一句话总结
这项工作作为文本识别领域在增量学习设定下的第一次尝试。我们提出了增量多语言文本识别任务,以及该场景独有的挑战:回放不平衡问题,实验结果和可视化表明模型成功解决了这一问题。
相关资源
论文链接:
arxiv.org/abs/2305.14758
代码链接:
https://github.com/simplify23/MRN
研究背景和动机
随着大数据时代的到来,训练模型的数据往往以现实世界中连续数据流的形式出现。近些年来,越来越多的的机器学习从业者希望模型可以不断的学习到新知识的同时,仍能保持对于旧知识的记忆能力,即更符合现实世界中连续数据流场景。这样的任务设定被称为增量学习。增量学习致力于解决模型训练的一个普遍缺陷:灾难性遗忘(catastrophic forgetting),即模型在不断学习新知识的同时,对于之前习得的旧知识表现大幅下降,并趋向于遗忘的问题。
然而大部分的增量学习方法主要关注于图像分类、目标检测、语义分割等问题。几乎没有工作考虑在文本识别的领域。据我们了解,MRN工作是第一个尝试在文本识别领域考虑增量学习工作。MRN主要关注增量学习的多语言场景文本识别问题(Incremental Multilingual Text Recognition (IMLTR))。在IMLTR场景下,多语言文本识别存在语种多样性的挑战,而增量学习和多语言文本的结合会带来专属IMLTR独特的挑战:回放不平衡问题(Rehearsal-imbalance)。
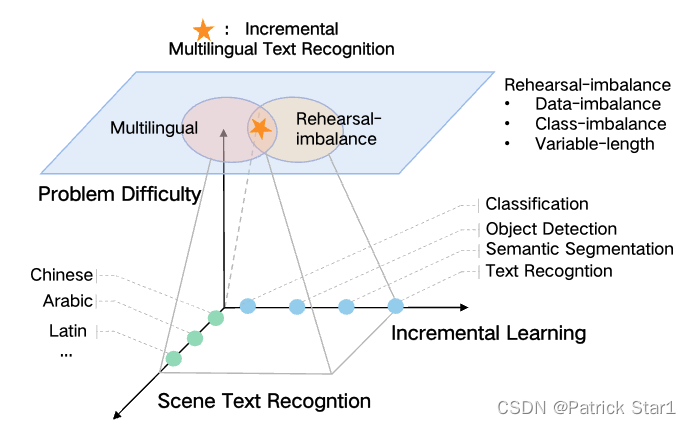
