非原创,在学习
目录
2 构造函数语意学(The Semantics of Constructors)
2.1 Default Constructor的构建操作
“带有Default Constructor”的Member Class Object
“带有Default Constructor”的Base Class
“带有一个Virtual Function”的Class
“带有一个Virtual Base Class”的Class
总结
2.2 Copy Constructor 的建构操作
default memberwise initialization
Bitwise Copy Semantics
不要 Bitwise Copy Semantics
重新设定Virtual Table 的指针
处理Virtual Base Class Subobject
2.3 程序转化语意学(Program Transformation Semantics )
明确的初始化操作(Explicit Initialization )
参数的初始化(Argument Initialization )
返回值的初始化(Return Value Initialization )
在使用者层面做优化( Optimization at the User Level )
在编译器层面做优化( Optimization at the Compiler Level)
Copy Constructor:要还是不要?
摘要
2.4成员们的初始化队伍(Member Initialization List )
2 构造函数语意学(The Semantics of Constructors)
一个案例:
if (cin) ...为了让 cin 能够求得一个真假值,Jerry首先为它定义一个conversion运算符: operator int()。在良好行为如上者,这的确可以正确运行。但是在下面这种错误的程序设计中,它的行为就势必令人大吃一惊了:
// 应该是cout,而不是cin
cin << intVal;这里应该是cout,而不是cin。
在此例中,内建的左移位运算符(left shift operator,<<)只有在“cin可改变为和一个整数值同义”时才适用。编译器会检查可以使用的各个conversion运算符,然后它找到了operator int(),那正是它要的东西.左移位运算符现在可以操作了;如果没有成功、至少也是合法的:
int temp = cin.operator int();
temp << intVal;关键词explicit之所以被导人这个语言,就是为了提供给程序员一种方法,使他们能够制止“单一参数的constructor”被当做一个conversion运算符。
2.1 Default Constructor的构建操作
案例
class Foo {public: int val; Foo* pnext;};
class foo_bar {
Foo bar;
// val和pnext都为0
if (bar.val || bar.pnext) {
// do something
}
};默认构造函数初始化成员变量位0
那么,什么时候才会合成出一个default constructor呢?当编译器需要它的时候!此外,被合成出来的 constructor只执行编译器所需的行动。也就是说,即使有需要为class Foo合成一个default constructor,那个constructor也不会将两个data members val和 pnext初始化为0。为了让上一段码正确执行,class Foo 的设计者必须提供一个明显的 default constructor,将两个members适当地初始化。
即:
对于class X,如果没有任何user-declared constructor,那么会有一个defaultconstructor被暗中( implicitly)声明出来……一个被暗中声明出来的defaultconstructor将是一个trivial(浅薄而无能,没啥用的) constructor…
下面的四小节分别讨论nontrivial default constructor的四种情况:
“带有Default Constructor”的Member Class Object
如果一个class没有任何 constructor,但它内含一个member object,而后者有default constructor ,那么这个class的implicit default constructor就是“nontrivial”,编译器需要为此 class合成出一个default constructor。不过这个合成操作只有在constructor真正需要被调用时才会发生。
这段话描述的很清楚:如果一个类没有任何的构造函数,但是有成员变量,这个成员变量是复合类型(即成员对象),且这个成员对象有自己默认的构造函数,那么这个类的隐式默认构造函数就是有用的,编译器会自动为该类合成一个默认的构造函数。
案例
class Foo {
public:
Foo(); // 无参构造函数
Foo(int); // 有参构造函数
};
class Bar {
public:
Foo foo; // 是内含,不是继承
char* str;
};
void foo_bar() {
Bar bar; // Bar::foo必须在此初始化
// Bar类中包含Foo类的对象,符合本小节主题
if (str) {
}
}Bar的default constructor内含必要的代码,能够调用Foo 类的default constructor来处理member object Bar::foo,但它并不产生任何码来初始化Bar::str。是的,将 Bar:.foo初始化是编译器的责任,将 Bar::str初始化则是程序员的责任。被合成的 default constructor看起来可能像这样。
// Bar的默认构造函数可能会被这样合成
// 被成员foo调用Foo类的默认构造函数
inline Bar::bar() {
// C++伪代码
foo.Foo::Foo();
}再一次请你注意,被合成的default constructor只满足编译器的需要,而不是程序的需要。为了让这个程序片段能够正确执行,字符指针 str也需要被初始化,让我们假设程序员经由下面的 default constructor提供了str的初始化操作:
// 程序员定义的默认构造函数
Bar::Bar() {str = 0;}编译器的行动是:“如果class A内含一个或一个以上的member class objects,那么class A 的每一个constructor必须调用每一个member classes的default constructor”。编译器会扩张已存在的 constructors,在其中安插一些码,使得user code在被执行之前,先调用必要的 default constructors.沿续前一个例子,扩张后的constructors可能像这样:
// 扩张后的默认构造函数
// C++伪码
Bar::Bar() {
foo.Foo::foo(); // 附加上的编译器代码
str = 0; // 显示程序员代码
}如果有多个class member objects都要求constructor初始化操作,将如何呢?
