今天我们来看看一个简单的数据库路由组件要怎么开发出来,这篇文章分为几个步骤进行介绍,分别为:
- 什么是数据库路由
- 路由组件的作用
- 为什么要自研组件
- 需要用到什么技术
- 整体的业务流程
- 主要代码
介绍
数据库路由的作用
使用数据库路由是在业务体量很大, 数据量增长过快,所以要把用户的数据拆分到不同的库表中,以此来减轻单机的压力。
数据库路由是用于分库分表操作,有两种方式。
1)垂直拆分
根据业务分类,将不同的业务表分布在不同的数据库中。可以将数据的压力分担到不同的数据库中,专库专用。
2)水平拆分
当垂直拆分遇到单机瓶颈的时候,就可以将一张数据表拆分多张表,放在不同的数据库中。
本篇文章也是基于水平拆分进行讲解。
为什么要自研数据库路由?
明明有一些成熟的路由组件,为什么还要自研?
1、更容易维护; 市面上有路由组件,比如:shardingsphere;但是这个组件非常庞大,而且我们也需要随着组件的版本给项目升级。而自研组件,维护起来就更容易。
2、更容易扩展; 我们可以结合自身的业务需求,去对组件进行一系列的扩展。比如说自定义路由协议、扫描指定的库表数据等等。
3、更安全; 自研的组件不会有因为额外导入Jar包,导致项目出现问题的风险。
最后是否去自研一个路由组件或者使用已经非常成熟的路由组件,还是要根据自己项目的业务需求来决定。我们可以为了更加的匹配项目,去自己研发一个简单的路由组件。也可以去使用成熟的组件,都可以。
需要什么技术?
开发一个简单的路由组件并不需要有多么🐮的技术框架,你需要了解的是关于SpringBoot的starter开发、面向切面编程、散列算法、Mybatis拦截器以及Java反射。
用到的技术都是比较基础的, 在学习这个路由组件开发的过程,你也能够务实好自身的基础。
整体流程
上面简单的介绍了一下什么是数据库路由,接下来我们来看看这个组件整体的一个流程是什么。首先我们要用到SpringBoot的starter开发,就是在项目启动的时候,去进行一系列的数据库的初始化配置。然后要用到AOP面向切面,自定义一个路由注解配置在你想要进行分库分表的接口方法处。当使用这个方法的时候,就会通过AOP定义库表索引。当连接数据库的使用getConnection()的时候,就会根据库表索引去切换数据源。最后,实现Mybatis的拦截器,通过反射修改SQL语句的表名,至此就完成了整体的流程。如下图:
