本文主要记录本周的学习内容,搭建mysql的高性能数据库服务
源于
现最多被使用的数据库还是Msql,而MySQL本身不是一种分布式型数据库,在高性能要求下,简单的主从、复制已无法满足高性能要求。
而本文主要在提供读者一种高性能方案。
主要进入角度在于分库,将数据按指定的维度进行分库处理。
为什么
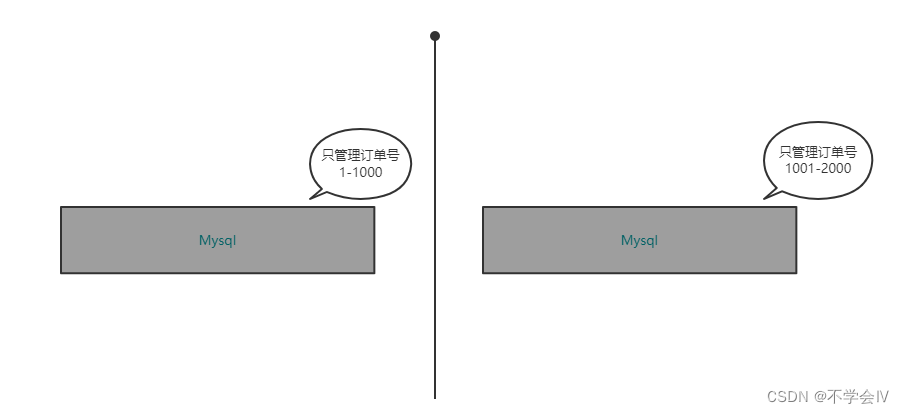
试想你有一台数据库你为了希望它高可用你部署了主从,在意外情况下可以切换到从库。为了提高性能你又使用了读写分离,但你发现性能还是不够因为主要的写库还是只有一台,然后你想做到集群化部署,不搞什么读写了,将数据分批放到不同的数据库中,其数据库之间不关联,性能也是独立的。两台性能+2、三台性能+3,就此性能问题解决了。
但实际上想要实现这样子分库并没有那么简单,需要借助一些中间件实现
选择
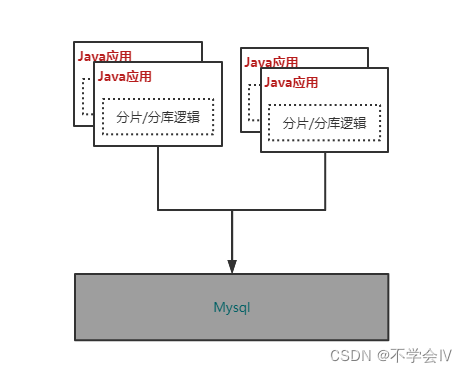
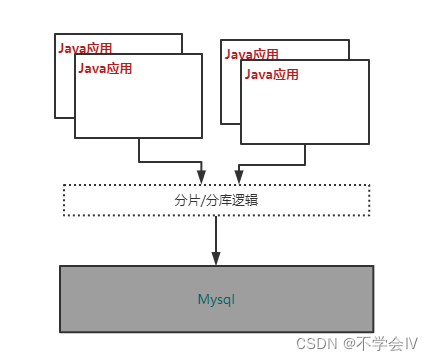
现有适用与MySQL的分库分表实现方案,主要有以下两种类型,其区别主要在于是否置入应用、独立应用的数据库上层代理
-
JDBC直连层
-
Proxy 代理层
主要代表方案 :
| 方案 | 类型 | 描述 |
|---|---|---|
| Sharding-JDBC | JDBC直连层 | 现比较常用的方案,其织入应用维护成本较底,但统一管理变的麻烦-后续已经支持集群proxy方案 |
| mycat | Proxy 代理层 | 需要独立部署,无疑加大了维护成本适用于大规模的开发 |
Sharding-JDBC
笔者这里不介绍Sharding-JDBC的实现,希望读者自行去点标题进入官网了解它能做些什么, 笔者已经把能直接运行的项目放到了👉gitee👈,方便读者学习
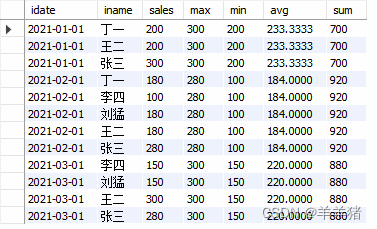
在我们对数据的数据进行分片后,订单数据已经成功的根据不同的订单号进入了不同的数据库了,但出现了一些问题,我希望查询用户Id是2的订单数据,但出现在了两个数据库中,我的sql应该怎么写;
select * from table_name where user_id=2;
现在这样子写还可以吗
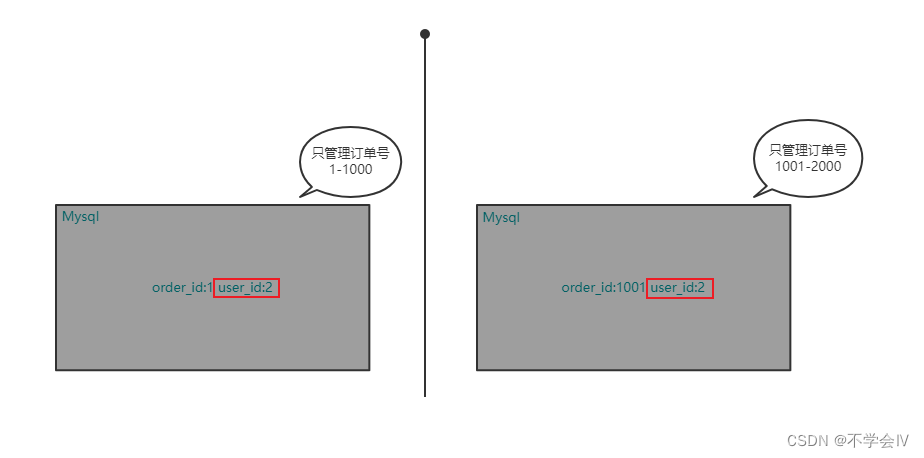