C+语言要求以“member objects在 class中的声明次序”来调用各个constructors。这一点由编译器完成,它为每一个constructor安插程序代码,以“member声明次序”调用每一个member所关联的 default constructors。这些码将被安插在explicit user code 之前。举个例子,假设我们有以下三个classes:
class Dopey {public: Dopey(); };
class Sneezy {public: Sneezy(int); Sneezy() };
class Bashful {public: Bashful(); };以及一个Snow_White类
class Snow_White {
public:
// dopey、sneezy、bashful是三个成员对象
Dopey dopey;
Sneezy sneezy;
Bashful bashful;
// ...
private:
int mumble;
};如果Snow_White没有定义default constructor ,就会有一个nontrivial constructor被合成出来,依序调用Dopey、Sneezy、Bashful 的default constructors,然而如果Snow_White定义了下面这样的 default constructor:
// 程序员所写的默认构造函数
Snow_White::Snow_White() : sneezy(1024) {
mumble = 2048;
}它会被扩张为:
// 编译器扩张后的默认构造函数
// C++伪码
Snow_White::Snow_Whie() : sneezy(1024) {
// 插入类成员对象,调用构造函数
dopey.Dopey::Dopey();
sneezy.Sneezy::Sneezy(1024);
bashful.Bashful::Bashful();
// 显示代码
mumble = 2048;
}完整案例:
#include <iostream>
// Dopey类
class Dopey {
public:
// 无参构造
Dopey() {
std::cout << "The constructor of Dopey has been called" << std::endl;
}
};
// Sneezy类
class Sneezy {
public:
// 有参构造
Sneezy(int num) {
std::cout << "The constructor of Sneezy(int) has been called" << std::endl;
}
// 无参构造
Sneezy() {
std::cout << "The constructor of Sneezy has been called" << std::endl;
}
};
// Bashful类
class Bashful {
public:
// 无参构造
Bashful() {
std::cout << "The constructor of Bashful has been called" << std::endl;
}
};
// Snow_White类
class Snow_White {
public:
// 无参构造,成员列表初始化
Snow_White():mumble(1024) {
std::cout << "The mumble = " << mumble << std::endl;
}
Snow_White(int num):sneezy(num), mumble(num) {
std::cout << "The mumble = " << mumble << std::endl;
}
private:
Dopey dopey;
Sneezy sneezy;
Bashful bashful;
int mumble;
};
int main(int argc, char** argv) {
Snow_White snowWhite1;
std::cout << "----------------------------------------------------------" << std::endl;
Snow_White snowWhite2(2048);
system("pause");
return 0;
} 结果

“带有Default Constructor”的Base Class
类似的道理,如果一个没有任何constructors 的class派生自一个“带有default constructor”的 base class,那么这个derived class 的 default constructor会被视为nontrivial,并因此需要被合成出来。它将调用上一层base classes的default constructor(根据它们的声明次序)﹒对一个后继派生的 class而言,这个合成的 constructor和一个“被明确提供的 default constructor”没有什么差异。
如果设计者提供多个constructors,但其中都没有default constructor呢?编译器会扩张现有的每一个constructors,将“用以调用所有必要之defaultconstructors”的程序代码加进去.它不会合成一个新的 default constructor,这是因为其它“由user所提供的 constructors”存在的缘故。如果同时亦存在着“带有default constructors”的member class objects,那些default constructor也会被调用——在所有base class constructor都被调用之后。
案例:
#include <iostream>
class Animal {
public:
Animal() {
std::cout << "The constructor's of Animal has been called" << std::endl;
}
Animal(int data):data(data) {
std::cout << "The constructor's of Animal has been called, data = " << data << std::endl;
}
public:
int data;
};
class Cat: public Animal {
};
int main(int argc, char** argv) {
Cat cat;
system("pause");
return 0;
} 结果

“带有一个Virtual Function”的Class
另有两种情况,也需要合成出 default constructor:
1. class声明(或继承)一个virtual function.
2. class 派生自一个继承串链,其中有一个或更多的 virtual base classes.
案例
#include <iostream>
class Widget {
public:
virtual void flip() = 0; // 纯虚函数,抽象类
// ...
};
void flip(Widget& widget) {
widget.flip();
}
class Bell: public Widget {
public:
virtual void flip() {
std::cout << "Bell's flip" << std::endl;
}
};
class Whistle: public Widget {
public:
virtual void flip() {
std::cout << "Whistle's flip" << std::endl;
}
};
// Bell和Whistle都派生自Widget
void foo() {
Bell b;
Whistle w;
flip(b);
flip(w);
}
int main(int argc, char** argv) {
foo();
system("pause");
return 0;
} 结果

下面两个扩张操作会在编译期间发生:
1.一个virtual function table (在 cfront中被称为vtbl)会被编译器产生出来,内放class 的virtual functions地址.
2.在每一个class object中,一个额外的 pointer member (也就是vptr)会被编译器合成出来,内含相关的class vtbl 的地址.
“带有一个Virtual Base Class”的Class
Virtual base class的实现法在不同的编译器之间有极大的差异.然而,每一种实现法的共通点在于必须使virtual base class在其每一个derived class object 中的位置,能够于执行期准备妥当.例如下面这段程序代码中:
#include <iostream>
class X {
public:
X() {
std::cout << "The constructor of X has been called" << std::endl;
}
int i;
};
class A: public virtual X {
public:
int j;
A() {
std::cout << "The constructor of A has been called" << std::endl;
}
};
class B: public virtual X {
public:
double d;
B() {
std::cout << "The constructor of B has been called" << std::endl;
}
};
class C: public A, public B {
public:
int k;
};
void foo(A* pa) {
pa->i = 1024;
}
int main(int argc, char** argv) {
foo(new A);
foo(new C);
system("pause");
return 0;
} 结果

这里结果就不分析了,很简答。
总结
有四种情况,会导致“编译器必须为未声明constructor 之 classes合成--个default constructor”.
C++ Stardand 把那些合成物称为implicit nontrivial defaultconstructors。被合成出来的constructor只能满足编译器(而非程序)的需要.它之所以能够完成任务,是借着“调用member object 或 base class 的 defaultconstructor”或是“为每一个object初始化其virtual function 机制或virtual baseclass机制”而完成。至于没有存在那四种情况而又没有声明任何constructor的classes,我们说它们拥有的是implicit trivial default constructors,它们实际上并不会被合成出来.
在合成的 default constructor中,只有base class subobjects和member classobjects 会被初始化、所有其它的 nonstatic data member,如整数、整数指针、整数数组等等都不会被初始化.这些初始化操作对程序而言或许有需要,但对编译器则并非必要。如果程序需要一个“把某指针设为0”的 default constructor,那么提供它的人应该是程序员.
C++新手一般有两个常见的误解:
1、任何class如果没有定义default constructor,就会被合成出一个来。
2.编译器合成出来的 default constructor会明确设定“class内每一个data member的默认值”.
如你所见,没有一个是真的!
2.2 Copy Constructor 的建构操作
有三种情况调用拷贝构造函数
(1)当用类的一个对象去初始化该类的另一个对象时,系统会自动调用拷贝构造函数;
(2)将一个对象作为实参传递给一个非引用类型的形参,系统会自动调用拷贝构造函数;
(3)从一个返回类为非引用的函数返回一个对象时,系统会自动调用拷贝构造函数;
详见:c++中拷贝构造函数被调用的时机_c++拷贝构造函数什么时候调用_StudyWinter的博客-CSDN博客
default memberwise initialization
(默认的成员初始化)
如果class没有提供一个explicit copy constructor又当如何?当class object以“相同class的另一个oejest”作为初值时,其内部是以所谓的default memberwise initialization手法完成的,也就是把每一个内建的或派生的 data member(例如一个指针或一数目组(数组?))的值,从某个object 拷贝一份到另一个object身上。不过它并不会铐贝其中的member class object,而是以递归的方式施行memberwise inicializaion.例如,考虑下面这个class声明:
class {
public:
// ...没有明确的拷贝构造函数
private:
char* str;
int len;
};一个String对象的默认成员初始化发生在这种情况下
String noun("book");
String verb = noun;其完成方式就好像个别设定每一个member一样
// 语意相等
verb.str = noun.str;
verb.len = noun.len;如果一个String对象被声明为另一个class的member,像这样
class Word {
public:
// ...没有明确的拷贝构造函数
private:
int _occurs;
String _word; // String对象成为Word类中的一个成员
};那么一个Word object 的 default memberwise initialization会拷贝其内建的member _occurs,然后再于String member object _word身上递归实施member wise initialization.
一个class object 可以从两种方式复制得到,一种是被初始化(也就是我们这里所关心的),另一种是被指定( assignment,第5章讨论之)。从概念上而言,这两个操作分别是以copy constructor和 copy assignment operator完成的。
就像default constructor一样,C++ Standard 上说,如果 class没有声明一个copy constructor,就会有隐含的声明( implicitly declared)或隐含的定义( implicitly defined)出现。和以前一样,C++ Standard把 copy constructor区分为 trivial和nontrivial两种.只有nontrivial 的实体才会被合成于程序之中.决定一个copyconstructor是否为trivial的标准在于class是否展现出所谓的“bitwise copy semantics”
Bitwise Copy Semantics
(位逐次拷贝)
在下面程序片中
#include "Word.h"
Word noun("book");
void foo() {
Word verb = noun;
// ...
}根据noun初始化verb。但是在尚未看过class Word 的声明之前,我们不可能预测这个初始化操作的程序行为.如果 class Word 的设计者定义了一个copy constructor,verb 的初始化操作会调用它.但如果该class没有定义explicit copy constructor,那么是否会有一个编译器合成的实体被调用呢?这就得视该class是否展现“bitwise copy semantics”而定。举个例子,已知下面的classWord声明:
// 以下声明展现了位逐次拷贝
class Word {
public:
Word(const char*);
~Word() {delete []str;}
// ...
private:
int cnt;
char* str;
};这种情况下并不需要合成出一个默认构造函数,因为上述声明展现了【默认拷贝语意】,而verb的初始化操作也就不需要以一个函数调用收场。
如果class Word是这样声明的:
// 以下声明并未展现出默认拷贝语意
class Word {
public:
Word(const String&) {};
~Word();
// ...
private:
int cnt;
String str;
};其中,String声明了一个明确的拷贝构造函数
class String {
public:
String(const char*);
String(const String&);
~String();
// ...
