深度学习中的卷积操作
文章目录
- 深度学习中的卷积操作
- 1. 卷积
- 2. 一维卷积
- 2.1 使用nn.functional库中conv1d
- 2.2 使用nn库中的Conv1d
- 3. 二维卷积
- 3.1 nn.functional.conv2d
- 3.2 nn.Conv2d
1. 卷积
加权求和是一种非常重要的运算,可以整合局部数字特征进而是提取局部信息的重要手段。这种加权求和的形式被称作卷积或者滤波,对于两个信号 f ( x ) f(x) f(x) 和 g ( x ) g(x) g(x),卷积操作表示为
f ( x ) ∗ g ( x ) = ∫ − ∞ + ∞ f ( τ ) g ( x − τ ) d τ f(x)*g(x)=\int^{+\infty}_{-\infty}f(\tau)g(x-\tau)d\tau f(x)∗g(x)=∫−∞+∞f(τ)g(x−τ)dτ
卷积在物理现象中类似于波的叠加。
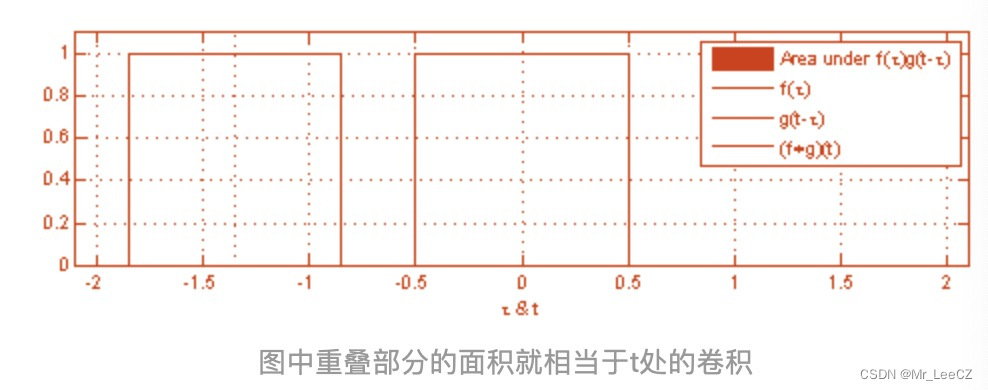
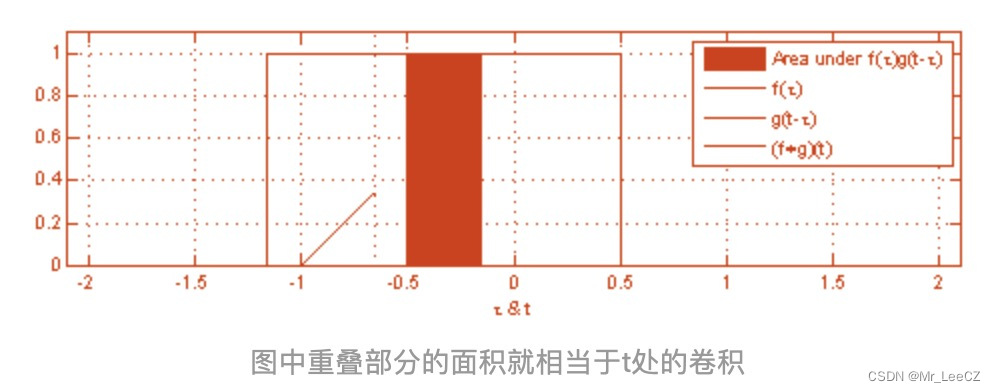
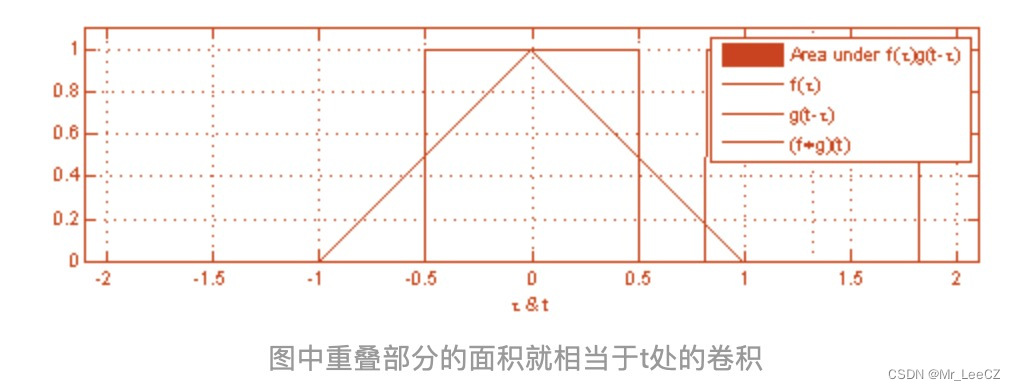
常用的卷积有1Dconv,2Dconv 和 3Dconv,这些卷积的区别仅在于滑动的方向不一样,而与卷积核的形状无关。1Dconv 滑动的方向仅为水平方向,2Dconv 沿着水平和竖直方向滑动。卷积后的形状遵循如下公式
h = ( h − kennel size + 2 ∗ padding ) / stride + 1 w = ( w − kennel size + 2 ∗ padding ) / stride + 1 h = (h - \text{kennel size}+2*\text{padding}) / \text{stride} + 1\\ w = (w - \text{kennel size}+2*\text{padding}) / \text{stride} + 1 h=(h−kennel size+2∗padding)/stride+1w=(w−kennel size+2∗padding)/stride+1
