目录
set概念
set基本使用
map概念
map的使用
map统计次数
operator[]
operator[]底层如何实现?
set和map迭代器封装
红黑树迭代器基本结构
operator++
operator--
operator[]
源代码链接
map、set底层都使用平衡搜索树(即红黑树),容器中的元素是一个有序的序列。
数据结构【红黑树模拟实现】_北方留意尘的博客-CSDN博客
set概念
1.set和map都是关联式容器:
与序列式容器(vector、list、deque)不同的是,关联式容器也是用来存储数据的,其里面存储的是结构的键值对(键值对是用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息,例如找到中文即可一一对应英文),在数据检索时比序列式容器效率更高。
2.在set中,元素的value就是key,是一个key模型(类型为模板参数T),每个value必须是唯一的(默认去重)。 set中的元素不能在容器中修改(否则会破坏树的结构),但是可以从容器中插入或删除它们。set是去重+排序(按照中序遍历是有序的)
3.模板中传compare仿函数,是方便控制“比较”规则,less默认用T对象本身比较大小(调用T的operator<),
如果T是自定义类型,默认不支持比较大小;或者需要指针解应用里面的内容来进行比较,可以自己写仿函数
set基本使用
set.insert

在set中插入元素x,实际插入的是<x, x>,构成的键值对,如果插入成功,返回pair中<该元素在set中的位置,true>;如果插入失败,说明x在set中已经存在,返回<x在set中的位置,false>
set.erase
直接使用erase删除不存在的值,不会报错
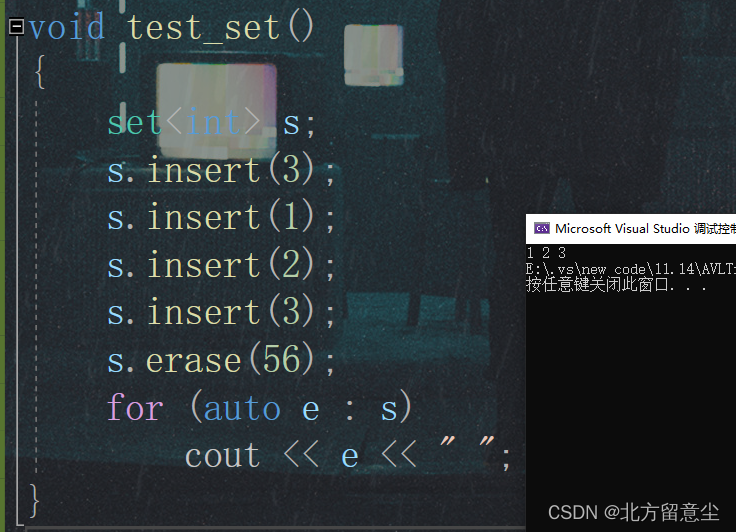
erase配合set中find来删除不存在的值,会导致程序崩溃
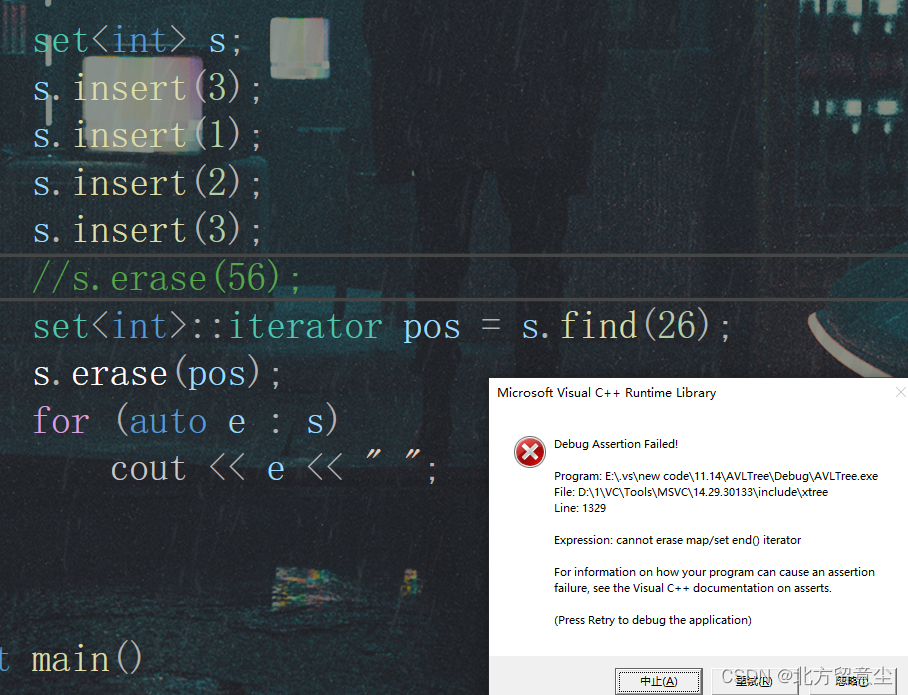
原因在于find找不到对应值,返回end位置,erase删除了end位置。

正确做法是应该判断pos != end()再进行删除
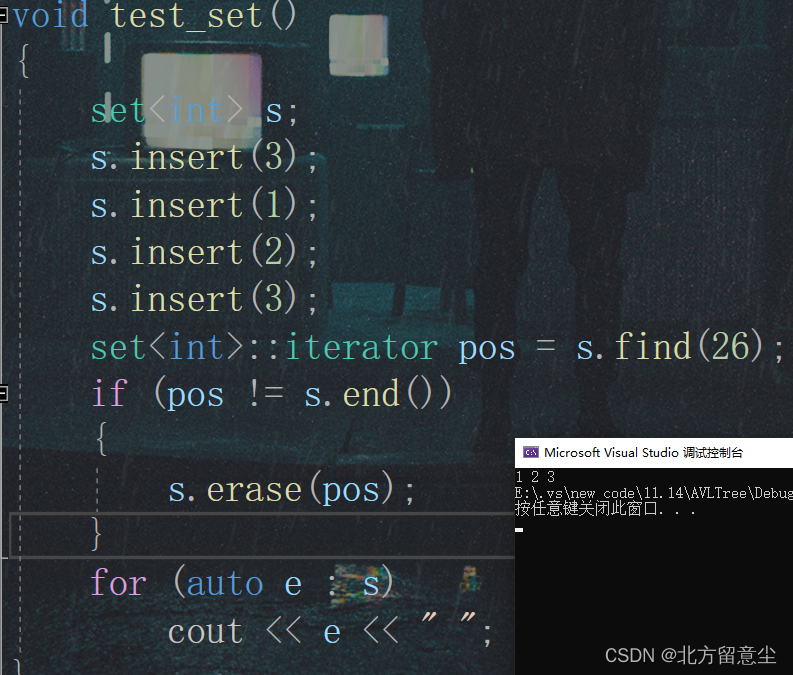
set和multiset的区别在于:
multiset中的find查找的是所有重复元素,返回的是中序的第一个重复元素;
multiset直接erase删除的是所有重复元素,multiset中的find+erase是删除一个元素
count
count并不是为set准备的,而是为multiset(允许键值冗余)准备的,用于查找重复元素个数
但是实际也可以用count查找在不在,返回bool
lower_bound/upper_bound
lower_bound返回的是大于等于这个值的位置
upper_bound是开区间,返回大于这个值的位置(给60返回70)
void test_set1()
{
std::set<int> myset;
std::set<int>::iterator itlow, itup;
for (int i = 1; i < 10; i++)
myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90
itlow = myset.lower_bound(35); // ^
itup = myset.upper_bound(60);
cout << *itlow <<" " << *itup << endl;//40 70
}equal_range:是一种二分查找算法,试图在已排序的[first,last)中寻找value
equal_range结构是pair键值对,给的是一段范围区间
左区间存在pair.first中,右区间存在pair.second中,区间范围是 first <= val < second (左闭右开)
void test_set2()
{
set<int> myset;
for (int i = 1; i <= 5; i++) myset.insert(i * 10);// myset: 10 20 30 40 50
pair<set<int>::const_iterator, set<int>::const_iterator> ret;
ret = myset.equal_range(30);
cout << "the lower bound points to: " << *ret.first << '\n';//30
cout << "the upper bound points to: " << *ret.second << '\n';//40
}map概念
1.map按照key来比较大小和存储元素,map是由键值key和值value组合,map中的元素总是按照键值key进行比较排序的
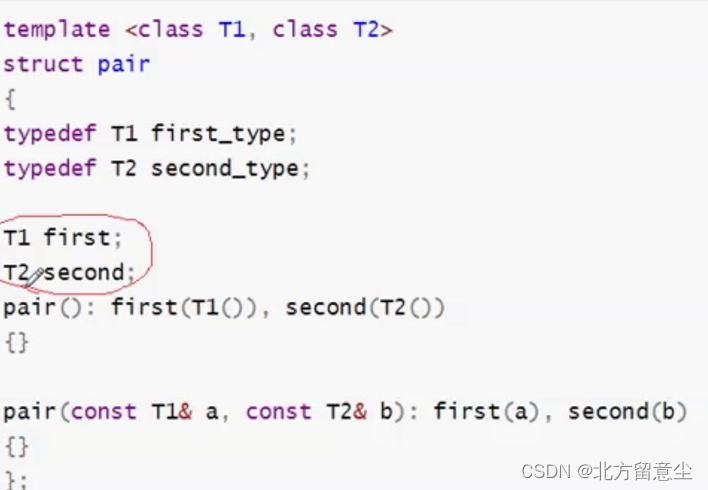
2.键值key用于排序和唯一标识元素,而值value中存储与此键值key关联的内容。key与value通过结构体pair绑定在一起

3. map不允许键值冗余,插入是根据key来判断,value改变而key不改变也无法插入,跟value无关
4. map中的key是唯一的,并且不能修改
5.map支持下标访问符,即在[]中放入key,就可以找到与key对应的value
6.仿函数Compare: map中的元素是按照key来比较的,缺省情况下按照小于比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下用函数指针或者仿函数来传递)
map的使用
map.insert

在map中插入键值对val,注意val是一个键值对,返回值也是键值对:返回值的iterator代表新插入元素的位置/已经存在元素的位置,bool代表是否插入成功
map.insert并不是直接insert两个值
void test_map()
{
map<string, string> dict;
dict.insert("左边","left");//错误写法
}而是要求给一个pair,而pair有对应的构造函数
void test_map()
{
map<string, string> dict;
//第一种写法,麻烦
pair<string, string> dt("left", "左边");
dict.insert(dt);
//第二种写法
dict.insert(pair<string, string>("right", "右边"));//隐式类型转换+匿名对象构造
}我们也可以使用make_pair函数,自动帮我们推导模板参数,不需要显示传参
void test_map()
{
map<string, string> dict;
//pair<string, string> dt("left", "左边");
dict.insert(make_pair("left","左边"));
}
迭代器
直接使用*it拿pair,会提示pair不支持流插入
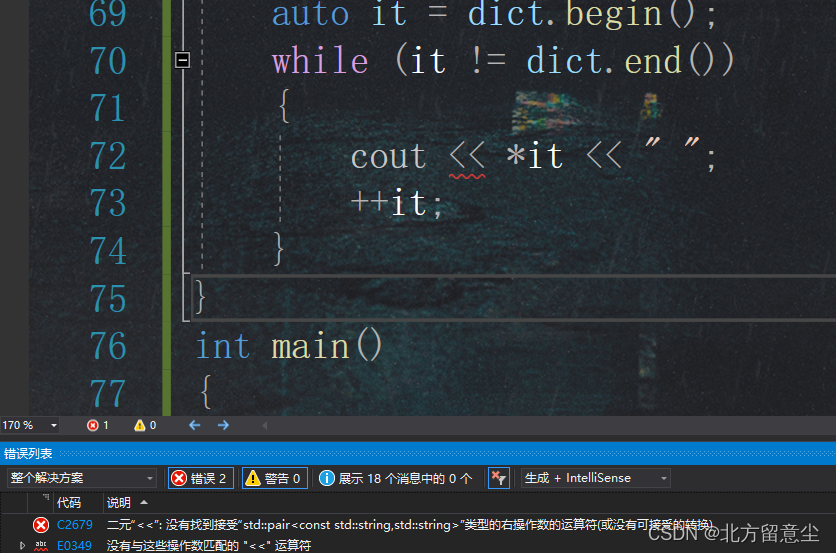
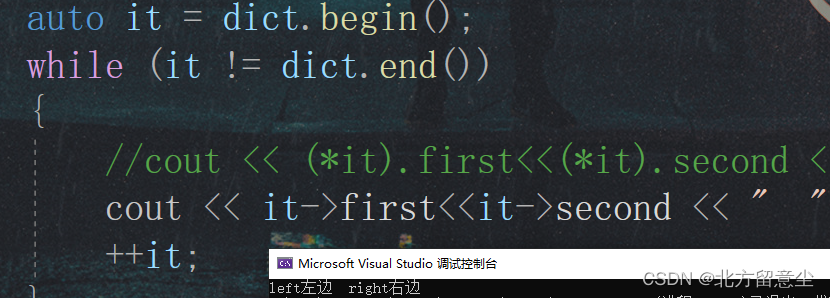
为了可以同时拿到key和value才设置成结构体,*it拿到的是pair,拿key对应it->first,拿value对应it->second(结构体时使用->)
void test_map()
{
map<string, string> dict;
//pair<string, string> dt("left", "左边");
dict.insert(make_pair("left","左边"));
dict.insert(pair<string, string>("right", "右边"));//隐式类型转换+匿名对象