};在这种情况下,编译器必须合成出一个拷贝构造函数以便调用String类对象的拷贝构造函数:
这种情况是指一个类中有一个类对象成员,而该类对象成员中有指针变量,同时该类有构造函数
// 一个被合成出来的拷贝构造函数
// C++伪码
inline Word::Word(const Word& wd) {
str.String::String(wd.str);
cnt = wd.cnt;
}有一点很值得注意:在这被合成出来的copy constructor中,如整数、指针、数组等等的nonclass members也都会被复制。
不要 Bitwise Copy Semantics
什么时候一个class不展现出“bitwise copy semantics”呢?有四种情况:
1.当class内含一个member object,而后者的 class声明有一个copy constructor时(不论是被class设计者明确地声明,就像前面的 String那样;或是被编译器合成,像class Word那样)。
2.当class继承自一个base class而后者存在有一个copy constructor时(再次强调,不论是被明确声明或是被合成而得)。
3. 当class声明了一个或多个virtual functions时。
4.当class派生自一个继承串链,其中有一个或多个virtual base classes时。
重新设定Virtual Table 的指针
回忆编译期间的两个程序扩张操作(只要有一个class声明了一个或多个virtual functions就会如此):
- 增加一个virtual function table ( vtbl),内含每一个有作用的virtual function 的地址。
- 将一个指向virtual function table 的指针(( vptr),安插在每一个class object内。
很显然,如果编译器对于每一个新产生的 class object的 vptr不能成功而正确地设好其初值,将导致可怕的后果。因此,当编译器导入一个vptr到 class 之中时,该class 就不再展现bitwise semantics 了。现在,编译器需要合成出一个copy constructor,以求将vptr 适当地初始化,下面是个例子。
定义两个类ZooAnimal和Bear
class ZooAnimal {
public:
ZooAnimal();
virtual ~ZooAnimal();
virtual void animate();
virtual void draw();
// ...
private:
// ZooAnimal的animate()和draw()需要的数据
};
class Bear : public ZooAnimal {
public:
Bear();
void animate(); // 虽未明写virtual,它其实是virtual
void draw(); // 虽未明写virtual,它其实是virtual
virtual void dance();
// ...
private:
// Bear的animate()和draw()和dance()需要的数据
};ZooAnimal class object以另一个 ZooAnimal class object作为初值,或Bear class object以另一个Bear class object作为初值,都可以直接靠“bitwise copysemantics”完成(除了可能会有的 pointer member之外。为了简化,这种情况被先不考虑),举个例子:
Bear yogi;
Bear winnie = yogi;yogi会被default Bear constructor初始化,而在constructor 中, yogi 的 vptr被设定指向Bear class 的 virtual table(靠编译器安插的码完成)。因此,把 yogi的vptr值拷贝给winnie 的 vptr是安全的。

当一个base class object以其derived class 的object内容做初始化操作时,其vptr复制操作也必须保证安全,例如:
ZooAnimal franny = yogi; // 发生切割franny的 vptr不可以被设定指向Bear class的 virtual table(但如果yogi 的vptr被直接“bitwise copy”的话,就会导致此结果),否则当下面程序片段中的draw()被调用而franny被传进去时,就会“炸毁”( blow up):
void draw(const ZooAnimal& zoey) {zoey.draw();}
void foo() {
// franny的vptr指向ZooAnimal的virtual table
// 而非Bear的virtual table
ZooAnimal franny = yogi;
draw(yogi); // 调用Bear::draw
draw(franny); // 调用ZooAnimal::draw();
}
也就是说,合成出来的 ZooAnimal copy constructor会明确设定object的vptr指向ZooAnimal class 的 virtual table,而不是直接从右手边的 class object 中将其vptr现值拷贝过来。
完整案例
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
class ZooAnimal {
public:
ZooAnimal() {
std::cout << "The constructor of ZooAnimal has been called" << std::endl;
}
virtual ~ZooAnimal() {
std::cout << "The destructor of ZooAnimal has been called" << std::endl;
}
virtual void animate() {
std::cout << "The animate of ZooAnimal has been called" << std::endl;
}
virtual void draw() {
std::cout << "The draw of ZooAnimal has been called" << std::endl;
}
// ...
private:
// ZooAnimal的animate()和draw()需要的数据
};
class Bear : public ZooAnimal {
public:
Bear() {
std::cout << "The constructor of Bear has been called" << std::endl;
}
void animate() {
std::cout << "The animate of Bear has been called" << std::endl;
}
void draw() {
std::cout << "The draw of Bear has been called" << std::endl;
}
virtual void dance() {
std::cout << "The dance of Bear has been called" << std::endl;
}
// ...
private:
// Bear的animate()和draw()和dance()需要的数据
};
void draw(ZooAnimal& zoey) {
zoey.draw();
}
void foo() {
Bear yogi;
// franny的vptr指向ZooAnimal的virtual table
// 而非Bear的virtual table
ZooAnimal franny = yogi;
draw(yogi); // 调用Bear::draw
draw(franny); // 调用ZooAnimal::draw();
}
int main() {
foo();
system("pause");
return 0;
}结果

处理Virtual Base Class Subobject
Virtual base class的存在需要特别处理.一个class object 如果以另一个object作为初值,而后者有一个virtual base class subobject,那么也会使“bitwisecopy semantics”失效。
每一个编译器对于虚拟继承的支持承诺,都表示必须让“derived class object中的virtual base class subobject位置”在执行期就准备妥当.维护“位置的完整性”是编译器的责任.“Bitwise copy semantics”可能会破坏这个位置,所以编译器必须在它自己合成出来的 copy constructor中做出仲裁。举个例子,在下面的声明中,ZooAnimal成为 Raccoon 的一个virtual base class:
class Raccoon : public virtual ZooAnimal {
public:
Raccoon() {
/*设定private data的值*/
}
Raccoon(int val) {
/*设定private data的值*/
}
// ...
private:
// 所有必要的数据
};
编译器所产生的代码(用以调用ZooAnimal 的default constructor、将Raccoon 的 vptr初始化,并定位出 Raccoon中的 ZooAnimal subobject)被安插在两个Raccoon constructors 之内,成为其先头部队.
