Ziplist是一种内存优化的list存储结构,通过使用连续的内存空间存储,来减少内存碎片化,同时和链表的不同还有,它不存储前后指针,而是通过变长的字节存储前节点元素长度,通过计算长度来实现节点的查找。它是一种以时间换空间的数据结构。
普通的链表中节都存储着前后指针,分别指向上一个节点和下一个节点,节点在内存不是顺序存储的,所以会造成内存碎片化。
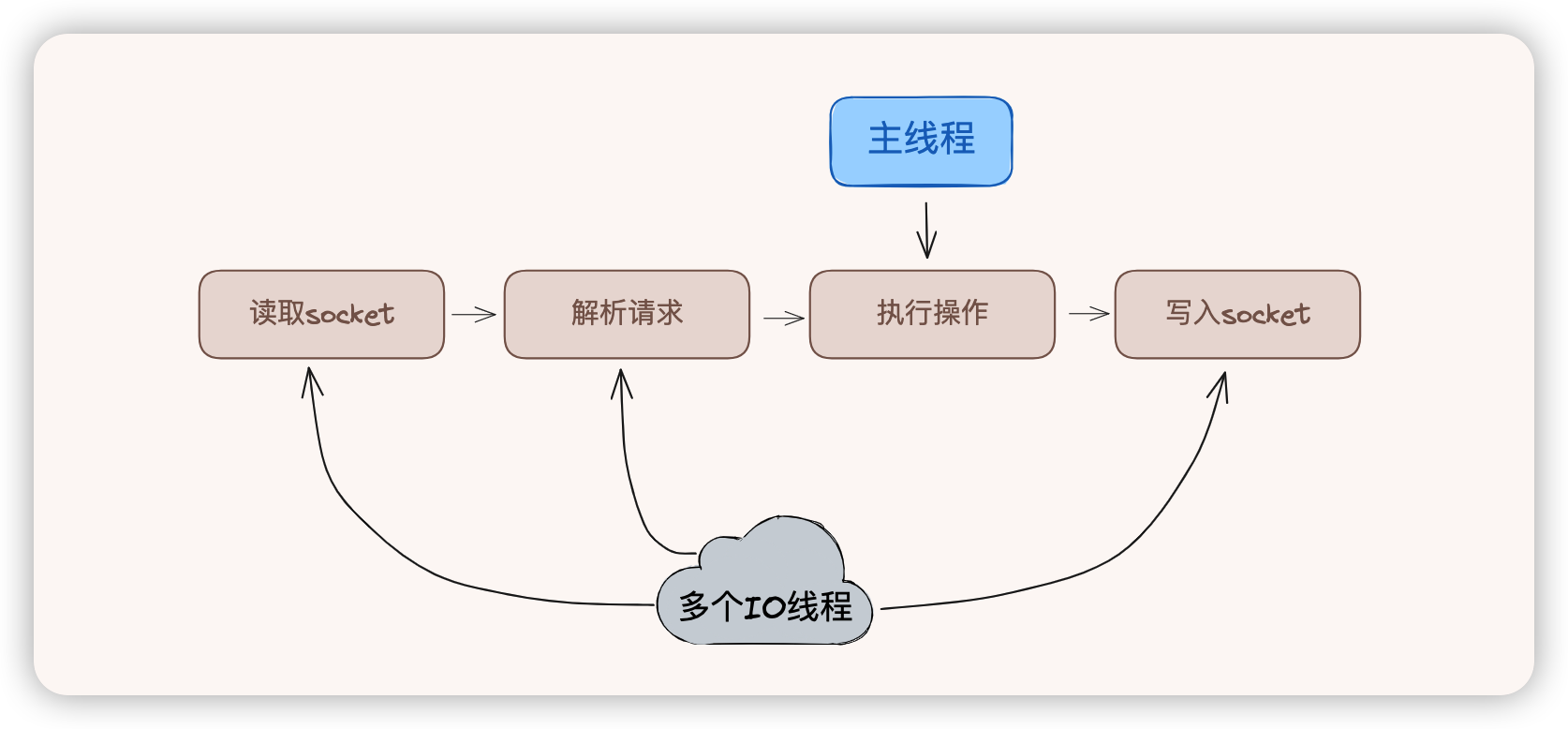
ziplist就是通过申请连续的内存空间来实现链表的功能,结构如下:
ziplist中,记录了zlail尾部指针偏移量,是为了可以通过其快速定位到尾部entry,实现方向索引。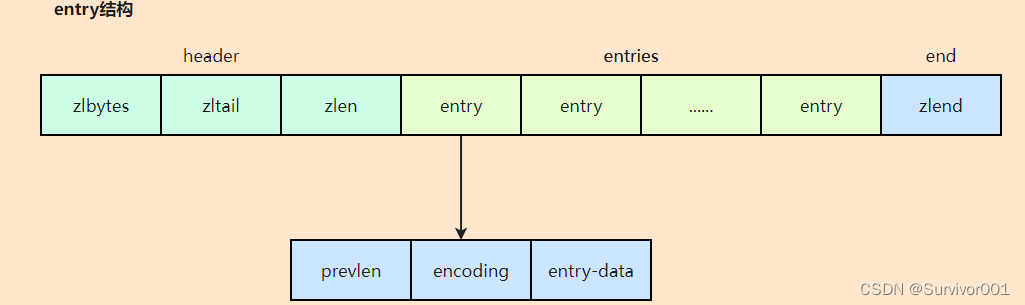
prevlen:上一个entry大小(1字节或者5字节),可以通过该长度计算来移动指针实现元素遍历查找。prevlen是一个边长字节:
- 当前entry元素大小在1~253字节时,prevlen使用1个节点来存储。
- 当前entry元素>= 254字节时,prevlen使用5个节点来存储,此时前一个1个字节固定为254最为标记,表示后面4个字节存储大真正数据。
(之所以取254,是因为zlend固定为255,用来表示结尾)
encoding:encoding存储了元素内容的类型编码信息(数值或者字符串)以及长度 (1、2、5字节),ziplist通过这个字段来决定后面的content的形式 。 当encoding最高的2位为11是,说明是数字,否则是字符串。
当数值类型在0~12范围内,则存储在encoding中,此时忽略entry-data。