其中,padding 为边界填充 0 的行列数,stride 为滑动步长。
2. 一维卷积
2.1 使用nn.functional库中conv1d
该函数的优势可以设定核中的权重,尽管这个在网络中不是必须的。
用法:
torch.nn.functional.conv1d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
参数:
-
input-形状(minibatch,in_channels,iW)的输入张量
-
weight-形状(out_channels,groupsin_channels,kW)的过滤器
-
bias-形状 (out_channels) 的可选偏差。默认值:None
-
stride-卷积核的步幅。可以是单个数字或 one-element 元组 (sW,) 。默认值:1
-
padding-输入两侧的隐式填充。可以是字符串 {‘valid’, ‘same’}、单个数字或 one-element 元组 (padW,) 。默认值:0 padding=‘valid’ 与无填充相同。 padding=‘same’ 填充输入,使输出具有作为输入的形状。但是,此模式不支持 1 以外的任何步幅值。
一维卷积可以对单个向量进行卷积操作
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
a=range(16)
x = Variable(torch.Tensor(a))
'''
a: range(0, 16)
x: tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15.])
'''
x=x.view(1,1,16)
'''
x variable: tensor([[[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15.]]])
'''
b=torch.ones(3)
b[0]=0.1
b[1]=0.2
b[2]=0.3
weights = Variable(b)
weights=weights.view(1,1,3)
'''
weights: tensor([[[0.1000, 0.2000, 0.3000]]])
'''
y=F.conv1d(x, weights, padding=0)
'''
y: tensor([[[0.8000, 1.4000, 2.0000, 2.6000, 3.2000, 3.8000, 4.4000, 5.0000, 5.6000, 6.2000, 6.8000, 7.4000, 8.0000, 8.6000]]])
'''
y
tensor([[[0.8000, 1.4000, 2.0000, 2.6000, 3.2000, 3.8000, 4.4000, 5.0000,
5.6000, 6.2000, 6.8000, 7.4000, 8.0000, 8.6000]]])
1Dconv 同样可以对多个向量进行一维卷积操作
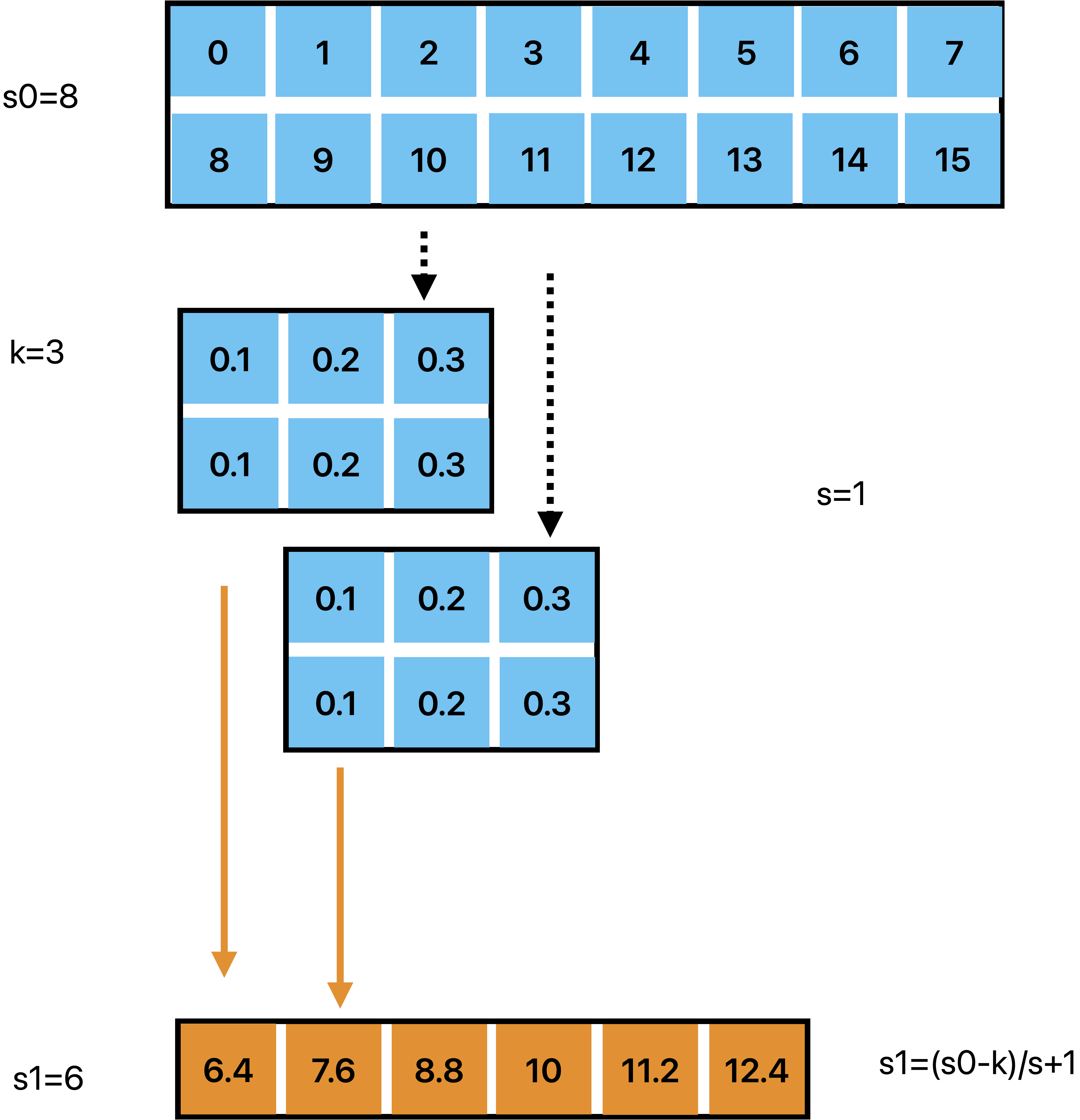
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
a=range(16)
x = Variable(torch.Tensor(a))
'''
a: range(0, 16)
x: tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15.])
'''
x=x.view(1,2,8)
'''
x variable: tensor([[[ 0., 1., 2., 3., 4., 5., 6., 7.]
[ 8., 9., 10., 11., 12., 13., 14., 15.]]])