那么"member wise初始化”呢?噢,一个virtual base class 的存在会使bitwise copy semantics无效。
其次,问题并不发生于“一个class object 以另一个同类的object作为初值”之时,而是发生于“一个class object 以其derived classes 的某个object作为初值”之时.例如,让 Raccoon object 以一个RedPanda object 作为初值,而RedPanda声明如下:
class RedPanda : public Raccoon {
public:
RedPanda() {
/*设定private data初值*/
}
ReaPanda(int val) {
/*设置private data初值*/
}
private:
// 所有必要的数据
};
如果以一个Raccoon object作为另一个Raccoon object 的初值,那么“bitwise copy”就绰绰有余了:
Raccoon rocky;
Raccoom little_critter = rocky;然而如果企图以一个RedPanda object作为little_critter的初值,编译器必须判断“后续当程序员企图存取其ZooAnimal subobject 时是否能够正确地执行”(这是一个理性的程序员所期望的):
// 简单的bitwise copy还不够
// 编译器必须明确地将little_critter的virtual base class pointer/offset初始化
RedPanda little_red;
Raccoon little_critter = little_red;在这种情况下,为了完成正确的 little_critter初值设定,编译器必须合成一个copy constructor,安插一些码以设定virtual base class pointerloffset的初值(或只是简单地确定它没有被抹消),对每一个members执行必要的 memberwise初始化操作,以及执行其它的内存相关工作.

在下面的情况中,编译器无法知道是否“bitwise copy semantics”还保持着,因为它无法知道(没有流程分析)Raccoon指针是否指向一个真正的 Raccoon object,或是指向一个derived class object:
// 简单的bitwise copy可能够用,也可能不够用
Raccoon* ptr;
Raccoon little_critter = *ptr;这里有一个有趣的问题:当一个初始化操作存在并保持着“bitwise copysemantics”的状态时,如果编译器能够保证 object有正确而相等的初始化操作,是否它应该压抑copy constructor的调用,以使其所产生的程序代码优化?至少在合成的 copy constructor之下,程序副作用的可能性是零,所以优化似乎是合理的。如果copy constructor是由class设计者提供的呢?这是一个颇有争议的题目,将在下一节结束前回来讨论之.
做个总结:我们已经看过四种情况,在那些情况下class不再保持“bitwise copy semantics”,而且default copy constructor 如果未被声明的话,会被视为是nontrivial。在这四种情况下,如果缺乏一个已声明的 copy constructor,编译器为了正确处理“以一个class object作为另一个class object的初值”,必须合成出-一-个copy constructor。下一节将讨论编译器调用copy constructor的策略,以及这些策略如何影响我们的程序
2.3 程序转化语意学(Program Transformation Semantics )
已知下面程序片段:
#include "X.h"
X foo() {
X xx;
// ...
return xx;
}一个人可能会做出以下假设:
1 每次foo()被调用,究传回xx的值;
2 如果class X定义了一个copy constructor,那么当foo()被调用的时候,保证该copy constructor也会被调用。
第一个假设的真实性,必须视 class X 如何定义而定。第二个假设的真实性,虽然也有部分必须视 class X 如何定义而定,但最主要还是视你的C++编译器所提供的进取性优化程度(degree of aggressive optimization)而定.你甚至可以假设在一个高品质的C+编译器中,上述两点对于class X 的 nontrivial definitions都不正确。以下小节将讨论其原因。
没懂
明确的初始化操作(Explicit Initialization )
已知有这样的定义:
X x0;下面有三个定义,每个都明显地以x0来初始化其类对象
void foo_bar() {
X x1(x0); // 定义了x1
X x2 = x0; // 定义了x2
X x3 = X(x0); // 定义了x3
// ...
}必要的程序转换有两个阶段:
1 重写每一个定义,其中的初始化操作会被剥削(这个所谓的“定义”是指上述的x1、x2、x3三行;在严谨的C++用词中,“定义”是指“占用内存”的行为)
2 类的拷贝构造函数调用操作会被安插进去
举例:
// 可能的程序转换
// C++伪码
void foo_bar() {
X x1; // 定义被重写,初始化操作被剥除
X x2; // 定义被重写,初始化操作被剥除
X x3; // 定义被重写,初始化操作被剥除
// 编译器安装X拷贝构造函数的调用操作
x1.X::X(x0);
x2.X::X(x0);
x3.X::X(x0);
// ...
}其中的:
x1.X::X(x0);就表现出对以下的拷贝构造函数的调用:
X::X(const X& xx);参数的初始化(Argument Initialization )
C++ Standard ( Section 8.5)说,把一个class object当做参数传给一个函数(或是作为一个函数的返回值),相当于以下形式的初始化操作:
X xx = arg;其中xx代表形式参数(或返回值),而arg代表真正的参数值,因此,若已知这个函数:
void foo(X x0);下面这样的调用方式:
X xx;
// ...
foo(xx);将会要求局部实体x0以成员逐一的方式将xx当作初值,在编译器实现技术上,有一种策略是导入所谓的暂时性object,并调用拷贝构造函数将它初始化,然后将该暂时性对象交给函数,例如前面案例:
// C++伪码
// 编译器产生出来的暂时对象
X _temp0;
// 编译器对拷贝构造函数的调用
_temp0.X::X(xx);
// 重写改写函数调用操作,以便使用上述的暂时对象
foo(_temp0);然而这样的转换只做了一半功夫而已.你看出残留问题了吗?问题出在 foo()的声明.暂时性object先以 class X 的 copy constructor正确地设定了初值,然后再以 bitwise方式拷贝到x0 这个局部实体中.噢,真讨厌,foo()的声明因而也必须被转化,形式参数必须从原先的一个class x object改变为一个class Xreference,像这样:
void foo(X& x0);其中class X声明了一个析构函数,它会在foo()函数完成之后被调用,对付那个暂时性的对象。
另一种实现方法是以“拷贝建构”( copy construct)的方式把实际参数直接建构在其应该的位置上,该位置视函数活动范围的不同记录于程序堆栈中.在函数返回之前,局部对象(local object)的 destructor (如果有定义的话)会被执行.Borland C++编译器就是使用此法,但它也提供一个编译选项,用以指定前一种做法,以便和其早期版本兼容.
返回值的初始化(Return Value Initialization )
已知下面这个函数定义:
X bar() {
X xx;
// 处理xx...
return xx;
}这其实是双阶段转换:
1 首先加上一个额外参数,类型是class object的一个reference,这个参数将用来放置被”拷贝构建“而得的返回值。
2 在return指令之前安插一个拷贝构造调用操作,以便将欲传回之object的内容当上述新增参数的初值
bar的转换如下:
// 函数转换
// 以反应出拷贝构造函数的应用
// c++伪码
void bar(X& _result) { // 加上一个额外参数
X xx;
// 编译器所产生的默认构造函数调用操作
xx.X::X();
// 处理xx...
// 编译器所产生的拷贝构造调用操作
_result.X::X(xx);
return;
}现在编译器必须转换每一个bar()调用操作,以反映其新定义。例如:
X xx = bar();将被转换为下列两个指令句
// 注意,不必实施默认构造函数
X xx;
bar(xx);有意思
而:
bar().memfunc(); // 指向bar()所传回之X类对象的memfunc()可能被转化为:
// 编译器所产生的暂时对象
X _temp0;
(bar(_temp0), _temp0).memfunc();同样道理,如果程序声明了一个函数指针,像这样
X (*pf)();
pf = bar;它必须被转化成:
void (*pf)(X&);
pf = bar;在使用者层面做优化( Optimization at the User Level )
程序员不用再写:
X bar(const T& y, const T& z) {
X xx;
// 以y和z来处理xx
return xx;
}那会要求xx被成员逐一的拷贝到编译器所产生的_result之中
X bar(const T& y, const T& z) {
return X(y, z);
}于是当bar()的定义被转换后,效率会比较高:
// c++伪码
void bar(X& _result) {
// 上行是否应为bar(X& _result, const T& y, const T& z)
_result.X::X(y, z);
return;
}__result 被直接计算出来,而不是经由copy constructor拷贝而得!不过这种解决方法受到了某种批评,怕那些特殊计算用途的 constructor可能会大量扩散.在这个层面上,class的设计是以效率考虑居多,而不是以“支持抽象化”为优先.
在编译器层面做优化( Optimization at the Compiler Level)
在一个如 bar()这样的函数中,所有的return指令传回相同的具名数值(译注: named value),因此编译器有可能自己做优化,方法是以result参数取代named return value。例如下面的 bar()定义:
X bar() {
X xx;
// ...处理xx
return xx;
}编译器把其中的xx以_result取代:
void bar(X& _result) {
// 默认构造函数被调用
// C++伪码
_result.X::X();
// ...直接处理_result
return;
}这样的编译器优化操作,有时候被称为Named Return Value (NRV)优化,在ARM Section 12.1.1.c ( 300~303页)中有所描述。NRV优化如今被视为是标准C++编译器的一个义不容辞的优化操作——虽然其需求其实超越了正式标准之外。为了对效率的改善有所感觉,请你想想下面的码:
class Test {
friend Test foo(double); // 友元函数
public:
Test() {
memset(array, 0, 100 * sizeof(double));
}
private:
double array[100];
};同时请考虑以下函数,它产生、修改,并传回一个test class object:
Test foo(double val) {
Test local;
local.array[0] = val;
local.array[99] = val;
return local;
}有一个main函数调用上述foo()函数一千万次
int main(int argc, char**argv) {
for (int cnt = 0; cnt < 10000000; cnt++) {
Test t = foo(double(cnt));
}
return 0;
}
// 整个程序的意义是重复循环10000000次,每次产生一个Test object
// 每个Test object配置一个拥有100个double的数组,所有的元素初值都设为0
// 只有#0核#99元素以循环计数器的值作为初始这个程序的第一个版本不能实施NRV优化,因为test class缺少一个copyconstructor。
完整代码
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
#include <cstring>
class Test {
friend Test foo(double); // 友元函数
public:
Test() {
memset(array, 0, 100 * sizeof(double));
}
private:
double array[100];
};
Test foo(double val) {
Test local;
local.array[0] = val;
local.array[99] = val;
return local;
}
int main(int argc, char**argv) {
for (int cnt = 0; cnt < 10000000; cnt++) {
Test t = foo(double(cnt));
}
system("pause");
return 0;
}第二个版本加上一个inline copy constructor 如下:
inline Test::Test(const Test& t) {
memcpy(this, &t, sizeof(Test));
}
// 在类中加上
public:
inline Test::Test(const Test& t);这个copy constructor的出现激活了C++编译器中的 NRV优化。NRV优化的执行并不通过另外独立的优化工具完成.下面是测试时间表(除了效率的改善,另一个值得注意的或许是不同编译器间的效率差异):
 一般而言,面对“以一个class object作为另一个class object的初值”的情形,语言允许编译器有大量的自由发挥空间.其利益当然是导致机器码产生时有明显的效率提升。缺点则是你不能够安全地规划你的 copy constructor的副作用必须视其执行而定。
一般而言,面对“以一个class object作为另一个class object的初值”的情形,语言允许编译器有大量的自由发挥空间.其利益当然是导致机器码产生时有明显的效率提升。缺点则是你不能够安全地规划你的 copy constructor的副作用必须视其执行而定。
Copy Constructor:要还是不要?
