目录
一:python语法回顾
1.1 print()
1.2 列表与字典
1.3自定义函数与return
1.4火车类(面向对象)
实例化总结:
二:LightGBM 代码精读
2.1导入库
2.2数据准备与参数设置
2.3时间特征函数
2.4优化
2.5训练与预测
三:优化讲解
3.1:
3.2优化建议:
一:python语法回顾
1.1 print()
-
每一个print()会默认换行,若不想换行则:print("",end=""),默认end="\t"
-
单行注释 使用“#”开头,只能写在一行中~
1.2 列表与字典
-
列表是一种序列,他是可变的:容器的唯一作用就是打包、解包、内容传递】
-
列表定义:p2s = []
-
字典是键值对的集合
-
定义一个集合:Dw_set = set() 用add()函数将诗句插入集合中
-
定义一个字典:dw_dict = {"d":"Data","w":"whale"} # key:value 键:值;
-
字典可以利用键去查询对应的值
-
字典的更新:dw_dict["w"] = "whale"
1.3自定义函数与return

回调函数(callback)
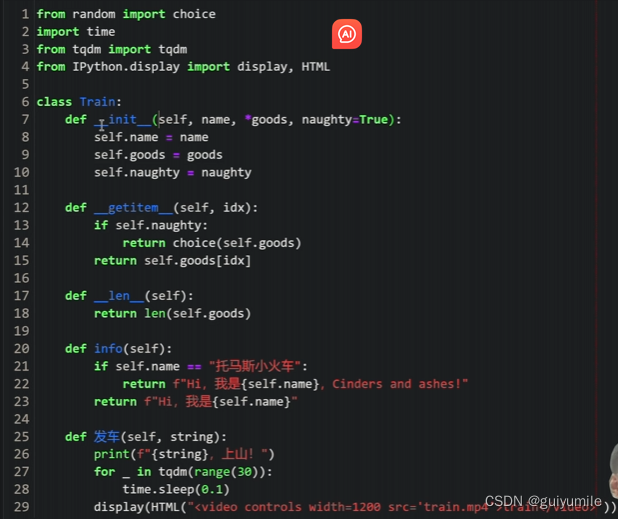
1.4火车类(面向对象)
-
发车函数里,有一个"_"意思是不赋值给任何变量,是一个黑洞
实例化总结:
二:LightGBM 代码精读
2.1导入库
!pip install -U lightgbm
!unzip data/data227148/data.zip
#特别适合处理大规模数据集。
#当处理大规模数据集、需要高效训练和预测速度,并且希望获得较好的性能时,LightGBM通常是一个不错的选择。
# 导入所需的库
import pandas as pd # 读取和处理csv文件的数据
#用于处理数据的工具,常用于数据加载、数据清洗和数据预处理。
import lightgbm as lgb # 机器学习模型 LightGBM
#构建梯度提升树模型,是一种高效的机器学习算法。
from sklearn.metrics import mean_absolute_error # 评分 MAE 的计算函数
#从sklearn.metrics模块中导入评分函数
#平均绝对误差(MAE),是用于回归问题的一个评价指标。
from sklearn.model_selection import train_test_split # 拆分训练集与验证集工具
#用于将数据集拆分为训练集和验证集,以便进行模型训练和评估。
#sklearn.model_selection:对机器学习模型进行参数调优、数据集拆分、交叉验证和性能评估等任务。
#train_test_split函数:将数据集划分为训练集和测试集,并且可以灵活地设置拆分比例和随机种子。
from tqdm import tqdm # 显示循环的进度条工具
#循环过程中显示进度条,方便查看代码执行进度。
2.2数据准备与参数设置
# 数据准备
train_dataset = pd.read_csv("C:\\Users\\86198\\OneDrive\\桌面\\train.csv") # 原始训练数据。
test_dataset = pd.read_csv("C:\\Users\\86198\\OneDrive\\桌面\\test.csv") # 原始测试数据(用于提交)。
submit = pd.DataFrame() # 定义提交的最终数据。
submit["序号"] = test_dataset["序号"] # 对齐测试数据的序号,保持与原始测试数据的一致性。
MAE_scores = dict() # 定义评分项。
# 模型参数设置
pred_labels = list(train_dataset.columns[-34:]) #训练数据集的最后34列是需要预测的目标变量。
train_set, valid_set = train_test_split(train_dataset, test_size=0.2) # 拆分数据集。
# 设定 LightGBM 训练参,查阅参数意义:https://lightgbm.readthedocs.io/en/latest/Parameters.html
lgb_params = {
'boosting_type': 'gbdt', #使用的提升方法,使用梯度提升决策树gbdt。
'objective': 'regression', #优化目标,这里设置为'regression',表示使用回归任务进行优化。
'metric': 'mae', #评估指标,使用MAE,表示使用平均绝对误差作为评估指标。
'min_child_weight': 5, #子节点中样本权重的最小和,用于控制过拟合。
'num_leaves': 2 ** 5, #每棵树上的叶子节点数,影响模型的复杂度。
'lambda_l2': 10, #L2正则化项的权重,用于控制模型的复杂度。
'feature_fraction': 0.8, #随机选择特征的比例,用于防止过拟合。