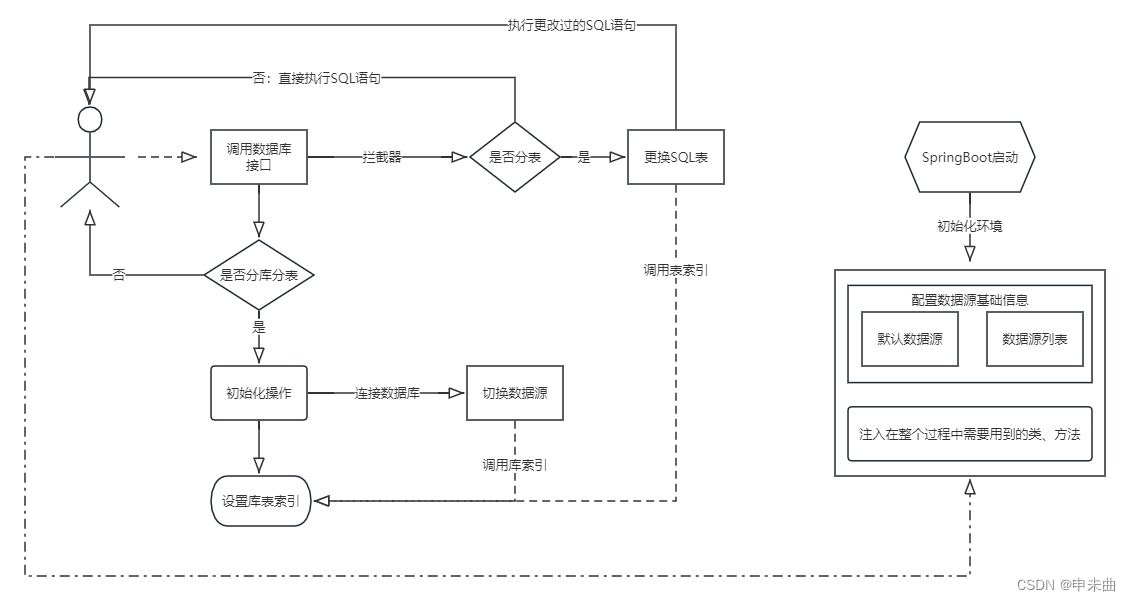
主要代码介绍
代码有很多,我们主要介绍一下切换数据源的代码以及通过散列设置库表索引的方法。
1)数据源切换
@Bean
public DataSource dataSource(){
Map<Object,Object> targetDatasource = new HashMap<>();
for (String key : dataSourceMap.keySet()) {
Map<String, Object> map = dataSourceMap.get(key);
targetDatasource.put(key,new DriverManagerDataSource(map.get("url")+"",map.get("username")+"",map.get("password")+""));
}
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDatasource);
dynamicDataSource.setDefaultTargetDataSource(defaultDataSource);
return dynamicDataSource;
}
数据源切换的代码就这么简单,看到这你应该也不知道到底是如何切换的。其实归根结底是因为DynamicDataSource 继承了AbstractRoutingDataSource,进去看这个源码后我们在getConnection()中能够发现一点端倪。

在getConnection()之前,先去确定了一个目标数据源,再让我们去看看determineTargetDataSource的代码。
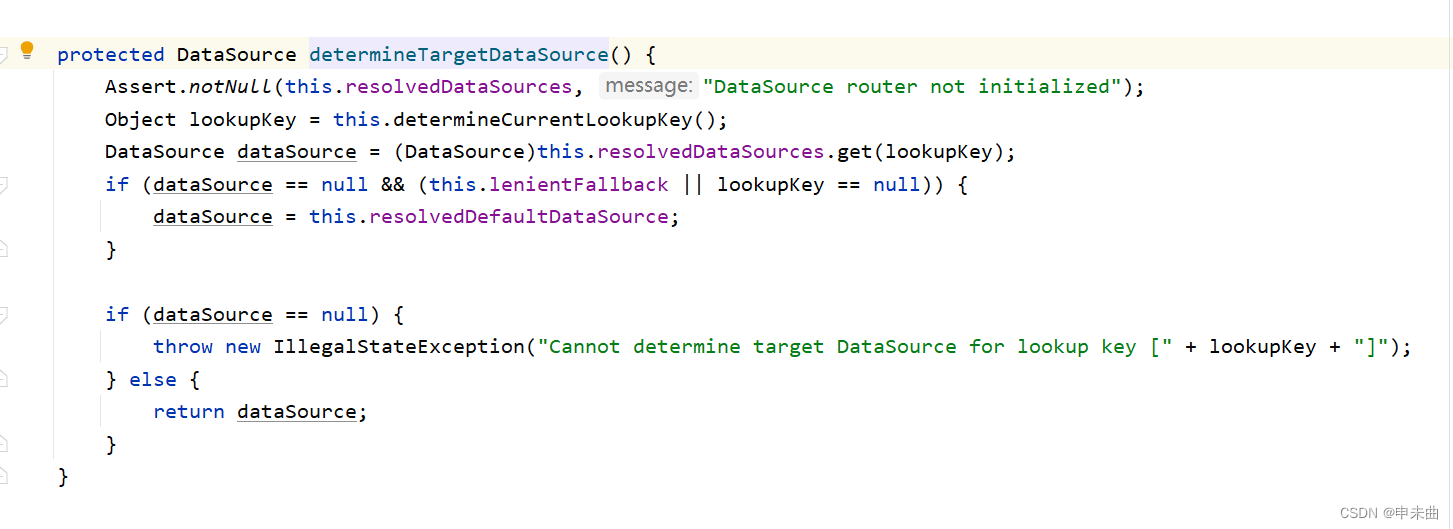
看到了吗,数据源默认使用的是resolvedDataSources里面的,如果没有再使用默认的数据源。在上面我们切换数据源的代码可以看到,我们是有设置了一个targetDataSource的,但是和resolvedDataSources又有什么关系?