'''
b=torch.ones(6)
b[0]=0.1
b[1]=0.2
b[2]=0.3
b[3]=0.1
b[4]=0.2
b[5]=0.3
weights = Variable(b)
weights=weights.view(1,2,3)
'''
weights: tensor([[[0.1000, 0.2000, 0.3000]
[0.1000, 0.2000, 0.3000]]])
'''
y=F.conv1d(x, weights, padding=0)
'''
y: tensor([[[ 6.4000, 7.6000, 8.8000, 10.0000, 11.2000, 12.4000]]])
'''
y
tensor([[[ 6.4000, 7.6000, 8.8000, 10.0000, 11.2000, 12.4000]]])
2.2 使用nn库中的Conv1d
在深度学习中,滤波器的初始权重并没有多大意义,因此,初始权重采用随机数和权重共享的方式,不必设定权重的值,而nn.Conv1d正是为了达到此目的而产生的。
用法:
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
参数:
-
in_channel:输入的通道数,信号一般为一维
-
out_channel:输出的通道数
-
kernel_size:卷积核的大小
-
stride:步长
-
padding:0填充
import time
import torch
import torch.nn as nn
'''
Description: torch.nn.Conv1d
input:(batch_size,in_channel,length)
output:(batch_size,out_channel,length)
shape of kernel:(channel*kernel_size)
out_channel :the num of kernel--> how much kernel do you need?
'''
#(batch_size,in_channel,length)
input =torch.ones(1,1,6)
print(input)
model =nn.Conv1d(in_channels=1,
out_channels=1,#可以设定多个滤波器,共享权重
kernel_size=3,
padding=0)
# (batch_size,out_channel,length)
output =model(input)
print(output)
tensor([[[1., 1., 1., 1., 1., 1.]]])
tensor([[[-0.2018, -0.2018, -0.2018, -0.2018]]],
grad_fn=<ConvolutionBackward0>)
import time
import torch
import torch.nn as nn
'''
Description: torch.nn.Conv1d
input:(batch_size,in_channel,length)
output:(batch_size,out_channel,length)
shape of kernel:(channel*kernel_size)
out_channel :the num of kernel--> how much kernel do you need?
'''
#(batch_size,in_channel,length)
input =torch.ones(1,1,6)
print(input)
model =nn.Conv1d(in_channels=1,
out_channels=2,#可以设定多个滤波器,共享权重
kernel_size=3,
padding=0)
# (batch_size,out_channel,length)
output =model(input)
print(output)
tensor([[[1., 1., 1., 1., 1., 1.]]])
tensor([[[-1.4254, -1.4254, -1.4254, -1.4254],
[ 0.4811, 0.4811, 0.4811, 0.4811]]],
grad_fn=<ConvolutionBackward0>)
import time
import torch
import torch.nn as nn
'''
Description: torch.nn.Conv1d
input:(batch_size,in_channel,length)
output:(batch_size,out_channel,length)
shape of kernel:(channel*kernel_size)
out_channel :the num of kernel--> how much kernel do you need?