不出意外的出现了异常,因为我们的数据划分是通过订单号,也就是说我们提供Sharding-JDBC一个订单号然后它去更具规则算出它在那个数据库中,但是如果我们没有提供订单号的查询,它无法进行判断,那此类sql就会变成整个集群的查询,此类查询不出意外的被拦截了,当然我们也可以关闭拦截,但关闭了拦截我们的分库就毫无意义(还是变成了全库扫描查询)。
分库后会出现以下问题
- 分库分表的算法 : 以什么条件作为分法,是否兼容后续数据库扩容
- 分库分表ID问题 : 多库如果用自增编号,会出现重复编号
- 分库分表后的事务 : 多库之间的分布式事务问题
- 多表联合查询/多维度 : 数据分布在不同的数据库中怎么做order by、group by等等
问题一 : 分库分表的算法
- 通过对order_id取模 : 取模的方案固然最简单,但在后续的扩容取模数+1会导致旧数据已经分配出去的,无法查询;
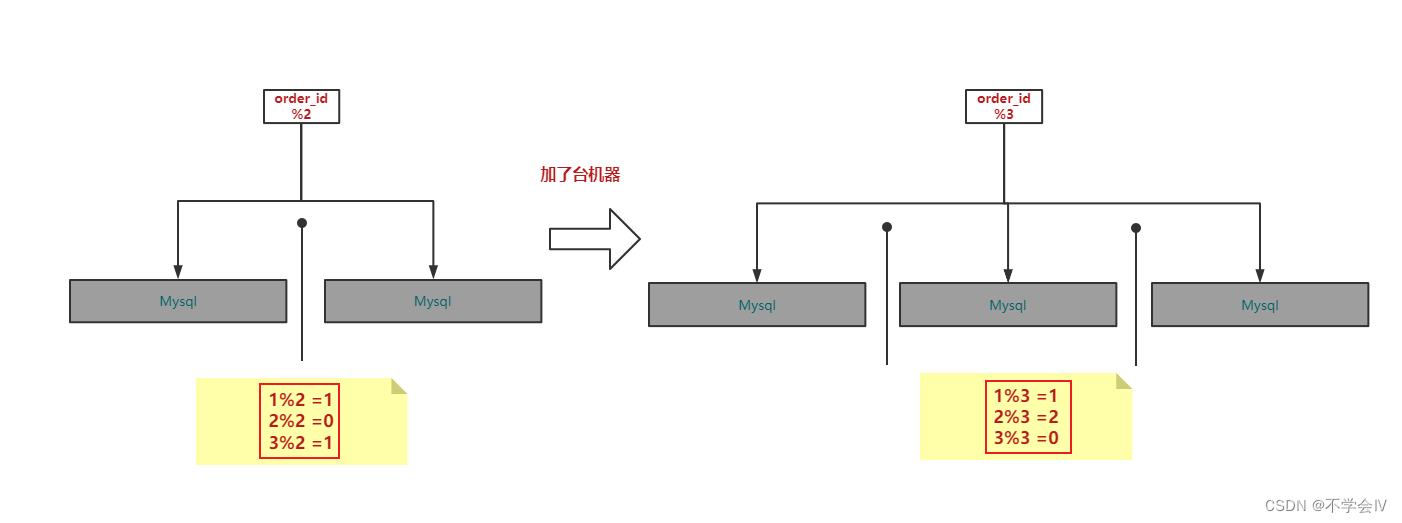
- 一致性哈希:当然还有其他方案,这里就直接告诉读者比较优解,该方案也是redis采用的,算法比较复杂,但如其名无论追加集群也不会导致order_id计算结果;
问题二:分库分表ID问题
通常我们单机应用的时候,我们完全可以采用主键自增,但在分布式集群的情况下,如果还使用自增那会出现不同库中自增的编号一样,也就是两个库的表里都会出现编号为1的数据,这种重复编号的出现十分破坏原子性,当然解决方案也是非常多,常见的雪花、美团的leaf、uuid等等都可以作为分布式id生成方案
问题三: 分库分表后的事务
在单机下我们的数据都在一个数据库中,MySQL会帮助我们管理事务,多表的修改可以统一的回滚,但分布式下不同数据库的事务并不互通,此时我们可以引入分布式XA事务解决方案
问题四:多表联合查询/多维度
也是本文的关键,如果我想在订单表下用用户维度查询,也就是上图的情况,应该怎么办,本文采用的解决方案也就是异构索引
为什么是异构索引
https://blog.csdn.net/u014231523/article/details/88096413
Canal
参考文档
ShardingSphere :: https://shardingsphere.apache.org/document/current/en/overview/
异构索引 :: https://blog.csdn.net/u014231523/article/details/88096413