(大部分的增量学习方法关注图像分类,目标检测,语义分割等任务。MRN是目前第一篇关注增量学习文本识别的工作。在这一场景下,出现了增量多语言文本识别任务特有的挑战:回放不平衡问题。回放不平衡问题表现为:类不平衡、数据不平衡和单词不定长问题。)
Rehearsal-imbalance
Rehearsal Set算是增量学习中常见的概念,指在训练新任务的时候,保留下来的一部分有代表性的少量旧数据。在[1]中发现,少量的旧数据可以显著的缓解灾难性遗忘问题,因此被作为增量学习中常见的设定。如何挑选旧数据,如何利用新旧数据进行结合也是一部分工作主要研究的方向。
在场景文本识别的背景下,IMLTR的Rehearsal Set容易面对一些特殊的不平衡问题。1)数据层面(Data- imbalance):语种和语种之间,由于数据的收集难度不一和使用频率不一致(训到理想精度所需样本量),容易收集的语种数据量大,而难以收集的语种往往数据量小,这造成了语种和语种之间,数据的不平衡问题。2)类层面(Class-imbalance): 由于语言表达内容的差异,一些语言(中文,日语,韩语)字符类数量较多而数据样本较少。在Rehearsal Set中,如果照顾每种语言进行均匀抽样,语言的均匀加剧了类不平衡。3)字符层面(Variable length):文本识别任务中的每一张图像往往包含不定长的多个字符类。这使得Rehearsal Set彻底无法保持字符和数据的平衡。我们把这一挑战统一称为Rehearsal-imbalance。
