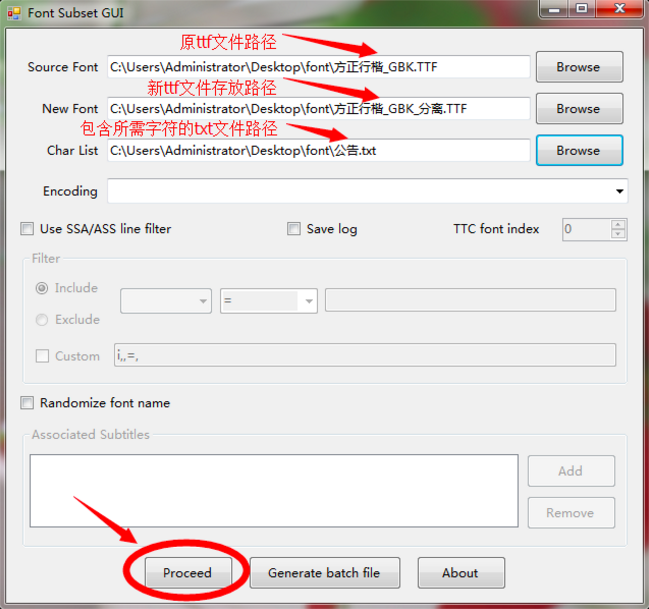
4.2 渲染状态优化
4.2.1 状态缓存
在引擎侧,可以使用状态缓存减少渲染管线的切换。伪代码:
class RenderStateCache
{
public:
void InitRenderStates();
{
for (RenderStateType t=RenderStateType.begin; t<RenderStateType.end; ++i)
{
_renderStateCache[t] = GetRenderStateFromDevice(t);
}
}
void SetRenderState(RenderStateType state, RenderStateValue value)
{
// 如果要设置的状态和当前缓存的一样,则忽略。
if (_renderStateCache.count(state) > 0 && _renderStateCache[state] == value)
{
return;
}
_renderStateCache[state] = value;
SetRenderStateToDevice(state, value);
}
private:
std::map<RenderStateType, RenderStateValue> _renderStateCache;
};
4.2.2 渲染状态建议
- 少用Alpha Blend。开启Alpha Blend了一般会关闭深度测试,无法利用深度测试剔除多余片元,导致片元数量增加,造成过绘制。所以要尽量少用。
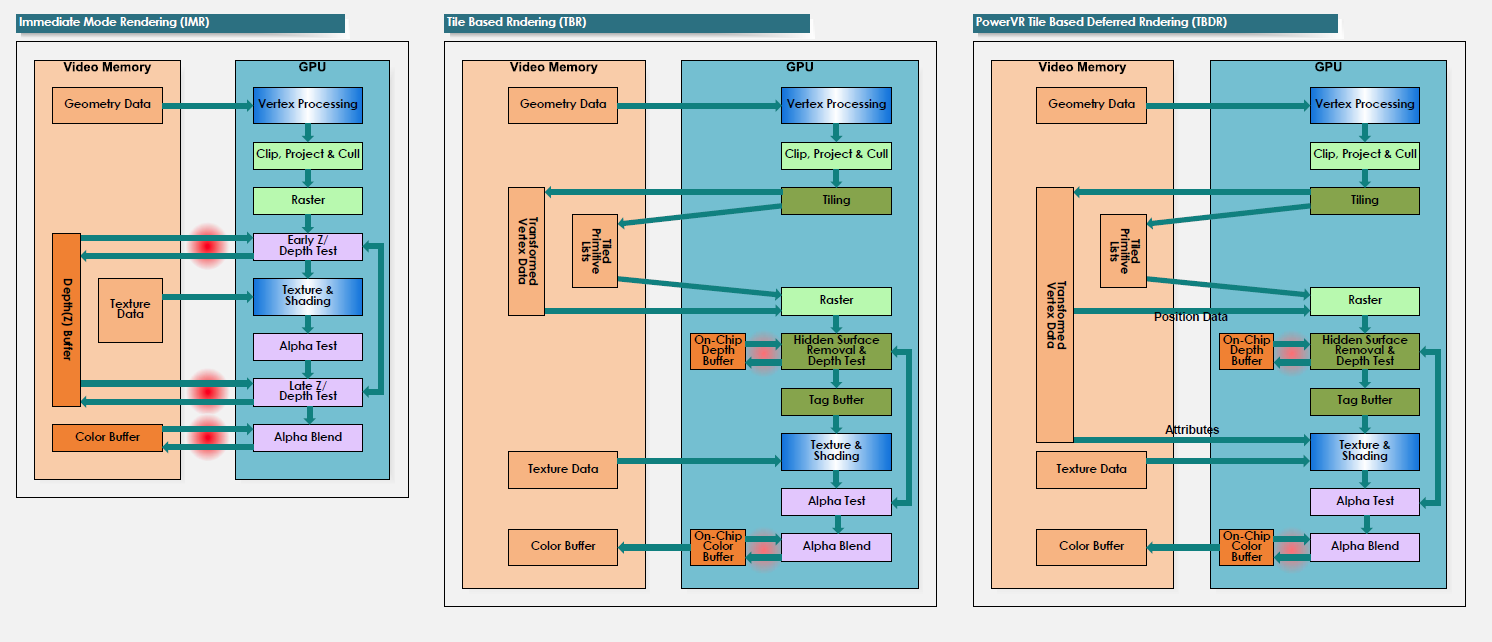
- 禁用Alpha Test。现代部分移动端GPU采用了特殊的渲染优化方式,如PowerVR采用Tile Based Deferred Rendering方式(下图右),而Alpha Test会破坏Early-Z优化技术,可用Alpha Blend代替。更多看这里。
- 开启背面裁剪。背面裁剪可以将背向摄像机的面片剔除,减少顶点和片元的数据量。
- 开启MipMaps。开启后,渲染时会自动根据画面尺寸选择合适大小的纹理,从而降低带宽,也可以降低锯齿,提高画质效果。但UI界面不能开启,原因见2.2.3。
- 关闭雾。只在固定管线适用。
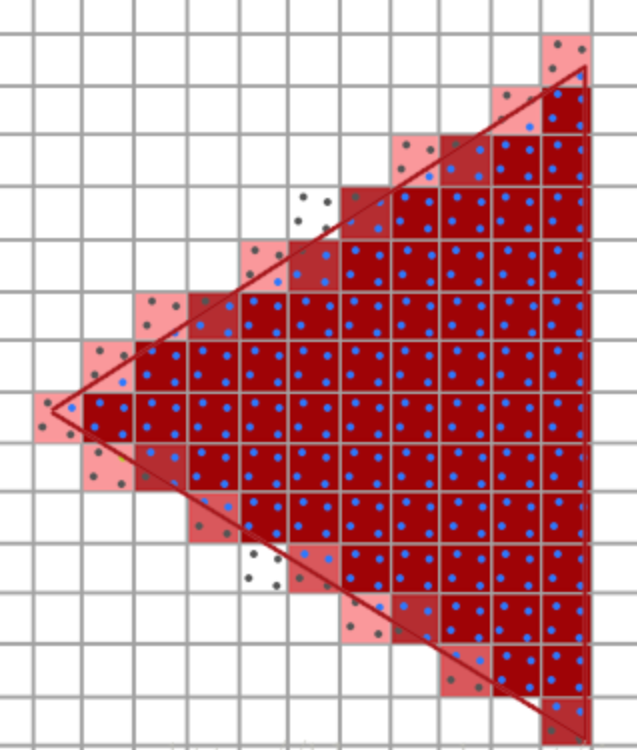
- 少用抗锯齿。图形API内置的抗锯齿通常会增加纹理采样次数数倍之多(下图),所以要慎用。
4.3 控制绘制顺序
控制模型绘制顺序的目的是充分利用深度测试,减少片元后续操作。特别是Early-Z技术的引入,此法效果更明显。绘制顺序是:先绘制已做好排序的不透明物体,再绘制Alpha Tested物体,最后渲染透明物体。伪代码:
void Render()
{
// 1. 绘制不透明物体
SortOpaqueObjectsInViewSpace(); // 对不透明物体进行排序,须在相机空间,离相机近的排在前面。
DrawOpaqueObjects(); // 绘制不透明物体,离相机近的先绘制。
// 2. 绘制Alpha测试物体
SortAlphaTestedObjectsInViewSpace(); // 对Alpha测试物体进行排序,须在相机空间,离相机近的排在前面。
DrawAlphaTestedObjects(); // 绘制Alpha测试物体,离相机近的先绘制。
// 3. 绘制透明物体(注意:绘制顺序跟不透明物体刚好相反)
SortTransparentObjectsInViewSpace(); // 对不透明物体进行排序,须在相机空间,离相机远的排在前面。
DrawTransparentObjects(); // 绘制不透明物体,离相机远的先绘制。
}
4.4 多线程渲染
在单线程渲染架构中,CPU性能消耗过高会影响GPU的渲染帧率,反之,GPU渲染过慢也会让CPU一直处于等待状态。多线程渲染就是为了解决CPU和GPU相互等待的问题。以Metal/Vulkan等架构出现为界限,将它们分成两个阶段。
4.4.1 软件级多线程渲染
早期的图形API和硬件架构都不支持多线程渲染,此阶段多线程渲染能做的优化比较受限,只能将渲染提交独立成一个线程,使之不会卡逻辑线程。开源图形渲染引擎OGRE的多线程渲染实现方式有两种:
-
Middle-level Multithread
每个渲染物体都有两份实例,主线程改变其中一份数据,在下一帧给渲染线程使用。(下图)
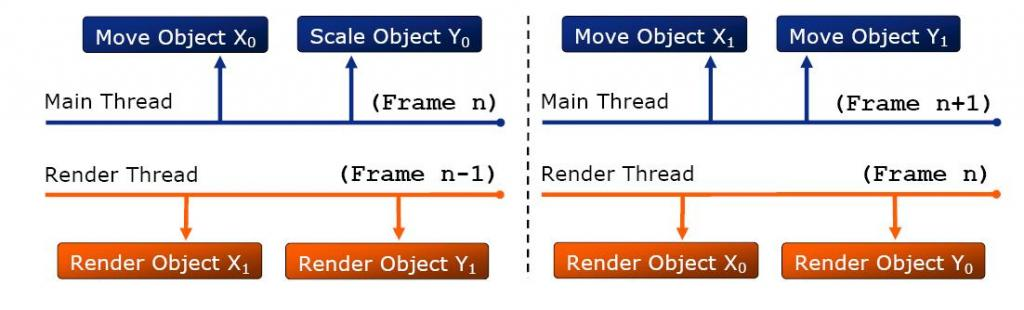
这种方式实现很复杂,要维护物体的两份实例,也不容易在多核CPU做扩展,不能充分发挥多核CPU的优势。
-
Low-level Multithread
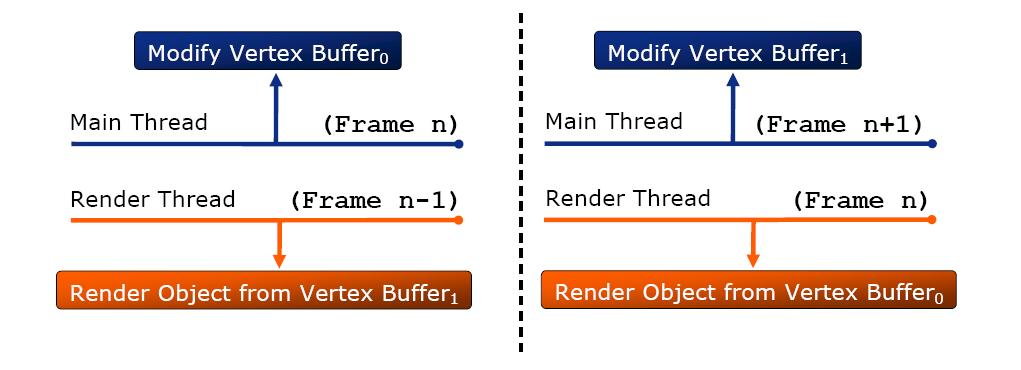
这种实现方式是将渲染物体的顶点等数据拷贝一份,逻辑线程修改其中一份数据,下一帧给渲染线程使用。除了以上两种方案外,可以给逻辑线程的若干逻辑(如Update/粒子/动画)开辟多个线程(下图),并行计算,缩短整体处理时间。
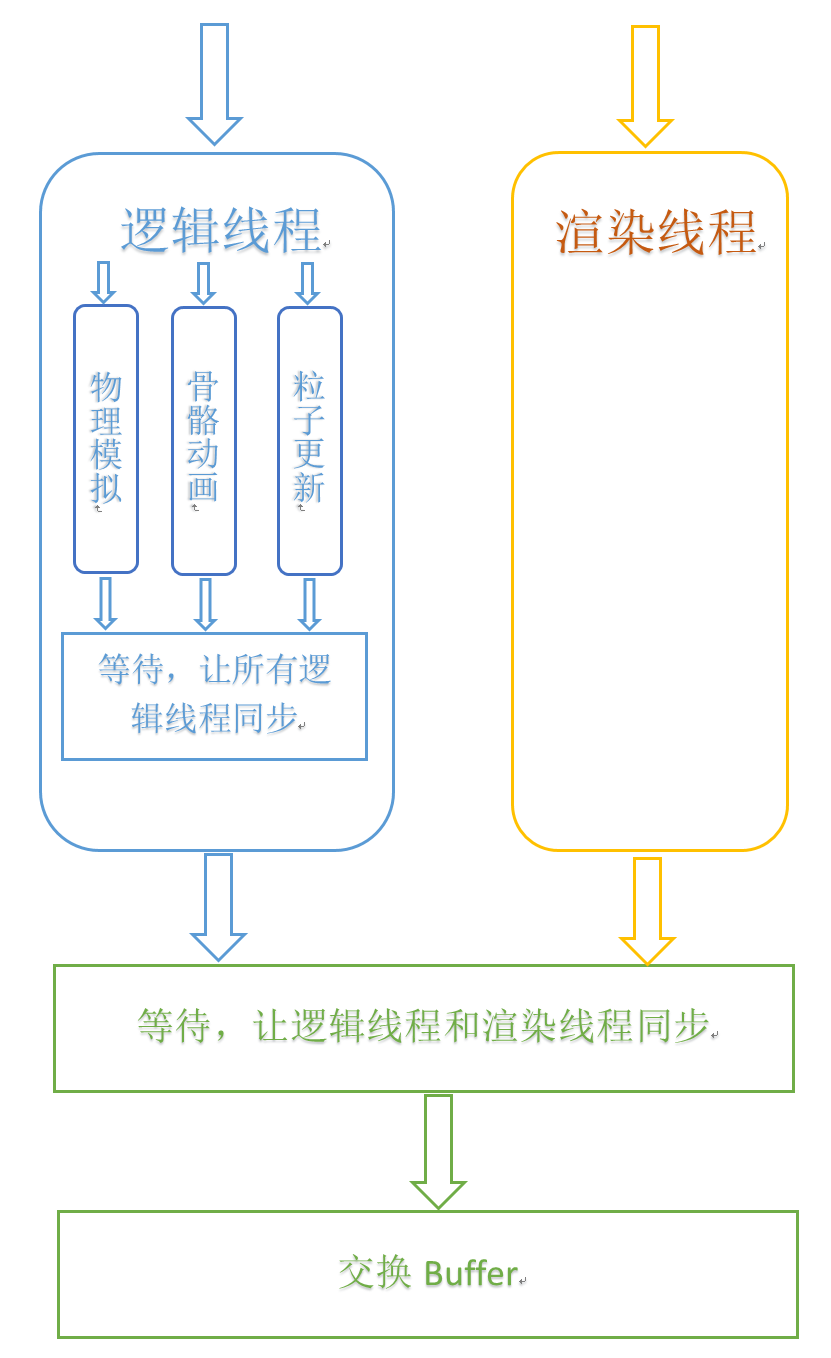
4.4.2 硬件级多线程渲染
近几年,Metal/Vulkan图形架构横空出世,基于硬件级别的多线程渲染的时代终于到来。它们的特点:
- 轻量化的驱动层。
OpenGL的API和驱动做了很多逻辑封装,用状态机的方式实现渲染(下图左)。而Metal/Vulkan与之不同的是,在驱动层只做少量的工作,为应用程序提供直接访问GPU硬件的接口,属于轻量级封装(下图右)。

从API架构上看,Metal/Vulkan的性能已胜出一大筹。
- 支持硬件级的多线程渲染。
Metal/Vulkan支持并行渲染指令,方便CPU各个线程各自提交渲染指令和数据。下图展示的是其中一种渲染方式,由多个线程创建不同的绘制命令,再由单独的线程管理渲染命令队列,统一提交给GPU绘制。

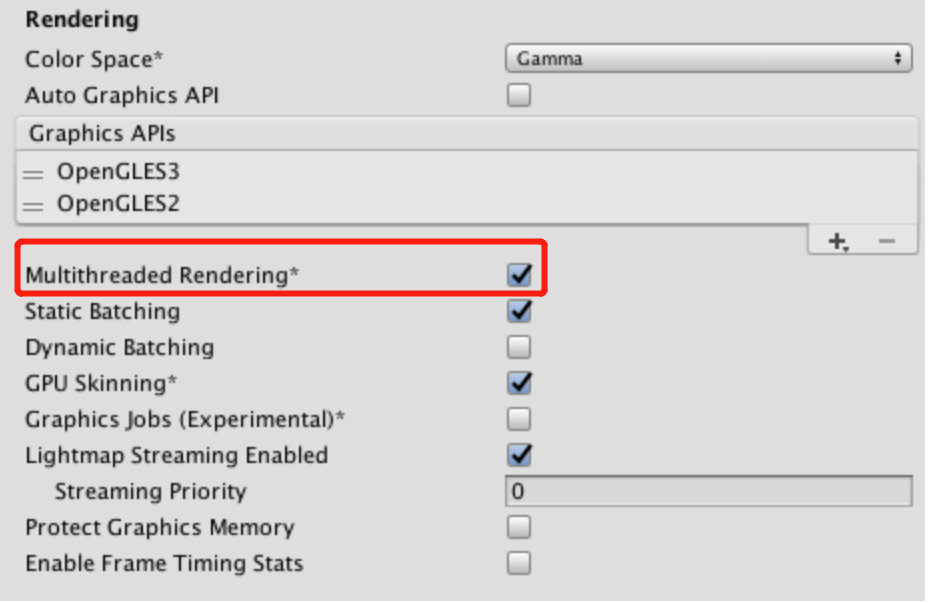
由于图形API已经支持多线程渲染指令提交,再结合上一节讲到的若干方案,将如虎添翼,渲染性能也会发生质的提升。目前主流商业引擎已经支持Metal/Vulkan,Unity2018.3已经支持Metal/Vulkan:
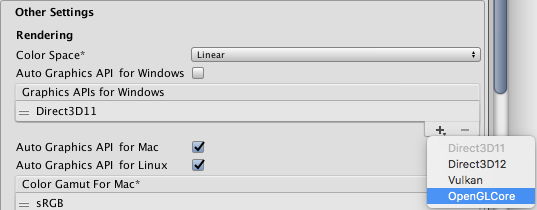
Unity在Rendering设置面板可以开启多线程渲染:
![[附源码]计算机毕业设计基于微信小程序的网络办公系统Springboot程序](https://img-blog.csdnimg.cn/439d6a91c09f4bf08d13951ff3a7f12f.png)









![[附源码]计算机毕业设计基于Vuejs的中国名茶销售平台Springboot程序](https://img-blog.csdnimg.cn/48bbdbeb7b8f4731afa792f50b67699c.png)