上可运行状态调度实体的负载信息之和。load_avg是所有的可运行状态及阻塞状态进程的负载之和。
五、CFS调度器-带宽控制
1、前言
什么是带宽控制?简而言之就是控制一个用户组在给定周期时间内可以消耗CPU的时间,如果在给定的周期内消耗CPU时间超额,就限制该用户组内任务调度,直到下一个周期。限制某个进程的最大CPU使用率是否真的有必要呢?如果一个系统中仅存在一个进程,限制该进程使用CPU使用率最大50%,当进程使用率达到50%的时候,就限制该进程运行,CPU进入idle状态。看起来好像没有任何意义。但是,有时候,这正是系统管理员可能想要做的事情。如果这些进程属于仅支付了一定CPU时间的客户或者需要提供严格资源的情况,则限制进程(或进程组)可能消耗的CPU时间的最大份额是很有必要的。毕竟付多少钱享受多少服务。本文章仅讨论SCHED_NORMAL进程的CPU带宽控制(CPU bandwidth control)。
注:代码分析基于Linux 4.18.0。
2、设计原理
如果使用CPU bandwith control,需要配置CONFIG_FAIR_GROUP_SCHED和CONFIG_CFS_BANDWIDTH选项。该功能是限制一个组的最大使用CPU带宽。通过设置两个变量quota和period,period是指一段周期时间,quota是指在period周期时间内,一个组可以使用的CPU时间限额。当一个组的进程运行时间超过quota后,就会被限制运行,这个动作被称作throttle。直到下一个period周期开始,这个组会被重新调度,这个过程称作unthrottle。
在多核系统中,一个用户组使用task_group描述,用户组中包含CPU数量的调度实体,以及调度实体对应的group cfs_rq。如何限制一个用户组中的进程呢?我们可以简单的将用户组管理的调度实体从对应的就绪队列上删除即可,然后标记调度实体对应的group cfs_rq的标志位。quota和period的值存储在cfs_bandwidth结构体中,该结构体嵌在tasak_group中,cfs_bandwidth结构体还包含runtime成员记录剩余限额时间。每当用户组中的进程运行一段时间时,对应的runtime时间也在减少。系统会启动一个高精度定时器,周期时间是period,在定时器时间到达后重置剩余限额时间runtime为quota,开始下一个轮时间跟踪。所有的用户组进程运行的时间累加在一起,保证总的运行时间小于quota。每个用户组会管理CPU个数的就绪队列group cfs_rq。每个group cfs_rq中也有限额时间,该限额时间是从全局用户组quota中申请。例如,周期period值100ms,限额quota值50ms,2个CPU系统。CPU0上group cfs_rq首先从全局限额时间中申请5ms时间(此实runtime值为45),然后运行进程。当5ms时间消耗完时,继续从全局时间限额quota中申请5ms(此实runtime值为40)。CPU1上的情况也同样如此,先以就绪队列cfs_rq的身份从quota中申请一个时间片,然后供进程运行消耗。当全局quota剩余时间不足以满足CPU0或者CPU1申请时,就需要throttle对应的cfs_rq。在定时器时间到达后,unthrottle所有已经throttle的cfs_rq。
总结一下就是,cfs_bandwidth就像是一个全局时间池(时间池管理时间,类比内存池管理内存)。每个group cfs_rq如果想让其管理的红黑树上的调度实体调度,必须首先向全局时间池中申请固定的时间片,然后供其进程消耗。当时间片消耗完,继续从全局时间池中申请时间片。终有一刻,时间池中已经没有时间可供申请。此时就是throttle cfs_rq的大好时机。
数据结构
每个task_group都包含cfs_bandwidth结构体,主要记录和管理时间池的时间信息。
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
ktime_t period; /* 1 */
u64 quota; /* 2 */
u64 runtime; /* 3 */
struct hrtimer period_timer; /* 4 */
struct list_head throttled_cfs_rq; /* 5 */
/* ... */
#endif
};
- 设定的定时器周期时间。
- 限额时间。
- 剩余可运行时间,在每次定时器回调函数中更新值为quota。
- 上面一直提到的高精度定时器。
- 所有被throttle的cfs_rq挂入此链表,在定时器的回调函数中便利链表执行unthrottle cfs_rq操作。
CFS就绪队列使用cfs_rq结构体描述,和bandwidth相关成员如下:
struct cfs_rq {
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* 1 */
struct task_group *tg; /* 2 */
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled; /* 3 */
u64 runtime_expires;
s64 runtime_remaining; /* 4 */
u64 throttled_clock, throttled_clock_task; /* 5 */
u64 throttled_clock_task_time;
int throttled, throttle_count; /* 6 */
struct list_head throttled_list; /* 7 */
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
- cfs_rq依附的cpu runqueue,每个CPU有且仅有一个rq运行队列。
- cfs_rq所属的task_group。
- 该就绪队列是否已经开启带宽限制,默认带宽限制是关闭的,如果带宽限制使能,runtime_enabled的值为1。
- cfs_rq从全局时间池申请的时间片剩余时间,当剩余时间小于等于0的时候,就需要重新申请时间片。
- 当cfs_rq被throttle的时候,方便统计被throttle的时间,需要记录throttle开始的时间。
- throttled:如果cfs_rq被throttle后,throttled变量置1,unthrottle的时候,throttled变量置0;throttle_count:由于task_group支持嵌套,当parent task_group的cfs_rq被throttle的时候,其chaild task_group对应的cfs_rq的throttle_count成员计数增加。
- 被throttle的cfs_rq挂入cfs_bandwidth->throttled_cfs_rq链表。
bandwidth贡献
周期性调度中会调用update_curr()函数更新当前正在运行进程的虚拟时间。该进程bandwidth贡献也在此时累计。从进程依附的cfs_rq的可用时间中减去进程运行的时间,如果时间不够,就从全局时间池中申请一定时间片。在update_curr()函数中调用account_cfs_rq_runtime()函数统计cfs_rq剩余可运行时间。
static __always_inline
void account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)
return;
__account_cfs_rq_runtime(cfs_rq, delta_exec);
}
如果使能CFS bandwidth control功能,cfs_bandwidth_used()返回1,cfs_rq->runtime_enabled值为1。__account_cfs_rq_runtime()函数如下:
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
/* dock delta_exec before expiring quota (as it could span periods) */
cfs_rq->runtime_remaining -= delta_exec; /* 1 */
expire_cfs_rq_runtime(cfs_rq);
if (likely(cfs_rq->runtime_remaining > 0)) /* 2 */
return;
/*
* if we're unable to extend our runtime we resched so that the active
* hierarchy can be throttled
*/
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr)) /* 4 */
resched_curr(rq_of(cfs_rq)); /* 5 */
}
- 进程已经运行delta_exec时间,因此cfs_rq剩余可运行时间减少。
- 如果cfs_rq剩余运行时间还有,那么没必要向全局时间池申请时间片。
- 如果cfs_rq可运行时间不足,assign_cfs_rq_runtime()负责从全局时间池中申请时间片。
- 如果全局时间片时间不够,就需要throttle当前cfs_rq。当然这里是设置TIF_NEED_RESCHED flag。在后面throttle。
assign_cfs_rq_runtime()函数如下:
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
u64 amount = 0, min_amount, expires;
int expires_seq;
/* note: this is a positive sum as runtime_remaining <= 0 */
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining; /* 1 */
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota == RUNTIME_INF) /* 2 */
amount = min_amount;
else {
start_cfs_bandwidth(cfs_b); /* 3 */
if (cfs_b->runtime > 0) {
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount; /* 4 */
cfs_b->idle = 0;
}
}
expires_seq = cfs_b->expires_seq;
expires = cfs_b->runtime_expires;
raw_spin_unlock(&cfs_b->lock);
cfs_rq->runtime_remaining += amount; /* 5 */
/*
* we may have advanced our local expiration to account for allowed
* spread between our sched_clock and the one on which runtime was
* issued.