由于这一现象的存在,这使得IMLTR任务不能被抽象成一个简单的增量学习任务。虽然有部分增量学习的工作[2]关注数据不平衡场景,但并没有类似IMLTR这种数据、类和字符都不平衡的场景和相关工作,这使得大部分的增量学习方法并不适用于IMLTR场景。因此,我们设计了更适应IMLTR场景的MRN网络。
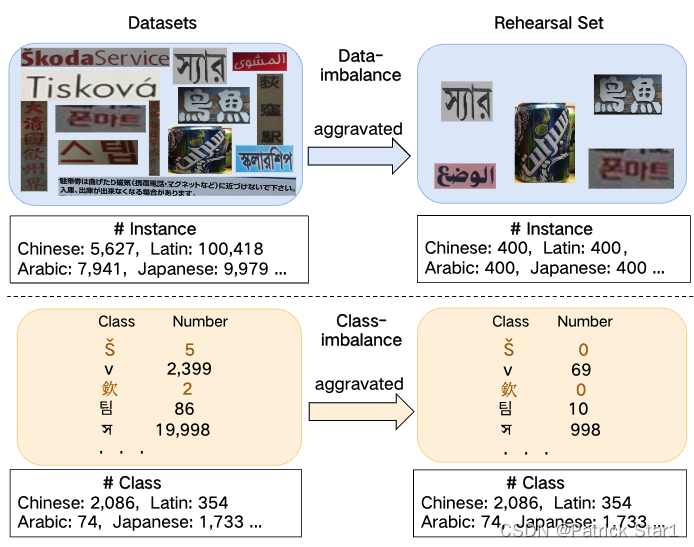
(在Rehearsal Set中,数据不平衡问题和类不平衡问题更加严重,而文本字符本身存在不定长的属性。我们把在Rehearsal Set中这三种特性归纳为Rehearsal- imbalance问题)
MRN如何解决Rehearsal-imbalance
这一章从原理的角度介绍MRN更有效的原理。传统的增量学习方法在做IMLTR的任务时,每种新的语言到来都需要重新扩大字符表。Rehearsal set一般固定内存大小,我们参考[2]设置了2000,当进行到第5个任务时,每一种语言分到400个样本(保持样本数量均匀),而部分语言如中文,常用字符接近2000。这使得每一个Rehearsal set的百数量级样本需要准确预测千级别的字符,这大大降低了预测的准确度。回放的样本在字符级别是不平衡的,但每种语言抽取的样本是可以均匀的。MRN方法抛弃了用Rehearsal set维持预测旧字符的做法,而是用Rehearsal set专注于预测当前字符的语种类别,保留并冻结旧模型的分类器,令旧模型的分类器去预测旧字符。通过这样的方式,2000的Rehearsal set被用于预测5个不同的语种的得分(语言域权重),这样大幅降低了模型对于Rehearsal set的字符内容依赖,并巧妙的避免了Rehearsal set中 rehearsal-imbalance的问题,能更好的适用于IMLTR场景。(可视化Figure 5中展示了,即使Rehearsal set中不再有相应的字符(红色标注),模型依然能通过旧的分类器正确分辩字符结果)
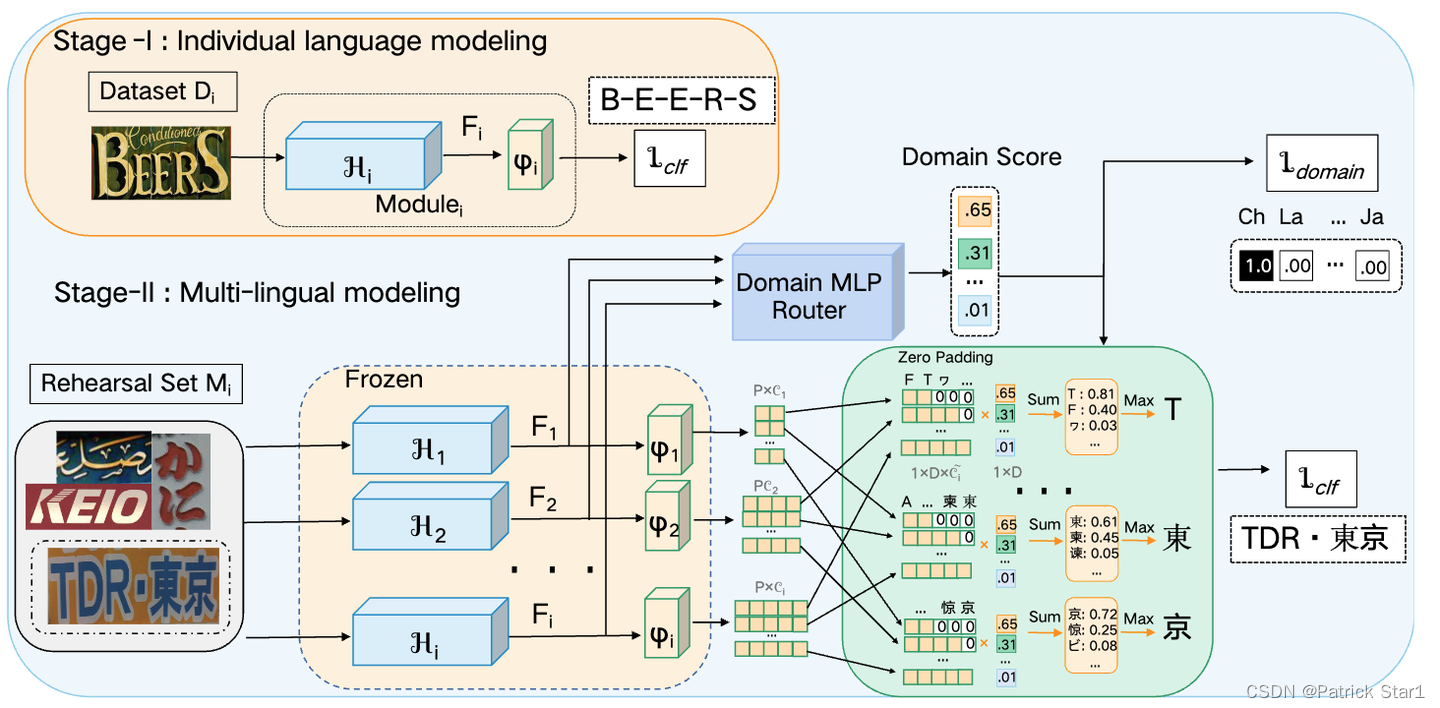
MRN网络结构
方法论方面是一个非常简洁并且直接的做法。MRN的详细结构如图所示。对于每种语言的训练主要分为两个步骤:1)只用相应的语言数据集训练模型。 2)将前面每种语言的模型全部冻结,用rehearsal set的数据集(包含当前语言)训练DM- Router(Domian MLP Router)权重投票器。Backbone预测出的特征经过DM-Router计算域得分(Domain Score)并进行后处理。 各个语言模型的分类器分别预测,并通过zero padding进行拼接,拼接以后的特征和域得分相乘并求最大值进行字符解码。由于后处理步骤语言模型的结果可以融合,所以模型可以依靠多个语言专家对同一图像进行复合预测。损失函数为语言域损失(当前标签属于哪种语言)和字符级的损失。
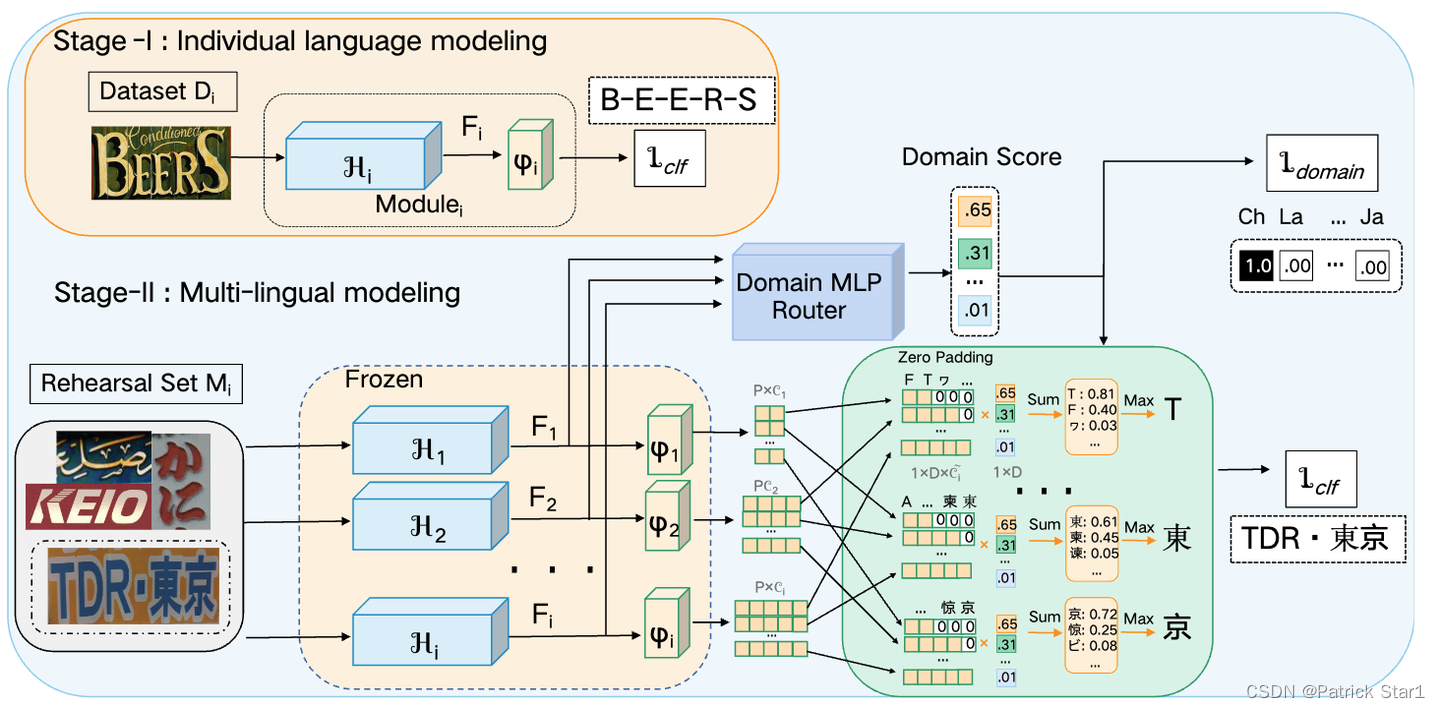
DM-Router :
刚刚介绍了整体的结构,下面我们介绍一下DM-Router的具体结构。DM-Router对backbone中的特征进行拼接,并且参考MLP- Attention的类似做法进行字符序列-语言域的注意力和通道-语言域的注意力。字符和字符之间存在不同语种的可能性,比如TDR東京,存在英文针对前3个字符,中文,日语针对后2个字符更加擅长。这时,将字符序列-语言域进行类似MLP- Attention的机制可以很好的探索这一线索。而通道-语言域注意力可以探索高低特征维度对语言预测的影响。MLP- Attention之后的特征被压缩到只有一个维度,并进行Softmax操作
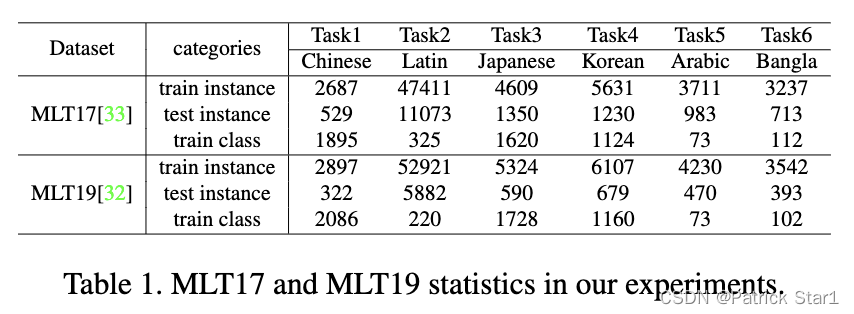
IMLTR数据集
我们针对MLT17和MLT19进行了增量学习场景的设定,并制作了针对IMLTR场景的数据集,具体配置如下:
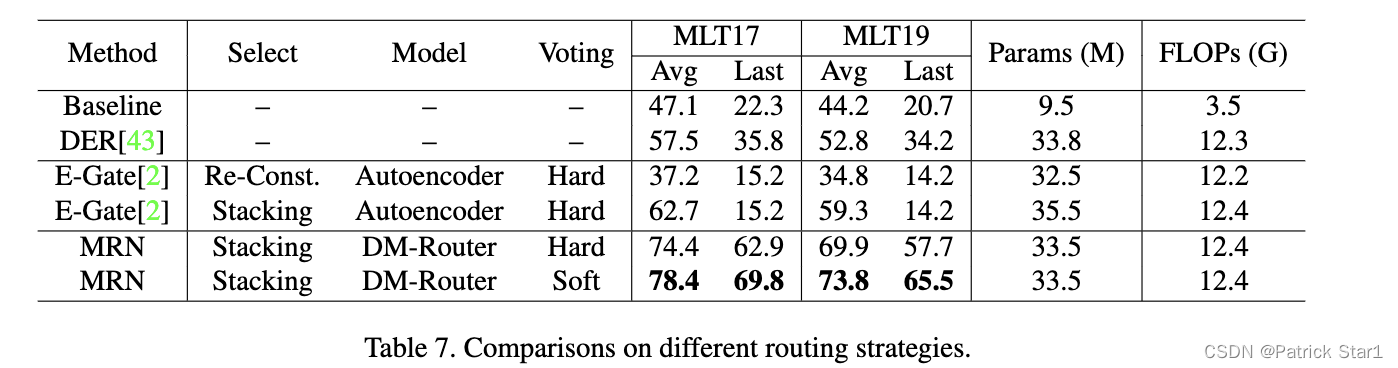
消融实验
我们研究了MRN每个模块对试验结果的影响。这里用和我们方法有一定相似性的E-Gate[3]做全面的试验分析。E-Gate分别在专家模型选择方式、模型结构、投票方式和MRN有差异,堆叠式、DM- Router和软投票都能为MRN带来收益。而且对于模型效率而言,MRN和E-Gate需要差不多的参数量和FLOPs.
实验分析
在实验上,我们选择了基于CTC的CRNN,基于Attention的TRBA,和最近流行的Transformer结构SVTR作为基本方法,并对比了不同增量学习方法在IMLTR场景下的性能评估。我们希望通过实验验证MRN性能大幅提升的关键在于它以一种巧妙的方式解决了rehearsal- imbalance的问题。但rehearsal- imbalance没法直接进行评估。为此,我们做了一系列的实验,来证明MRN的作用。
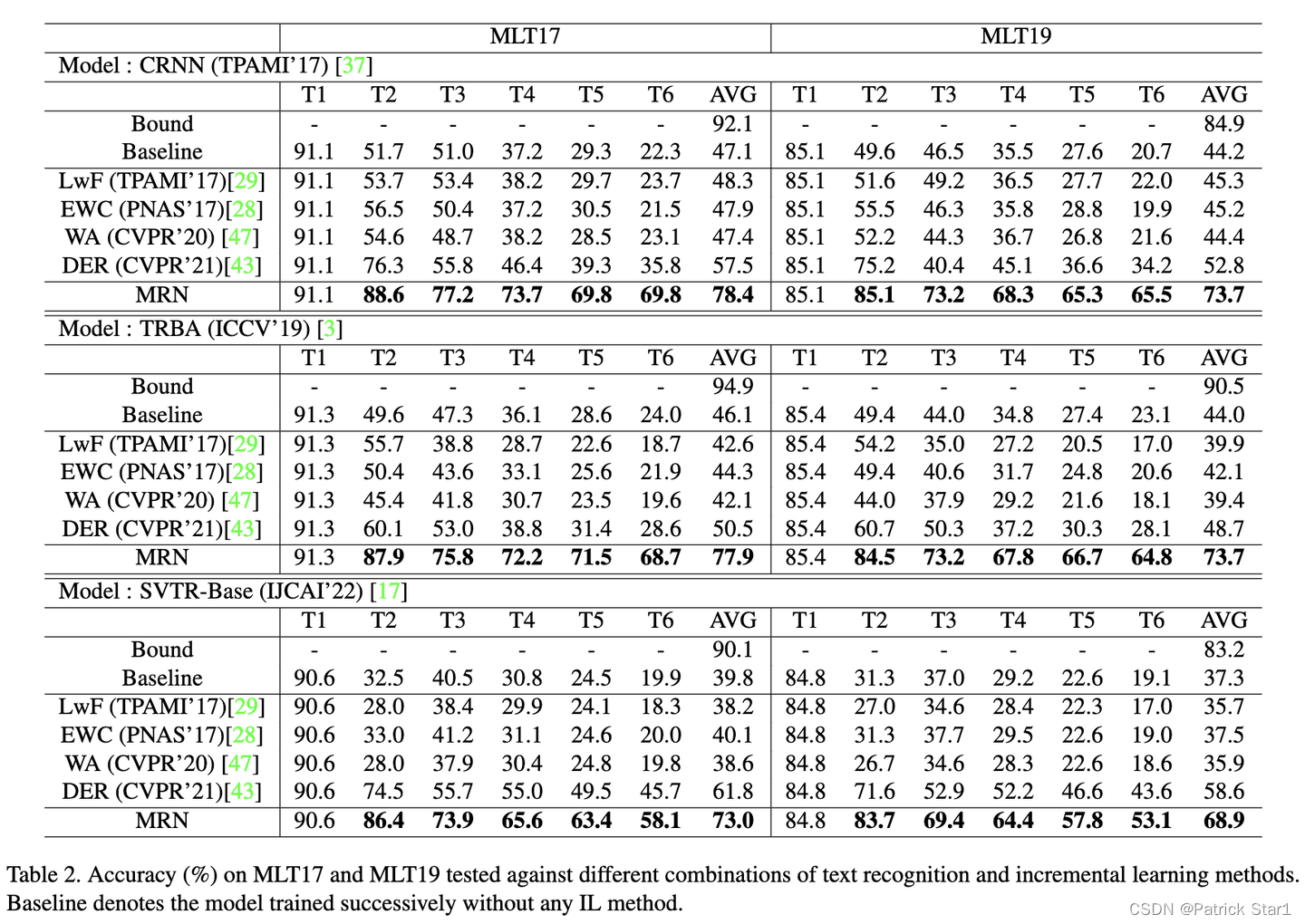
SOTA的实验评估,三种不同识别器中MRN都获得了最高的性能,并且远超其他方法
1)数据层面:为评估模型对Data-imbalance的效果,我们设计了改变Rehearsal set大小的实验。MRN在数据严重不平衡(较小的内存)时比其他方法有更大的增益,显示了其对数据不平衡的鲁棒性。
Rehearsal set不同内存大小的实验分析
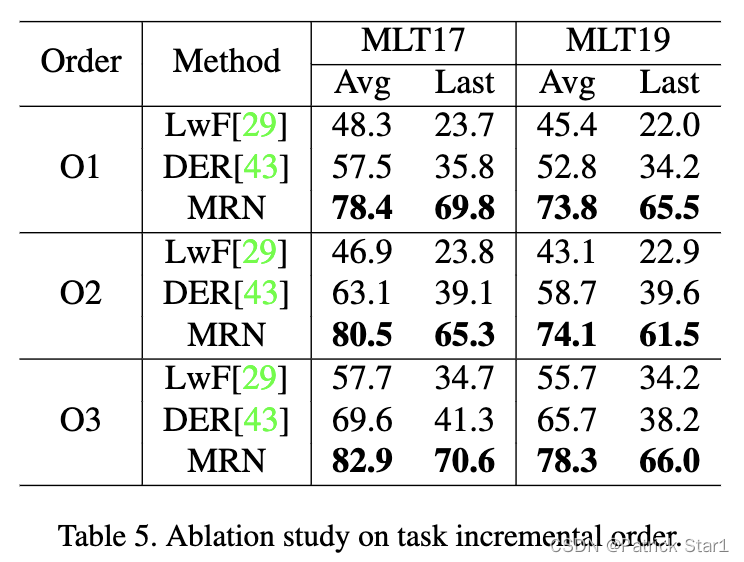
2)类层面:为了评估MRN是否更好的缓解class-imbalance问题,我们改变了语种的增量顺序(不同语种类数量差别大)来评估这一问题。 O1为:Chinese, Latin, Japanese, Korean, Arabic, Bangla. 大词汇量的语言(中,日,韩)出现更早,类别不平衡最为严重,这表明 MRN 可以更好地对抗类别不平衡
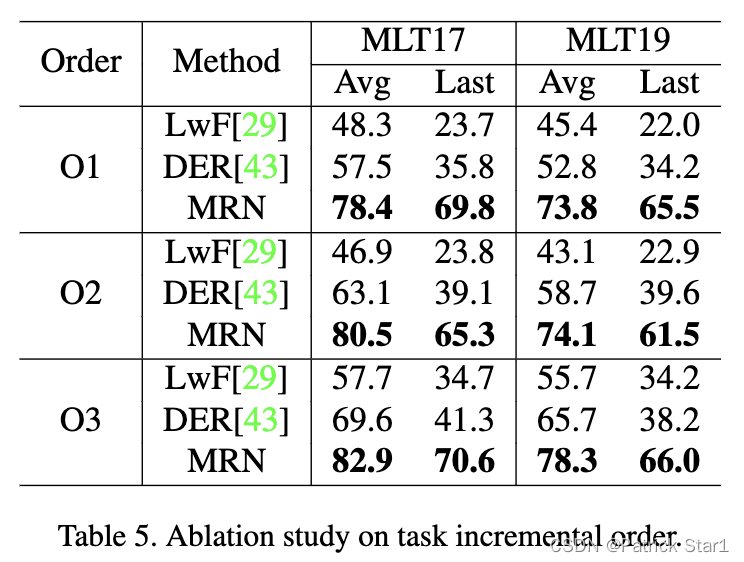
不同语种顺序的实验分析
3)字符层面: 不同的采样方式可以改变rehearsal set中每张图片的字符数量,以评估MRN是否能解决字符不定长的问题。Random 的性能优于Length(字符长度普遍更长),这意味着 MRN 可以很好地处理字符不定长问题。
