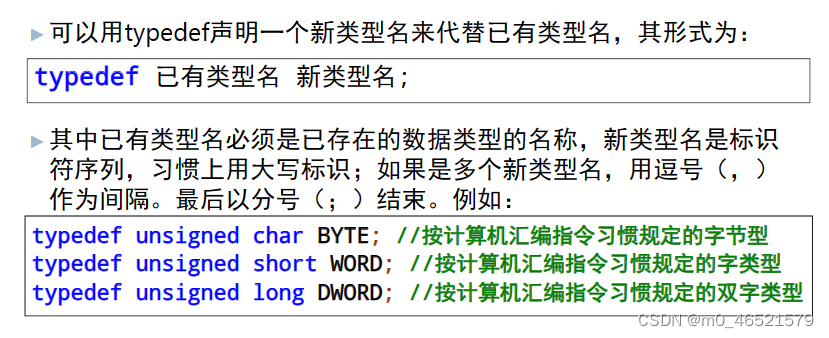
文章目录
- 1、分布式监控系统
- 2、OpenTelemetry
- 3、OpenTelemetry-Trace相关组件
- 4、Context Propagation搭配HTTP Header传递信息
- 5、Span相关
1、分布式监控系统
随着单体架构演变为微服务架构,线上问题的追踪和排查变的越来越困难,想解决这个问题就得实现线上业务的可观测性。由此,涌现出许多链路追踪和服务监控的中间件,如:
- Java玩家常用的SpringCloud Seluth + MQ + Zipkin
- skywalking
- 阿里的鹰眼
- 大众点评的Cat
- …
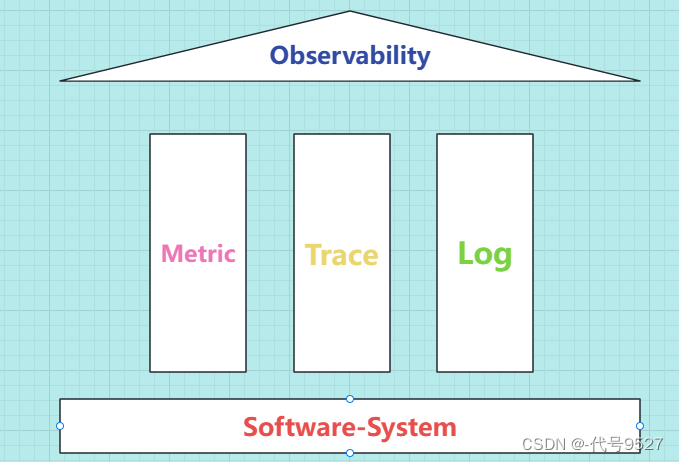
而监控系统主要有三个维度:
- Mertic:度量系统
- Tracing:追踪系统
- Logging:日志系统
Metric:
Metric,即度量,可聚合性是Metric的特征,比如服务的QPS是多少、当天用户的登录次数、CPU和内存占用情况,这时就需要需要将一段时间内的一部分时间进行聚合或者计数。
Logging:
和Metric相比,Logging则是离散事件,日志是系统运行时发生的一个个事件的记录,为问题排查提供详细信息。
Tracing:
Trace,即追踪,是一个最外层请求下所包含的所有调用信息,如请求过来,先到gateway服务,再路由到服务A,再远程调用服务B,再调数据库、缓存等一条完整的链路。
Metric、Logging、Trace在监控中是相辅相成的:
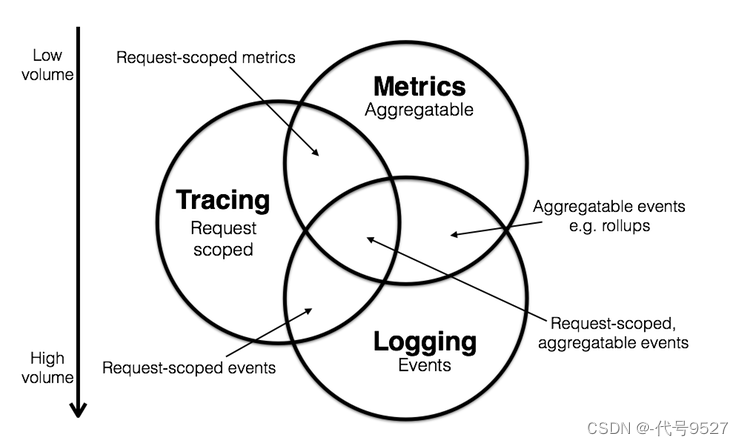
看这个图中两两相交的部分:通过度量和日志维度,我们可以作一些事件的聚合统计(如某应用每分钟的错误日志数)。通过链路追踪和日志系统,我们可以得到某个请求详细的请求信息(如请求的入参、出参、链路中途方法打印出的日志信息等)。通过度量和链路系统,我们可以查到某种类请求(通常是慢请求)的调用信息(如慢请求的问题排查及优化)。可见,通过这三种类型数据相互作用,可以得到很多在单单某一种数据中无法呈现的信息。
2、OpenTelemetry
OpenTelemetry is an Observability framework. OpenTelemetry is not an observability back-end like Jaeger, Prometheus, or commercial vendors. OpenTelemetry is focused on the generation, collection, management, and export of telemetry data. The storage and visualization of that data is intentionally left to other tools.
即OpenTelemetry 是一个可观测性框架,它不像Jaeger、Prometheus,而是专注于 生成、收集 、导出 Telemetry遥测数据(Metrics,Logs and traces)。存储和可视化数据的事儿则留给其他工具,比如Zipkin、Jageger、skywalking、Prometheus等…
官方文档:
https://opentelemetry.io/docs/instrumentation/java/manual/
3、OpenTelemetry-Trace相关组件
整理下Trace相关的概念,Metric 和 Log 的移步官网文档。
Traces give us the big picture of what happens when a request is made to an application. Whether your application is a monolith with a single database or a sophisticated mesh of services, traces are essential to understanding the full “path” a request takes in your application.
Trace向我们提供了向程序发出请求时发生的全局,无论程序是具有单个数据库的整体还是复杂的服务网格,trace对于了解请求在程序中的完整路径都是必不可少的。接下来整理下在整个Trace中发挥作用的组件:
1)TraceProvider :
TraceProvider是创建Tracer的工厂,它在服务中只会初始化一次,生命周期和服务的生命周期相同,初始化traceProvider对象,需要带上两个参数:Exporter和Resource,前者为导出的目的端信息,后者为一些资源信息。创建这个对象是使用OpenTelemetry的第一步,示例程序:
//....
SpanProcessor spanProcessor = getOtlpProcessor();
//resource通常用于添加非临时的底层元数据信息,如服务名、实例名、命名空间等
Resource serviceNameResource = Resource.create(Attributes.of(
ResourceAttributes.SERVICE_NAME, "myServiceName"));
// Set to process the spans by the Zipkin Exporter
SdkTracerProvider tracerProvider =SdkTracerProvider.builder()
.addSpanProcessor(spanProcessor) //Exporter导出端
.setResource(Resource.getDefault().merge(serviceNameResource)) //设置上面的resource
.build();
//....
2)Tracer :
Trace由TracerProvider创建,它自己则是用来创建Span的,Span中又包含相关操作下(如请求一个服务)所发生情况的详细信息(一条链路,共用一个traceId,再由一个个span连接起来)。示例程序:
import io.opentelemetry.api;
//...
OpenTelemetrySdk openTelemetry =
OpenTelemetrySdk.builder().setTracerProvider(tracerProvider)
.setPropagators(ContextPropagators.create(W3CTraceContextPropagator.getInstance()))
.buildAndRegisterGlobal();
Tracer tracer =
openTelemetry.getTracer("instrumentation-library-name", "1.0.0");
//上面getTracer方法的形参instrumentation-library-name指定用于跟踪的库的名称
//该方法重载,只传一个参数时是instrumentationScopeName,用于指定当前追踪器的作用域名称
//通常情况下,作用域名称可以是应用程序的名称、模块名称、服务名称等,以便在分布式系统中明确标识追踪数据的来源
3)TraceExporter :
TraceExporter把生产的Span发送到Trace接收器,既可以发送到本地文件来调试,也可以发送到远端的链路分析端,如ZipKin
整个流程如下:
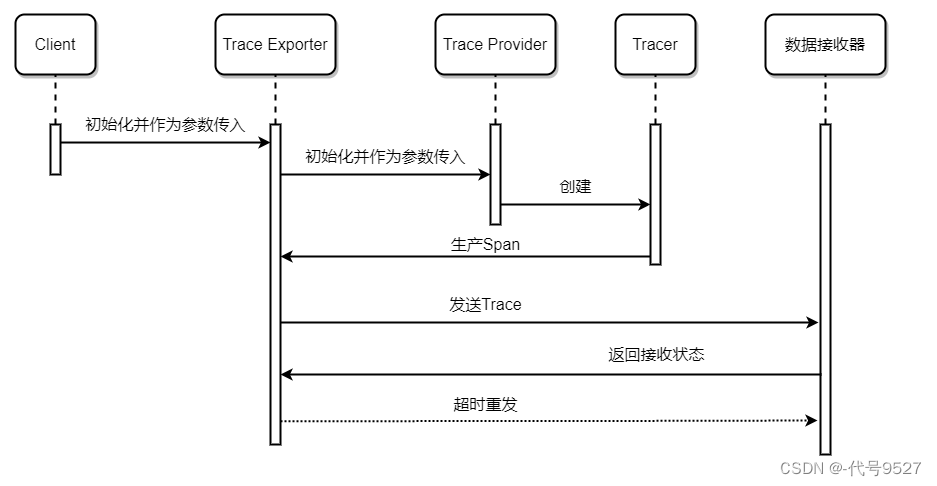
结合上面Tracer的示例程序看这个时序图:
- traceExporter做为初始化traceProvider对象时的参数传入
- traceProvider又做为初始化OpenTelemetrySdk操作对象时的参数传入
- OpenTelemetrySdk对象去创建tracer
- tracer生产span
- TracerExporter来发送Trace到数据接收器(本地或远端)
- traceId相同的span被远端链路分析端串起来,由此显示整个链路
4)Context Propagator :
Context Propagator,上下文传播器。在分布式系统中,为了实现对不同部分和组件的追踪和监控,通常需要将跟踪信息从应用程序的一部分传递到另一部分。Context Propagator提供了一种机制,用于在分布式系统中传播跟踪上下文信息。
当一个请求到达应用程序时,Context Propagator会收集请求的上下文信息,并将其传递到应用程序的各个部分。在每个部分中,Context Propagator会更新并传播上下文信息,以便在分布式系统中保持一致性。
OpenTelemetry支持几种不同的上下文格式。默认格式是W3C TraceContext。每个上下文对象都是存储在Span中。
5)TextMapPropagator :
TextMapPropagator 的作用是将跟踪上下文以文本格式存储在一个映射(map)中,将其传递到应用程序的其他部分。
//创建了一个 TextMapPropagator 实例,并使用 TextMapReader 和 TextMapWriter 分别作为读取和写入文本格式跟踪上下文的组件
TextMapPropagator textMapPropagator = new TextMapPropagator(new TextMapReader(), new TextMapWriter());
//注入一条数据,实际开发注入trace信息
textMapPpropagator.inject(TextMap.create("user_id", "123"));
//调用 extract() 方法,从分布式系统中提取文本格式的跟踪上下文
TextMap<?, ?> distributedTraceContext = propagator.extract();
以上是个简单例子。实际对传播器的应用应该是:OpenTelemetry使用W3C Trace Context HTTP请求头来传播上下文信息
4、Context Propagation搭配HTTP Header传递信息
注入:
首先要告诉Telemetry注入上下文信息到请求头里,核心方法是TextMapPropagator类里的inject方法:

先看官方给的例子分析直接写注释里了:
// 先创建TextMapSetter对象,泛型指定为HttpURLConnection类型
//匿名内部类,实现set方法,表示将一个键值对添加到HttpHeader中
//TextMapSetter对象也就是未来inject方法的第三个形参的值
TextMapSetter<HttpURLConnection> setter =
new TextMapSetter<HttpURLConnection>() {
@Override
public void set(HttpURLConnection carrier, String key, String value) {
// Insert the context as Header
carrier.setRequestProperty(key, value);
}
};
URL url = new URL("http://127.0.0.1:8080/resource");
//创建span
Span outGoing = tracer.spanBuilder("/resource").setSpanKind(SpanKind.CLIENT).startSpan();
try (Scope scope = outGoing.makeCurrent()) {
// 添加一堆乱七八糟的属性
// (Note that to set these, Span does not *need* to be the current instance in Context or Scope.)
outGoing.setAttribute(SemanticAttributes.HTTP_METHOD, "GET");
outGoing.setAttribute(SemanticAttributes.HTTP_URL, url.toString());
//创建个HttpURLConnection对象,即inject方法的第二个参数
HttpURLConnection transportLayer = (HttpURLConnection) url.openConnection();
// Inject the request with the *current* Context, which contains our current Span.
//创建上下文传播器对象,调用inject方法
//注入上上下文信息到HTTP连接的HttpHeader中
openTelemetry.getPropagators().getTextMapPropagator().inject(Context.current(), transportLayer, setter);
// Make outgoing call
} finally {
outGoing.end();
}
...
以上,就实现了上下文信息写到了Http请求头里,接下来,以上面的例子为参考,自己定义一个inject方法,对官方的inject做个封装,方便后续信息往Header的注入:
private void inject(ServerWebExchange serverWebExchange) {
//先创建个空的HttpHeaders对象
HttpHeaders httpHeaders = new HttpHeaders();
//创建文本映射传播器对象,用来调用官方inject方法
TextMapPropagator textMapPropagator = openTelemetry.getPropagators().getTextMapPropagator();
//HttpHeaders::add是一个方法引用,表示将一个键值对添加到HttpHeaders对象中
//HttpHeaders::add和上面官方例子中的匿名内部类,实现TextMapSetter对象set方法,一个意思
textMapPropagator.inject(Context.current(), httpHeaders, HttpHeaders::add);
//getRequest() 方法从serverWebExchange取出里面的原始请求对象
//mutate() 方法创建一个新的请求对象
ServerHttpRequest request = serverWebExchange.getRequest().mutate()
//将 httpHeaders 对象里的信息全部添加到新的请求对象中
.headers(headers -> headers.addAll(httpHeaders))
.build(); //此时这个request对象是的请求头是带上下文信息的
//将原始的ServerWebExchange对象中的请求对象替换为新的request对象
serverWebExchange.mutate().request(request).build();
}
//传入一个ServerWebExchange对象对象,经过修改,新的ServerWebExchange对象包含了修改后的request对象
//而request对象是有上下文信息的
//由此完成ServerWebExchange对象的改造,也就是上下文信息的注入
上面用到了一个mutate方法,mutate直译就是变异的意思。它用于创建一个新的请求对象,该对象是原始请求对象的副本,并对副本进行修改。如上面以从ServerWebExchange中取出Request对象创建副本,造我自己的request对象。
mutate() 方法的主要作用是允许对请求对象进行自定义修改,例如添加新的属性、修改现有属性或添加自定义的跟踪数据。这些修改不会影响原始请求对象,而是创建一个新的副本。
举例:
ServerWebExchange exchange = ...;
Request request = exchange.getRequest();
//以从ServerWebExchange对象中取出的request对象,创建副本,进行修改
// 创建新的请求对象,并添加自定义属性
mutator.mutate(request).addHeader("Custom-Header", "Custom Value");
// 修改请求头
mutator.mutate(request).setHeader("Header-Name", "Header Value");
// 添加自定义跟踪数据
mutator.mutate(request).setTraceId("12345678-9abc-def0-1234-56789abcdef0");
// 执行请求处理逻辑
// ...
提取:
同样的,也可以从过来的请求里读W3C Trace Context信息, 核心方法是TextMapPropagator类里的extract方法:

官方给的例子:
TextMapGetter<HttpExchange> getter =
new TextMapGetter<>() {
@Override
public String get(HttpExchange carrier, String key) {
if (carrier.getRequestHeaders().containsKey(key)) {
return carrier.getRequestHeaders().get(key).get(0);
}
return null;
}
@Override
public Iterable<String> keys(HttpExchange carrier) {
return carrier.getRequestHeaders().keySet();
}
};
...
public void handle(HttpExchange httpExchange) {
// Extract the SpanContext and other elements from the request.
Context extractedContext = openTelemetry.getPropagators().getTextMapPropagator()
.extract(Context.current(), httpExchange, getter);
try (Scope scope = extractedContext.makeCurrent()) {
// Automatically use the extracted SpanContext as parent.
Span serverSpan = tracer.spanBuilder("GET /resource")
.setSpanKind(SpanKind.SERVER)
.startSpan();
try {
// Add the attributes defined in the Semantic Conventions
serverSpan.setAttribute(SemanticAttributes.HTTP_METHOD, "GET");
serverSpan.setAttribute(SemanticAttributes.HTTP_SCHEME, "http");
serverSpan.setAttribute(SemanticAttributes.HTTP_HOST, "localhost:8080");
serverSpan.setAttribute(SemanticAttributes.HTTP_TARGET, "/resource");
// Serve the request
...