'''
#(batch_size,in_channel,length)
input =torch.ones(4,2,6)
print(input)
model =nn.Conv1d(in_channels=2,
out_channels=4,#可以设定多个滤波器,共享权重
kernel_size=3,
padding=0)
# (batch_size,out_channel,length)
output =model(input)
print(output)
tensor([[[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]]])
tensor([[[-0.4742, -0.4742, -0.4742, -0.4742],
[ 1.0267, 1.0267, 1.0267, 1.0267],
[-0.8237, -0.8237, -0.8237, -0.8237],
[ 0.2031, 0.2031, 0.2031, 0.2031]],
[[-0.4742, -0.4742, -0.4742, -0.4742],
[ 1.0267, 1.0267, 1.0267, 1.0267],
[-0.8237, -0.8237, -0.8237, -0.8237],
[ 0.2031, 0.2031, 0.2031, 0.2031]],
[[-0.4742, -0.4742, -0.4742, -0.4742],
[ 1.0267, 1.0267, 1.0267, 1.0267],
[-0.8237, -0.8237, -0.8237, -0.8237],
[ 0.2031, 0.2031, 0.2031, 0.2031]],
[[-0.4742, -0.4742, -0.4742, -0.4742],
[ 1.0267, 1.0267, 1.0267, 1.0267],
[-0.8237, -0.8237, -0.8237, -0.8237],
[ 0.2031, 0.2031, 0.2031, 0.2031]]],
grad_fn=<ConvolutionBackward0>)
3. 二维卷积
3.1 nn.functional.conv2d
卷积的方式有多种,主要区别在于卷积核与图像矩阵边界匹配的方式和加权求和后值的位置分配不同,下图尽通过一组图来展示卷积的过程。

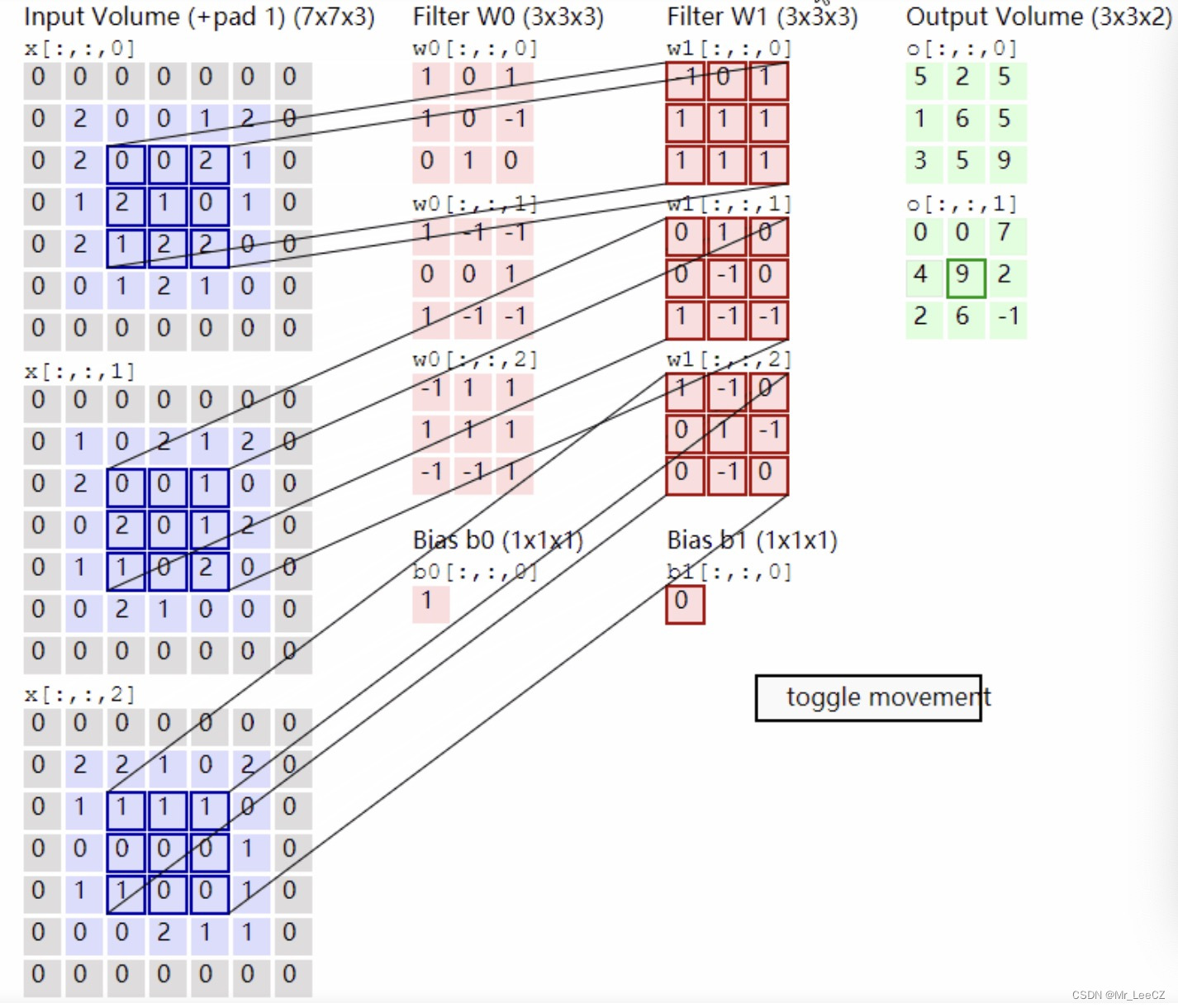
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
其中input代表的是输入图像/矩阵(这里限制输入必须是以[minibatch,channel,H,W]这样的shape输入)
weight代表的是卷积核(同样是要求以上面的shape输入)
stride代表的是卷积核在输入图像上移动的步长
padding代表的是进行卷积之前是否对输入图像进行边缘填充(默认不填充)
import torch
import torch.nn.functional as F
#卷积操作
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
print(input) # [5,5]
print('\n', kernel) # [3,3]
input = torch.reshape(input, (1, 1, 5, 5)) # (batch, channal, width, heiht)
kernel = torch.reshape(kernel, (1, 1, 3, 3)) # (batch, channal, width, heiht)
# stride=1,卷积核每次移动一个元素
output1 = F.conv2d(input, kernel, stride=1)
print("\n stride=1,不进行padding,卷积操作后:")
print(output1) # (5-3+2*0)/1 + 1 = 3
