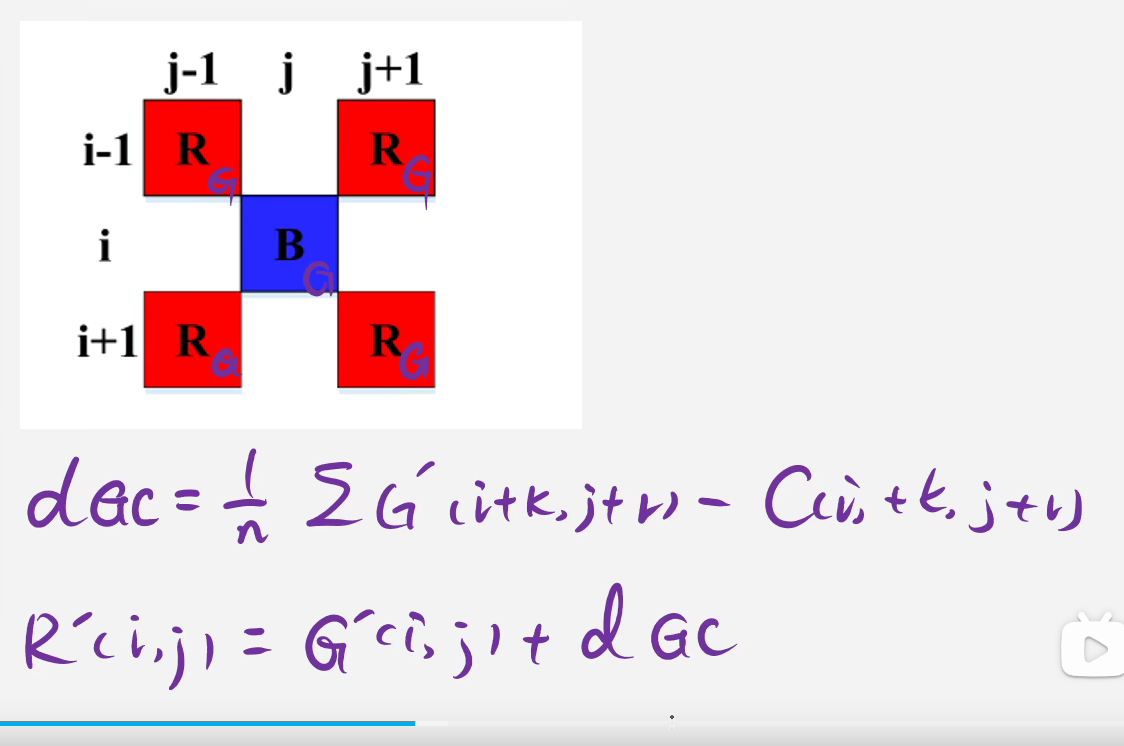
1. 冒泡排序
冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较相邻的元素,如果他们的顺序错误就交换他们。
def bubble_sort(arr):
# 遍历所有数组元素
for i in range(len(arr)):
# 最后i个元素是已经排序好的
for j in range(0, len(arr)-i-1):
# 如果当前元素大于下一个元素,则交换位置
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
arr = [11, 32, 21, 67, 54, 19]
sorted_arr = bubble_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(完全逆序)
- 最好情况:O(n)
- 平均情况:O(n2)
- 空间复杂度:O(1)(原地排序)
2. 选择排序
选择排序是一种简单直观的排序算法,它的工作原理是每次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排序完毕。
def select_sort(arr):
# 遍历所有数组元素
for i in range(len(arr)):
# 找到剩余未排序部分的最小元素索引
min_index = i
for j in range(i+1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
# 将找到的最小元素与第i个位置的元素交换
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
arr = [11, 32, 21, 67, 54, 19]
sorted_arr = select_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:O(n2)
- 空间复杂度:O(1)(原地排序)
3. 插入排序
插入排序是一种简单直观的排序算法,它的工作原理是通过构建有序序列,在已排序序列中从后向前扫描,找到相应位置并插入。
def insert_sort(arr):
# 遍历从1到倒数第二个元素
for i in range(1, len(arr)):
# 当前需要插入的元素
key = arr[i]
# 已排序部分的最后一个元素索引
j = i - 1
# 将arr[i]与已排序部分的元素逐个比较,如果比key大则后移一位
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
# 找到合适位置,插入key
arr[j + 1] = key
return arr
arr = [11, 32, 21, 67, 54, 19]
sorted_arr = insert_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(当数组是逆序时)
- 最好情况:O(n)(当数组已经有序时)
- 平均情况:O(n2)
- 空间复杂度:O(1)(原地排序)
4. 快速排序
快速排序是一种高效的排序算法,采用分治法策略。首先任意选取一个元素作为基准数据,将待排序列表中的数据分割成独立的两部分,比基准数据小的放在它左边,比基准数据大的放在它右边,此时第一轮数据排序完成。然后再按照此方法对两边的数据分别进行分割,直至被分割的数据只有一个或者零个时,递归结束。
def quick_sort(arr):
if len(arr) <= 1:
return arr
# 选择中间元素作为基准值
pivot = arr[len(arr)//2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
arr = [11, 32, 21, 67, 54, 19]
sorted_arr = quick_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(当分区极度不平衡时)
- 最好情况:O(n log n)
- 平均情况:O(n log n)
- 空间复杂度:O(n)(创建了新的列表)
5. 归并排序
归并排序是一种基于分治策略的高效排序算法,将数组不断地分成两半,然后递归地对两半进行排序,最后将排序好的两半合并在一起。
def merge_sort(arr):
if len(arr) <= 1:
return arr
# 分割阶段
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
# 合并阶段
return merge(left, right)
def merge(left, right):
"""
合并两个已排序的列表
"""
