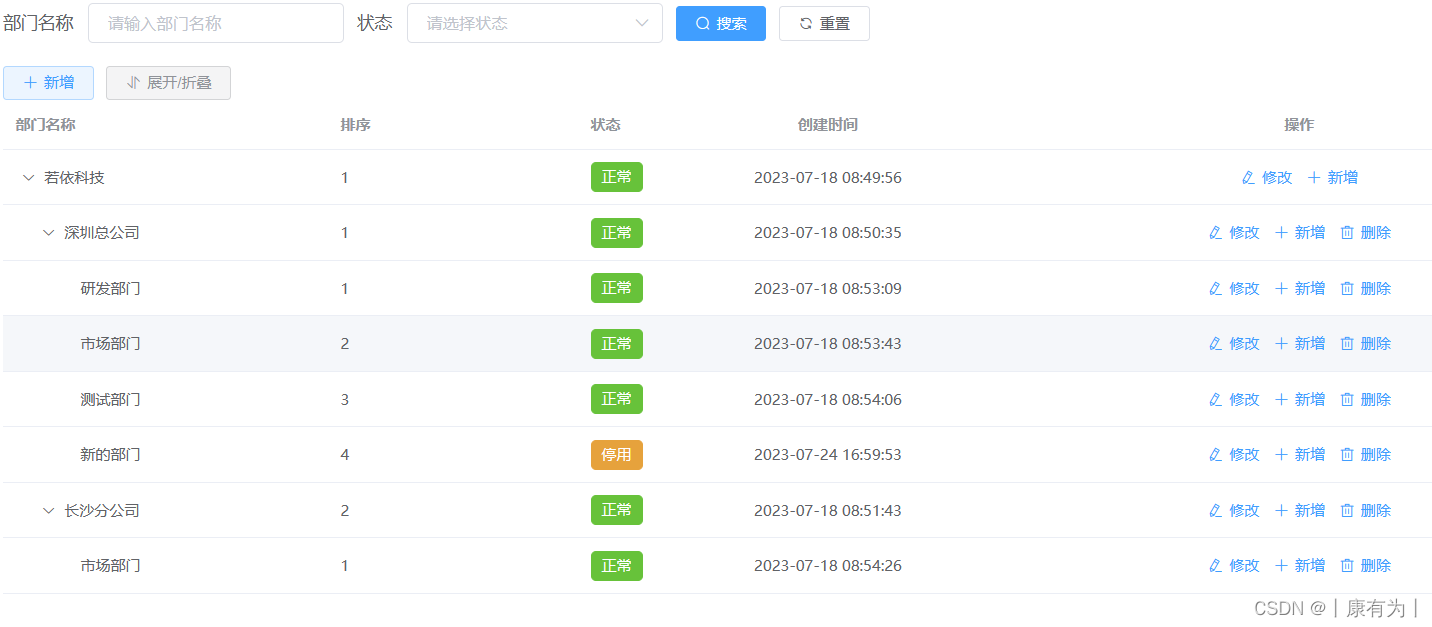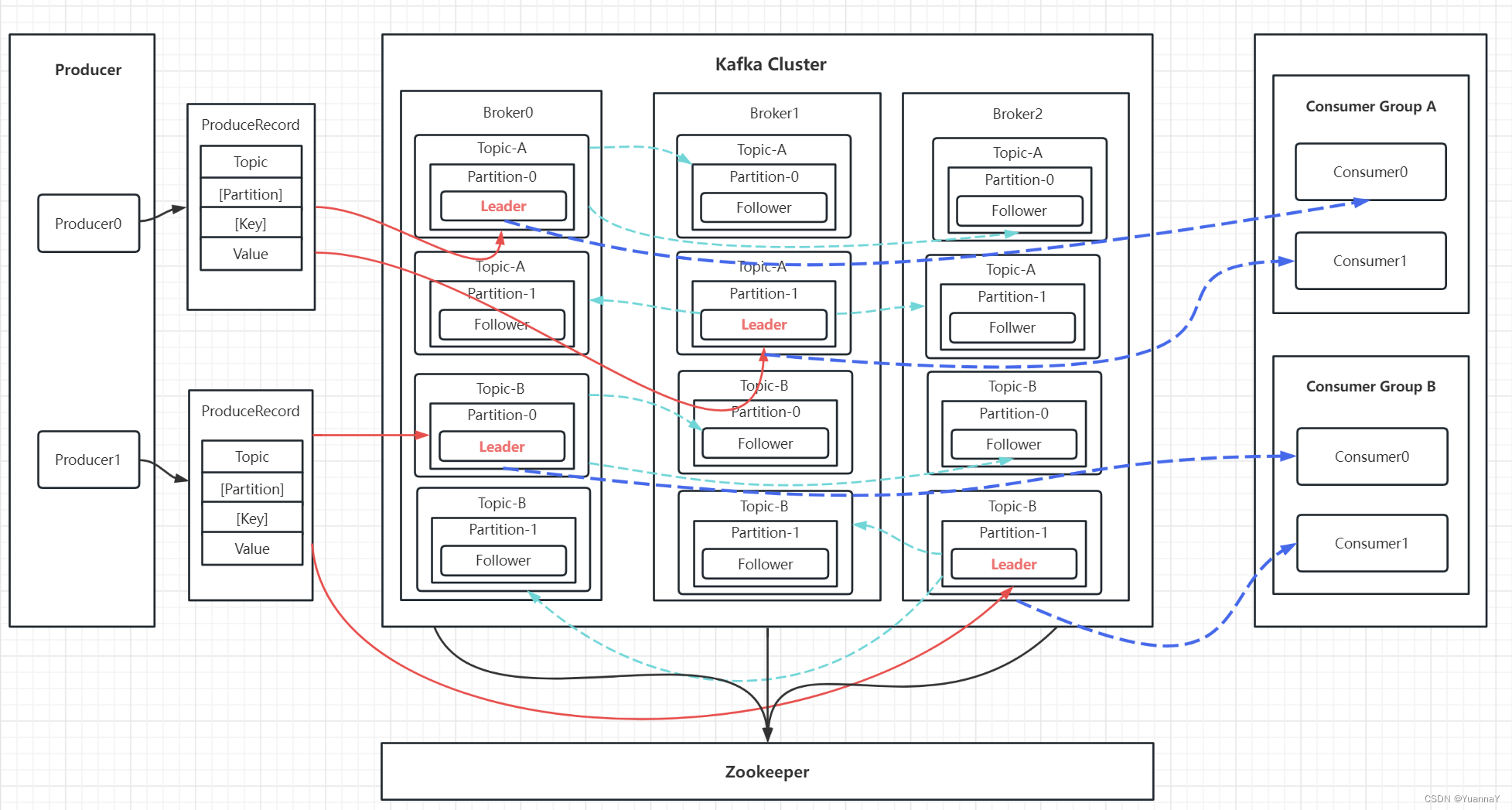
Kafka角色介绍:
1. Producer:消息生产者:
2. Broker: kafka实例,可以理解为一台kafka服务器,kafka cluster 是由多个broker构成的集群。
3. Topic: 消息主题,理解为消息队列,kafka数据就保存在topic里。
4. Partition: 消息分区,一个Topic会有多个分区, 分区的作用是负载均衡,同一个topic在不同分区内的数据是不重复的,目的是提高kafka的吞吐率。
5. Replication:副本,每一个分区都会有副本(Follower),作用是做备用,主分区(Leader)会将数据备份到副分区(Follower),且副分区不会和主分区在同一个broker中。当主分区出现故障,会从副分区中重新推举一个leader。
6. Message: 信息,底层是封装的ProduceRecord
7. Consumer: 消费者,消息的消费方,消息出口。
8. Consumer Group: 消费者组,可以将多个消费者组成一个消费者组,作用是开启多线程,加快消息的消费速度,提高吞吐率。同一分区中的数据只能由消费组中的一个消费者消费,消费者组可以消费同一Topic的不同分区的数据,实现多线程消费信息。一般消费者组中的消费者数和分区数相同。
9. Zookeeper: kafka集群的负载均衡,保存集群的元数据(offset,稀疏索引),实现集群的高可用性。
Kafka的分区机制:
1. 有key的话,根据Key进行hash 操作分区。
2. 无key的话,采用轮询的方式进行分区。
kafka的发布订阅模式:
1. 基于NIO, 异步响应,多线程。
举例:
角色分配:
2个Producer, 3个Broker, 2个Partiton,3个Replication , 2个ConsumerGroup .每个Group 有2个Consumer。
数据流转过程:
- Producer 生成一个ProduceRecord消息,topic为TopicA,分区机制将消息分到不同分区中,partition0, partition1.
- 每个Topic生成3个副本分区,分别放到不同的broker上,并选举其中一个为Leader,其余的为Follower.数据写入时先向Leader分区写入数据,然后由Leader分区向其余的Follower分区写入数据。
- 消息写入成功,会生成RecordMetaData元数据,记录Topic, 分区信息,offset(偏移量), 存入zk中。
- 消息消费:消费者组Consumer Group A 中的consumer0,consumer1分别访问TopicA的不同分区,优先访问Leader分区。