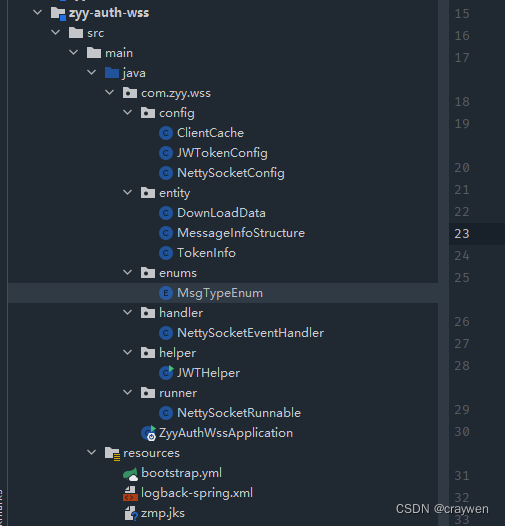
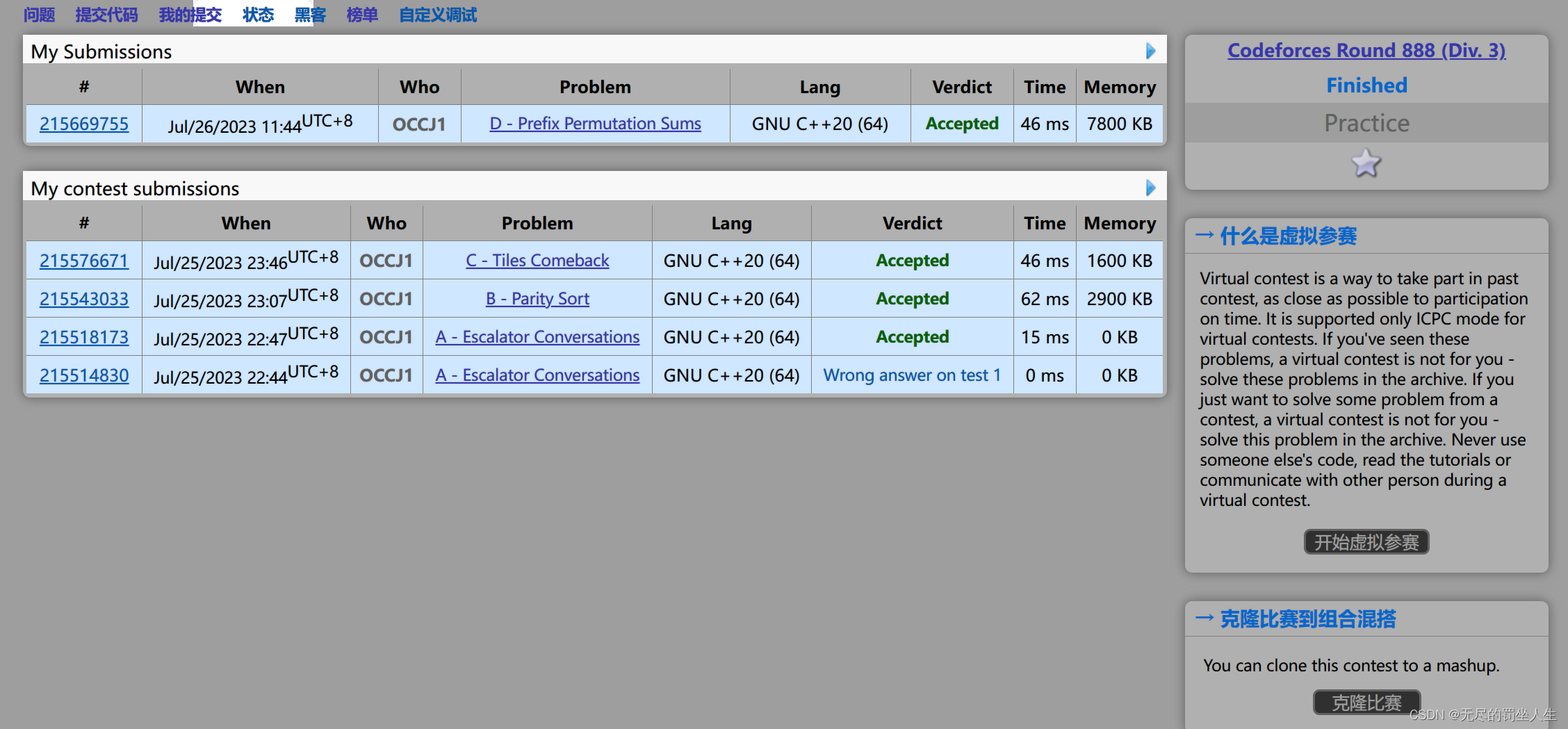
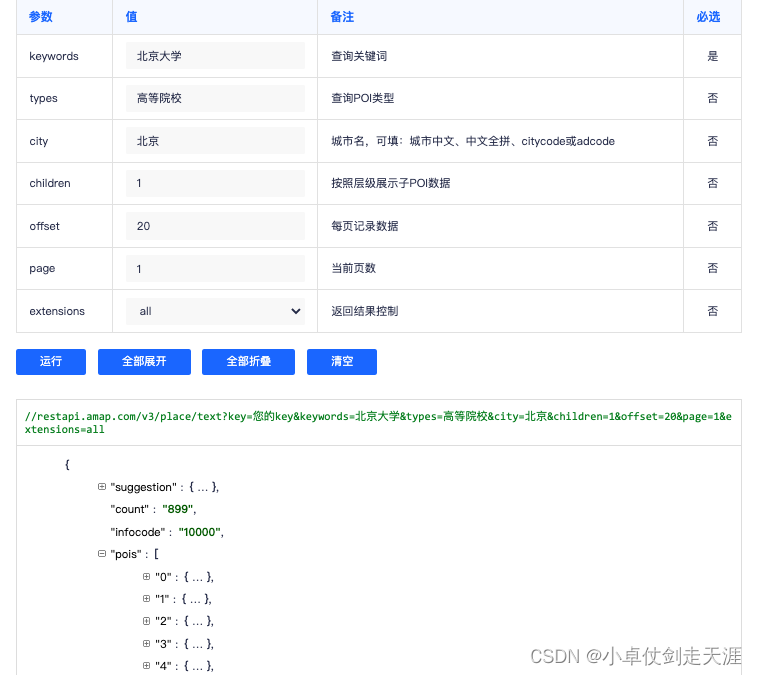
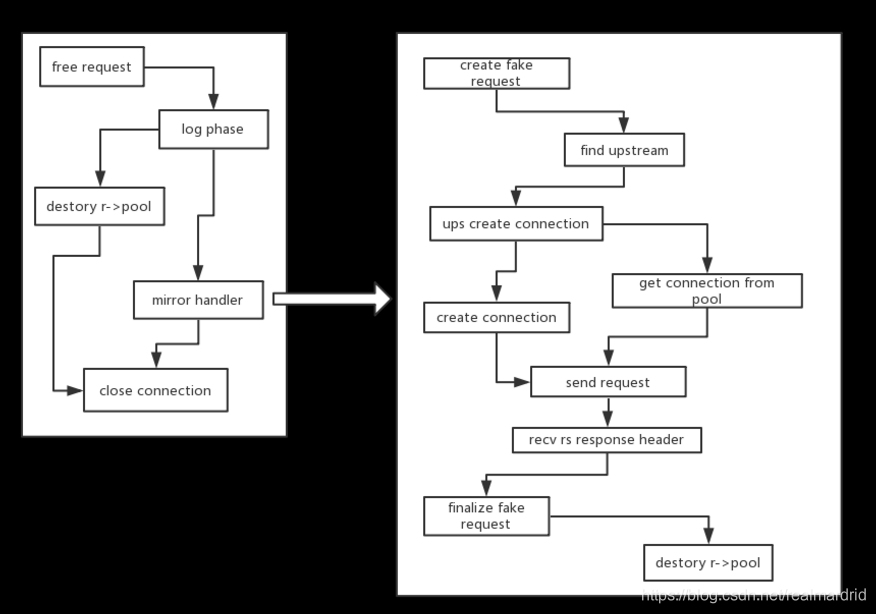
五、试分析在使用下列循环不变量时,HEAP-INCREASE-KEY 的正确性:在算法的第4~6行 while循环每次迭代开始的时候,子数组 A[1…A.heap-size]要满足最大堆的性质。如果有违背,只有一个可能:A[i]大于 A[PARENT(i)]。这里,你可以假定在调用 HEAPINCREASE-KEY时,A[1…A.heap-size]是满是最大堆性质的。
文心一言:
在使用以下循环不变量时,HEAP-INCREASE-KEY的正确性可以得到分析:
循环不变量:在算法的第4~6行 while循环每次迭代开始的时候,子数组 A[1…A.heap-size]要满足最大堆的性质。
这个循环不变量是在调用 HEAP-INCREASE-KEY 之前被满足的。因此,在这个函数内部,我们可以假设 A[1…A.heap-size] 是满足最大堆性质的。
在 HEAP-INCREASE-KEY 函数中,只有一行代码可能会破坏最大堆的性质:
A[i] = key;
但是,根据前提条件,我们只知道 A[1…A.heap-size] 是满足最大堆性质的。因此,如果 A[i] 大于 A[PARENT(i)],那么在执行上述行之前,最大堆的性质已经被破坏了。
因此,可以得出结论:在使用这个循环不变量时,HEAP-INCREASE-KEY 的正确性可以得到保证,因为它不会在执行上述行之前破坏最大堆的性质。
讯飞星火:
在使用HEAP-INCREASE-KEY时,确保子数组A[1…A.heap-size]满足最大堆的性质是正确的。在算法的第4~6行while循环每次迭代开始的时候,需要检查当前元素A[i]是否大于其父节点A[PARENT(i)]的值。如果存在违背最大堆性质的情况,即A[i]大于A[PARENT(i)],那么可以通过调用HEAPINCREASE-KEY来调整A[i]的位置,使其满足最大堆的性质。
在调用HEAPINCREASE-KEY之前,可以假定子数组A[1…A.heap-size]已经满足最大堆的性质。这意味着每个子数组中的元素都是按照非递减顺序排列的,并且对于任何i,都有A[LEFT(i)/2] <= A[i] <= A[RIGHT(i)/2]。
通过调用HEAPINCREASE-KEY,可以将A[i]与其父节点进行比较,并根据需要进行交换或调整位置,以确保整个子数组仍然满足最大堆的性质。这样可以维护堆的性质,并在后续的插入、删除等操作中保持正确性。
因此,在使用HEAP-INCREASE-KEY时,确保子数组A[1…A.heap-size]满足最大堆的性质是正确的。

360智脑:
在算法第4到6行的while循环中,假设A[1…A.heap_size]是一个最大堆,那么每次迭代开始时,A[1…A.heap_size]仍然是一个最大堆,因为在每次迭代中,都会将A[i]与A[parent(i)]进行比较,如果A[i]大于A[parent(i)],则交换两个元素的位置,这样保证了A[1…A.heap_size]仍然是一个最大堆。因此,当A[1…A.heap_size]满足最大堆性质时,HEAP-INCREASE-KEY就是正确的了。
chatglm:
在使用 HEAP-INCREASE-KEY 函数时,需要保证堆的最大性质,否则可能会导致堆的不稳定。在算法的第 4~6 行 while 循环每次迭代开始的时候,子数组 A[1…A.heap-size] 要满足最大堆的性质,这是正确的。
如果 A[i] 大于 A[PARENT(i)],则需要进行堆调整,将 A[i] 调整到其正确位置,以满足最大堆性质。在调整过程中,可以使用 HEAP-INCREASE-KEY 函数来辅助实现。
在调用 HEAPINCREASE-KEY 时,需要假定 A[1…A.heap-size] 是满足最大堆性质的,这是因为 HEAPINCREASE-KEY 函数的作用是将堆顶元素 A[1] 调整到其正确位置,如果 A[1] 本来就不在堆顶,那么调整后的结果可能会破坏堆的最大性质。
因此,使用 HEAP-INCREASE-KEY 函数时需要保证输入的堆是满足最大堆性质的,否则可能会导致堆的不稳定。同时,在调整堆时,需要使用 HEAP-INCREASE-KEY 函数来辅助实现,以保证堆的正确性和稳定性。

通义千问:
在使用HEAP-INCREASE-KEY算法时,如果A[1…A.heap-size]不满足最大堆的性质,则可能是由于以下原因:
1.在调用HEAPINCREASE-KEY之前,数组A中存在一个非最大元素A[i],它大于A[PARENT(i)],导致A[1…A.heap-size]不满足最大堆的性质。
2.在调用HEAPINCREASE-KEY之后,数组A中存在一个非最大元素A[i],它大于A[PARENT(i)],导致A[1…A.heap-size]不满足最大堆的性质。
在第一种情况下,我们需要找到非最大元素A[i],并将其替换为A[PARENT(i)],以满足最大堆的性质。在第二种情况下,我们需要再次调用HEAPINCREASE-KEY算法,以确保A[1…A.heap-size]满足最大堆的性质。
因此,HEAP-INCREASE-KEY算法的正确性依赖于数组A在调用HEAPINCREASE-KEY之前和之后是否满足最大堆的性质。如果A[1…A.heap-size]在调用HEAPINCREASE-KEY之前和之后都满足最大堆的性质,则HEAP-INCREASE-KEY算法是正确的。

天工:
在使用 HEAP-INCREASE-KEY 时,我们需要确保在每次迭代开始时,子数组 A[1…A.heap-size] 要满足最大堆的性质。这是因为在每次迭代中,我们需要将子数组中的元素重新排列以满足堆的性质。
在循环中,我们可以假定在调用 HEAP-INCREASE-KEY 时,A[1…A.heap-size] 是满是最大堆性质的。因此,我们可以放心地使用 HEAP-INCREASE-KEY 来实现 HEAPSORT。
具体来说,在 HEAP-INCREASE-KEY 中,我们首先将子数组 A[1…A.heap-size] 中的最后一个元素 PARENT(i) 与当前元素 CURRENT(i) 进行比较。如果 CURRENT(i) 大于 PARENT(i),则说明当前元素需要向上移动,以满足最大堆的性质。我们将 CURRENT(i) 替换为 PARENT(i),然后将 A[1…A.heap-size] 中的最后一个元素 PARENT(i) 向上移动一位,以便满足最大堆的性质。
因此,在 HEAP-INCREASE-KEY 中,我们始终确保子数组 A[1…A.heap-size] 满足最大堆的性质。这使得 HEAPSORT 算法能够正确地排序,并且时间复杂度为 O(nlgn)。

chatgpt:
这个循环不变量表明在算法的第4~6行 while 循环的每次迭代开始时,子数组 A[1…A.heap-size] 必须满足最大堆的性质。也就是说,堆的每个父节点的值都要大于或等于其子节点的值。
在进行堆操作时,我们假设在调用 HEAP-INCREASE-KEY 之前,数组 A[1…A.heap-size] 已经是一个满足最大堆性质的堆。HEAP-INCREASE-KEY 的目标是将某个节点的值增加,并使得调整后的堆仍然满足最大堆的性质。
通过 HEAP-INCREASE-KEY 算法的实现,我们可以确保调整后的堆仍然满足最大堆性质。算法的基本思路是将当前节点的值与其父节点进行比较,如果当前节点的值大于其父节点的值,就交换这两个节点,然后继续向上调整直到满足最大堆性质。
根据循环不变量,在 while 循环的每次迭代开始时,子数组 A[1…A.heap-size] 都是满足最大堆性质的。如果有违背最大堆性质的情况发生,那么只有一种可能,即当前节点 A[i] 大于其父节点 A[PARENT(i)]。
在循环的第2和第3行中,我们将当前节点的值与其父节点进行比较,如果当前节点的值更大,则交换它们。这样做的目的是为了将当前节点向上移动,保持满足最大堆性质的子数组。
因此,在 while 循环的每次迭代开始时,子数组 A[1…A.heap-size] 仍然满足最大堆的性质。
综上所述,使用这个循环不变量可以确保 HEAP-INCREASE-KEY 算法的正确性,即调整后的堆仍然满足最大堆性质。

总结