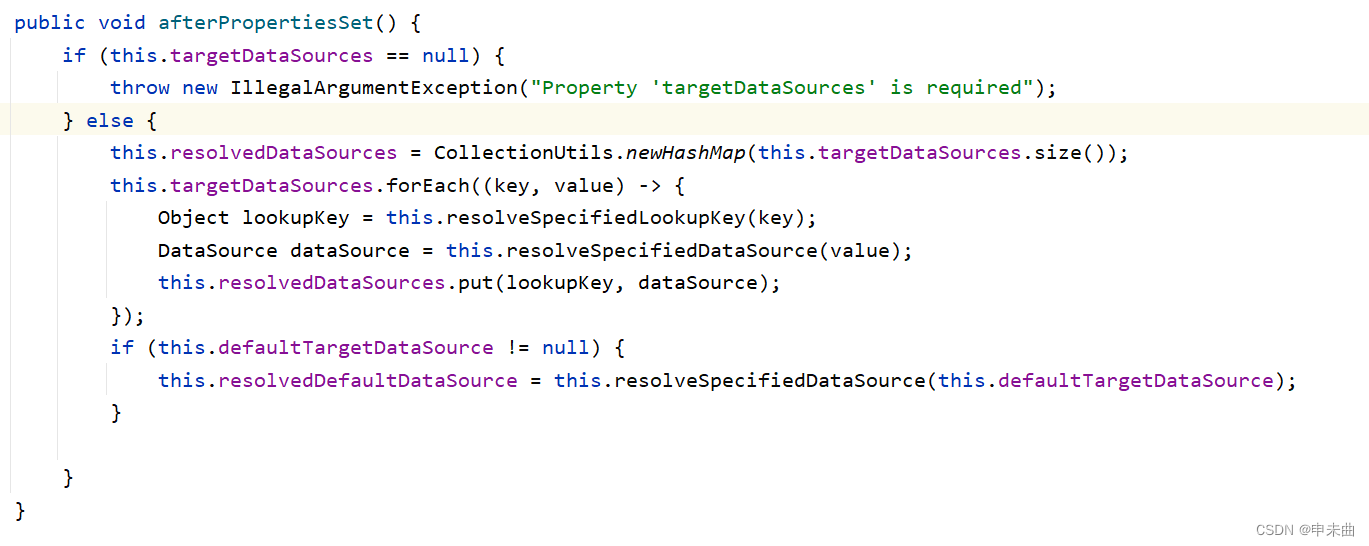
看这个代码就知道了。看到这,不知道你对数据源的切换是否了解了呢?
2)散列算法
看完了数据源的切换,我们接下来看看是怎么设置库表索引的。我们都知道,如果单纯的在Map中设置索引的话,就很有可能会出现哈希碰撞,我们可以参考HashMap的方法,使用扰动函数让数据更加分散。
int size = tbCount + dbCount;
String key = "申未曲"
int idx = (size - 1) & (key.hashCode() ^ key.hashCode() >>> 16);
int dbIdx = idx / tbCount + 1;
int tbIdx = idx - tbCount * (dbIdx + 1);
这样我们就可以在size的范围内去获取到对应的索引了。
我们来理解一下代码,先看看第三行。
int idx = (size - 1) & (key.hashCode() ^ key.hashCode() >>> 16);
这句代码分为了两个部分,第一个部分是将两个key的哈希值的前后16为进行了按位异或。比如说“申未曲”的二进制码为:1110001001101100101111011,不足32为前补0,得到了:
00000001110001001101100101111011 将这个二进制码右移16位就得到了:
00000000000000000000000111000100 按位异或之后就得到了如下二进制:
00000001110001001101100111111111 = 29678079
假设size=10,那么接下来就需要让size与hashcode进行按位与,29678079 & 9
00000001110001001101100111111111 & 00000000000000000000000000001001得到的值为1001=9
int dbIdx = idx / tbCount + 1;
int tbIdx = idx - tbCount * (dbIdx + 1);
然后再看看这两句代码,这样看可能也不好理解,那我们举个例子。当前有8张表,分别放在了两个库内,获取到的索引分别为1~8,那当索引idx=5的时候,所在的是第几个库第几张表?
带入进来,5 / 4 + 1 = 2 (库) ;5 - 4 * (2 -1 ) 1 (表),认真理解后还是很简单的。
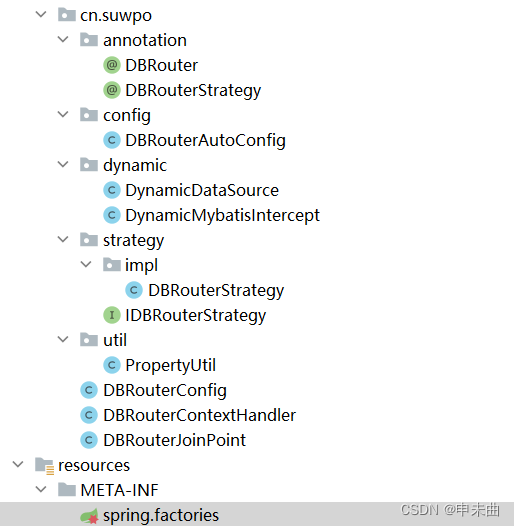
就说这些, 大家可以根据上面提供的流程与逻辑,看看能不能自己研发一个出来。代码结构图如下: