以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 14 章 InfluxDB仪表盘
14.1 什么是InfluxDB仪表盘
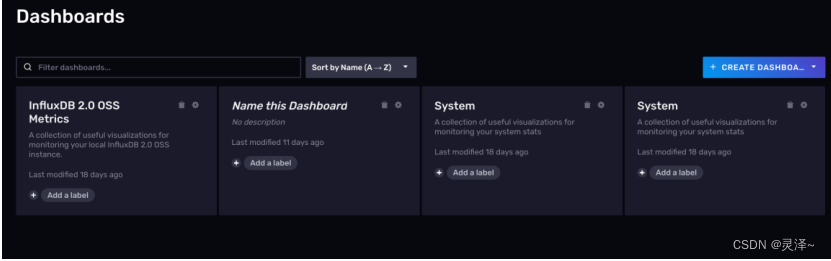
1、前面已经给大家介绍过InfluxDB的仪表盘功能了。点击左侧的 按钮,可以进入 InfluxDB的仪表盘管理页面。可以看到仪表盘的管理页面,如下图所示:
2、我这里打开一个System仪表盘,注意,这个仪表盘中的内容依赖我们之前做的示例 2 。
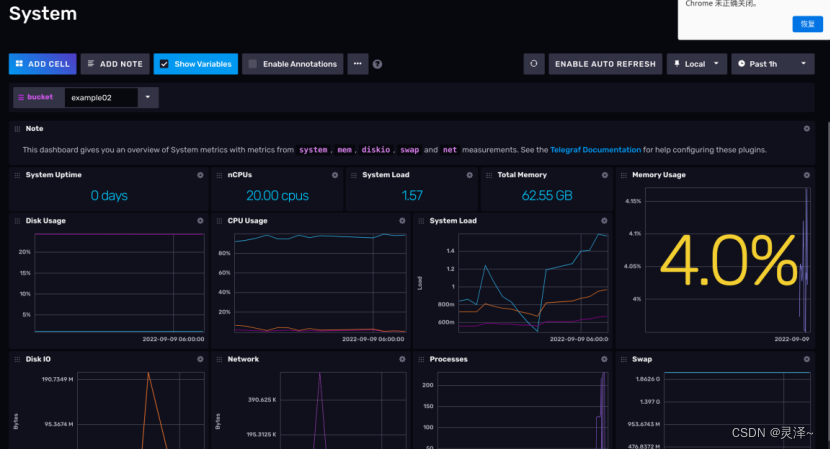
3、这是一个监控主机硬件与网络资源的仪表盘。仪表盘中的每个 Cell其实都是一个FLUX查询语句,通过执行FLUX获取数据结果,再使用UI将它展示为各类图表。在你打开仪表盘的一瞬间,InfluxDB就会执行这些查询。
14.2 仪表盘控件
14.2.1 手动刷新
1、右上方的 按钮,点击一次可以重新执行一轮仪表盘中的查询。因为通常的FLUX 脚本都是查询距当前一段时间的数据,所以刷新的功能还是比较必要的。
14.2.2 开启自动刷新
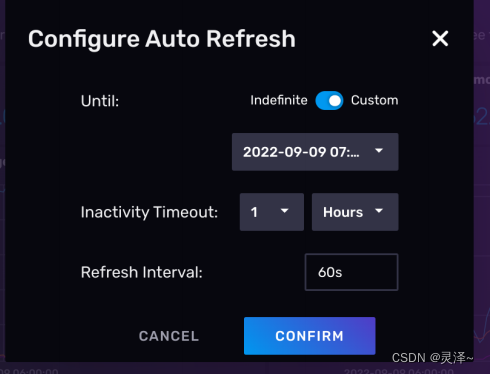
1、 右上方的 按钮,可以开启仪表盘的自动刷新
14.2.3 切换显示时区
1、Local按钮,可以选择将当前的日期时间显示为当前时区还是UTC。
14.2.4 设定查询范围
1、指定查询过去多长一段时间的数据。

14.2.5 添加一个Cell
1、Cell就是仪表盘中多个的图形的一个图形。添加图形对应的是左上角ADD CELL按钮。

14.2.6 添加一个Note
1、一个Note也是仪表盘中的一个模块,支持Markdown语法。对应左上角ADD NOTE按钮。

14.2.7 显示变量
1、如果仪表盘中包含涉及到变量的查询,那么在仪表盘的顶部会出现一个下拉菜单,通过下拉菜单这一指定变量的值,从而操作仪表盘展示响应数据。对应左上角的 Show Variables。

14.2.8 开启注解
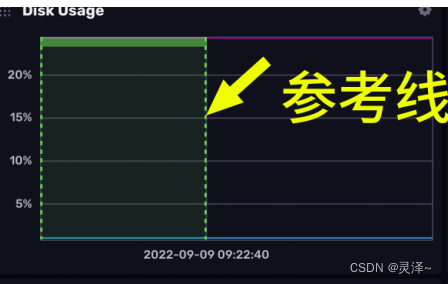
1、你可以按住shift和鼠标左键,在仪表盘的图示上添加参考线。打开个关闭注解会影响参考线的可见性。
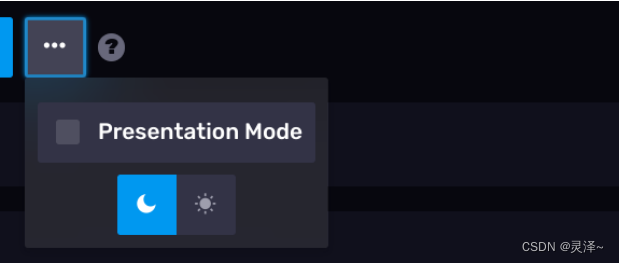
14.2.9 全屏和黑夜模式
1、此功能在左上角的按钮,如图所示:
14.3 示例:制作可交互的动态仪表盘
1、本示例要对CPU使用情况的相关指标制作仪表盘,这依赖于示例 2 。请在完成示例 2的基础上完成改示例。
14.3.1 需求
1、用户希望我们的仪表盘上能加入一个下拉菜单以选择查看哪个CPU的使用情况。要监控的指标是useage_user,仪表盘上要显示每 1 分钟,CPU使用率的最大值、最小值和中位数。
14.3.2 创建变量
1、这里先不解释为什么创建变量。鼠标悬停在左侧的【扳手图案】按钮,在弹出栏上选择Variables。如图所示:

2、点击右上角CREATE VARIABLES按钮,选择New Variable,会弹出一个创建变量的对话框。在右上角的Type为Query的前提下,在脚本编辑区键入以下内容:
import "influxdata/influxdb/schema"
schema.tagValues(bucket: "example02",tag:"cpu")
3、解释:这个脚本可以查询出example02存储桶中的cpu标签有哪些标签值。左上角需要给变量指定一个名称,这里我输入的是CPU。
14.3.3 创建新的仪表盘
1、回到仪表盘管理页面,点击CREATE DASHBOARD按钮,创建一个新的仪表盘。
2、点击左上角的ADD CELL按钮。
14.3.4 创建新的cell
1、可以看到,又出现了我们熟悉的DataExplorer。进入后直接切换到SCRIPT EDITOR。键入以下内容。
basedata = from(bucket: "example02")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
|> filter(fn: (r) => r["cpu"] == v.CPU)
basedata
|> aggregateWindow(every: 1m, fn: median, createEmpty: false)|> yield(name: "median")
basedata
|> aggregateWindow(every: 1m, fn: max, createEmpty: false)
|> yield(name: "max")
basedata
|> aggregateWindow(every: 1m, fn: min, createEmpty: false)
|> yield(name: "min")
2、点击SUBMIT查看效果。
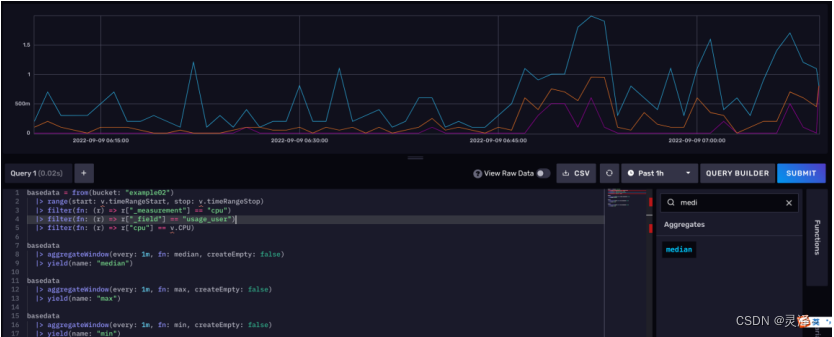
14.3.5 优化展示效果
1、默认的可视化类型为Graph,我们现在将它切换为Band,表示带有边界的折线图。
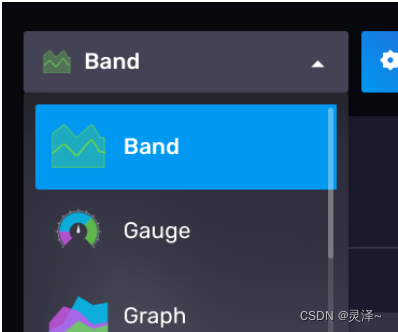
2、切换图形后,点击CUSTOMIZE,进行自定义设置。有一栏是Aggregate Functions,在这里分别指定 Upper Column Name为max。MainColumn Name为median,Lower Column Name 为min。这就是有边界的折线图的效果。最后,点击右上角的对号保存。
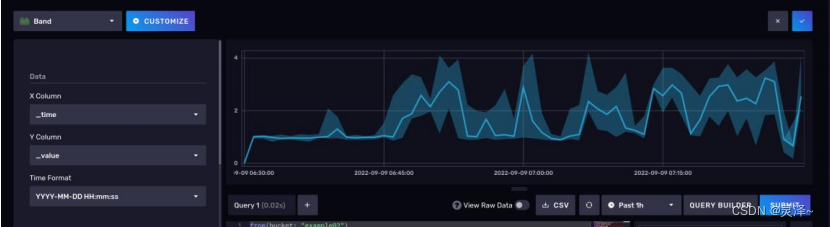
14.3.6 查看效果
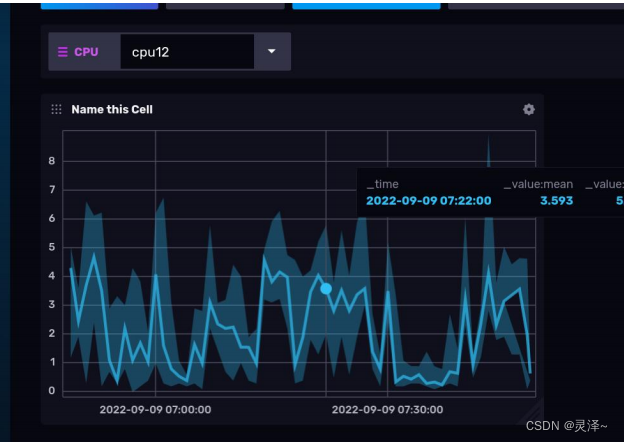
1、可以看到,在仪表盘的顶部出现了一个名为CPU的下拉菜单,通过这个下拉菜单,我们可以控制整个仪表盘,但前提是cell对应的FLUX查询语句引用了我们设置的变量 v.CPU。

2、使用下拉菜单选择不同的CPU,可以显示对应的数据。
14.4 示例:更加灵活的变量与仪表盘
14.4.1 需求
1、 在上一个示例中,我们可以通名为CPU的变量对仪表盘中展示的序列进行动态的调整。但是上一个示例中的仪表盘还有一个缺陷。如图所示,我们每次只能展示一个序列,但是如果我们想对比两个CPU的性能差别呢?这个时候上一个示例做出的仪表盘就不够用了。
2、现在,我们希望仪表盘中能够同时显示两个CPU到的工作状况,方便我们在视觉上进行对比。
14.4.2 创建变量
1、在左侧的工具栏点击Settings->Variables按钮。进入到变量的配置页面
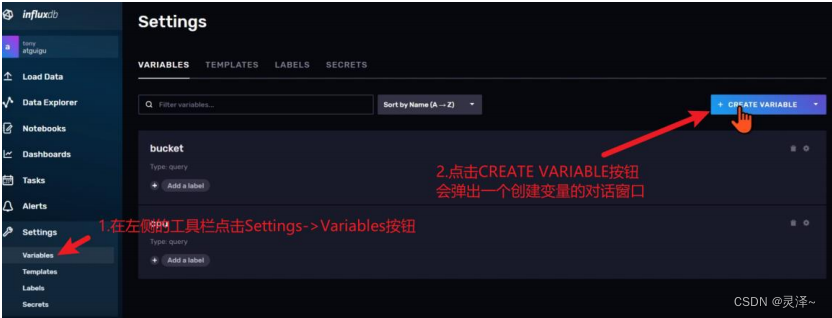
2、点击页面右上角的CREATE VARIABLE按钮。Web UI上会弹出一个创建变量的 对话窗。
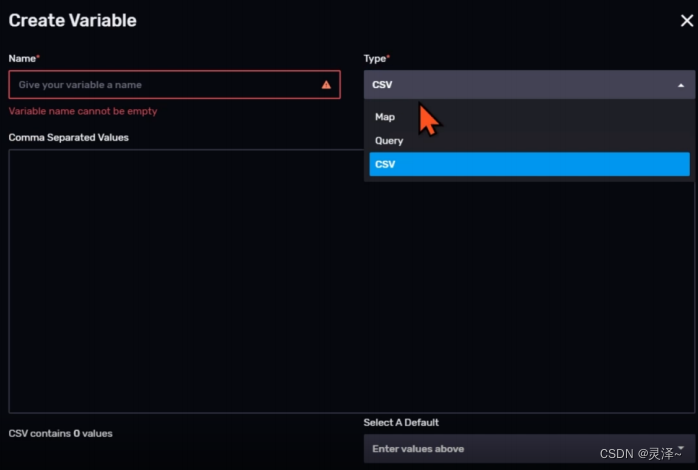
3、在右上角的Type下拉菜单中选择CSV。(上一个示例中我们创建的是Query类型,Query类型的变量可以根据数据的状况进行动态的变化。但是另外的Map类型和CSV类型不行,它们是静态的,如果想让其中的值发生改变,除非再次通过API或者Web UI
对其值进行手动的调整)
4、在左上角给变量起好名字,在演示中,我们将变量名设为cpuxxx。

5、中间的主要区域是用来设置变量的值的,这里可以使用CSV格式,但却没有必要非要按照行列的方式来组织这些值。这里的 CSV格式其实只是要求你用,(英文逗号)来分隔值。其实这个地方也能用换行的方式来分隔值,如图所示,我这里用的是换行分隔的方式。
6、此处,我们将值设为cpu0、cpu 1 、cpu2、cpu3和cpu1|cpu 2 。注意!此处的cpu1|cpu2是正则表达式写法,表示cpu1或者cpu2。
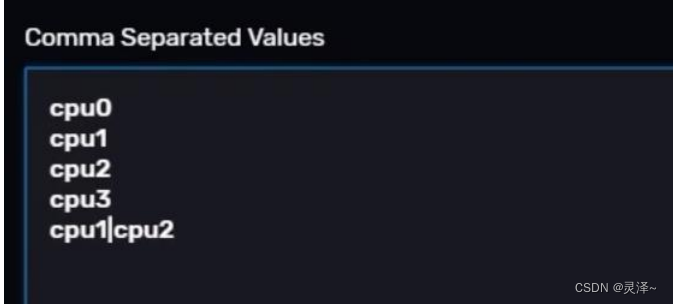
7、左下角会实时显示你当前给变量cpuxxx设了几种取值。
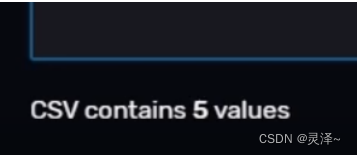
8、在右下角有一个Select A Default下拉菜单,它可以给我们的变量设置一个默认值。此处可以将默认值设为cpu0。至此,我们的cpuxxx就创建好了。

14.4.3 修改FLUX脚本(添加正则过滤)
1、首先,如图所示,先点击齿轮按钮,再在弹出的菜单中点击Configure按钮,就可以修改当前的Cell了。
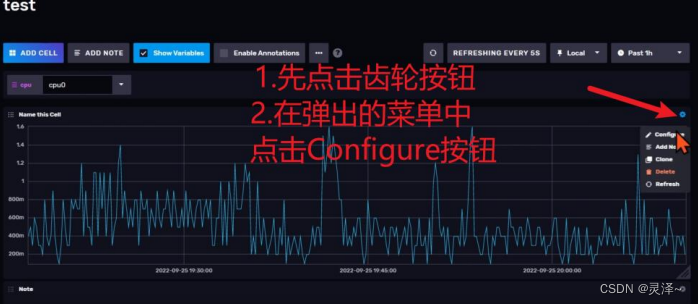
2、现在,我们需要对上一个示例中的查询脚本作一些修改。在 filter中去添加一个蒸锅cpuxxx的取值进行正则过滤的方法。
下面是我们的最终脚本,此处我们就不展示数据的最大值和最小值了。红色的部分是我们需要额外注意的。
basedata = from(bucket: "example02")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_user")
|> filter(fn: (r) =>
regexp.matchRegexping(r:regexp.compile(v:v.cpuxxx),v:r["cpu"])
3、代码解释:
- regexp.compile(v:v.cpuxxx):需要注意,我们在 InfluxDB中设置的变量的类型始终都是字符串类型,所以要进行正则匹配的话必须先把字符串转成正则表达式。regexp包下的compile函数就是专门用来将字符串转为正则表达式的。
- regexp.matchRegexpString:用来判断字符串能否与正则表达式匹配。如果可以匹配上,那么该函数就会返回true,如果匹配不上,那么就会返回false。
- 这样的话,当我们将变量cpuxxx的值置为cpu1|cpu2时,就可以同时展示出我们想要的两个序列了。
4、最终,点击右上角的√按钮保存修改后的cell。
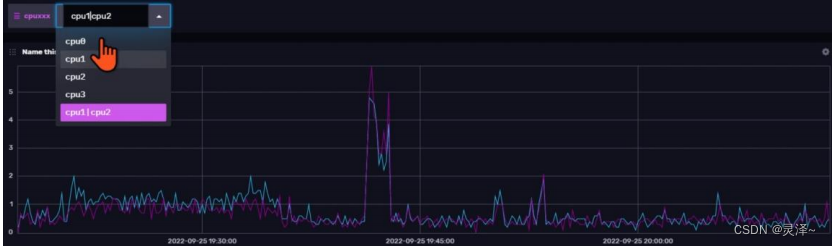
14.4.4 查看最终效果
1、回到仪表盘后,可以看到,最上方的变量下拉菜单已经从cpu变成了cpuxxx,这说明仪表盘会自动判断内部的cell用到了哪些变量并做出相应的调整。如下图所示,这就是修改后的效果。
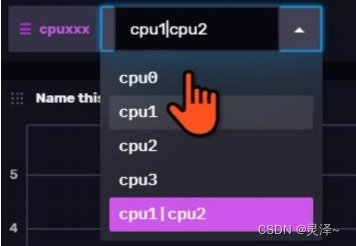
2、此时,选择cpu1|cpu2,就可以看到之前的cell里面会出现两条序列了。