'bagging_fraction': 0.8, #随机选择数据的比例,用于防止过拟合。
'bagging_freq': 4, # 随机选择数据的频率,用于防止过拟合。
'learning_rate': 0.05, #学习率,控制每次迭代的步长。
'seed': 2023, #随机种子,用于产生随机性,保持结果的可重复性。
'nthread' : 16, #并行线程数,用于加速模型训练。
'verbose' : -1, #控制训练日志输出,-1表示禁用输出。
}
#调整参数是优化模型性能的重要手段
no_info = lgb.callback.log_evaluation(period=-1) # 回调函数no_info:禁用训练日志输出。
#LightGBM通常会输出一些训练过程的信息,通过回调函数可以避免输出这些信息,使得训练过程更简洁。
2.3时间特征函数
# 时间特征函数 特征提取
def time_feature(data: pd.DataFrame, pred_labels: list = None) -> pd.DataFrame:
"""提取数据中的时间特征。
输入:
data: Pandas.DataFrame
需要提取时间特征的数据。
pred_labels: list, 默认值: None
需要预测的标签的列表。如果是测试集,不需要填入。
输出: data: Pandas.DataFrame
提取时间特征后的数据。
"""
# 接收数据集DataFrame和可选参数pred_labels,返回处理后的DataFrame
data = data.copy() # 复制数据,避免后续影响原始数据。
data = data.drop(columns=["序号"]) # 去掉”序号“特征。
data["时间"] = pd.to_datetime(data["时间"]) # 将”时间“特征的文本内容转换为 Pandas 可处理的格式。
data["month"] = data["时间"].dt.month # 添加新特征“month”,代表”当前月份“。
data["day"] = data["时间"].dt.day # 添加新特征“day”,代表”当前日期“。
data["hour"] = data["时间"].dt.hour # 添加新特征“hour”,代表”当前小时“。
data["minute"] = data["时间"].dt.minute # 添加新特征“minute”,代表”当前分钟“。
data["weekofyear"] = data["时间"].dt.isocalendar().week.astype(int) # 添加新特征“weekofyear”,代表”当年第几周“,
# 并转换成 int整数类型,否则 LightGBM 无法处理。
data["dayofyear"] = data["时间"].dt.dayofyear # 添加新特征“dayofyear”,代表”当年第几日“。
data["dayofweek"] = data["时间"].dt.dayofweek # 添加新特征“dayofweek”,代表”当周第几日“。
data["is_weekend"] = data["时间"].dt.dayofweek // 6 # 添加新特征“is_weekend”,代表”是否是周末“,1 代表是周末,0 代表不是周末。
data = data.drop(columns=["时间"]) # LightGBM 无法处理这个特征,它已体现在其他特征中,故丢弃。
2.4优化
# 新加入特征代码展示(不必运行)
# 交叉特征
for i in range(1,18):
train[f'流量{i}/上部温度设定{i}'] = train[f'流量{i}'] / train[f'上部温度设定{i}']
test[f'流量{i}/上部温度设定{i}'] = test[f'流量{i}'] / test[f'上部温度设定{i}']
train[f'流量{i}/下部温度设定{i}'] = train[f'流量{i}'] / train[f'下部温度设定{i}']
test[f'流量{i}/下部温度设定{i}'] = test[f'流量{i}'] / test[f'下部温度设定{i}']
train[f'上部温度设定{i}/下部温度设定{i}'] = train[f'上部温度设定{i}'] / train[f'下部温度设定{i}']
test[f'上部温度设定{i}/下部温度设定{i}'] = test[f'上部温度设定{i}'] / test[f'下部温度设定{i}']
# 历史平移
for i in range(1,18):
train[f'last1_流量{i}'] = train[f'流量{i}'].shift(1)
train[f'last1_上部温度设定{i}'] = train[f'上部温度设定{i}'].shift(1)
train[f'last1_下部温度设定{i}'] = train[f'下部温度设定{i}'].shift(1)
test[f'last1_流量{i}'] = test[f'流量{i}'].shift(1)