和linklist相对比为什么会节省空间?
- ziplist通过申请连续内存空间存储,减少了内存碎片化。
- 内存不需要维护前后指针,节省了空间,而是通过len的计算偏移量,从而移动指针实现遍历查询。
- 同时redis对其做了相对优化,比如边长的prevlen,当前entry在254以内时,使用1个字节存储,超过时使用5个字节存储。
缺点?
- 压缩列表通过申请连续的内存空间存储,节省空间,这是它优点,同时也是它缺点,因为当数据量越来越大时,并不能保证能申请到大的连续的内存空间,查询性能也会下降(O(n)),所以一般当数据量达到一定程度时,需要转成其他存储结构。比如quicklist、hash等。
压缩链表中连锁更新问题
通过上面的介绍,了解到entry中pervious_entry_length会使用1或者5字节来存储上一个entry长度:
- 如果前一个节点长度小于254时,则使用1个字节来保存长度。
- 如果前一个节点长度>= 254时,使用5个字节来保持长度,其中前1个字节固定为0xfe,后4和字节才是真正的长度数据。
压缩链表中连锁更新场景
如果,有N个连续的、长度为250~253字节之间entry,此时他们的prevlen都是1个字节存储前一个节点长度,如下:

此时插入了一个大于或等于254字节元素A:

此时发现因为A是超过了254字节,所以B需要申请空间使用5个字节的prevlen保存A长度:

当B完成空间申请之后,B的内存空间就是254了,因为多申请了4个字节,此时C又需要使用5字节prevlen来存储,需要申请空间。
总结:压缩链表中entry使用边长prevlen记录上一个entry长度,当存在连续的、长度为250~253之间的entry时,此时发生新增、删除新的大于254数据时,会导致连续空间扩张操作称之为连锁更新。Redis并没有对此进行处理,因为概率比较低。
Ziplist特性:
- 压缩列表可以看成一种连续空间的”双线链表“。
- 列表节点之间不是通过指针连接,而是记录上一个节点和本节点长度来寻址,内存占用低。
- 如果列表数据过多,导致列表过程,可能影响查询性能,因为和链表一样都需要O(n)的查询效率。
- 增或者删除数据时,可能发生连锁更新问题。
图地址: