欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131899662
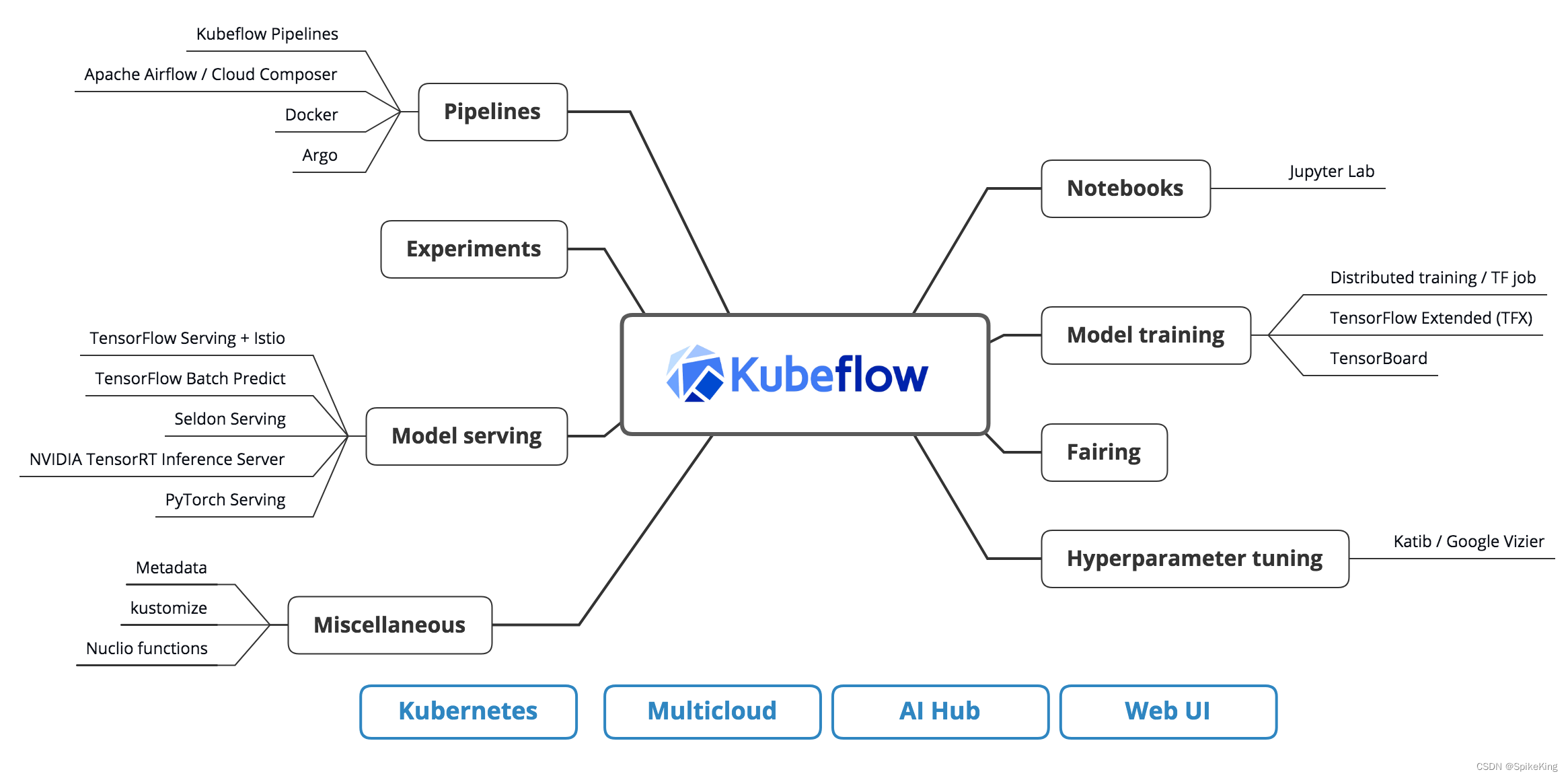
Kubeflow 是基于 Kubernetes 的机器学习工具包,提供了一套技术栈,包含了很多组件,用于支持机器学习的各个阶段,如数据处理、模型训练、超参数调优、模型部署、流水线管理等。目标是构建一个统一的机器学习平台,覆盖最主要的机器学习流程(数据 - 特征 - 建模 - 服务 - 监控),同时兼顾机器学习的实验探索阶段和正式的生产环境。
1. 前置准备 Docker 镜像
上传已准备好的 Docker 镜像至 Docker 管理网站。
在网页中,登录 Docker 服务器,选择 新建项目 - [Your Name],进入个人页面,没有镜像则暂时为空。
在服务器中,登录 Docker 服务器:
docker login [server name]
如无法登录,则需要管理员配置,或使用可登录的服务器
设置 BOS 命令:
alias bos='bcecmd --conf-path bcecmd/bceconf/ bos'
加载已有的 Docker Image,设置标签 (Tag),以及上传 Docker,如:
# 加载已保存的 Docker Image
docker image load -i af2_v1_0_2.tar.gz
docker images | grep "af"
# 提交 Tag
docker ps -l
docker commit [container id] af2:v1.01
# 准备远程 Tag
docker tag af2:v1.02 [your server path]/af2:v1.02
docker images | grep "af"
# 推送至远程
docker push [your server path]/af2:v1.02
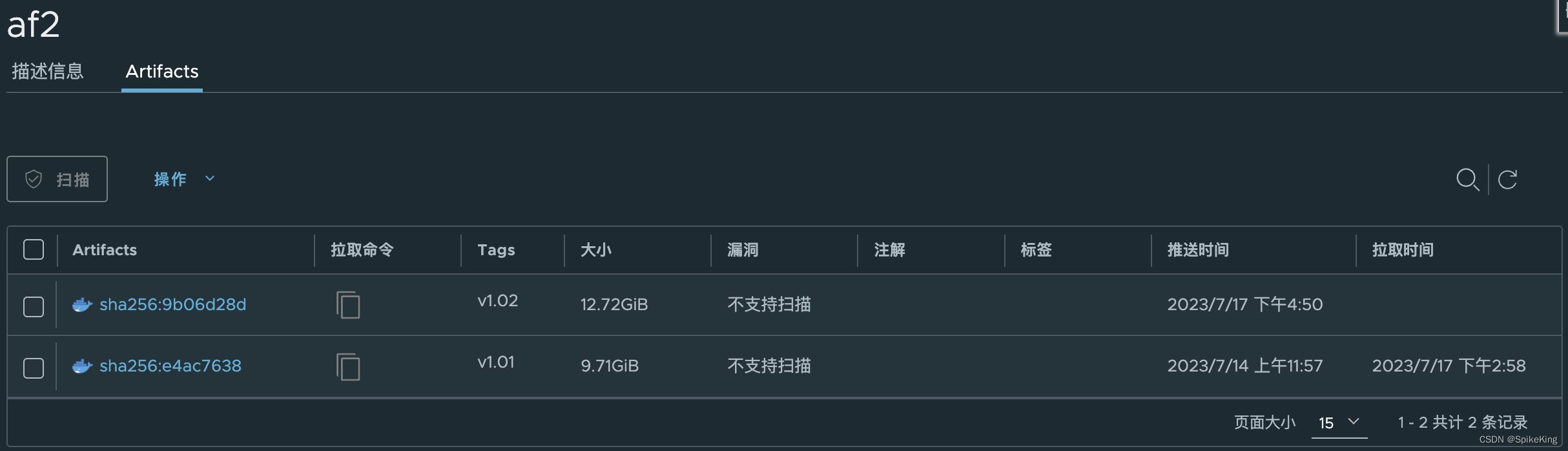
再次进入Harbor 页面查看,发现已上传的 Docker Image 以及不同版本,即:
2. POD 配置文件
配置文件,格式是yaml,如下:
apiVersion: batch/v1
kind: Job
metadata:
name: af2-predict-[your time] # 任务名称, 不能重复
spec:
completions: 1 # 总pod数量
parallelism: 1 # 并行运行的pod数量
backoffLimit: 0 # 重试次数,这里失败后不需要重试
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
labels:
file-mount: "true" # 这两个label必须加,kubeflow帮你自动配置一些基本环境
user-mount: "true"
spec:
nodeSelector:
gpu.device: "a10" # device是gpu类型,比如a10,a100
containers:
- name: sp
image: [your server path]/af2:v1.02 # 已准备的 cuda 环境,提供一个基础conda和cuda环境
imagePullPolicy: Always
resources:
limits:
cpu: 10
memory: "40G" # 所需内存,因为不同的模型预测对内存需求不同
nvidia.com/gpu: 1
command: ["/bin/sh", "-cl", "bash k8s_shells/shells/k8s_run.sh"] # 添加运行命令
workingDir: "af2/" # 默认的工作目录,就是你启动脚本的所在目录
env: # 这是把每个pod的名字注入环境变量,以便能够在程序里区分当前是在哪一个pod中
- name: PODNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
restartPolicy: Never
注意:
completions与parallelism,是所需的 pod 数量,以及可并行的 pod 数量,数值一般相同。
当运行时,遇到名称重复,无法运行,则需要重新命名,或者删除之前的 Job。操作如下:
# 查看当前全部job
kubectl get job
# 删除job
kubectl delete job [job name]
3. 运行脚本
基础的运行脚本如下:
- 激活 conda 环境,需要与docker环境对齐。
- 进入工作目录,执行运行脚本。
- 执行脚本:
/bin/sh -cl "bash k8s_shells/shells/k8s_run.sh"
即:
#!/bin/bash
source deactivate
conda info --envs
conda deactivate
# 与 Docker 中的环境对齐
conda activate /opt/conda/envs/alphafold
conda info --envs
printf "[Info] start run_alphafold.sh\n"
cd /[your path]/af2/ || exit
bash run_alphafold.sh \
-f mydata/test-case/idr_test_fasta/ \
-o mydata/test-case/idr_test_outputs/
printf "[Info] over run_alphafold.sh\n"
4. 调度 K8S
已编写 Template,调用 K8S 进行蛋白质结构预测,即:
kubectl apply -f k8s_template_idr_test1.yaml
查看日志:
kubectl get jobs # 查看 job
kubectl delete job [pod name] # 删除 job
kubectl get pods # 查看 pod
kubectl delete pod [pod name] # 删除 pod
kubectl logs [pod name]
已提交任务:
kubectl get pods
NAME READY STATUS RESTARTS AGE
af2-predict-20230724-1-ftjtl 0/1 Pending 0 2m9s
具体运行日志,已成功:
[CL] Amber relaxation param - use_gpu_relax: True
Using random seed 352410606854520785 for the data pipeline
[CL] The flag of use_saved_msa: True, run_only_msa: False, use_no_template: False.
Predicting T1157s1_A1008
[CL] Load saved extra 1 msas with 1 a3m and 0 sto.
[CL] merged.a3m msa size: 13535 sequences.