已知下面的3D坐标点类
class Point3d {
public:
Point3d(float x, float y, float z);
// ...
private:
float _x, _y, _z;
};这个类需要显示的拷贝构造函数吗?
答案是不需要,因为它不会导致内存泄漏和地址对齐。
摘要
copy constructor的应用,迫使编译器多多少少对你的程序代码做部分转化.尤其是当一个函数以传值( by value)的方式传回一个class object,而该class 有一个copy constructor(不论是明确定义出来的,或是合成的)时。这将导致深奥的程序转化——不论在函数的定义或使用上。此外编译器也将copy constructor的调用操作优化,以一个额外的第一参数(数值被直接存放于其中)取代NRV。程序员如果了解那些转换,以及 copy constructor优化后的可能状态,就比较能够控制他们的程序的执行效率。
2.4成员们的初始化队伍(Member Initialization List )
下列情况中,为了让你的程序能够被顺利编译,你必须使用memberinitialization list:
1.当初始化一个reference member时;
2. 当初始化一个const member时;
3.当调用一个base class 的constructor,而它拥有一组参数时;
4. 当调用一个member class的constructor,而它拥有一组参数时。
背的八股......
在这四种情况中,程序可以被正确编译并执行,但是效率低,例如
class Word {
String _name;
int _cnt;
public:
// 没有错误,只不过太天真
Word() {
_name = 0;
_cnt = 0;
}
};在这里,Word constructor会先产生一个暂时性的 String object,然后将它初始化,再以一个assignment运算符将暂时性object指定给_name,然后再摧毁那个暂时性 object。这是故意的吗?不大可能。编译器会产生一个警告吗?我不知道!以下是 constructor可能的内部扩张结果:
// c++伪码
Word::Word() {
// 调用String的default contructor
_name.String::String();
// 产生暂时性对象
String temp = String(0);
// memberwise地拷贝_name
_name.String::operator= (temp);
// 摧毁暂时性对象
temp.String::~String();
_cnt = 0;
}对程序代码反复审查并修正之,得到一个明显更有效率的实现方法:
// 较佳的方式
Word::Word: _name(0) {
_cnt = 0;
}它会被扩张成这个样子
// c++伪码
Word::Word() {
// 调用String(int) constructor
_name.String::String(0);
_cnt = 0;
}顺带一提,陷阱最有可能发生在这种形式的template code中:
template <class type>
foo<type>::foo(type t) {
// 可能是(也可能不是)个好主意
// 视type的真正类型而定
_t = t;
}这会引导某些程序员十分积极进取地坚持所有的 member初始化操作必须在member iniialization list中完成,甚至即使是一个行为良好的member 如_cnt:
// 坚持此种风格写代码
Word::Word(): _cnt(0), _name(0) {}编译器会一一操作initialization list,以适当次序在 constructor 之内安插初始化操作,并且在任何explicit user code 之前。例如,先前的 Word constructor被扩充为:
// C++伪码
Word::Word() {
_name.String::String(0);
_cnt = 0;
}有一些微妙的地方要注意:list中的项目次序是由class 中的members声明次序决定,不是由initialization list 中的排列次序决定。在本例的 Word class中,_name被声明于__cnt之前,所以它的初始化也比较早。
“初始化次序”和“initialization list中的项目排列次序”之间的外观错乱,会导致下面意想不到的危险:
class X {
int i;
int j;
public:
X(int val) : j(val), i(j) {}
// ...
};上述程序代码看起来像是要把j设初值为val,再把i设初值为 j.问题在于,由于声明次序的缘故,initialization list 中的i()其实比 j(val)更早执行。但因为j一开始未有初值,所以i (j)的执行结果导致i无法预知其值。
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
#include <cstring>
class X {
int i;
int j;
public:
X(int val) : j(val), i(j) {}
// ...
void show() {
std::cout << "i = " << this->i << ", j = " << this->j << std::endl;
}
};
int main(int argc, char**argv) {
X xx(1);
xx.show();
system("pause");
return 0;
}结果

现在成员变量默认初始化为0
如果总是把一个member的初始化操作和另一个放在一起(如果你真觉得必要的话),放在 constructor之内,像这样:
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
#include <cstring>
class X {
int i;
int j;
public:
// 注意这里
X(int val) : j(val) {
i = j;
}
// ...
void show() {
std::cout << "i = " << this->i << ", j = " << this->j << std::endl;
}
};
int main(int argc, char**argv) {
X xx(1);
xx.show();
system("pause");
return 0;
}结果

另一个常见的问题是,是否你能够像下面这样,调用一个member function以设定一个member的初值:
// X::xfoo()被调用,这样可以吗
X::X(int val)
:i(xfoo(val)), j(val)
{ }其中xfoo()是X 的个member function。答案是 yes
但是,是因为我要给你一个忠告:请使用“存在于constructor体内的一个member”,而不要使用“存在于member initialization list中的 member”,来为另一个member 设定初值。你并不知道xfoo)对X object 的依赖性有多高,如果你把xfoo()放在constructor体内,那么对于“到底是哪个member 在 xfoo()执行时被设立初值”这件事,就可以确保不会发生模棱两可的情况.
