1、序列化的概念:
序列:就是字符串。
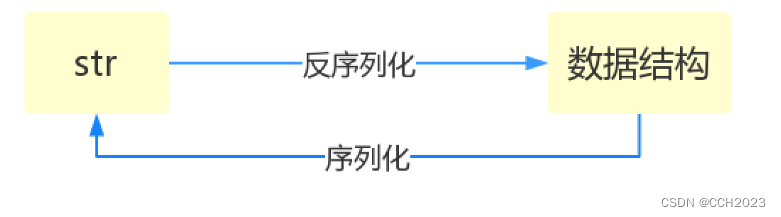
序列化:将原本的字典、列表等内容转换成一个字符串数据类型的过程就叫做序列化。
反序列化:从字符串到数据类型的过程。
2、序列化的目的:
1、以某种存储形式使自定义的数据持久化;
2、将对象从一个地方传递到另外一个地方;
3、使程序更具维护性;
3、Json模块和Pickle模块:
Json:和别人数据交互的时候使用。Json就是一种通话的序列化格式,是一个沟通的桥梁。只有很少的一部分数据类型可以通过Json转成字符串类型。
Pickle:所有的Python中的数据类型都可以转化成字符串形式。Pickle序列化的内容只有Python能理解。且部分反序列化依赖代码。
Shelve: 序列化句柄,使用句柄直接操作,非常方便。
4、Json的dumps和loads,直接操作内存中的数据类型:
数字、字符串、列表、字典、元组:这几种数据类似可以序列化。Json只能转化很少的数据类型。
import json
# dumps 序列化方法
dic = {'k1': 'v1'}
print(type(dic))
str_d = json.dumps(dic)
print(type(str_d), str_d)
# loads 反序列化方法
dic_d = json.loads(str_d)
print(type(dic_d), dic_d)输出结果:

说明,序列化的字符串,在大括号里面的都是双引号,这是一个特点。
5、Json dump和load是文件中写和读:
import json
dic = {1: 'a', 2: 'b'}
# json.dump 序列化数据到文件中
f = open('log', 'w', encoding='utf-8')
json.dump(dic, f)
f.close()
# json.load 从数据文件执行反序列化
f = open('log', 'r', encoding='utf-8')
res = json.load(f)
print(type(res), res)
f.close()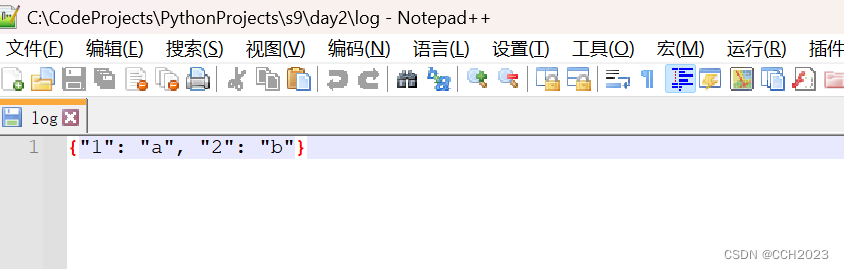
log文件,我通过notepad++工具打开可查看到其中的内容,在Pycharm中还查看不了。
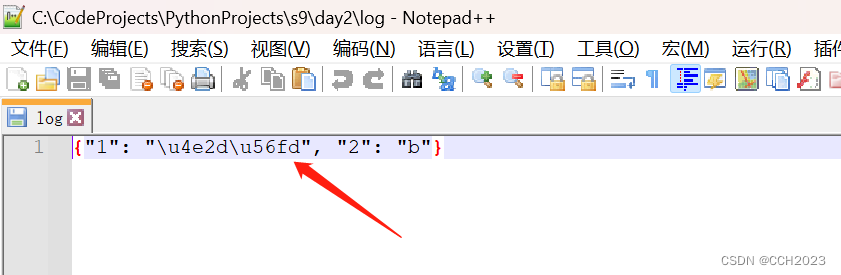
6、如果字典中含有中文字符:
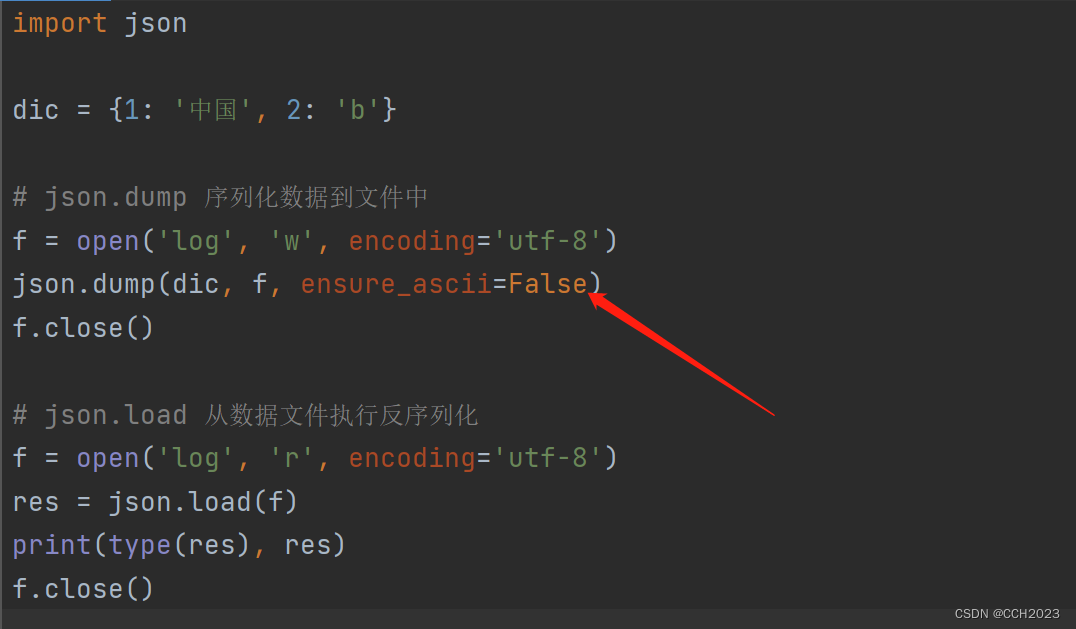
import json
dic = {1: '中国', 2: 'b'}
# json.dump 序列化数据到文件中
f = open('log', 'w', encoding='utf-8')
json.dump(dic, f)
f.close()
# json.load 从数据文件执行反序列化
f = open('log', 'r', encoding='utf-8')
res = json.load(f)
print(type(res), res)
f.close()log中的文件变成了bytes:
我们将代码进行修改:
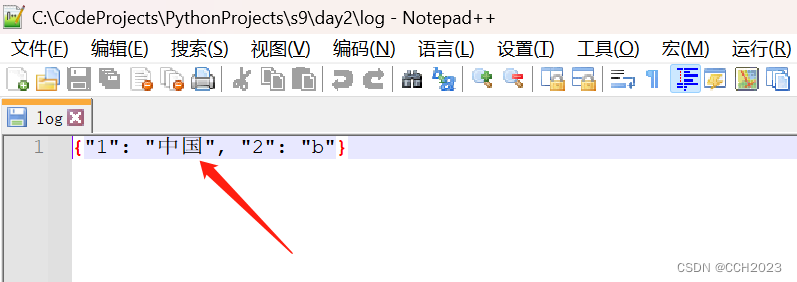
7、再进一步:
import json
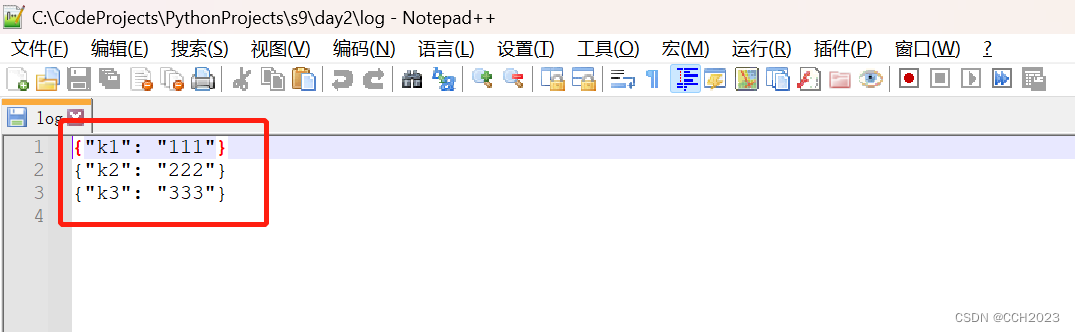
lst = [{'k1': '111'}, {'k2': '222'}, {'k3': '333'}]
f = open('log', 'w', encoding='utf-8')
for dic in lst:
str_d = json.dumps(dic) # 在内存中对每个字典进行序列化
f.write(str_d + '\n') # 然后再将序列化的字符串末尾添加\n
f.close()文件中将显示多行信息:
import json
l_dest = []
f = open('log')
for line in f:
dic = json.loads(line.strip())
l_dest.append(dic)
f.close()
print(l_dest)结果:

8、pickle模块:提供了四个功能:dump、dumps(序列化、存)、loads(反序列化、读)可以把Python中的任意的数据类型序列化。
1)pickle dumps和loads:直接内存操作:
import pickle
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
str_dic = pickle.dumps(dic) # 显示bytes类型
print(str_dic)
dic2 = pickle.loads(str_dic)
print(dic2) # 字典类型结果:

2) pickle dump和load:跟文件操作有关。
import pickle
import time
struct_time = time.localtime(1670000000)
print(struct_time)
f = open('pickle_file', 'wb') # wb
pickle.dump(struct_time, f)
f.close()
f = open('pickle_file', 'rb') # rb
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
f.close()结果:

再进一步:分步dump和load:json是做不到这个功能的。
import pickle
import time
struct_time1 = time.localtime(1600000000)
struct_time2 = time.localtime(1670000000)
f = open('pickle_file', 'wb') # wb
pickle.dump(struct_time1, f)
pickle.dump(struct_time2, f)
f.close()
f = open('pickle_file', 'rb') # rb
struct_time1 = pickle.load(f)
struct_time2 = pickle.load(f)
print(struct_time1.tm_year)
print(struct_time2.tm_year)
f.close()总结:
1)可以序列化任意数据类型;
2)文件读取模式要加b;
3)可以分步dump和load;
4)pickle_file保存的信息都是乱码;






![[附源码]计算机毕业设计惠农微信小程序论文Springboot程序](https://img-blog.csdnimg.cn/a809023d3d2a43acaba109457b4dd941.png)