原文链接:https://arxiv.org/abs/2307.10249
1. 引言
目前的一些雷达-相机融合3D目标检测方法进行实例级的融合,从相机图像生成3D提案,并与雷达点云相关联以修正提案。但这种方法没有在最初阶段使用雷达,依赖于相机3D检测器;且融合发生在图像视图,多模态数据关联可能因为雷达点云的高度模糊性而不精确。
本文提出雷达-相机多级融合(RCM-Fusion)方法,在BEV融合特征。首先会进行特征级融合,使用雷达数据指导图像特征变换到BEV下,并生成3D边界框。然后使用基于网格点的提案特征融合,进行实例级融合以修正提案,
对于特征级融合,本文设计了雷达指导的BEV查询,使用雷达的位置信息将图像特征转换到BEV。然后雷达-相机门控模块加权聚合多模态BEV特征。这种自适应特征聚合模块被整合到Transformer中,解码密集的BEV查询特征。对于实例级融合,提出提案感知的雷达注意力模块,考虑雷达点与3D提案的相关性,获取雷达点特征。
2. 相关工作
2.3. 两阶段3D目标检测
基于激光雷达的两阶段3D目标检测器利用提案框内的激光雷达点云来修正提案。可分两种方法:第一种方法将与提案相关的一些点视为关键点,使用PointNet++基于关键点提取特征。第二种方法定义一组虚拟点,称为网格点,并基于网格点提取特征。本文认为考虑提案内的点云分布是两阶段检测器的关键部分,使用网格点方法根据点云分布生成关键点。
3. 方法
网络结构如下图所示。
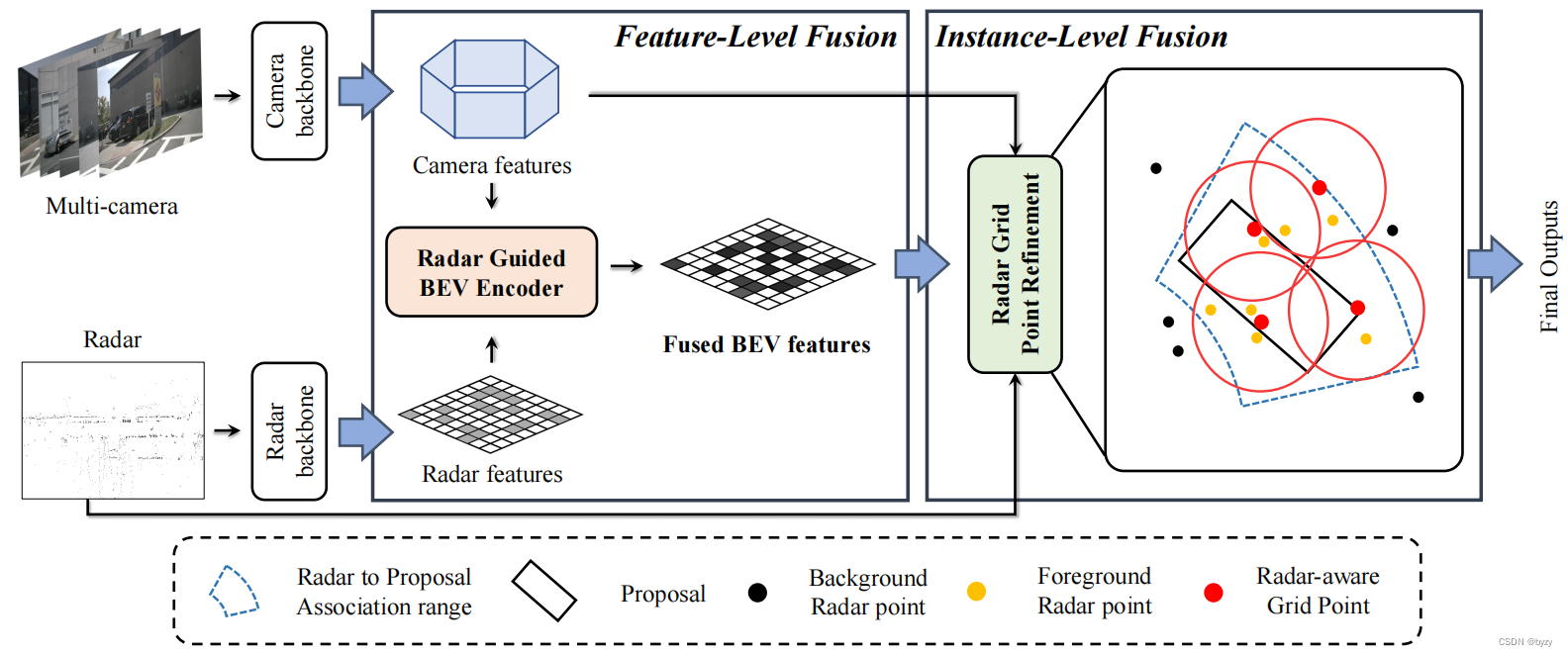
3.1. 雷达和图像主干
使用ResNet-101和FPN提取多尺度图像特征 F C F_C FC;使用PointPillars提取雷达BEV特征图 F R ∈ R H × W × C F_R\in\mathbb{R}^{H\times W\times C} FR∈RH×W×C。
3.2. 雷达指导的BEV编码器
首先使用
F
R
F_R
FR生成雷达指导的BEV查询(RGBQ),该查询包含雷达的位置信息。然后,使用RGBQ将多模态特征转换为增强BEV特征。最后,雷达-相机门控(RCG)根据各模态的信息量,进行多模态的门控聚合。
雷达指导的BEV查询:本文利用雷达的位置信息,使用
F
R
F_R
FR生成BEV查询(RGBQ)
Q
R
G
∈
R
H
×
W
×
C
Q^{RG}\in\mathbb{R}^{H\times W\times C}
QRG∈RH×W×C。具体来说,将
F
R
F_R
FR与BEV查询
Q
∈
R
H
×
W
×
C
Q\in\mathbb{R}^{H\times W\times C}
Q∈RH×W×C拼接后通过可变形注意力(DeformAttn)模块生成
Q
R
G
Q^{RG}
QRG:
Q
p
R
G
=
∑
V
∈
{
Q
,
F
R
}
DeformAttn
(
Q
p
,
p
,
V
)
Q_p^{RG}=\sum_{V\in\{Q,F_R\}}\text{DeformAttn}(Q_p,p,V)
QpRG=V∈{Q,FR}∑DeformAttn(Qp,p,V)其中
Q
p
R
G
Q_p^{RG}
QpRG和
Q
p
Q_p
Qp分别表示BEV像素
p
=
(
x
,
y
)
p=(x,y)