} finally {
serverSpan.end();
}
}
}
写个简略版的实现:这个方法的核心是提取httpServletRequest对象里的Header信息,顺便再返回一个Span,这个Span通过setParent方法,传入提取到的信息的新context对象,从而完成链接。
private Span getServerSpan(Tracer tracer, HttpServletRequest httpServletRequest) {
TextMapPropagator textMapPropagator = openTelemetry.getPropagators().getTextMapPropagator();
Context context = textMapPropagator.extract(Context.current(), httpServletRequest, new TextMapGetter<HttpServletRequest>() {
@Override
public Iterable<String> keys(HttpServletRequest request) {
List<String> headers = new ArrayList();
for (Enumeration names = request.getHeaderNames(); names.hasMoreElements();) {
String name = (String)names.nextElement();
headers.add(name);
}
return headers;
}
@Override
public String get(HttpServletRequest request, String s) {
return request.getHeader(s);
}
});
return tracer.spanBuilder(httpServletRequest.getRequestURI())
.setParent(context)
.setSpanKind(SpanKind.SERVER)
.setAttribute(SemanticAttributes.HTTP_METHOD, httpServletRequest.getMethod())
.startSpan();
}
再贴上官方给的完整示例,即利用 HttpHeaders 获取用于上下文传播的跟踪父标:
TextMapGetter<HttpHeaders> getter =
new TextMapGetter<HttpHeaders>() {
@Override
public String get(HttpHeaders headers, String s) {
assert headers != null;
return headers.getHeaderString(s);
}
@Override
public Iterable<String> keys(HttpHeaders headers) {
List<String> keys = new ArrayList<>();
MultivaluedMap<String, String> requestHeaders = headers.getRequestHeaders();
requestHeaders.forEach((k, v) ->{
keys.add(k);
});
}
};
TextMapSetter<HttpURLConnection> setter =
new TextMapSetter<HttpURLConnection>() {
@Override
public void set(HttpURLConnection carrier, String key, String value) {
// Insert the context as Header
carrier.setRequestProperty(key, value);
}
};
//...
public void handle(<Library Specific Annotation> HttpHeaders headers){
Context extractedContext = opentelemetry.getPropagators().getTextMapPropagator()
.extract(Context.current(), headers, getter);
try (Scope scope = extractedContext.makeCurrent()) {
// Automatically use the extracted SpanContext as parent.
Span serverSpan = tracer.spanBuilder("GET /resource")
.setSpanKind(SpanKind.SERVER)
.startSpan();
try(Scope ignored = serverSpan.makeCurrent()) {
// Add the attributes defined in the Semantic Conventions
serverSpan.setAttribute(SemanticAttributes.HTTP_METHOD, "GET");
serverSpan.setAttribute(SemanticAttributes.HTTP_SCHEME, "http");
serverSpan.setAttribute(SemanticAttributes.HTTP_HOST, "localhost:8080");
serverSpan.setAttribute(SemanticAttributes.HTTP_TARGET, "/resource");
HttpURLConnection transportLayer = (HttpURLConnection) url.openConnection();
// Inject the request with the *current* Context, which contains our current Span.
openTelemetry.getPropagators().getTextMapPropagator().inject(Context.current(), transportLayer, setter);
// Make outgoing call
}finally {
serverSpan.end();
}
}
}
5、Span相关
Span就是整个链路的一个操作单元,同一个traceId下的一个个span连接起来就是整个调用链路。接下来整理Span的基本操作,先是创建span:
//only need to specify the name of the span,即只需指定名字,起止时间SDK自动做完了
//The start and end time of the span is automatically set by the OpenTelemetry SDK.