test[f'last1_上部温度设定{i}'] = test[f'上部温度设定{i}'].shift(1)
test[f'last1_下部温度设定{i}'] = test[f'下部温度设定{i}'].shift(1)
# 差分特征
for i in range(1,18):
train[f'last1_diff_流量{i}'] = train[f'流量{i}'].diff(1)
train[f'last1_diff_上部温度设定{i}'] = train[f'上部温度设定{i}'].diff(1)
train[f'last1_diff_下部温度设定{i}'] = train[f'下部温度设定{i}'].diff(1)
test[f'last1_diff_流量{i}'] = test[f'流量{i}'].diff(1)
test[f'last1_diff_上部温度设定{i}'] = test[f'上部温度设定{i}'].diff(1)
test[f'last1_diff_下部温度设定{i}'] = test[f'下部温度设定{i}'].diff(1)
# 窗口统计
for i in range(1,18):
train[f'win3_mean_流量{i}'] = (train[f'流量{i}'].shift(1) + train[f'流量{i}'].shift(2) + train[f'流量{i}'].shift(3)) / 3
train[f'win3_mean_上部温度设定{i}'] = (train[f'上部温度设定{i}'].shift(1) + train[f'上部温度设定{i}'].shift(2) + train[f'上部温度设定{i}'].shift(3)) / 3
train[f'win3_mean_下部温度设定{i}'] = (train[f'下部温度设定{i}'].shift(1) + train[f'下部温度设定{i}'].shift(2) + train[f'下部温度设定{i}'].shift(3)) / 3
test[f'win3_mean_流量{i}'] = (test[f'流量{i}'].shift(1) + test[f'流量{i}'].shift(2) + test[f'流量{i}'].shift(3)) / 3
test[f'win3_mean_上部温度设定{i}'] = (test[f'上部温度设定{i}'].shift(1) + test[f'上部温度设定{i}'].shift(2) + test[f'上部温度设定{i}'].shift(3)) / 3
test[f'win3_mean_下部温度设定{i}'] = (test[f'下部温度设定{i}'].shift(1) + test[f'下部温度设定{i}'].shift(2) + test[f'下部温度设定{i}'].shift(3)) / 3
if pred_labels: # 如果提供了 pred_labels 参数,则执行该代码块。
data = data.drop(columns=[*pred_labels]) # 去掉所有待预测的标签。在模型训练时不使用这些标签。
return data # 返回最后处理的数据。
test_features = time_feature(test_dataset) # 处理测试集的时间特征,无需 pred_labels。
2.5训练与预测
# 从所有待预测特征中依次取出标签进行训练与预测。
for pred_label in tqdm(pred_labels):
# print("当前的pred_label是:", pred_label)
train_features = time_feature(train_set, pred_labels=pred_labels) # 处理训练集的时间特征。
# train_features = enhancement(train_features_raw)
# 调用time_feature函数处理训练集train_set的时间特征,并将处理后的训练集数据赋值给train_features
train_labels = train_set[pred_label] # 训练集的标签数据。
# print("当前的train_labels是:", train_labels)
# 获取当前特征标签pred_label在训练集中的真实值,并赋值给train_labels。
train_data = lgb.Dataset(train_features, label=train_labels) # 将训练集转换为 LightGBM 可处理的类型。
# 将train_features和train_labels转换为LightGBM可处理的数据类型,创建训练数据集train_data。
valid_features = time_feature(valid_set, pred_labels=pred_labels) # 处理验证集的时间特征。
# valid_features = enhancement(valid_features_raw)
# 调用time_feature函数处理验证集valid_set的时间特征,并将处理后的验证集数据赋值给valid_features。
valid_labels = valid_set[pred_label] # 验证集的标签数据。
