引言
书接上篇 何为Spring Batch?怎么玩? ,前面普及了一下Spring Batch 相关介绍,本篇来一个helloword,简单试一下Spring Batch 怎么玩
批量处理流程
开始前,先了解一下Spring Batch程序运行大纲:
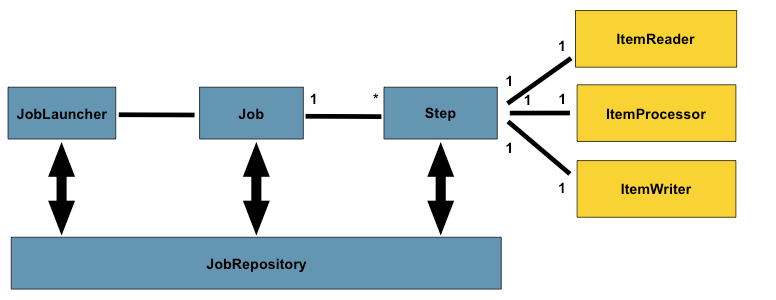
JobLauncher:作业调度器,作业启动主要入口。
Job:作业,需要执行的任务逻辑,
Step:作业步骤,一个Job作业由1个或者多个Step组成,完成所有Step操作,一个完整Job才算执行结束。
ItemReader:Step步骤执行过程中数据输入。可以从数据源(文件系统,数据库,队列等)中读取Item(数据记录)。
ItemWriter:Step步骤执行过程中数据输出,将Item(数据记录)写入数据源(文件系统,数据库,队列等)。
ItemProcessor:Item数据加工逻辑(输入),比如:数据清洗,数据转换,数据过滤,数据校验等
JobRepository: 保存Job或者检索Job的信息。SpringBatch需要持久化Job(可以选择数据库/内存),JobRepository就是持久化的接口
入门案例-H2版(内存)
需求:打印一个hello spring batch!不带读/写/处理
步骤1:导入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--内存版-->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>其中的h2是一个嵌入式内存数据库,后续可以使用MySQL替换
步骤2:编写启动类与开启批处理
@SpringBootApplication
@EnableBatchProcessing
public class HelloJob {
public static void main(String[] args) {
SpringApplication.run(HelloJob.class, args);
}
}步骤3:构建操作任务:Tasklet
//任务-step执行逻辑由tasklet完成
@Bean
public Tasklet tasklet(){
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("Hello SpringBatch....");
return RepeatStatus.FINISHED;
}
};
}步骤4:定义作业步骤
//step构造器工厂
@Autowired
private StepBuilderFactory stepBuilderFactory;
//作业步骤-不带读/写/处理
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.tasklet(tasklet())
.build();
}步骤5:定义批处理作业
//job构造器工厂
@Autowired
private JobBuilderFactory jobBuilderFactory;
//定义作业
@Bean
public Job job(){
return jobBuilderFactory.get("hello-job")
.start(step1())
.build();
}步骤6:完整代码
package com.langfeiyes.batch._01_hello;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableBatchProcessing
public class HelloJob {
//job构造器工厂
@Autowired
private JobBuilderFactory jobBuilderFactory;
//step构造器工厂
@Autowired
private StepBuilderFactory stepBuilderFactory;
//任务-step执行逻辑由tasklet完成
@Bean
public Tasklet tasklet(){
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("Hello SpringBatch....");
return RepeatStatus.FINISHED;
}
};
}
//作业步骤-不带读/写/处理
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.tasklet(tasklet())
.build();
}
//定义作业
@Bean
public Job job(){
return jobBuilderFactory.get("hello-job")
.start(step1())
.build();
}
public static void main(String[] args) {
SpringApplication.run(HelloJob.class, args);
}
}
步骤7:右键执行main方法观察结果
步骤8:分析
例子是一个简单的SpringBatch 入门案例,使用了最简单的一种步骤处理模型:Tasklet模型,step1中没有带上读/写/处理逻辑,只有简单打印操作,后续随学习深入,我们再讲解更复杂化模型。
入门案例-MySQL版
MySQL跟上面的h2一样,区别在连接数据库不一致。
步骤1:在H2版本基础上导入MySQL依赖
<!-- <dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency> -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>步骤2:配置数据库四要素与初始化SQL脚本
spring:
datasource:
username: root
password: admin
url: jdbc:mysql://127.0.0.1:3306/springbatch?serverTimezone=GMT%2B8&useSSL=false&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始化数据库,文件在依赖jar包中
sql:
init:
schema-locations: classpath:org/springframework/batch/core/schema-mysql.sql
mode: always
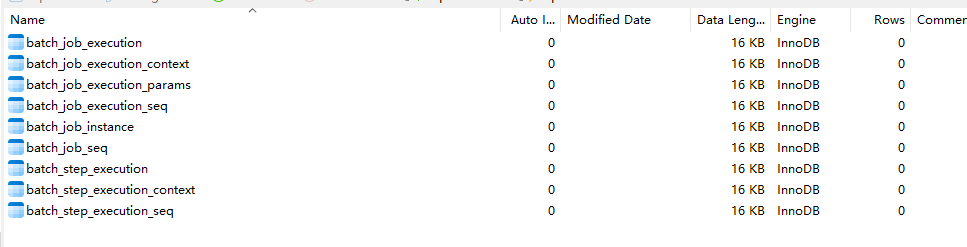
#mode: never这里要注意, sql.init.model 第一次启动为always, 后面启动需要改为never,否则每次执行SQL都会异常。
第一次启动会自动执行指定的脚本,后续不需要再初始化
步骤3:代码、测试
跟H2版一样。
到这,Spring Batch 入门案例就结束~
![[附源码]计算机毕业设计惠农微信小程序论文Springboot程序](https://img-blog.csdnimg.cn/a809023d3d2a43acaba109457b4dd941.png)