实验环境:
操作系统:Linux (Ubuntu 20.04.5)
Hadoop版本:3.3.2
JDK版本:1.8.0_162
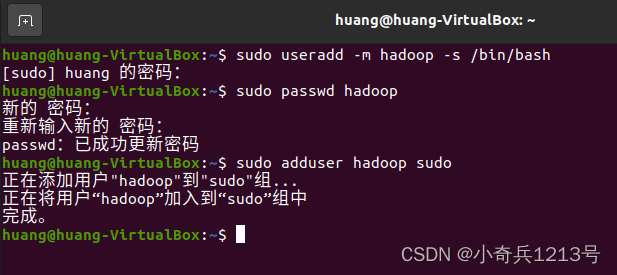
(1)创建 hadoop 用户(使用 /bin/bash 作为 Shell)、设置密码(建议简单)并为其添加管理员权限。具体命令如下:
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
(2)切换到 hadoop 用户
sudo su - hadoop

(3)安装 SSH server,并测试登陆。
sudo apt-get install openssh-server
ssh localhost

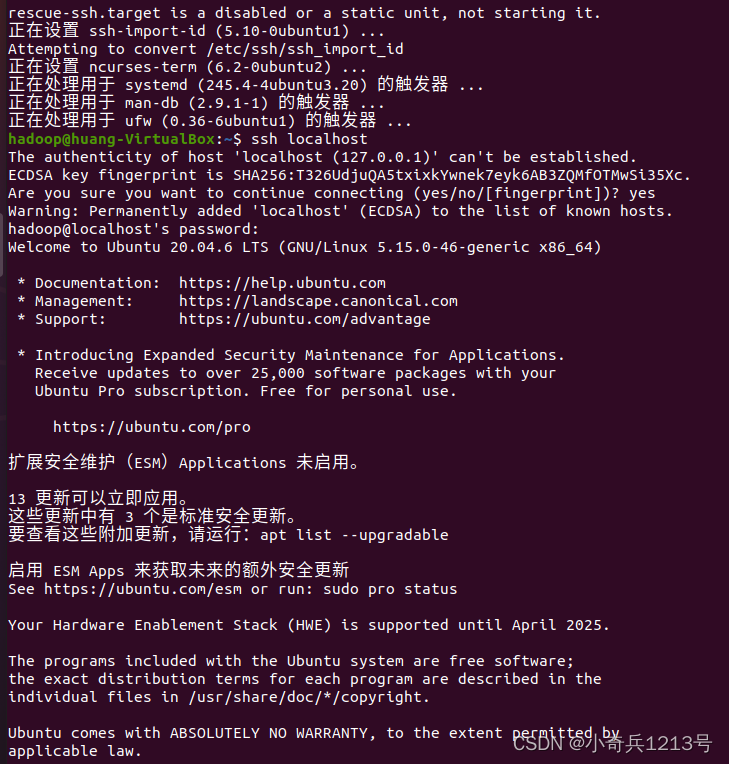
在执行命令时,注意要按照指示输入 yes,再输入 hadoop 用户的密码。在执行结束后,即可通过 SSH 登陆到本机。由于 hadoop 需要通过 SSH 来控制集群,所以需要对 SSH 设置免密登陆,即允许名称节点可以无密码登录集群中的所有机器。
(4)设置SSH 免密登录,利用 ssh-keygen 生成密钥并将秘钥加入到授权中
exit #退出刚才的ssh localhost
cd ~/.ssh/ #若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa #会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys #加入授权
在执行 ssh-keygen -t rsa 命令时,每次按回车键即可。此时免密设置完成,使用 ssh localhost 进行验证。


(5)安装 Java环境。Hadoop 3.3.2需要JDK版本在1.8及以上。JDK 1.8安装方式多种多样。这里采取手动安装,需要自行下载 JDK1.8 的安装包。将 JDK 安装包放在 Downloads 目录下,并且创建存放 JDK 文件的目录。如果在切换 Downloads 目录时出现找不到目录,可以重启系统,手动选择进入 hadoop 用户。
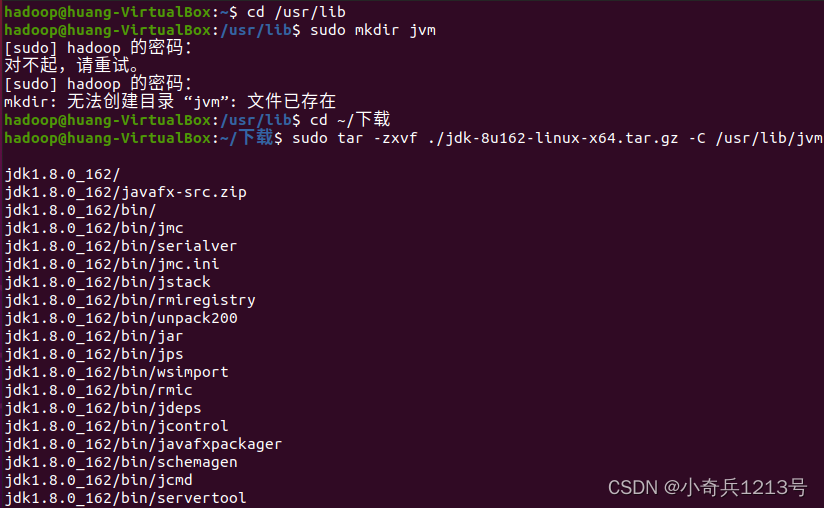
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件

cd ~/Downloads (Ubuntu为中文版则为cd ~/下载)
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
#把JDK文件解压到/usr/lib/jvm目录下
解压:
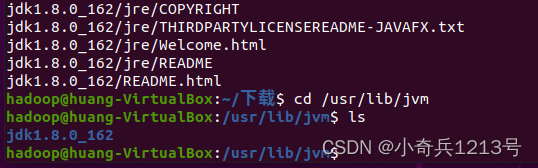
(6)查看 JDK 是否解压到 jvm 文件夹中。
cd /usr/lib/jvm
ls
解压成功:
(7)设置 java 环境变量使其生效,并查看版本号验证是否安装成功。
vim ~/.bashrc
上述命令使用vim编辑器打开了hadoop这个用户的环境变量配置文件.bashrc,请在这个文件的开头位置插入如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version
插入内容:


至此,成功安装了Java环境。下面将进入Hadoop的安装。
(8)下载 hadoop-3.3.2 至 Downloads 目录,并将Hadoop安装至/usr/local/中。
sudo tar -zxvf ~/Downloads/hadoop-3.3.2.tar.gz -C /usr/local #解压到/usr/local中(/下载)
cd /usr/local/
sudo mv ./hadoop-3.3.2/ ./hadoop #将文件夹名修改为hadoop
sudo chown -R hadoop ./hadoop #修改文件权限
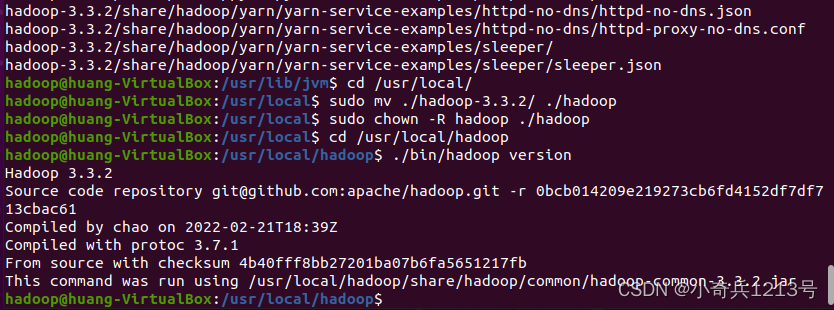
Hadoop解压后即可使用。输入如下命令来检查Hadoop是否可用,成功则会显示Hadoop版本信息:
cd /usr/local/hadoop
./bin/hadoop version
在执行上述命令的过程中,需要注意相对路径与绝对路径:
(9)Hadoop伪分布式配置。对core-site和hdfs-site两个配置文件分别进行修改。
1)cd /usr/local/hadoop/etc/hadoop/
2)vim core-site.xml #使用vim打开配置文件core-site.xml并进行修改
将 core-site.xml 中的配置修改为如下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3)vim hdfs-site.xml #使用vim打开配置文件hdfs-site.xml并进行修改
将 hdfs-site.xml 中的配置修改为如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
将 core-site.xml 中的配置修改为如下内容

将 hdfs-site.xml 中的配置修改为如下内容


(10)对NameNode进行格式化(建议:在执行此步之前可以存快照)
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到“successfully formatted”的提示
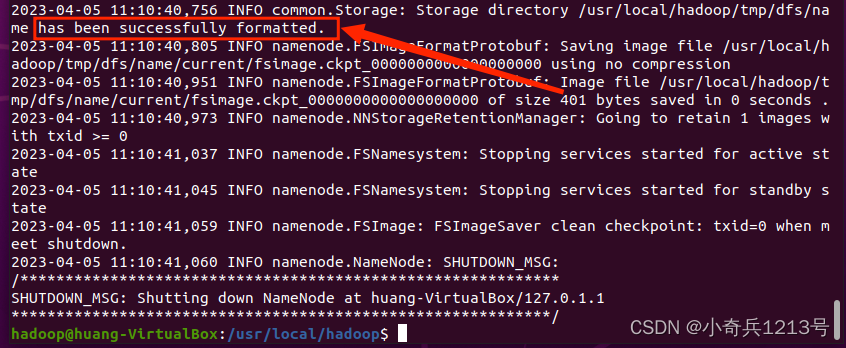
看到“successfully formatted”的提示格式化成功
(11)开启NameNode和DataNode守护进程。
在启动完成后使用 jps 命令来查看是否启动成功。若成功启动则会列出如下进程:NameNode, DataNode和SecondaryNameNode(如果SecondaryNameNode没有启动,请运行./sbin/stop-dfs.sh关闭进程,然后再次尝试启动)。如果没有 NameNode 或 DataNode,那就是配置不成功,请仔细检查之前的步骤,或通过查看启动日志排查原因。
./sbin/start-dfs.sh
jps
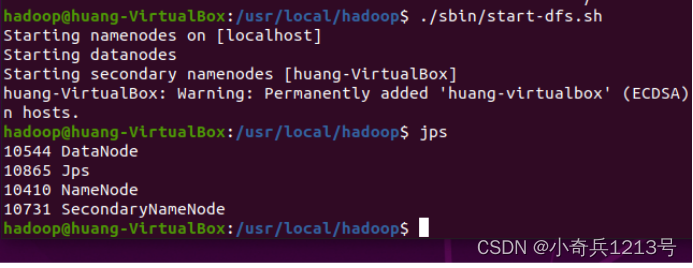
启动成功
若此步运行出错,可以选择通过日志查看出错内容,恢复快照改正错误再重新启动进程。若 datanode 没有启动,可以输入以下语句解决:
cd /usr/local/hadoop
./sbin/stop-dfs.sh
rm -r ./tmp
./bin/hdfs namenode -format
./sbin/start-dfs.sh
(12)安装成功后,在 linux 浏览器中访问 http://localhost:9870 来查看NameNode和DataNode信息,还可以在线查看HDFS中的文件