p=(x,y)处的查询。然后
Q
p
R
G
Q_p^{RG}
QpRG通过空间交叉注意力(SCA)块生成修正的相机BEV特征
B
C
B_C
BC和修正的雷达BEV特征
B
R
B_R
BR:
B
C
=
SCA
C
(
Q
p
R
G
,
F
C
)
B
R
=
SCA
R
(
Q
p
R
G
,
F
R
)
B_C=\text{SCA}_C(Q_p^{RG},F_C)\\B_R=\text{SCA}_R(Q_p^{RG},F_R)
BC=SCAC(QpRG,FC)BR=SCAR(QpRG,FR)其中SCA是将
Q
p
R
G
Q_p^{RG}
QpRG投影到模态特征然后进行可变形交叉注意力的操作。
雷达-相机门控:通过加权组合融合
B
C
B_C
BC与
B
R
B_R
BR:
B
R
C
=
{
σ
(
Conv
C
[
B
C
;
B
R
]
)
⊙
B
C
}
⊕
{
σ
(
Conv
R
[
B
R
;
B
C
]
)
⊙
B
R
}
B_{RC}=\{\sigma(\text{Conv}_C[B_C;B_R])\odot B_C\}\oplus\{\sigma(\text{Conv}_R[B_R;B_C])\odot B_R\}
BRC={σ(ConvC[BC;BR])⊙BC}⊕{σ(ConvR[BR;BC])⊙BR}其中
B
R
C
B_{RC}
BRC表示融合BEV特征图,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)表示sigmoid函数,
⊙
\odot
⊙、
⊕
\oplus
⊕和
[
⋅
;
⋅
]
[\cdot;\cdot]
[⋅;⋅]分别表示按元素乘法、按元素加法和通道拼接。然后,
B
R
C
B_{RC}
BRC以和基准方案BEVFormer相同的方式,通过归一化和前馈网络。重复BEV编码器(本节所有内容)
L
L
L次后,生成最终的BEV特征图。和BEVFormer相比,本文的方法可以生成更精确的BEV特征图(特征更集中在真实边界框附近),而前者缺少足够的深度信息。
3.3. 雷达网格点修正
提案感知的雷达注意力(PRA)将3D提案和相关联的雷达点云作为输入,使用基于MLP的注意力决定每个点的重要程度。然后使用雷达网格点池化(RGPP),考虑雷达点的特性和分布采样网格点,并将雷达点和多尺度图像的特征聚合到网格点中,生成细化特征。细化特征和初始提案特征组合产生最终输出。
提案感知的雷达注意力:使用CRAFT中的软极性关联(SPA)将雷达点与3D提案关联。首先将3D提案和雷达点转换到极坐标系下,然后将径向距离和水平角均在一定范围内的雷达点与3D提案关联。但这样会使更多的点与3D提案关联,因为该范围比3D提案更大。引入PRA,设
b
=
(
c
,
w
,
l
,
h
,
θ
,
v
pred
)
b=(\mathbf{c},w,l,h,\theta,\mathbf{v}_\text{pred})
b=(c,w,l,h,θ,vpred)表示一个3D提案,其中心位置为
c
\mathbf{c}
c,3D尺寸为
(
w
,
l
,
h
)
(w,l,h)
(w,l,h),朝向角为
θ
\theta
θ,速度为
v
pred
\mathbf{v}_\text{pred}
vpred。与
b
b
b相关联的
K
K
K个雷达点记为
{
r
k
}
k
=
1
K
\{r_k\}_{k=1}^K
{rk}k=1K,其中第
k
k
k个点的位置为
u
k
∈
R
3
\mathbf{u}_k\in\mathbb{R}^3
uk∈R3。引入逐点的分数向量
s
k
s_k
sk来决定每个点的重要程度,得到被关注的雷达点特征
a
k
a_k
ak:
s
k
=
MLP
2
(
[
MLP
1
(
r
k
)
;
δ
(
c
−
u
k
)
]
)
a
k
=
Softmax
(
s
k
)
⊙
MLP
3
(
r
k
)
s_k=\text{MLP}_2([\text{MLP}_1(r_k);\delta(\mathbf{c}-\mathbf{u}_k)])\\a_k=\text{Softmax}(s_k)\odot\text{MLP}_3(r_k)
sk=MLP2([MLP1(rk);δ(c−uk)])ak=Softmax(sk)⊙MLP3(rk)其中MLP沿通道维度处理,
δ
(
⋅
)
\delta(\cdot)
δ(⋅)表示位置编码。
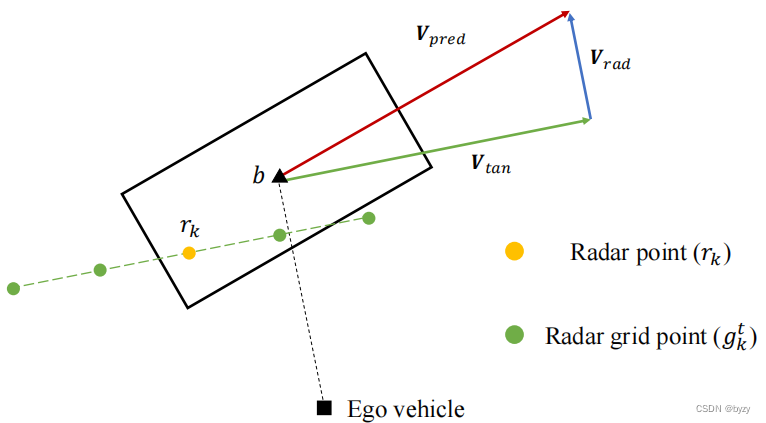
雷达网格点池化:网格点的位置和数量对基于网格点的修正模块来说是最重要的。考虑到雷达点的位置误差和稀疏程度,本文提出RGPP。如上图所示,3D提案的速度向量
v
pred
\mathbf{v}_\text{pred}
vpred可分解为切向速度
v
tan
\mathbf{v}_\text{tan}
vtan和径向速度
v
rad
\mathbf{v}_\text{rad}
vrad。对第
k
k
k个雷达点
r
k
r_k
rk,
T
T
T个网格点
{
g
k
t
}
t
=
0
T
−
1
\{g_k^t\}_{t=0}^{T-1}
{gkt}t=0T−1按如下方式被生成在位置
u
k
\mathbf{u}_k
uk附近:
γ
=
{
ρ
min
,
∣
v
tan
∣
≤
ρ
min
∣
v
tan
∣
,
ρ
min
<
∣
v
tan
∣
<
ρ
max
ρ
max
,
∣
v
tan
∣
≥
ρ
max
g
k
t
=
γ
⋅
(
t
T
−
1
−
1
2
)
⋅
v
tan
∣
v
tan
∣
+
u
k
,
t
=
0
,
⋯
,
T
−
1
\gamma=\left\{\begin{matrix} \rho_{\min}, & |\mathbf{v}_{\tan}|\leq\rho_{\min}\\ |\mathbf{v}_{\tan}|, & \rho_{\min}<|\mathbf{v}_{\tan}|<\rho_{\max}\\ \rho_{\max}, & |\mathbf{v}_{\tan}|\geq\rho_{\max} \end{matrix}\right.\\g_k^t=\gamma\cdot \left(\frac{t}{T-1}-\frac{1}{2}\right)\cdot \frac{\mathbf{v}_{\tan}}{|\mathbf{v}_{\tan}|}+\mathbf{u}_k, \;\;\; t=0,\cdots,T-1
γ=⎩
⎨