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
#include <cstring>
class X {
int i;
int j;
public:
// 测试
X(int val) : i(xfoo(val)), j(val) {}
// ...
void show() {
std::cout << "i = " << this->i << ", j = " << this->j << std::endl;
}
int xfoo(int val) {
return val + 10;
}
};
int main(int argc, char**argv) {
X xx(10);
xx.show();
system("pause");
return 0;
}结果

其被扩充为:
// c++伪码
X::X(int val) {
i = this->xfoo(val);
j = val;
}最后,如果一个derived class member function被调用,其返回值被当做base class constructor 的一个参数,将会如何:
// 调用FooBar::fval()可以吗
class FooBar : public X {
int _fval;
public:
int fval() { return _fval;} // 子类的成员函数
FooBar(int val)
:_fval(val),
X(fval()) // fval()作为基类构造函数的参数
{ }
// ...
};它可能扩张为:
// C++伪码
FooBar::FooBar() {
X::X(this, this->fval());
_fval = val;
}它的确不是一个好主意,简略地说,编译器会对initialization list 一一处理并可能重新排序,以反映出members的声明次序.它会安插一些代码到 constructor 体内,并置于任何 explicituser code 之前。
#include <ctime>
#include <cstdlib>
#include <iterator>
#include <algorithm>
#include <iostream>
#include <numeric>
#include <cstring>
class X {
int i;
int j;
public:
// 测试
X(int val) : i(xfoo(val)), j(val) {
std::cout << "X(int val) has been called, " << "i = " << this->i << ", j = " << this->j << std::endl;
}
// ...
void show() {
std::cout << "i = " << this->i << ", j = " << this->j << std::endl;
}
int xfoo(int val) {
return val + 10;
}
};
// 调用FooBar::fval()可以吗
class FooBar : public X {
int _fval;
public:
int fval() { return _fval;} // 子类的成员函数
FooBar(int val)
:_fval(val),
X(fval()) // fval()作为基类构造函数的参数
{
std::cout << "FooBar(int val) has been called, _fval = " << this->_fval << std::endl;
}
// ...
};
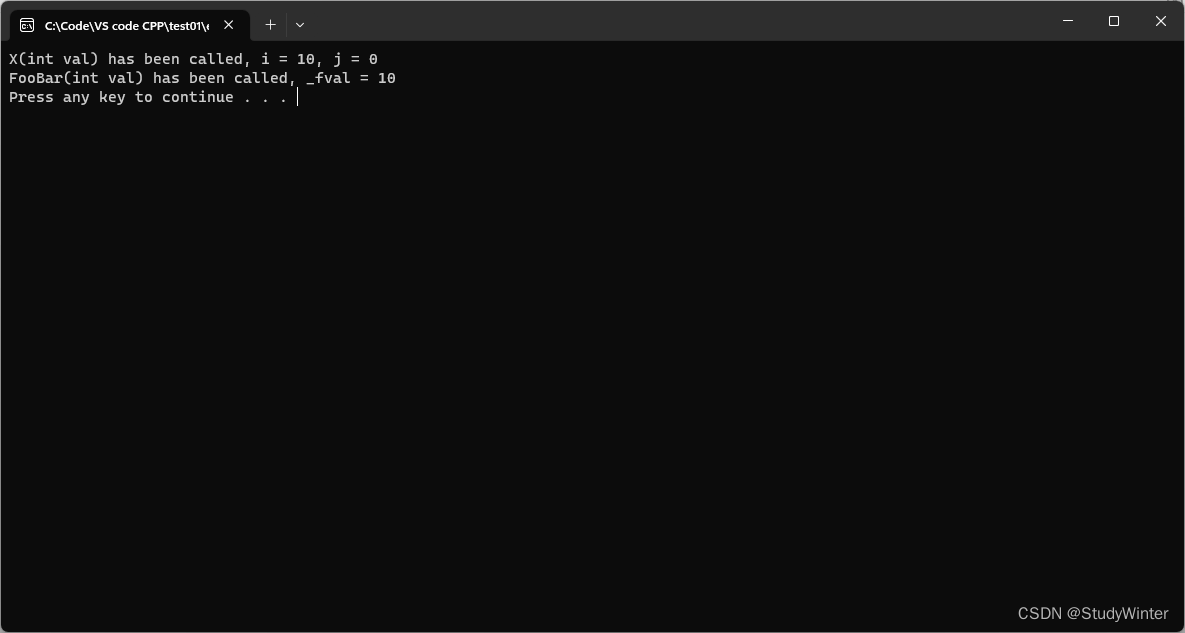
int main(int argc, char**argv) {
FooBar fooBar(10);
system("pause");
return 0;
}结果