*/
if (cfs_rq->expires_seq != expires_seq) {
cfs_rq->expires_seq = expires_seq;
cfs_rq->runtime_expires = expires;
}
return cfs_rq->runtime_remaining > 0; /* 6 */
}
- 从全局时间池申请的时间片默认是5ms。
- 如果该cfs_rq不限制带宽,那么quota的值为RUNTIME_INF,既然不限制带宽,自然时间池的时间是取之不尽用之不竭的,所以申请时间片一定成功。
- 确保定时器是打开的,如果关闭状态,就打开定时器。该定时器会在定时时间到达后,重置全局时间池可用剩余时间。
- 申请时间片成功,全局时间池剩余可用时间更新。
- cfs_rq剩余可用时间增加。
- 如果cfs_rq向全局时间池申请不到时间片,那么该函数返回0,否则返回1,代表申请时间片成功,不需要throttle。
如何throttle cfs_rq
假设上述assign_cfs_rq_runtime()函数返回0,意味着申请时间失败。cfs_rq需要被throttle。函数返回后,会设置TIF_NEED_RESCHED flag,意味着调度即将开始。调度器核心层通过pick_next_task()函数挑选出下一个应该运行的进程。CFS调度器的pick_next_task接口函数是pick_next_task_fair()。CFS调度器挑选进程前会先put_prev_task()。在该函数中会调用接口函数put_prev_task_fair(),函数如下:
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}
prev指向即将被调度出去的进程,我们会在put_prev_entity()函数中调用check_cfs_rq_runtime()检查cfs_rq->runtime_remaining的值是否小于0,如果小于0就需要被throttle。
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return false;
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0)) /* 1 */
return false;
if (cfs_rq_throttled(cfs_rq)) /* 2 */
return true;
throttle_cfs_rq(cfs_rq); /* 3 */
return true;
}
- 检查cfs_rq是否满足被throttle的条件,可用运行时间小于0。
- 如果该cfs_rq已经被throttle,这不需要重复操作。
- throttle_cfs_rq()函数是真正throttle的操作,throttle核心函数。
throttle_cfs_rq()函数如下:
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, dequeue = 1;
bool empty;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))]; /* 1 */
/* freeze hierarchy runnable averages while throttled */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq); /* 2 */
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
break;
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP); /* 3 */
qcfs_rq->h_nr_running -= task_delta;
if (qcfs_rq->load.weight) /* 4 */
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta);
cfs_rq->throttled = 1; /* 5 */
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
empty = list_empty(&cfs_b->throttled_cfs_rq);
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq); /* 6 */
if (empty)
start_cfs_bandwidth(cfs_b);
raw_spin_unlock(&cfs_b->lock);
}
- throttle对应的cfs_rq可以将对应的group se从其就绪队列的红黑树上删除,这样在pick_next_task的时候,顺着根cfs_rq的红黑树往下便利,就不会找到已经throttle的se,也就是没有机会运行。
- task_group可以父子关系嵌套。walk_tg_tree_from()函数功能是顺着cfs_rq->tg往下便利每一个child task_group,并且对每个task_group调用tg_throttle_down()函数。tg_throttle_down()负责增加cfs_rq->throttle_count计数。
- 从依附的cfs_rq的红黑树上删除。
- 如果qcfs_rq运行的进程只有即将被dequeue的se一个的话,那么parent se也需要dequeue。如果qcfs_rq->load.weight不为0,说明qcfs_rq就绪队列上运行的进程不止se一个,那么parent se理所应当不能被dequeue。
- 设置throttle标志位。
- 记录throttle时刻。
- 被throttle的cfs_rq加入cfs_b链表中,方便后续unthrottle操作可以找到这些已经被throttle的cfs_rq。
tg_throttle_down()函数如下,主要是cfs_rq->throttle_count计数递增:
static int tg_throttle_down(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
/* group is entering throttled state, stop time */
if (!cfs_rq->throttle_count)
cfs_rq->throttled_clock_task = rq_clock_task(rq);
cfs_rq->throttle_count++;