⎧ρmin,∣vtan∣,ρmax,∣vtan∣≤ρminρmin<∣vtan∣<ρmax∣vtan∣≥ρmaxgkt=γ⋅(T−1t−21)⋅∣vtan∣vtan+uk,t=0,⋯,T−1
本文沿速度切向(
v
tan
\mathbf{v}_{\tan}
vtan)创建网格点,这是因为雷达点通常在切向更具噪声。网格点的距离与切向速度
v
tan
\mathbf{v}_{\tan}
vtan的大小相关。这样,对该3D提案有
K
T
KT
KT个网格点。然后使用最远点采样选择
M
M
M个网格点
{
g
m
}
m
=
1
M
\{g_m\}_{m=1}^M
{gm}m=1M。
然后使用集合抽象(SetAbs)编码每个网格点
g
m
g_m
gm周围的雷达点,得到雷达点特征
F
m
pts
F_m^\text{pts}
Fmpts:
F
m
pts
=
SetAbs
(
{
a
k
}
k
=
1
K
,
{
r
k
}
k
=
1
K
,
g
m
)
F_m^\text{pts}=\text{SetAbs}(\{a_k\}_{k=1}^K,\{r_k\}_{k=1}^K,g_m)
Fmpts=SetAbs({ak}k=1K,{rk}k=1K,gm)同时,网格点被投影到图像特征图
F
C
F_C
FC上通过双线性采样得到图像特征
F
m
img
F_m^\text{img}
Fmimg:
F
m
img
=
Bilinear
(
F
C
,
proj
(
g
m
)
)
F_m^\text{img}=\text{Bilinear}(F_C,\text{proj}(g_m))
Fmimg=Bilinear(FC,proj(gm))其中
proj
(
⋅
)
\text{proj}(\cdot)
proj(⋅)表示投影过程。最后按下式获得提案特征:
F
m
obj
=
maxpool
(
F
m
pts
⊕
F
m
img
)
F_m^\text{obj}=\text{maxpool}(F_m^\text{pts}\oplus F_m^\text{img})
Fmobj=maxpool(Fmpts⊕Fmimg)上述提案特征会与初始提案特征融合进行3D提案的修正。
3.4. 雷达数据预处理
本文通过降低判断雷达点是否有效的严格性和多帧积累(进行自车运动补偿和点运动补偿)增加雷达点云的密度。
4. 实验
4.2. 实施细节
图像分支使用FCOS3D的预训练权重,雷达分支从头训练。训练时使用类别平衡策略CBGS。
4.3. 数据增广
通过关联雷达点与图像像素,使用图像数据增广和BEV数据增广;在极坐标下使用GT增广,并使用方法增加非空(即含雷达点的)真实边界框的数量。
4.4. nuScenes数据集上的结果
本文方法的性能能大幅超过基于相机的和基于相机-雷达融合的方法。
4.5. nuScenes验证集上的消融实验
组件分析:RGBQ能带来最高的性能提升,而RCG,RGPP和RPA能带来少量性能提升。
雷达网格点采样的作用:与不适用网格点的方法以及常规网格点生成方法相比,本文的自适应网格点生成方法的性能最优。常规网格点的生成会受到稀疏雷达的特性影响,而导致某些网格点周围不含雷达点,从而减少有效网格点的数量。
数据增广:图像数据增广和BEV数据增广均能显著增加性能;极坐标GT增广能略微增加性能。
雷达点过滤:通过适当过滤原始雷达点能带来一定的性能提升。