dict.insert(pair<string, string>("right", "xx"));//隐式类型转换+匿名对象
auto it = dict.begin();
while (it != dict.end())
{
//cout << (*it).first<<(*it).second << " ";
cout << it->first<<it->second << " ";
++it;
}
}
map统计次数
void test_map1()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
map<string, int> CountMap;
for (auto& s : arr)
{
map<string,int>::iterator it = CountMap.find(s);
if (it != CountMap.end())
{
it->second++;//如果map中存在,则++次数
}
else
{
CountMap.insert(make_pair(s, 1));
//如果map中不存在,新增对应水果名称,次数为1
}
}
auto it = CountMap.begin();
while (it != CountMap.end())
{
//cout << (*it).first<<(*it).second << " ";
cout << it->first << it->second <<endl;
++it;
}
}operator[]
operator[]介绍:如果 k 与容器中任何元素的键不匹配,则该函数将插入具有该键的新元素,并返回对其映射值的引用。请注意,这始终将容器大小增加 1,如果没有为元素分配映射值,映射元素使用默认构造函数构造。
探讨[]
void test_map2()
{
map<string, string> dict;
dict.insert(make_pair("left", "左边"));
dict["left"];
dict["right"];
dict["left"] = "right";
}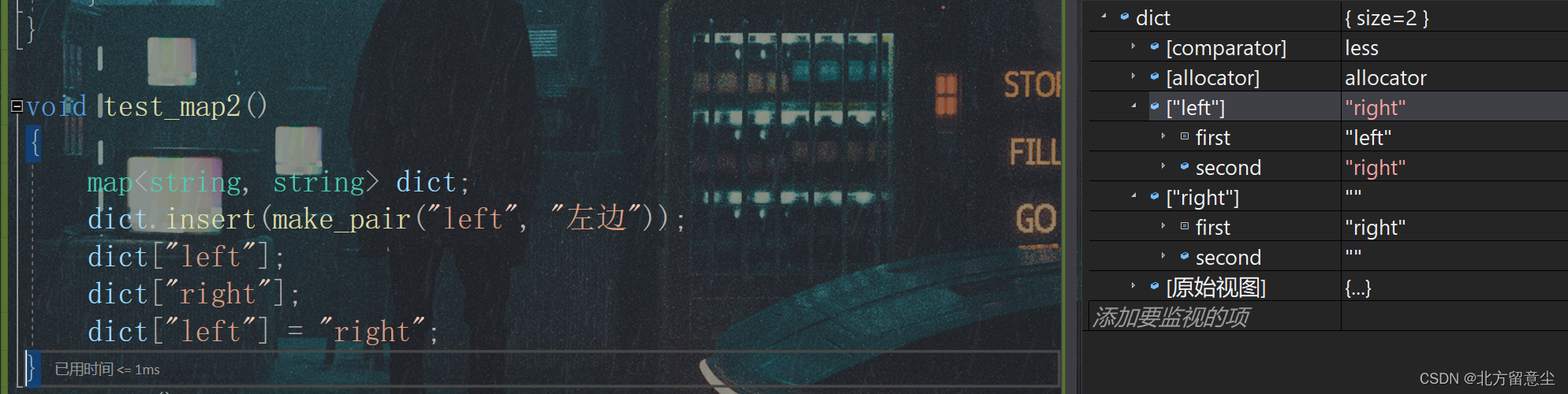
[]有以下功能:
1.如果map中有存在的key,返回value引用,可以用作查找value、修改value
2.如果map中不存在key,会插入新元素pair<key,value()>,调用其value默认构造函数,返回value引用,可以充当插入+修改
operator[]底层如何实现?
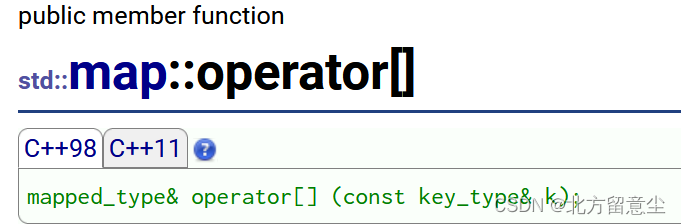
mapped_type& operator[] (const key_type& k)
{
return (*((this->insert(make_pair(k,mapped_type()))).first)).second;
}以下解释来自网站:
https://cplusplus.com/reference/map/map/insert/
解释
insert返回值是pair<iterator,bool>
first首先设置一个迭代器,
如果插入key不在map中,将该迭代器指向新插入的元素。则将对中的第二个元素pair设置为true。pair(new_iterator,true);
如果已存在key,将该迭代器指向跟key相等的元素。则将其设置为false。pair(key_iterator,false)
所以insert插入失败还充当一个查找的功能
pair<iterator,bool> insert (const value_type& val);按照上面说法,insert和operator[]有很多重复功能,模拟实现operator[]直接调用insert
mapped_type& operator[] (const key_type& key)
{
pair<iterator,bool> ret = insert(make_pair<key,V()>);
return ret.first->second;
}解释:构造一个pair,调用insert函数,如果key在,ret.first就是key位置的迭代器,默认构造函数没起作用,ret.first就是取pair迭代器位置,pair.second就是取对应的value
如果key不在,新建一个key位置迭代器元素,返回新插入元素,取默认构造函数。
利用operator[]实现统计次数
void test_map1()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
map<string, int> CountMap;
for (auto& s : arr)
{
CountMap[s]++;
}
auto it = CountMap.begin();
while (it != CountMap.end())
{
//cout << (*it).first<<(*it).second << " ";
cout << it->first << it->second <<endl;
++it;
}
} 
第一次对象不在map中,插入+修改,使用pair<key,int()>;第二次对象在map中,返回value值++
set和map迭代器封装
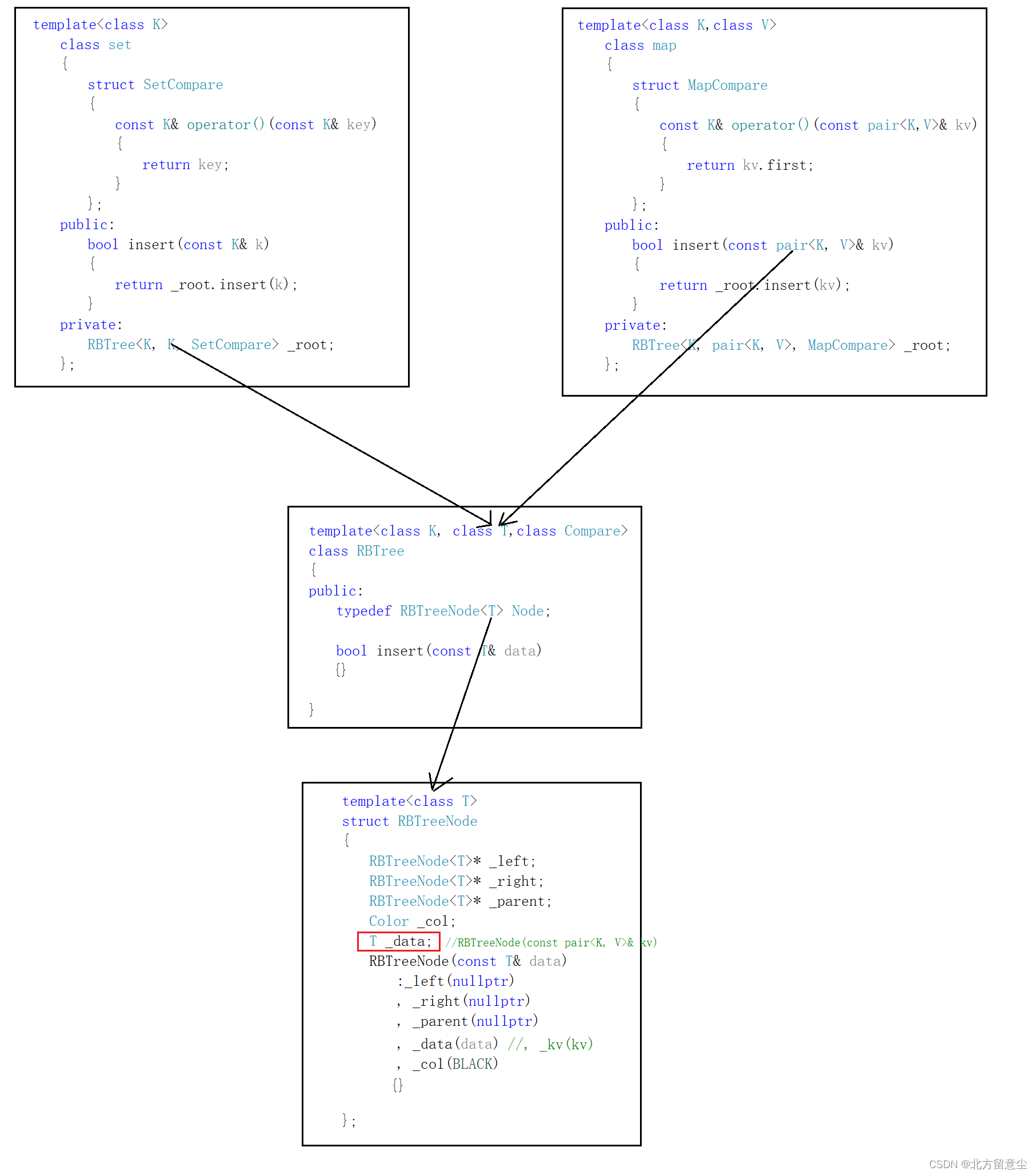
set和map的底层共用同一颗红黑树,通过传入不同实例化参数来实现(体现复用性)
底层的RBTree用一个模板接收,上层的set和map通过传入不同的value(set传K,map传键值对pair<K,V>)给RBTree实例化不同的树,其中RBTreeNode节点中只包含了_data,所以在insert等操作时,需要配合仿函数使用(重载)
迭代器begin()与end()代表的是一段前闭后开的区间,而对红黑树进行中序遍历, 可以得到一个有序的序列
因此:begin()可以放在红黑树中最小节点(即最左侧节点)的位置,end()放在最大节点(最右侧节点)的下一个位置
红黑树迭代器基本结构
template<class T,class Ref,class Ptr>
struct __IteratorRBTree
{
typedef RBTreeNode<T> Node;
typedef __IteratorRBTree<T, Ref, Ptr> it;
Node* _node;
__IteratorRBTree(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const it& r) const
{
return _node != r._node;//节点指针比较
}
bool operator==(const it& r) const
{
return _node == r._node;//节点指针比较
}
};operator++
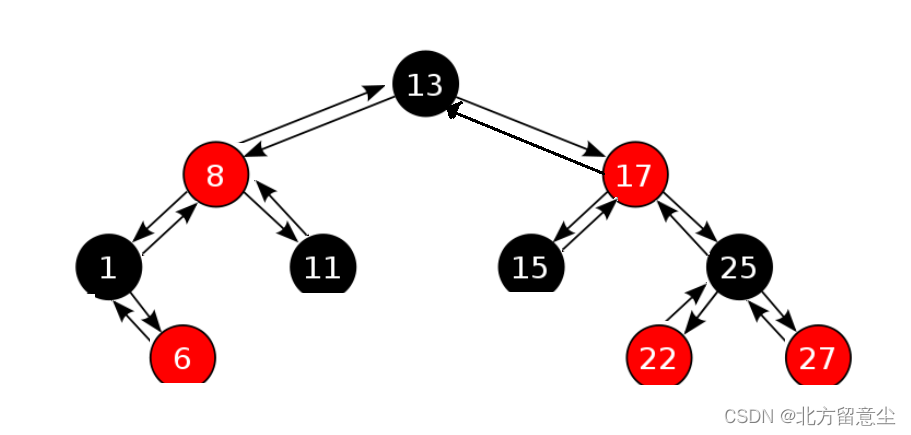
如果在迭代器中嵌套栈辅助完成,消耗巨大。
由于三岔链可以找parent,operator++中序遍历是有序的,我们可以总结出规律:
1.首先需要找到最左节点(为中序遍历的第一个节点),例如此时找到节点1,1所在节点代表其左节点已经全部遍历完,此时只需要看1的右子树,就要分情况讨论:1的右子树不为空,++就是找右子树中序遍历的最左节点,此时为6。
2.此时6左右子树都为空,但是6是1的右子树,代表1也早就访问结束(中序决定),此时需要访问1的parent8。此时++找父亲的parent,总结为++找孩子不是父亲右的那个祖先(持续寻找)
3.找到最后一个节点27后,继续++会沿着三岔链找到13的parent,此时parent为nullptr
it& operator++()
{
if (_node->_right)
{
Node* left = _node->_right;
while (left->_left)//右子树最左节点
{
left = left->_left;
}
_node = left;
}
else//找孩子不是父亲右的那个祖先(持续寻找)
{
Node* parent = _node->_parent;
