NoSQL数据库原理与应用综合项目——起始篇
文章目录
- NoSQL数据库原理与应用综合项目——起始篇
- 0、 写在前面
- 1、项目说明
- 1.1 项目背景
- 1.2 项目功能
- 2、数据集和数据预处理
- 2.1 数据集
- 2.2 数据预处理
- 2.2.1 图书出版日期字段的处理
- 2.2.2 添加id字段
- 2.2.3 价格字段的处理
- 2.2.4 打折字段的处理
- 2.2.5 最终数据

0、 写在前面
- Windos版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - HBase版本:
HBase-1.1.5 - Zookeepr版本:使用HBase自带的ZK
- Redis版本:
Redis-3.2.7 - MongoDB版本:
MongoDB-3.2.7 - Neo4j版本:
Neo4j-3.2.7 Community - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3
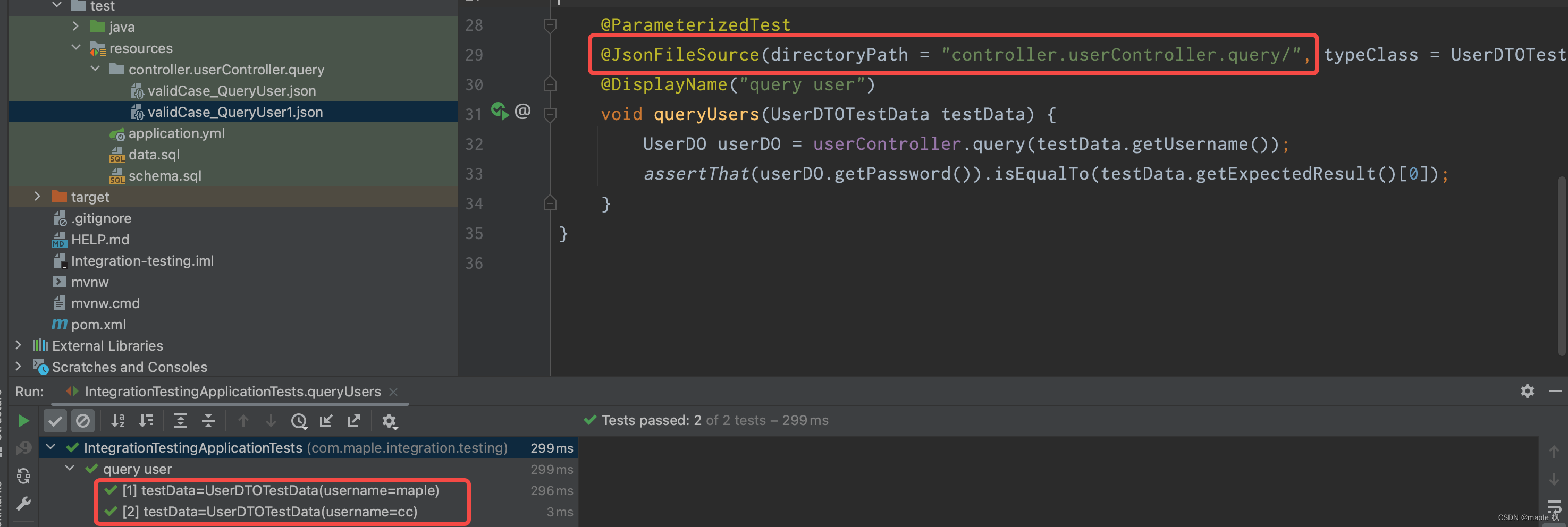
1、项目说明
1.1 项目背景
书籍是学习生活中必不可少的一部分,本次项目利用不同类型的书籍数据,包括小说、社会科学、计算机、文学、科普百科五个不同种类,经过统计分析了解不同类型书籍的各个维度。
1.2 项目功能
本次项目实现对Hbase、Redis、MongoDB、Neo4j等NoSQL数据库的增删改查操作,并使用MongoDB对书籍数据进行基本的统计分析。
2、数据集和数据预处理
2.1 数据集
数据来源
使用后裔采集器爬取工具,对中图网爬取多种类别图书数据信息。
数据量
13518条
数据字段说明
| 字段名 | 字段类型 | 字段描述 |
|---|---|---|
| id | int | ID编号 |
| type | varchar(10) | 书籍类型 |
| name | varchar(255) | 书籍名称 |
| author | varchar(100) | 作者 |
| price | varchar(6) | 价格 |
| discount | varchar(10) | 折数 |
| pub_time | varchar(20) | 出版日期 |
| pricing | varchar(20) | 原始价格 |
| publisher | varchar(20) | 出版社 |
| crawler_time | datetime | 数据爬取时间 |
原始数据展示

2.2 数据预处理
数据预处理阶段,本项目是先将爬取的数据直接导入到MySQL(Windows10环境下),接着通过使用SQL语句,对原始数据进行处理。
2.2.1 图书出版日期字段的处理
- 处理目的:
爬取的pub_time字段均为日期后面存在“ /”这种字符的情况。因此,需要提前处理为正确的出版日期。
- 具体处理过程:
处理前:pub_time字段均为日期后面存在“ /”这种字符的情况如下图所示:

使用SQL语句直接处理:
update tb_book set pub_time = replace(pub_time, ' /', '');
- 处理结果:
处理后pub_time字段均为正确的出版日期,如下图所示:

2.2.2 添加id字段
- 处理目的:
增加id字段作为主键,以便数据更加直观。
- 具体处理过程:
直接在MySQL(Windows10环境下)中执行下面的SQL语句,并将id字段设置为主键且设置为自增模式。
alter table tb_book add id int(6);

- 处理结果:
处理后,id字段已经添加成功,如下图所示:

2.2.3 价格字段的处理
- 处理目的:
对于原价字段pricing和打折后的价格字段price,均含有“¥”字符,为方便下文中的分析,此处对于这两个字段都删除掉“¥”字符,只剩下数字即可。此种情况如下图所示:

- 具体处理过程:
使用SQL语句直接处理:
update tb_book set price = replace(price, '¥', '');
update tb_book set pricing = replace(pricing, '¥', '');
- 处理结果:

2.2.4 打折字段的处理
- 处理目的:
爬取的数据中,打折字段discount均含有“()”字符,为方便获取打折力度以及下文的分析,对于此种情况,直接删除带“()”字符。此种情况如下图所示:

- 具体处理过程:
SQL语句:
update tb_book set discount = replace(discount, ‘(’, ‘’);
update tb_book set discount = replace(discount, ‘)’, ‘’);
- 处理结果:

2.2.5 最终数据
前20条数据

预处理完之后将数据上传到HDFS和本地
结束!






![[附源码]计算机毕业设计基于微信小程序的网络办公系统Springboot程序](https://img-blog.csdnimg.cn/439d6a91c09f4bf08d13951ff3a7f12f.png)