说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
蝙蝠算法是2010年杨教授基于群体智能提出的启发式搜索算法,是一种搜索全局最优解的有效方法。该算法基于迭代优化,初始化为一组随机解,然后迭代搜寻最优解,且在最优解周围通过随机飞行产生局部新解,加强局部搜索速度。该算法具有实现简单、参数少等特点。
混合蝙蝠算法针对基本蝙蝠算法存在收敛速度慢,易陷入局部最优,求解精度低等缺陷,提出一种融合局部搜索的混合蝙蝠算法用于求解无约束优化问题。该算法利用混沌序列对蝙蝠的位置和速度进行初始化,为全局搜索的多样性奠定基础;融合Powell搜索以增强算法的局部搜索能力,加快收敛速度;使用变异策略在一定程度上避免算法陷入局部最优。
本项目通过HBA混合蝙蝠智能算法优化XGBoost分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
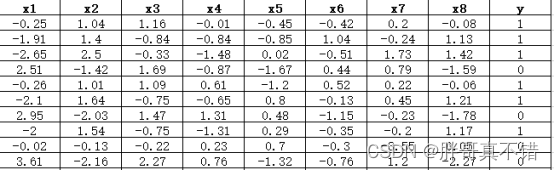
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
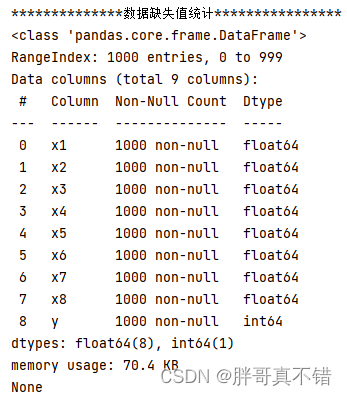
从上图可以看到,总共有9个变量,数据中无缺失值,共1000条数据。
关键代码:

3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
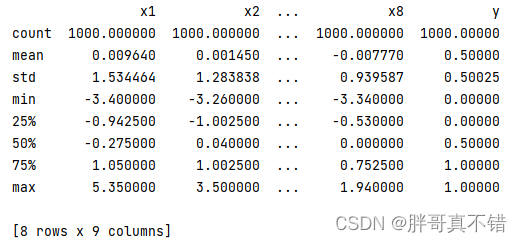
关键代码如下:

4.探索性数据分析
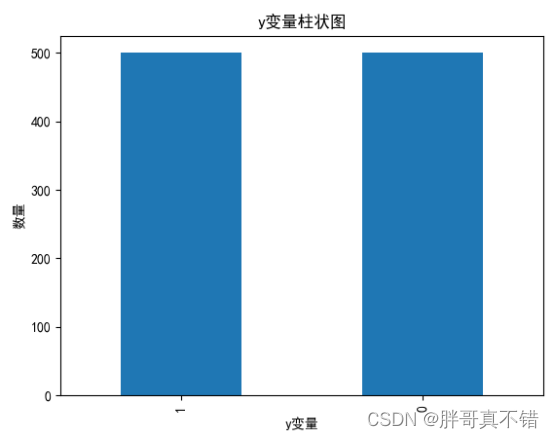
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
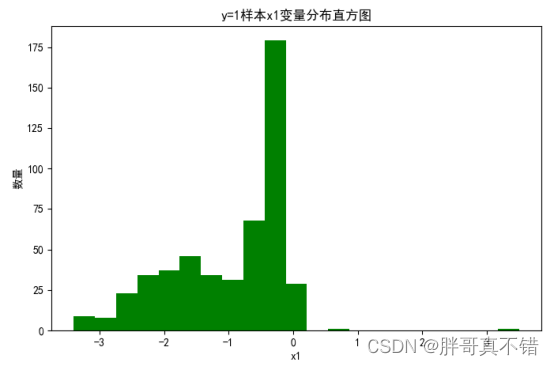
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析

从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
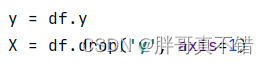
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
6.构建HBA混合蝙蝠优化算法优化XGBoost分类模型
主要使用HBA混合蝙蝠优化算法优化XGBoost分类算法,用于目标分类。
6.1 HBA混合蝙蝠优化算法寻找最优的参数值
最优参数:

6.2 最优参数值构建模型

7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
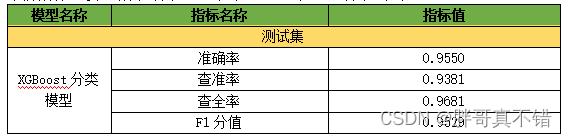
从上表可以看出,F1分值为0.9529,说明模型效果较好。
关键代码如下:

7.2 分类报告
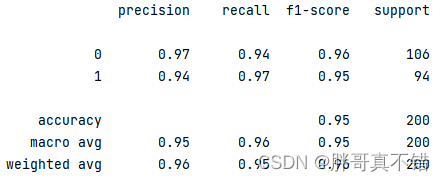
从上图可以看出,分类为0的F1分值为0.96;分类为1的F1分值为0.95。
7.3 混淆矩阵
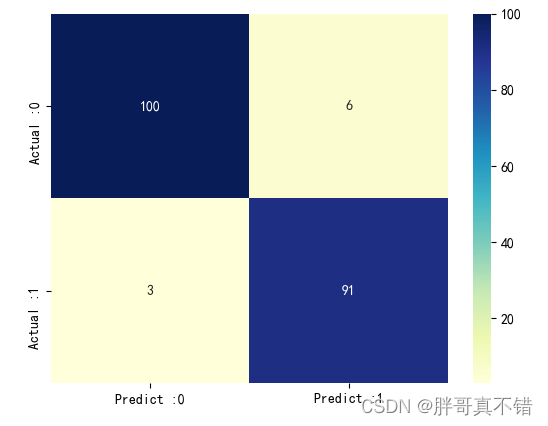
从上图可以看出,实际为0预测不为0的 有6个样本;实际为1预测不为1的 有3个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了HBA混合蝙蝠智能优化算法寻找XGBoost算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 初始化种群、初始解
Sol = np.zeros((N_pop, d)) # 初始化位置
Fitness = np.zeros((N_pop, 1)) # 初始化适用度
for i in range(N_pop): # 迭代种群
Sol[i] = np.random.uniform(Lower_bound, Upper_bound, (1, d)) # 生成随机数
Fitness[i] = objfun(Sol[i]) # 适用度
# ******************************************************************************
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
# 提取码:thgk
# ******************************************************************************
# y变量柱状图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# kind='bar' 绘制柱状图
df['y'].value_counts().plot(kind='bar')更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客