# padding=1, 边界填充一格,元素设置为0,扩充完之后是一个7*7的矩阵
output2 = F.conv2d(input, kernel, stride=1, padding=1)
'''
[[0,0,0,0,0,0,0]
[0,1,2,0,3,1,0],
[0,0,1,2,3,1,0],
[0,1,2,1,0,0,0],
[0,5,2,3,1,1,0],
[0,2,1,0,1,1,0]
[0,0,0,0,0,0,0]]
'''
print("\n stride=1,padding=1,卷积操作后:")
print(output2) # (5-3+2*1)/1 + 1 = 5
# stride=2,卷积核每次移动2个元素
output3 = F.conv2d(input, kernel, stride=2)
print("\n stride=2,不进行padding,卷积操作后:")
print(output3) # (5-3+2*0)/2 + 1 = 2
tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
stride=1,不进行padding,卷积操作后:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
stride=1,padding=1,卷积操作后:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
stride=2,不进行padding,卷积操作后:
tensor([[[[10, 12],
[13, 3]]]])
3.2 nn.Conv2d
深度学习中一般不需要刻意设定卷积核的权重,可以使用nn.Conv2d,将关注点放在输入和输出上的数目上。
函数:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
import torch
x = torch.randn(3,1,5,4) # [batch, channel, height, width]
print('3 批数据单通道矩阵:')
print(x)
conv = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=(2,3), stride=1, padding=0)
res = conv(x) # (5-2+2*0)/1+1 =4; (4-3+2*0)/1+1=2
print(res.shape) # torch.Size([3, 4, 4, 2])
3 批数据单通道矩阵:
tensor([[[[-0.2597, -0.2103, 0.0358, -1.0163],
[ 0.9965, 0.0855, -0.7477, -1.5901],
[ 2.2799, -1.1986, -2.2921, -0.8996],
[ 1.2546, -0.2645, -0.0734, 2.1464],
[ 0.4333, -1.4566, 1.4044, 0.9502]]],
[[[-0.5962, -0.0100, 1.2836, 1.5562],
[ 0.7060, 0.9727, 0.3383, -0.8690],
[ 0.2354, 0.2068, -1.1025, 2.9323],
[-0.8895, -0.9010, 1.4417, -0.3452],
[ 1.3244, 1.5612, -2.3033, 0.5028]]],
[[[ 1.3851, -0.9373, 1.4245, 0.9449],
[-1.7409, -1.2329, 0.4447, 0.8167],
[ 1.4936, -0.2248, 1.3076, -1.7958],
[ 1.2098, 0.6465, 0.0848, 0.8640],
[-0.0291, -0.3277, 2.0227, -0.7025]]]])
torch.Size([3, 4, 4, 2])