介绍
网络通讯,一台计算机给另一台计算机传输数据,中间过程就叫做通信,也就是通过IO接口输入输出到另一台计算机,这个就叫做网络IO.
文件描述符(File descriptor)
是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统而windows为句柄的概念。
原文链接:
网络通信和IO(1):网络通信与IO基本概念/什么是IO,什么是网络通信/文件IO和网络IO的区别/什么是文件描述符/什么是阻塞IO(BIO)/什么是非阻塞IO(NIO)/JAVA中的IO_丨1?io_加班攒钱种头发的博客-CSDN博客
同步IO和异步IO对比

同步阻塞IO/BlockingIO
经典应用阻塞socket/BIO
如果内核数组一直没准备号,那用户进程就将一直阻塞,浪费性能,可以使用非阻塞IO优化。

同步非阻塞IO/ non BlockingIO

如果内核数据还么有准备好,可以先返回错误信息给用户进程,让它需要等待(通过轮询方式再请求)
流程:
- 应用进程向操作系统内核,发起recvfrom读取数据。
- 操作系统内核数据没有准备好,立即返回EWOULDBLOCK错误码。
- 应用程序轮询调用,继续向操作系统内核发起recvfrom读取数据。
- 操作系统内核数据准备好了,从内核缓冲区拷贝到用户空间。
- 完成调用,返回成功提示。
它依然存在性能问题,即频繁的轮询,导致频繁的系统调用,同样会消耗大量的CPU资源。可以考虑IO复用模型,去解决这个问题。
多路复用IO模型
复习下,什么是文件描述符fd(File Descriptor),它是计算机科学中的一个术语,形式上是一个非负整数。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
IO复用模型核心思路:系统给我们提供一类函数(如我们耳濡目染的select、poll、epoll函数),它们可以同时监控多个fd的操作,任何一个返回内核数据就绪,应用进程再发起recvfrom系统调用。
IO多路复用之select
应用进程通过调用select函数,可以同时监控多个fd,在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时应用进程再发起recvfrom请求去读取数据。

非阻塞IO模型(NIO)中,需要N(N>=1)次轮询系统调用,然而借助select的IO多路复用模型,只需要发起一次系统调用就够了,大大优化了性能。
但是呢,select有几个缺点:
- 监听的IO最大连接数有限,在Linux系统上一般为1024。
- select函数返回后,是通过遍历fdset,找到就绪的描述符fd。(仅知道有I/O事件发生,却不知是哪几个流,所以遍历所有流)
因为存在连接数限制,所以后来又提出了poll。与select相比,poll解决了连接数限制问题。但是呢,select和poll一样,还是需要通过遍历文件描述符来获取已经就绪的socket。如果同时连接的大量客户端在一时刻可能只有极少处于就绪状态,伴随着监视的描述符数量的增长,效率也会线性下降。
因此经典的多路复用模型epoll诞生。
IO多路复用之epoll
为了解决select/poll存在的问题,多路复用模型epoll诞生,它采用事件驱动来实现,流程图如下:

epoll先通过epoll_ctl()来注册一个fd(文件描述符),一旦基于某个fd就绪时,内核会采用回调机制,迅速激活这个fd,当进程调用epoll_wait()时便得到通知。这里去掉了遍历文件描述符的坑爹操作,而是采用监听事件回调的的机制。这就是epoll的亮点。
我们一起来总结一下select、poll、epoll的区别

epoll明显优化了IO的执行效率,但在进程调用epoll_wait()时,仍然可能被阻塞的。能不能酱紫:不用我老是去问你数据是否准备就绪,等我发出请求后,你数据准备好了通知我就行了,这就诞生了信号驱动IO模型。
信号驱动模型
信号驱动IO不再用主动询问的方式去确认数据是否就绪,而是向内核发送一个信号(调用sigaction的时候建立一个SIGIO的信号),然后应用用户进程可以去做别的事,不用阻塞。当内核数据准备好后,再通过SIGIO信号通知应用进程,数据准备好后的可读状态。应用用户进程收到信号之后,立即调用recvfrom,去读取数据。

信号驱动IO模型,在应用进程发出信号后,是立即返回的,不会阻塞进程。它已经有异步操作的感觉了。但是你细看上面的流程图,发现数据复制到应用缓冲的时候,应用进程还是阻塞的。回过头来看下,不管是BIO,还是NIO,还是信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的。还有没有优化方案呢?AIO(真正的异步IO)!
异步IO(AIO)
前面讲的BIO,NIO和信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的,因此都不是真正的异步。AIO实现了IO全流程的非阻塞,就是应用进程发出系统调用后,是立即返回的,但是立即返回的不是处理结果,而是表示提交成功类似的意思。等内核数据准备好,将数据拷贝到用户进程缓冲区,发送信号通知用户进程IO操作执行完毕。
流程如下:

异步IO的优化思路很简单,只需要向内核发送一次请求,就可以完成数据状态询问和数据拷贝的所有操作,并且不用阻塞等待结果。日常开发中,有类似的业务场景:
比如发起一笔批量转账,但是转账处理比较耗时,这时候后端可以先告知前端转账提交成功,等到结果处理完,再通知前端结果即可。
参考链接:看一遍就理解:IO模型详解 - 掘金
Java IO
按照流的流向分,可以分为输入流和输出流;
按照操作单元划分,可以划分为字节流和字符流;
Java中的流分为两种,一种是字节流,另一种是字符流,分别由四个抽象类来表示(每种流包括输入和输出两种所以一共四个):InputStream,OutputStream,Reader,Writer。
Java中其他多种多样变化的流均是由它们派生出来的.
字符流和字节流是根据处理数据的不同来区分的。字节流按照8位传输,字节流是最基本的,所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。
BIO、NIO、AIO区别
BIO【同步阻塞IO blocking IO】、 ServerSocket
NIO【同步非阻塞IO Non BlockingIO】、多路复用IO ServerSocketChannel
AIO [异步Asynchronous IO] AsynchronousServerSocketChannel

原文链接:https://blog.csdn.net/zhcswlp0625/article/details/93461137
原文链接:https://blog.csdn.net/hequnwang10/article/details/124626326
适用场景分析
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解;
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持;
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持;
原文链接:
Java中IO流分为几种?BIO,NIO,AIO 有什么区别?_java 中 io 流分为几种?bio,nio,aio 有什么区别_hequnwang10的博客-CSDN博客
java.io包基于流模型实现,提供File抽象、输入输出流等IO的功能。交互方式是同步、阻塞的方式,在读取输入流或者写入输出流时,在读、写动作完成之前,线程会一直阻塞。java.io包的好处是代码比较简单、直观,缺点则是IO效率和扩展性存在局限性,容易成为应用性能的瓶颈。
java.net包下提供的部分网络API,比如Socket、ServerSocket、HttpURLConnection
也可以被归类到同步阻塞IO类库,因为网络通信同样是IO行为
java 1.4中引入了NIO框架(java.nio 包),提供了Channel、Selector、Buffer等新的抽象,可以构建多路复用IO程序,同时提供更接近操作系统底层的高性能数据操作方式.
在Java7中,NIO有了进一步的改进,也就是NIO2,引入了异步非阻塞IO方式,也被称为AIO(Asynchronous IO),异步IO操作基于事件和回调机制。
zero 拷贝
在传统的数据 IO 模式中,读取一个磁盘文件,并发送到远程端的服务,就共有四次用户空间与内核空间的上下文切换,四次数据复制,包括两次 CPU 数据复制,两次 DMA 数据复制。
解放CPU,这也就是零拷贝Zero-Copy技术。数据应该可以直接从内核缓冲区直接送入Socket缓冲区。
解决思路:零拷贝技术的几个实现手段包括:mmap+write、sendfile、sendfile+DMA收集、splice等。
在Java NIO包中提供了零拷贝机制对应的API
(1)mmap + write 的零拷贝方式:
FileChannel 的 map() 方法产生的 MappedByteBuffer:FileChannel 提供了 map() 方法
(2)sendfile 的零拷贝方式:
FileChannel 的 transferTo、transferFrom 如果操作系统底层支持的话,transferTo、transferFrom也会使用 sendfile 零拷贝技术来实现数据的传输。
FileChannel的实现类并不在JDK本身,而位于sun.nio.ch.FileChannelImpl类中,零拷贝的具体实现自然也都是native方法,看源码。
零拷贝机制的应用
零拷贝在很多框架中得到了广泛应用,一般都以Netty为例来分析。但作为大数据工程师,
Kafka 的索引文件使用的是 mmap + write 方式,数据文件使用的是 sendfile 方式
DMA(Direct Memory Access,直接内存访问):DMA 本质上是一块主板上独立的芯片,允许外设设备直接与内存存储器进行数据传输,并且不需要CPU参与的技术
扩展
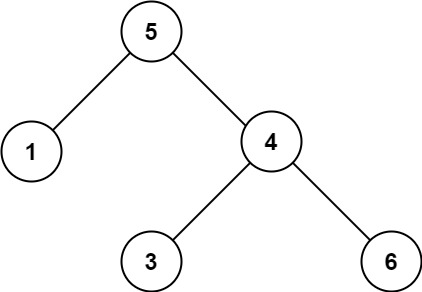
问题一万个元素,普通链表无序 寻找x元素?
左边小右边大,数据结构要有序
遍历、2分查找 O(n)对有序链表建索引,链表加多级索引的结构 就是 跳表,(以空间换时间)
跳跃表
查询/增加/删除O(logN),每一层的节点数为下一层的一半,处理方法抛硬币法。
分治【分而治之,减而治之】有路由、索引、映射
跳表的原理与实现 [图解]_Monkey Ji的博客-CSDN博客
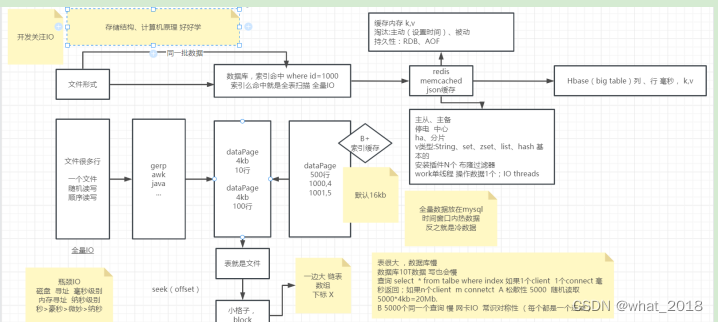
redis和memcached区别

3高 高性能[不浪费就是高性能]、高可靠、高并发