return 0;
}
throttle cfs_rq时,数据结构示意图如下:
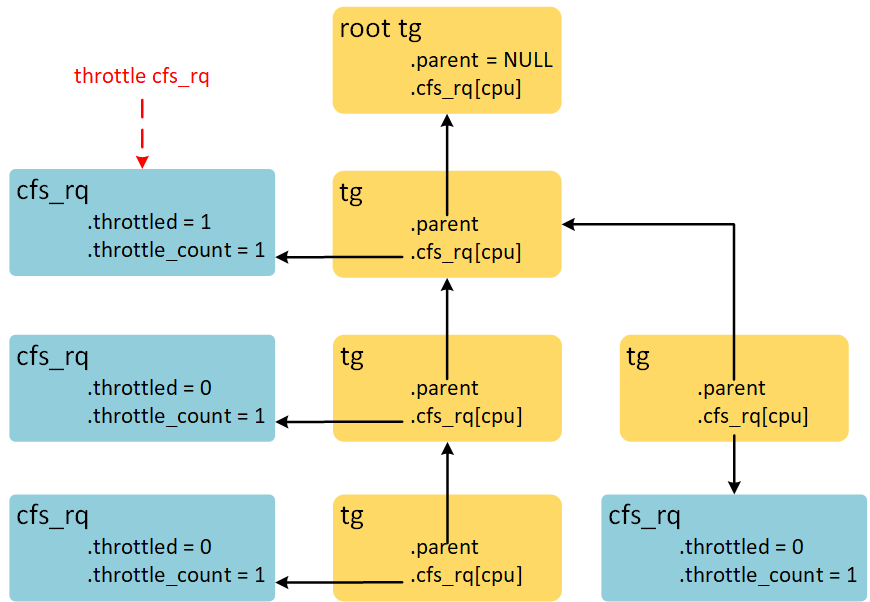
顺着被throttle cfs_rq依附的task_group的children链表,找到所有的task_group,并增加对应CPU的cfs_rq->throttle_count成员。
如何unthrottle cfs_rq
unthrottle cfs_rq操作会在周期定时器定时时间到达之际进行。负责unthrottle cfs_rq操作的函数是unthrottle_cfs_rq(),该函数和throttle_cfs_rq()的操作相反。函数如下:
void unthrottle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
int enqueue = 1;
long task_delta;
se = cfs_rq->tg->se[cpu_of(rq)]; /* 1 */
cfs_rq->throttled = 0; /* 2 */
update_rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock; /* 3 */
list_del_rcu(&cfs_rq->throttled_list); /* 4 */
raw_spin_unlock(&cfs_b->lock);
/* update hierarchical throttle state */
walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq); /* 5 */
if (!cfs_rq->load.weight) /* 6 */
return;
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
if (se->on_rq)
enqueue = 0;
cfs_rq = cfs_rq_of(se);
if (enqueue)
enqueue_entity(cfs_rq, se, ENQUEUE_WAKEUP); /* 7 */
cfs_rq->h_nr_running += task_delta;
if (cfs_rq_throttled(cfs_rq))
break;
}
if (!se)
add_nr_running(rq, task_delta);
/* Determine whether we need to wake up potentially idle CPU: */
if (rq->curr == rq->idle && rq->cfs.nr_running)
resched_curr(rq);
}
- unthrottle操作的做cfs_rq对应的调度实体,调度实体在parent cfs_rq上才有机会运行。
- throttled标志位清零。
- throttled_time记录cfs_rq被throttle的总时间,throttled_clock在throttle_cfs_rq()函数中记录开始throttle时刻。
- 从链表上删除自己。
- tg_unthrottle_up()函数是tg_throttle_down()函数的反操作,递减cfs_rq->throttle_count计数。
- 如果unthrottle的cfs_rq上没有进程,那么无需进行enqueue操作。cfs_rq->load.weight为0就代表就绪队列上没有可运行的进程。
- 将调度实体入队,这里的for循环操作和throttle_cfs_rq()函数的dequeue操作对应。
tg_unthrottle_up()函数如下:
static int tg_unthrottle_up(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
cfs_rq->throttle_count--;
if (!cfs_rq->throttle_count) {
/* adjust cfs_rq_clock_task() */
cfs_rq->throttled_clock_task_time += rq_clock_task(rq) -
cfs_rq->throttled_clock_task;
}
return 0;
}
除了递减cfs_rq->throttle_count计数外,还计算了throttled_clock_task_time时间。和throttled_time不同的是,throttled_clock_task_time时间还包括由于parent cfs_rq被throttle的时间。虽然自己是unthrottle状态,但是parent cfs_rq是throttle状态,自己也是没办法运行的。所以throttled_clock_task_time统计的是cfs_rq->throttle_count从非零变成0经历的时间总和。
周期更新quota
带宽的限制是以task_group为单位,每一个task_group内嵌cfs_bandwidth结构体。周期性的更新quota利用的是高精度定时器,周期是period。struct hrtimer period_timer嵌在cfs_bandwidth结构体就是为了这个目的。定时器的初始化函数是init_cfs_bandwidth()。
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
raw_spin_lock_init(&cfs_b->lock);
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
INIT_LIST_HEAD(&cfs_b->throttled_cfs_rq);
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED);
cfs_b->period_timer.function = sched_cfs_period_timer;
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
}
初始化两个hrtimer,分别是period_timer和slack_timer。period_timer的回调函数是sched_cfs_period_timer()。回调函数中刷新quota,并调用distribute_cfs_runtime()函数unthrottle cfs_rq。distribute_cfs_runtime()函数如下:
static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b,
u64 remaining, u64 expires)
{
struct cfs_rq *cfs_rq;
u64 runtime;
u64 starting_runtime = remaining;
rcu_read_lock();
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq, /* 1 */
throttled_list) {
struct rq *rq = rq_of(cfs_rq);
struct rq_flags rf;
rq_lock(rq, &rf);
if (!cfs_rq_throttled(cfs_rq))
goto next;
runtime = -cfs_rq->runtime_remaining + 1;
if (runtime > remaining)
runtime = remaining;
remaining -= runtime; /* 2 */
cfs_rq->runtime_remaining += runtime; /* 3 */
cfs_rq->runtime_expires = expires;
/* we check whether we're throttled above */
if (cfs_rq->runtime_remaining > 0)
unthrottle_cfs_rq(cfs_rq); /* 3 */
next:
rq_unlock(rq, &rf);
if (!remaining)
break;
}
rcu_read_unlock();
return starting_runtime - remaining;
}
- 循环便利所有已经throttle cfs_rq,函数参数remaining是全局时间池剩余可运行时间。
- remaining是全局时间池剩余时间,这里借给cfs_rq的时间是runtime。
- 如果从全局时间池借到的时间保证cfs_rq->runtime_remaining的值应该大于0,执行unthrottle操作。
另外一个slack_timer的作用是什么呢?我们先思考另外一个问题,如果cfs_rq从全局时间池申请5ms时间片,该cfs_rq上只有一个进程,该进程运行0.5ms后就睡眠了,按照CFS的代码逻辑,整个cfs_rq对应的group se都会被dequeue。那么剩余的4.5ms是否应该归返给全局时间池呢?如果不归返,可能这个进程失眠很久,而其他CPU的cfs_rq很有可能申请不到5ms时间片(全局时间池时间剩余4ms)导致throttle,实际上可用时间是8.5ms。因此,我们针对这种情况会归返部分时间,可以用在其他CPU上消耗。这步处理的函数调用流程是dequeue_entity()->return_cfs_rq_runtime()->__return_cfs_rq_runtime()。
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime; /* 1 */
if (slack_runtime <= 0)
return;
raw_spin_lock(&cfs_b->lock);
if (cfs_b->quota != RUNTIME_INF &&
cfs_rq->runtime_expires == cfs_b->runtime_expires) {
cfs_b->runtime += slack_runtime; /* 2 */
/* we are under rq->lock, defer unthrottling using a timer */
if (cfs_b->runtime > sched_cfs_bandwidth_slice() &&
!list_empty(&cfs_b->throttled_cfs_rq))
start_cfs_slack_bandwidth(cfs_b); /* 3 */
}
raw_spin_unlock(&cfs_b->lock);
/* even if it's not valid for return we don't want to try again */
cfs_rq->runtime_remaining -= slack_runtime; /* 4 */
}
- min_cfs_rq_runtime的值是1ms,我们选择至少保留min_cfs_rq_runtime时间给自己,剩下的时间归返全局时间池。全部归返的做法也是不明智的,有可能该cfs_rq上很快就会有进程运行。如果全部归返,进程运行的时候需要立刻去全局时间池申请,效率低。
- 归返全局时间池slack_runtime时间。
- 开启slack_timer定时器条件有2个(从注释可以得知,使用定时器的原因是当前持有rq->lock锁)。
-
- 全局时间池的时间大于5ms,这样才有可能供其他cfs_rq申请时间片(最小申请时间片大小是5ms)。
- 已经存在throttle的cfs_rq,现在开启slack_timer,在回调函数中尝试分配时间片,并unthrottle cfs_rq。
- cfs_rq剩余可用时间减少。
slack_timer定时器的回调函数是sched_cfs_slack_timer()。sched_cfs_slack_timer()调用do_sched_cfs_slack_timer()处理主要逻辑。
static void do_sched_cfs_slack_timer(struct cfs_bandwidth *cfs_b)
{
u64 runtime = 0, slice = sched_cfs_bandwidth_slice();
u64 expires;
/* confirm we're still not at a refresh boundary */
raw_spin_lock(&cfs_b->lock);
if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) { /* 1 */
raw_spin_unlock(&cfs_b->lock);
return;
}
if (cfs_b->quota != RUNTIME_INF && cfs_b->runtime > slice) /* 2 */
runtime = cfs_b->runtime;
expires = cfs_b->runtime_expires;
raw_spin_unlock(&cfs_b->lock);
if (!runtime)
return;
runtime = distribute_cfs_runtime(cfs_b, runtime, expires); /* 3 */
raw_spin_lock(&cfs_b->lock);
if (expires == cfs_b->runtime_expires)
cfs_b->runtime -= min(runtime, cfs_b->runtime);
raw_spin_unlock(&cfs_b->lock);
}
- 检查period_timer定是时间是否即将到来,如果period_timer时间到了会刷新全局时间池。因此借助于period_timer即可unthrottle cfs_rq。如果,period_timer定是时间还有一段时间,那么此时此刻需要借助当前函数unthrottle cfs_rq。
- 全局时间池剩余可运行时间必须大于slice(默认5ms),因为cfs_rq申请时间片的单位是5ms。
- distribute_cfs_runtime()函数已经分析过,根据传递的参数runtime计算可以unthrottle多少个cfs_rq,就unthrottle几个cfs_rq,尽力而为。
3、用户空间如何使用
CFS bandwidth control提供的接口是以cgroupfs的形式呈现。提供以下三个文件。
- cpu.cfs_quota_us: 一个周期内限额时间,就是文中一直说的quota
- cpu.cfs_period_us: 一个周期时间,就是文中一直说的period
- cpu.stat: 带宽限制状态信息
默认情况下cpu.cfs_quota_us=-1,cpu.cfs_period_us=100ms。quota的值为-1,代表不限制带宽。我们如果想限制带宽,可以往这两个文件写入合法值。quota和period合法值范围是1ms~1000ms。除此之外还需要考虑层级关系。写入cpu.cfs_quota_us负值将不限制带宽。
关于上文一直提到cfs_rq向全局时间池申请时间片固定大小默认是5ms,当然该值也是可以更改的。文件路径如下:
/proc/sys/kernel/sched_cfs_bandwidth_slice_us
cpu.stat文件会输出以下3点信息。
- nr_periods: 目前已经经历时间周期数
- nr_throttled: 用户组发生带宽限制次数
- throttled_time: 用户组中调度实体总的限制时间和
用户组层级限制
cpu.cfs_quota_us和cpu.cfs_period_us接口可以将一个task_group带宽控制在:max(c_i) <= C(这里C代表parent task_group带宽,c_i代表它的children taskgroup)。所有的children task_group中最大带宽不能超过parent task_group带宽。但是,允许所有的children task_group带宽总额大于parent task_group带宽。即:\Sum (c_i) >= C。所以,task_group被throttle有两种可能原因:
- task_group在一个周期时间内消耗完自己的quota
- parent task_group在一个周期时间内消耗完自己的quota
第2种情况下,虽然child task_group仍然剩余quota没有消耗,但是child task_group也必须等到parent task_group下个周期时间到来。
使用举例
- 设置task_group带宽100%period和quota都设置250ms,相当于提供task_group 1个CPU的带宽资源,总的CPU使用率是100%。
echo 250000 > cpu.cfs_quota_us /* quota = 250ms */ echo 250000 > cpu.cfs_period_us /* period = 250ms */
- 设置task_group带宽200%(多核系统)500ms period和1000ms quota设置相当于提供task_group 2个CPU的带宽资源,总的CPU使用率是200%。
echo 1000000 > cpu.cfs_quota_us /* quota = 1000ms */ echo 500000 > cpu.cfs_period_us /* period = 500ms */
更大的period时间,可以增加task_group吞吐量。
- 设置task_group带宽20%以下配置可以使用20% CPU带宽资源。
echo 10000 > cpu.cfs_quota_us /* quota = 10ms */ echo 50000 > cpu.cfs_period_us /* period = 50ms */
在使用更小的period的情况下,周期越短相应延迟越小。
六、CFS调度器-总结
经过前面一系列的文章描述,我们已经对CFS调度器有了一定的认识。那么本篇文章就作为一篇总结和思考。我们就回忆一下CFS调度器的那些事。我们就以问题的形式重新回顾一遍CFS调度器设计的原理。现在开始,我们问题来了。
1、CFS调度器为什么要引入虚拟时间片vruntime?
我觉得如果所有的进程不存在优先级区分的话,我们完全可以不引入vruntime的概念。所有的进程需要运行的实际时间都是一样的,大家都保持绝对的公平。如果由我们设计调度器,当然完全可以记录每个进程运行的实际时间。每次调度选择下一个进程的时候,我们完全可以挑选出已经运行时间最短的进程。当然,进程是存在轻重关系的。用户认为重要的进程,就是应该运行更长的时间。此时不同的进程由于优先级的原因导致运行时间不等。如果我们依然想采用像没有优先级的时候的方法去选择下一个运行的进程的话,自然有点困难。因为现在不同的进程运行的时间就是应该不一样,我们还怎么评判哪个进程运行时间最少呢。所以我们引入虚拟时间的概念。现在我们希望不同的进程根据优先级分配的物理时间通过一个公式计算得到一个相同的值,我们称这个值为虚拟时间。我们记录每个进程运行的虚拟时间,当需要选择下一个运行进程的时候,找出虚拟时间最小的进程即可。
2、新建进程的vruntime的初值是不是0?
我们先考虑另一个问题,通过fork()创建的新进程的vruntime如果是0会怎么样?就绪队列上所有的进程的vruntime都已经是很大的一个值。如果新建进程的vruntime的值是0的话,根据CFS调度器pick_next_task_fair()逻辑,我们会倾向选择新建进程,一直让其更多的运行,追赶上就绪队列中其他进程的vruntime。既然不能是0,初值应该是什么比较合理呢?当然是和就绪队列上所有进程的vruntime的值差不多。具体怎么操作,下个问题揭晓。
3、就绪队列记录的min_vruntime的作用是什么?
首先我们需要明白的是min_vruntime记录的究竟是什么。min_vruntime记录的是就绪队列管理的所有进程的最小虚拟时间。理论上来说,所有的进程的虚拟时间都大于min_vruntime。记录这个时间有什么用呢?我认为主要有3点作用。
- 当我们fork()一个新的进程的时候,虚拟时间肯定不能赋值0。否则的话,新建的进程会追赶其他进程,直到和就绪队列上其他进程的虚拟时间相当。这当然是不公平的,也是不可合理的设计。所以针对新fork()的进程,我们根据min_vruntime的值适当调整后赋值给新进程的虚拟时间。这样就不会出现新建的进程疯狂的运行。
- 当进程sleep一段时间被wakeup的时候,此时也仅是物是人非。同样面临着类似新建进程的境况。同样我们需要根据min_vruntime的值适当调整后赋值给该进程。
- 针对migration进程,我们面临一个新的问题。每个CPU上就绪队列的min_vruntime的值各不相同。有可能相差很多。如果进程从CPU0迁移到CPU1的话,进程的vruntime是否应该改变呢?当时是需要的,否则就会面临迁移后受到惩罚或者奖励。我们的方法是进程进程的vruntime减去CPU0的min_vruntime,然后加上CPU1的min_vruntime。
4、唤醒的进程的vruntime该如何处理?
经过上一个问题,我们应该有点答案了。如果睡眠时间很长,自然是根据min_vruntime的值处理。问题是我们该如何处理?我们会根据min_vruntime的值减去一个数值作为唤醒进程的vruntime。为何减去一个值呢?我认为该进程已经sleep很长时间,本身就没有太占用CPU时间。给点补偿也是正常的。大多数的交互式应用,基本都是属于这种情况。这样处理,又提高了交互式应用的相应速度。如果sleep时间很短呢?当然是不需要干涉该进程的vruntime。
5、就绪队列上所有的进程的vruntime都一定大于min_vruntime吗?
答案当然不是的。我们虽然引入min_vruntime的意义是最终就绪队列上所有进程的最小虚拟时间,但是并不能代表所有的进程vruntime都大于min_vruntime。这个问题在部分的情况下是成立的。例如,上面提到给唤醒进程vruntime一定的补偿,就会出现唤醒的进程的vruntime的值小于min_vruntime。
6、唤醒的进程会抢占当前正在运行的进程吗?
分成两种情况,这个取决于唤醒抢占特性是否打开。即sched_feat的WAKEUP_PREEMPTION。如果没有打开唤醒抢占特性,那么就没有后话了。现在考虑该特性打开的情况。由于唤醒的进程会根据min_vruntime的值进行一定的奖励,因此存在很大的可能vruntime小于当前正在运行进程的vruntime。当时是否意味着只要唤醒进程的vruntime比当前运行进程的vruntime小就抢占呢?并不是。我们既要满足小的条件,又要在此基础上附加条件。两者差值必须大于唤醒粒度时间。该时间存在变量sysctl_sched_wakeup_granularity中,默认值1ms。
7、min_vruntime初始值为何如此奇怪?
就绪队列struct cfs_rq初始化是通过init_cfs_rq()函数进行。该函数如下:
void init_cfs_rq(struct cfs_rq *cfs_rq)
{
cfs_rq->min_vruntime = (u64)(-(1LL << 20));
}
初始值是U64_MAX - (1LL << 20),U64_MAX代表64 bits无符号整型最大值。这里,我也有同样的疑问,min_vruntime为何初值不是0,搞个这么大的数是什么意思,和0相比有什么好处吗。当然,我也没有找到答案。下面都是我的猜测,和大家分享。min_vruntime单位是ns。也就是说系统运行大概(1<<20)ns,大约1ms的时间min_vruntime就会溢出。因此,原因可能就是为了更早的发现由于min_vruntime数值溢出导致的问题。如果初值是0的话,我们如果要提前发现min_vruntime溢出导致的问题大概需要545年时间(以NICE为0的进程计算,如果以NICE值为20计算的话,只需要8年左右时间)。
8、最小粒度时间sysctl_sched_min_granularity是否一定会满足?