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 添加剩余元素
result.extend(left[i:])
result.extend(right[j:])
return result
arr = [38, 27, 43, 3, 9, 82, 10]
sorted_arr = merge_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [3, 9, 10, 27, 38, 43, 82]
复杂度分析
- 时间复杂度:O(n log n)
- 空间复杂度: O(n)(需要额外空间存储临时数组)
6. 堆排序
堆排序是一种基于二叉堆数据结构的高效排序算法。堆是一种特殊的完全二叉树,其中每个父节点的值都大于或等于其子节点的值(称为最大堆)或每个父节点的值都小于或等于其子节点的值(称为最小堆)。
import heapq
def heap_sort(arr):
# 构建最小堆
heapq.heapify(arr)
return [heapq.heappop(arr) for _ in range(len(arr))]
arr = [12, 11, 15, 3, 21, 9]
sorted_arr = heap_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [3, 9, 11, 12, 15, 21]
复杂度分析
- 时间复杂度:
- 建堆过程:O(n)
- 每次堆化:O(log n)
- 总体时间复杂度:O(n log n)
- 空间复杂度: O(1)(原地排序)
7. 计数排序
计数排序是一种非比较排序算法,适用于对一定范围内的整数进行排序。它统计数组中每个元素出现的次数,然后根据统计结果将元素放回正确的位置。
def count_sort(arr):
if len(arr) == 0:
return arr
# 找到数组中的最大值和最小值
max_val = max(arr)
min_val = min(arr)
# 创建计数数组,初始化为0
count = [0] * (max_val - min_val + 1)
# 统计每个元素出现的次数
for num in arr:
count[num - min_val] += 1
# 重建排序后的数组
sorted_arr = []
for i in range(len(count)):
sorted_arr.extend([i + min_val] * count[i])
return sorted_arr
arr = [4, 2, 5, 1, 8]
sorted_arr = count_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [1, 2, 4, 5, 8]
复杂度分析
- 时间复杂度:O(n+k),其中n是元素数量,k是数据范围
- 空间复杂度:O(n+k)
8. 基数排序
基数排序是一种非比较型整数排序算法,它通过将整数按位切割成不同的数字,然后按每个位数分别比较排序。基数排序可以采用最低位优先(LSD)或最高位优先(MSD)两种方式。
def radix_sort(arr):
# 找到数组中的最大数,确定排序的轮数
max_num = max(arr)
# 从个位开始
exp = 1
while max_num // exp > 0:
counting_sort_by_digit(arr, exp)
exp *= 10
return arr
def counting_sort_by_digit(arr, exp):
n = len(arr)
output = [0] * n
count = [0] * 10
# 统计当前位数的数字出现次数
for num in arr:
digit = (num // exp) % 10
count[digit] += 1
# 计算累加计数
for i in range(1, 10):
count[i] += count[i-1]
# 反向填充输出数组(保证稳定性)
for i in range(n-1, -1, -1):
digit = (arr[i] // exp) % 10
output[count[digit] - 1] = arr[i]
count[digit] -= 1
# 将排序结果复制回原数组
for i in range(n):
arr[i] = output[i]
arr = [170, 45, 75, 90, 802, 24, 2, 66]
sorted_arr = radix_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [2, 24, 45, 66, 75, 90, 170, 802]
复杂度分析
- 时间复杂度:O(d*(n+k)),其中d是最大数字的位数,n是元素数量,k是基数
- 空间复杂度:O(n+k)
9. 桶排序
桶排序是一种分布式排序算法,它将元素分到有限数量的桶里,每个桶再分别排序。
def bucket_sort(arr, bucket_size=5):
if len(arr) == 0:
return arr
# 找到最大值和最小值
max_val = max(arr)
min_val = min(arr)
# 计算桶的数量
bucket_count = (max_val - min_val) // bucket_size + 1
buckets = [[] for _ in range(bucket_count)]
# 将元素分配到各个桶中
for num in arr:
index = (num - min_val) // bucket_size
buckets[index].append(num)
# 对每个桶进行排序
sorted_arr = []
for bucket in buckets:
# 使用内置的sorted函数
sorted_arr.extend(sorted(bucket))
return sorted_arr
arr = [29 ,25, 13, 21, 8, 43]
sorted_arr = bucket_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [8, 13, 21, 25, 29, 43]
复杂度分析
- 时间复杂度:
- 平均情况:O(n+k),其中k是桶的数量
- 最坏情况:O(n2)(当所有元素都分配到同一个桶中)
- 空间复杂度:O(n+k)
10. 希尔排序
希尔排序是插入排序的一种高效改进版本,也称为缩小增量排序。它通过将原始列表分割成多个子列表来进行插入排序,随着算法的进行,子列表的长度逐渐增大,最终整个列表变为一个子列表完成排序。
def shell_sort(arr):
n = len(arr)
# 初始间隔(gap)设置为数组长度的一半
gap = n // 2
while gap > 0:
# 对各个间隔分组进行插入排序
for i in range(gap, n):
temp = arr[i]
j = i
# 对子列表进行插入排序
while j >= gap and arr[j - gap] > temp:
arr[j] = arr[j - gap]
j -= gap
arr[j] = temp
# 缩小间隔
gap = gap // 2
return arr
arr = [9 , 8, 3, 6, 5, 7, 1]
sorted_arr = shell_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [1, 3, 5, 6, 7, 8, 9]
复杂度分析
- 时间复杂度:
- 平均情况:O(n1.3)到O(n1.5)
- 最坏情况:O(n*n)
- 最好情况:O(n log n)
- 空间复杂度:O(1)(原地排序)
11. 拓扑排序
拓扑排序是针对有向无环图的线性排序算法,使得对于图中的每一条有向边(u, v),u在排序中总是位于v的前面。
from collections import deque
def topo_sort_kahn(graph):
# 计算所有节点的入度
in_degree = {node: 0 for node in graph}
for node in graph:
for neighbor in graph[node]:
in_degree[neighbor] += 1
# 初始化队列,将所有入度为0的节点加入队列
queue = deque([node for node in graph if in_degree[node] == 0])
topo_order = []
while queue:
current = queue.popleft()
topo_order.append(current)
# 减少所有邻居的入度
for neighbor in graph[current]:
in_degree[neighbor] -= 1
# 如果邻居的入度变为0,加入队列
if in_degree[neighbor] == 0:
queue.append(neighbor)
# 检查是否所有节点都被排序(无环)
if len(topo_order) == len(graph):
return topo_order
else:
return [] # 图中存在环,无法进行拓扑排序
# 定义有向无环图(邻接表表示)
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
print("Kahn算法拓扑排序结果:", topo_sort_kahn(graph))
输出结果:
Kahn算法拓扑排序结果: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’]
复杂度分析
- 时间复杂度:O(V+E),其中V是顶点数,E是边数
- 空间复杂度:O(V)(存储入度或递归栈)