# print("当前的valid_labels是:", valid_labels)
# 获取当前特征标签pred_label在验证集中的真实值,并赋值给valid_labels。
valid_data = lgb.Dataset(valid_features, label=valid_labels) # 将验证集转换为 LightGBM 可处理的类型。
# 训练模型,参数依次为:导入模型设定参数、导入训练集、设定模型迭代次数(5000)、导入验证集、禁止输出日志
model = lgb.train(lgb_params, train_data, 5000, valid_sets=valid_data, callbacks=[no_info])
valid_pred = model.predict(valid_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行验证集预测。
test_pred = model.predict(test_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行测试集预测。
MAE_score = mean_absolute_error(valid_pred, valid_labels) # 计算验证集预测数据与真实数据的 MAE。
MAE_scores[pred_label] = MAE_score # 将对应标签的 MAE 值 存入评分项中。
submit[pred_label] = test_pred # 将测试集预测数据存入最终提交数据中。
submit.to_csv(r"C:\Users\86198\OneDrive\桌面\submit_result.csv", index=False) # 保存最后的预测结果到 submit_result.csv
# 保存文件并查看结果
submit.to_csv(r"C:\Users\86198\OneDrive\桌面\submit_result.csv", index=False) # 保存最后的预测结果到 submit_result.csv。
print(MAE_scores) # 查看各项的 MAE 值。三:优化讲解
3.1:
具体地,我们可以尝试提取更多特征改善最终结果,这也是数据挖掘比赛中的主要优化方向,很多情况下决定着最终的成绩。
这里主要构建了交叉特征、历史平移特征、差分特征、和窗口统计特征;每种特征都是有理可据的,具体说明如下:
(1)交叉特征:主要提取流量、上部温度设定、下部温度设定之间的关系;
(2)历史平移特征:通过历史平移获取上个阶段的信息;
(3)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(4)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
3.2优化建议:
1、过拟合现象
在代码运行的时候可以将callbacks=[no_info]去除,以查看模型运行的日志,运行结束后也可以利用代码print(MAE_scores)来打印出最终的损失,观察不难看出,模型会在一定时间后进入过拟合,因此可以尝试以一些措施来缓解这种现象。
- 利用lightgbm自带的early_stopping_rounds参数。
- 采用多折验证的方式扩大数据量,使得模型泛化能力增强。
2、 参数设定
此次基线没有做精确的调参处理,因此可以调参的范围还是挺大的,常用的搜索参数策略有两种:
-
网格搜索(Grid Search):这是一种传统的参数调整方法,它会测试指定参数的所有可能组合来找出最佳参数。但是,当参数空间较大时,这种方法可能会消耗大量计算资源和时间。
-
随机搜索(Random Search):与网格搜索相比,随机搜索不会测试所有的参数组合,而是在参数空间中随机选择一定数量的参数组合进行测试。尽管随机搜索可能无法找到最优的参数组合,但在计算资源有限的情况下,它是一个有效的选择。
3、 模型设定
我们此次基线采用的是LightGBM,我们也可以试试XGBoost, Adaboost, Catboost等等传统的模型,并且也可以使用深度学习的方法构建循环神经网络来处理此次任务,因为本质是一个时序任务,在采用机器学习的同时也可以保存模型的参数配置,尝试进行模型集成的训练。
4、 特征
在特征选择方面,目前给出的特征仅仅是单独对时间处理,与对流量\上\下\部温度设定进行处理,并未结合时间与其他特征的关系,可以尝试自己构建合理的新特征。
5、 后处理
对已经给出的csv文件仍然可以分析其趋势,抓住评估的关键来调整文件内容使得结果更加精确。
6、 迭代步数 目前设置的迭代步数为200轮,其实这对于某些预测数据来说是不够的,可以尝试自己增大迭代步数
baseline进行修改优化后并跑通,结果可观如下:

调整参数后:
![]()
参考文章:
datawhale暑期夏令营:datawhale开源项目