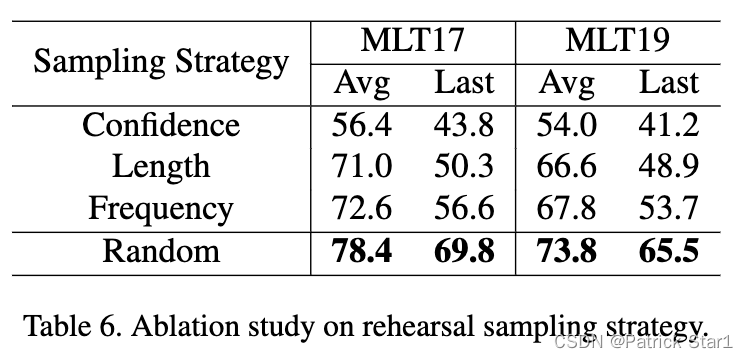
不同Rehersal set采样策略的分析
可视化
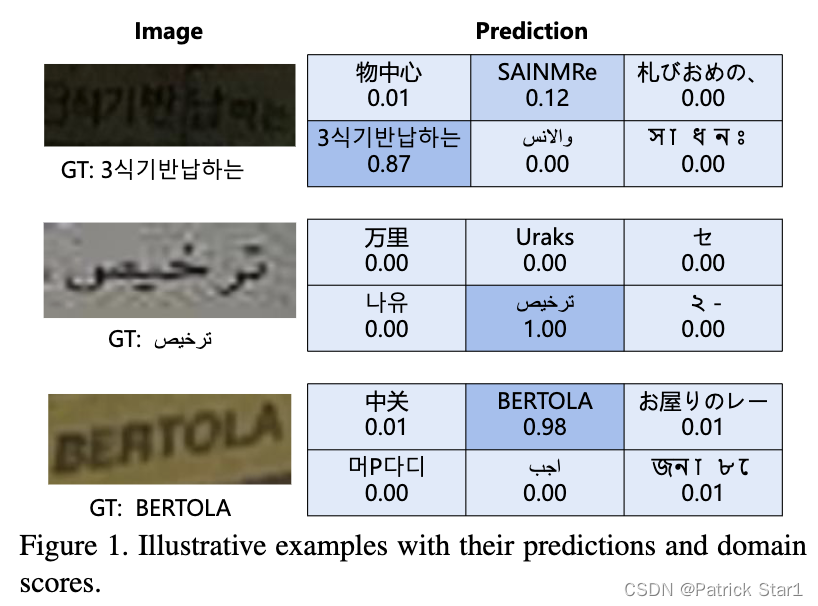

总结与展望
我们引入了一个新的场景:增量多语言文本识别(IMLTR),作为一个文本识别领域进行增量学习的设定,IMLTR面临Rehearsal- imbalance的问题,这使得主流的增量学习方法并不适用。为此,我们设计了专注于解决这一问题的MRN网络。作为第一个关注文本识别领域的增量学习任务,我们希望这个工作能推动文本识别社区的进一步发展。
第一次写这样的文章,逻辑还有很多不够strong的情况,欢迎大家提问一起进步~
参考文献
[1] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In CVPR, pages 2001–2010, 2017
[2] Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleˇs Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2022
[3] Rahaf Aljundi, Punarjay Chakravarty, and Tinne Tuytelaars. Expert gate: Lifelong learning with a network of experts. In CVPR, July 2017