Span span = tracer.spanBuilder("my span").startSpan();
//Scope是一个跟踪范围的概念,它表示一次分布式追踪中的所有操作和请求的集合
// Make the span the current span
try (Scope ss = span.makeCurrent()) {
//span.makeCurrent()即当前范围里的操作的span就是我上面创建的那个span
// In this scope, the span is the current/active span
} finally {
span.end(); //结束span
}
获取当前span,直接调静态方法:
Span span = Span.current()
也可获取某个Context对象里的Span对象:
Span span = Span.fromContext(context)
Span可以嵌套,Span的子Span即这个操作下的一个子操作。比如一个方法调用一个方法,就可以手动的将span链接起来:
void parentOne() {
Span parentSpan = tracer.spanBuilder("parent").startSpan();
try {
childOne(parentSpan);
} finally {
parentSpan.end();
}
}
void childOne(Span parentSpan) {
Span childSpan = tracer.spanBuilder("child")
.setParent(Context.current().with(parentSpan))
.startSpan();
try {
// do stuff
} finally {
childSpan.end();
}
}
若要链接来自远程进程的Span,只需将远程上下文设置为父级即可,不用再with()
Span childRemoteParent = tracer.spanBuilder("Child")
.setParent(remoteContext)
.startSpan();
OpenTelemetry框架下的Span包含以下信息:
- Name
- Parent span ID (empty for root spans)
- Start and End Timestamps
- Span Context
- Attributes
- Span Events
- Span Links
- Span Status
举个例子:
{
"name": "hello",
"context": {
"trace_id": "0x5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "0x051581bf3cb55c13"
},
"parent_id": null, # 父span的id,为空即和其他span平级
"start_time": "2022-04-29T18:52:58.114201Z",
"end_time": "2022-04-29T18:52:58.114687Z",
"attributes": {
"http.route": "/v1/sys/health"
},
"events": [
{
"name": "Guten Tag!",
"timestamp": "2022-04-29T18:52:58.114561Z",
"attributes": {
"event_attributes": 1
}
}
]
}
名称、父Span的id,开始结束时间戳不再细说,看看其他的属性:
1)Span Context :
Span的不可变对象,里面又包含:
- 所属trace的TraceId
- 自己的SpanId
- TraceFlags,二进制形式的调用链标志位,用于表示这条trace链是否被采样(isSampled)
- TraceState,承载调用链信息的K-V(键对值)结构列表

2)Attributes :
即属性,一系列元数据信息的键值对,用来携带这个span对应的操作的一些信息。
Span span = tracer.spanBuilder("/resource/path").setSpanKind(SpanKind.CLIENT).startSpan();
span.setAttribute("http.method", "GET");
span.setAttribute("http.url", url.toString());
//Keys must be non-null string values
//Values must be a non-null string, boolean, floating point value, integer, or an array of these values
3)Span Events :
用来记录Span在某一时刻发生的有意义的事件。
span.addEvent("Init");
...
span.addEvent("End");
当然也不止只能写个字符串,这个方法是重载的:
Attributes eventAttributes = Attributes.of(
AttributeKey.stringKey("key"), "value",
AttributeKey.longKey("result"), 0L);
span.addEvent("End Computation", eventAttributes);
4)Span Links :
用来关联异步操作的另一个span的SpanContext。一个响应下面对应一些操作,另一个操作将排队等待执行,但其执行是异步的。可以链接第一条trace的最后一个span到第二条trace的第一个span,如此,它们之间就有了因果关系。
//创建span的时候去addLink
Span child = tracer.spanBuilder("childWithLink")
.addLink(parentSpan1.getSpanContext())
.addLink(parentSpan2.getSpanContext())
.addLink(parentSpan3.getSpanContext())
.addLink(remoteSpanContext)
.startSpan();
5)Span Status :
就是给Span加个状态,比如出现异常时设置span状态为error。共有三种状态:
- Unset
- Ok
- Error
Span span = tracer.spanBuilder("my span").startSpan();
// put the span into the current Context
try (Scope scope = span.makeCurrent()) {
// do something
} catch (Throwable throwable) {
span.setStatus(StatusCode.ERROR, "Something bad happened!");
//Record exceptions in spans
span.recordException(throwable);
} finally {
span.end(); // Cannot set a span after this call
}
上面这个架子,配合过滤器来手动埋点如下:
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest)servletRequest;
Span span = getServerSpan(openTelemetry.getTracer(appConfig.getApplicationName()), httpServletRequest);
try (Scope scope = span.makeCurrent()) {
filterChain.doFilter(servletRequest, servletResponse);
} catch (Exception ex) {
span.setStatus(StatusCode.ERROR, "HTTP Code: " + ((HttpServletResponse)servletResponse).getStatus());
span.recordException(ex);
throw ex;
} finally {
span.end();
}
}
5)Span Kind :
不同种类的span用在不同类型的操作中,span类型在创建span时设置。官方文档里说根据OpenTelemetry规范:
the parent of a server span is often a remote client span, and the child of a client span is usually a server span. Similarly, the parent of a consumer span is always a producer and the child of a producer span is always a consumer. If not provided, the span kind is assumed to be internal.
- Client
- Server
- Internal
- Producer
- Consumer
本质是种规范,了解下,不想扣文字。
Span span = tracer.spanBuilder(httpServletRequest.getRequestURI())
.setSpanKind(SpanKind.SERVER) //设置为Server类型
.startSpan();
![[Java] 观察者模式简述](https://img-blog.csdnimg.cn/5748f0279fe34db4abff51248e1a55c0.png)