CFS调度周期的时间设定取决于进程的数量,根据__sched_period()函数可知,当进程的数量大于sched_nr_latency时,调度周期的时间等于进程数量乘以sysctl_sched_min_granularity。
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
但是这样做是否就意味着进程至少运行sysctl_sched_min_granularity时间才会被抢占呢?如果所有进程的优先级都一样的话,结果的确是这样的。但是当存在优先级不同的进程的时候,而且系统进程数量大于sched_nr_latency,那么NICE值高的进程并不能保证最少运行sysctl_sched_min_granularity时间被强占。这是一种特殊的情况,这种进程在一个调度周期内分配的总时间都不足sysctl_sched_min_granularity。
如果有进程在一个周期内分配的份额大于sysctl_sched_min_granularity会是什么情况呢?在这种情况下,CFS调度器倒是可能可以保证最小粒度时间。我们看下check_preempt_tick()。
- 如果进程运行时间超过本周期分配时间,just reschedule it。
- 第1处不满足,如果这里运行时间不足最小粒度时间,直接退出。
原文地址:
CFS调度器(6)-总结
CFS调度器(5)-带宽控制
CFS调度器(4)-PELT(per entity load tracking)
CFS调度器(3)-组调度
CFS调度器(2)-源码解析
CFS调度器(1)-基本原理







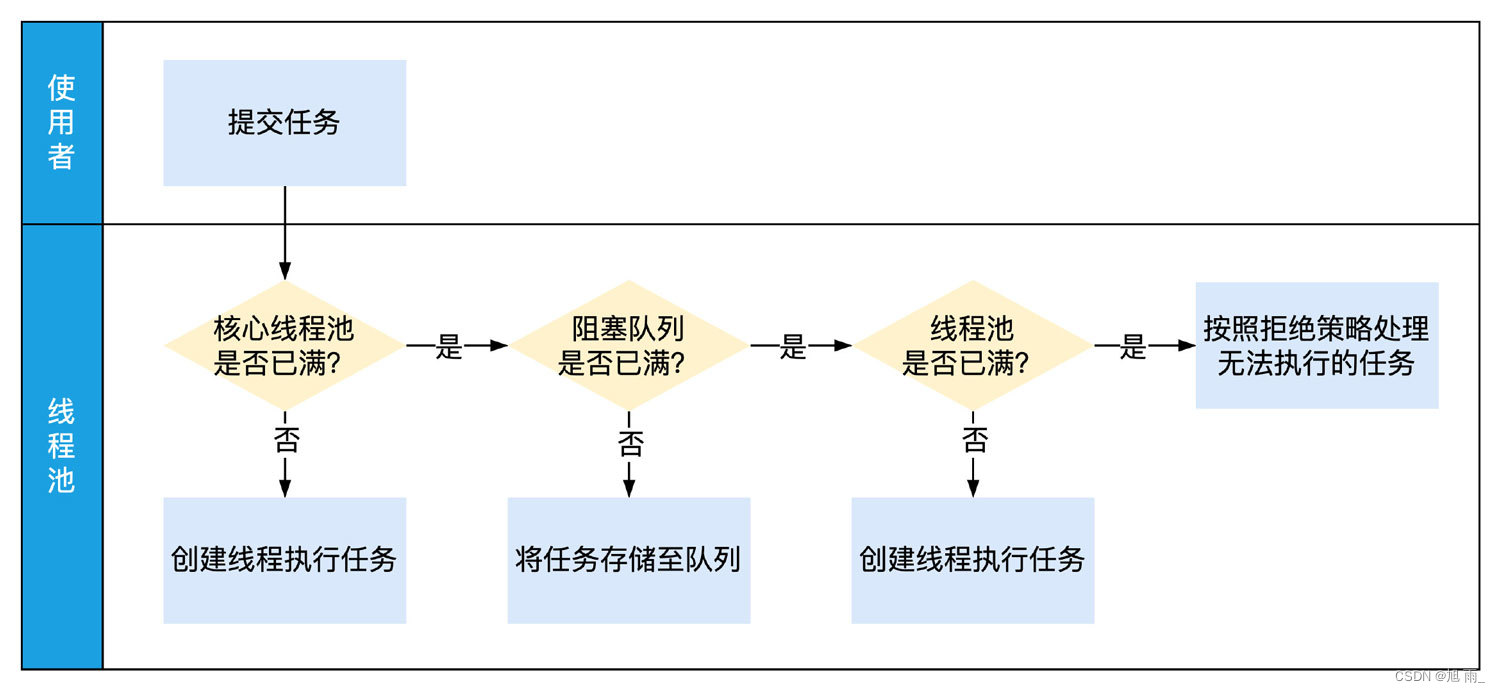
![[Java] 观察者模式简述](https://img-blog.csdnimg.cn/5748f0279fe34db4abff51248e1a55c0.png)