Node* cur = _node;
if(_node == parent->_left)
{
_node = _node->_parent;
}
else
{
while (parent && parent->_right == cur)
{
parent = parent->_parent;
cur = cur->_parent;
}
_node = parent;
}
}
return *this;
}
operator--
operator--和operator++反过来:左子树 <-- 根 <--右子树,关注点在于左子树是否为空
1.左子树不为空,访问左子树最右节点
2.左子树为空,找孩子不是父亲左的那个祖先
it& operator--()
{
if ( _node->_left)//不需要判断_node是否为空,如果传空begin构造空迭代器
{
Node* right = _node->_left;
while (right->_right)
{
right = right->_right;
}
_node = right;
}
else//左子树为空
{
Node* parent = _node->_parent;
Node* cur = _node;
while (parent && parent->_left == cur)
{
parent = parent->_parent;
cur = cur->_parent;
}
_node = parent;
}
return *this;
}operator[]
operator[]底层用insert实现,返回值为pair<iterator,bool>
插入时数据存在,insert返回所在迭代器位置,返回false
插入时数据不存在,insert返回新插入位置,返回true
K/V模型才有[],还没实例化时无法确定是否为K/V,因此需要在map封装[]
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _root.insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> tmp = insert(make_pair(key, V()));
//传V缺省值,如果是int为0,自定义类型调默认构造函数
return tmp.first->second;//首先取pair的迭代器iterator,再取K/V的second
}源代码链接
刷题+代码: 刷题+代码 - Gitee.com





![[附源码]JAVA毕业设计-学生宿舍故障报修管理信息系统-(系统+LW)](https://img-blog.csdnimg.cn/f879e01d37e84324ae73ca06662f2d43.png)