2023 年第二届钉钉杯大学生大数据挑战赛初赛 初赛 A:智能手机用户监测数据分析 问题二分类与回归问题Python代码分析

相关链接
【2023 年第二届钉钉杯大学生大数据挑战赛初赛】 初赛 A:智能手机用户监测数据分析 问题一Python代码分析
【2023 年第二届钉钉杯大学生大数据挑战赛初赛】 初赛 A:智能手机用户监测数据分析 问题二分类与回归问题Python代码分析
1 题目
2023 年第二届钉钉杯大学生大数据挑战赛初赛题目 初赛 A:智能手机用户监测数据分析
一、问题背景
近年来,随着智能手机的产生,发展到爆炸式的普及增长,不仅推动了中 国智能手机市场的发展和扩大,还快速的促进手机软件的开发。近年中国智能手 机市场品牌竞争进一步加剧,中国超越美国成为全球第一大智能手机市场。手机 软件日新月异,让人们更舒适的使用手机,为人们的生活带来很多乐趣,也产生 了新的群体“低头一族”。手机软件进入人们的生活,游戏、购物、社交、资讯、理财等等APP吸引着、方便着现代社会的人们,让手机成为人们出门的必备物 品。该数据来自某公司某年连续30天的4万多智能手机用户的监测数据,已经做 了脱敏和数据变换处理。每天的数据为1个txt文件,共10列,记录了每个用户(以uid为唯一标识)每天使用各款APP(以appid为唯一标识)的起始时间,使 用时长,上下流量等。具体说明见表1。此外,有一个辅助表格, app_class.csv,共两列。第一列是appid,给出4000多个常用APP所属类别(app_class),比如:社交类、影视类、教育类等,用英文字母a-t表示,共20个常 用得所属类别,其余APP不常用,所属类别未知。
表 1
| 变量编号 | 变量名 | 释义 |
|---|---|---|
| 1 | uid | 用户的id |
| 2 | appid | APP的id(与app_class文件中的第一列对应) |
| 3 | app_type | APP类型:系统自带、用户安装 |
| 4 | start_day | 使用起始天,取值1-30(注:第一天数据的头两行的使用起始天取 值为0,说明是在这一天的前一天开始使用的) |
| 5 | start_time | 使用起始时间 |
| 6 | end_day | 使用结束天 |
| 7 | end_time | 使用结束时间 |
| 8 | duration | 使用时长(秒) |
| 9 | up_flow | 上行流量 |
| 10 | down_flow | 下行流量 |
二、解决问题
- 聚类分析
(一)根据用户常用所属的20类APP的数据对用户进行聚类,要求至少给出三种不同的聚 类算法进行比较,选择合理的聚类数量K值,并分析聚类结果。
(二)根据聚类结果对不同类别的用户画像,并且分析不同群体用户的特征。(用户画 像定义:根据用户的属性,偏好,行为习惯等信息对用户打标签,用以描述不同群体的用户 行为,从而针对不同群体的用户推荐不同所属类别的APP产品。)
- APP使用情况预测分析:要研究的问题是通过用户的APP使用记录预测用户未来是否使 用APP(分类问题)及使用时长(回归问题)
(一)对用户使用APP的情况进行预测,根据用户第111天的a类APP的使用情况,来预测用户在第1221天是否会使用该类APP。给出预测结果和真实结果相比的准确率。(注:测 试集不能参与到训练和验证中,否则作违规处理)
(二)对用户使用APP的情况进行预测,根据用户第1~11天的a类APP的使用情况,来预测 第12~21天用户使用a类APP的有效日均使用时长。评价指标选用MMSE。
M
M
S
E
=
∑
(
y
i
−
y
i
^
)
∑
(
y
i
−
y
i
‾
)
MMSE = \sqrt{\frac{\sum(y_i-\hat{y_i})}{\sum(y_i-\overline{y_i})}}
MMSE=∑(yi−yi)∑(yi−yi^)
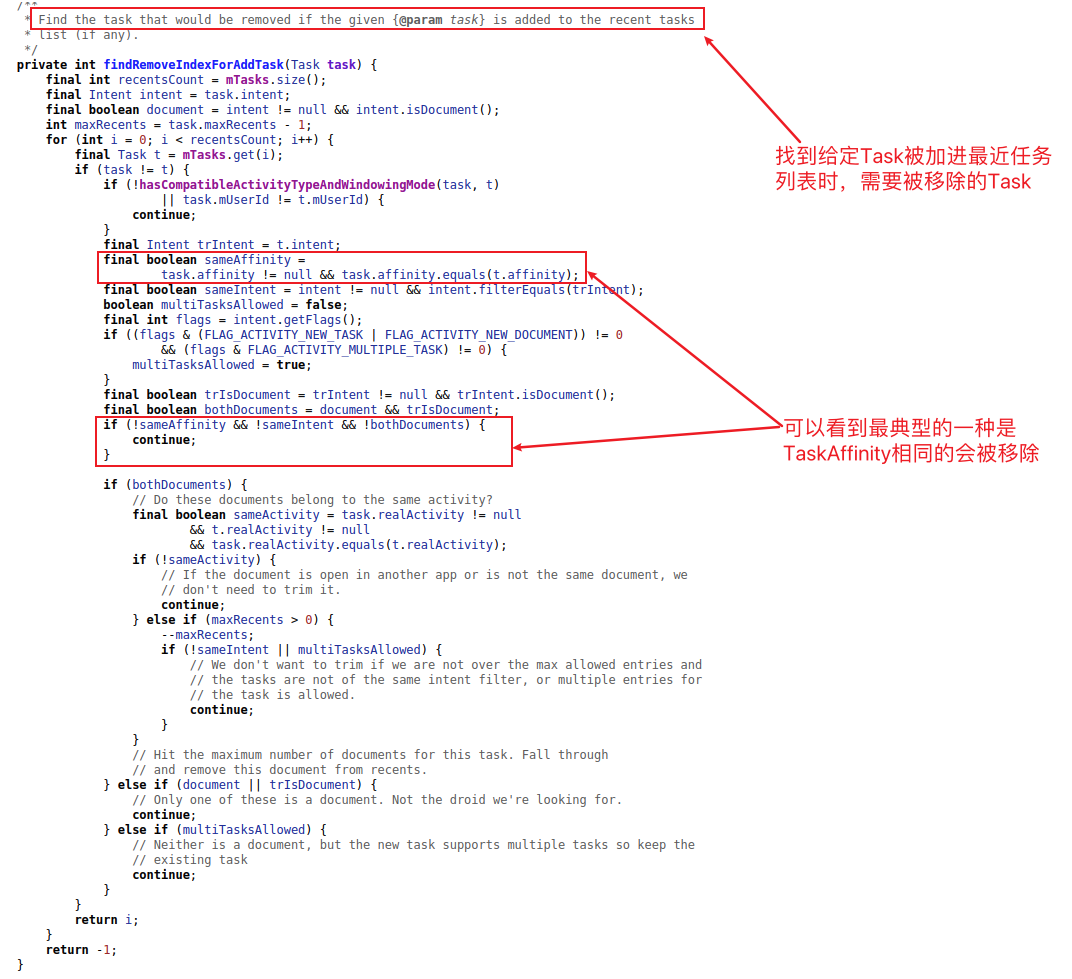
式中, y i y_i yi表示使用时长的实际值; y i ^ \hat{y_i} yi^表示使用时长的预测值; y i ‾ \overline{y_i} yi表示所有用户的实际使用时长的平均值。给出预测结果和真实结果之间的NMSE。(注:测试集不能参与到训练和验证中, 否则作违规处理)
data.csv数据来自某公司某年连续30天的4万多智能手机用户的监测数据,表格式如下,请根据用户第1~11天的a类APP的使用情况,采用XGBoost模型预测 第12~21天用户使用a类APP的有效日均使用时长。评价指标选用MMSE。
| 变量编号 | 变量名 | 释义 |
|---|---|---|
| 1 | uid | 用户的id |
| 2 | category | APP的类别(a到z类,共26类) |
| 3 | app_type | APP类型:系统自带、用户安装 |
| 4 | start_day | 使用起始天,取值1-30(注:第一天数据的头两行的使用起始天取 值为0,说明是在这一天的前一天开始使用的) |
| 5 | start_time | 使用起始时间 |
| 6 | end_day | 使用结束天 |
| 7 | end_time | 使用结束时间 |
| 8 | duration | 使用时长(秒) |
| 9 | up_flow | 上行流量 |
| 10 | down_flow | 下行流量 |
2 建模思路
第一题:
-
数据预处理:对用户常用的20类APP数据,进行数据清洗和特征提取。可以使用PCA、LDA算法进行降维,减小计算复杂度。
-
聚类算法:
a. K-means: 进行数据聚类时,选择不同的K值进行多次试验,选取最优的聚类结果。可以使用轮廓系数、Calinski-Harabaz指数等评价指标进行比较和选择。
b. DBSCAN: 利用密度对数据点进行聚类,不需要预先指定聚类的数量。使用基于密度的聚类算法时,可以通过调整半径参数和密度参数来得到不同聚类效果。
c. 层次聚类:可分为自顶向下和自底向上两种方式。通过迭代计算每个数据点之间的相似度,将数据点逐渐合并,最后得到聚类结果。d.改进的聚类算法
e. 深度聚类算法
-
聚类结果分析:选择最优的聚类结果后,对不同类别用户进行画像。分析每个类别的用户行为特征(如使用时段、使用频率、使用时长、使用偏好等),根据用户画像为用户打标签。根据用户标签,推荐不同所属类别的APP产品。
第二题:
- 数据预处理:对用户APP使用记录数据,进行数据清洗和特征提取,例如统计用户每种APP的使用次数、时长等特征量。
- 分类问题预测:建立分类模型,利用用户1~11天的APP使用记录,采用特征工程对数据进行处理,并选择合适的分类算法进行训练和测试,如决策树、随机森林、支持向量机、改进的机器学习分类算法。最后使用测试集进行模型验证,评价模型的准确率。
- 回归问题预测:建立回归模型,利用用户1~11天的APP使用记录,采用特征工程对数据进行处理,并选择合适的回归算法进行训练和测试,如线性回归、决策树回归、神经网络回归。使用测试集进行模型验证,评价模型的准确性,可以使用NMSE评价指标。
3 问题一实现代码
【2023 年第二届钉钉杯大学生大数据挑战赛初赛】 初赛 A:智能手机用户监测数据分析 问题一Python代码分析
4 问题二实现代码
4.1 分类问题:预测是否会使用a类APP
(1)特征工程部分,见问题一博客
【2023 年第二届钉钉杯大学生大数据挑战赛初赛】 初赛 A:智能手机用户监测数据分析 问题一Python代码分析
(2)数据读取
1-11天的数据作为训练集,12-21天的数据作为测试集
建立分类,注意,一个用户有多次使用记录,在测试集中,需要根据用户id进行去重后,再预测
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
# 读取全部数据集
# 读取训练集
train_folder_path = '初赛数据集/训练集'
train_dfs = []
for filename in os.listdir(train_folder_path):
if filename.endswith('.txt'):
csv_path = os.path.join(train_folder_path, filename)
tempdf = pd.read_csv(csv_path)
train_dfs.append(tempdf)
train_df = pd.concat(train_dfs,axis=0)
# 读取测试集
test_folder_path = '初赛数据集/测试集'
test_dfs = []
for filename in os.listdir(test_folder_path):
if filename.endswith('.txt'):
csv_path = os.path.join(test_folder_path, filename)
tempdf = pd.read_csv(csv_path)
test_dfs.append(tempdf)
test_df = pd.concat(test_dfs,axis=0)
# 提取特征和标签
X_train = train_df.drop(['category','uid','appid'], axis=1)
y_train = train_df['category']
X_test = test_df.drop(['category','uid','appid'], axis=1)
y_test = test_df['category']
(3)模型训练
# 训练决策树模型
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_y_pred = dt_model.predict(X_test)
dt_accuracy = accuracy_score(y_test, dt_y_pred)
print('决策树模型的准确率:', dt_accuracy)
决策树模型的准确率: 0.8853211009174312
# 训练随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
rf_y_pred = rf_model.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_y_pred)
print('随机森林模型的准确率:', rf_accuracy)
随机森林模型的准确率: 0.9724770642201835
# 训练支持向量机模型
svc_model = SVC(kernel='linear')
svc_model.fit(X_train, y_train)
svc_y_pred = svc_model.predict(X_test)
svc_accuracy = accuracy_score(y_test, svc_y_pred)
print('支持向量机模型的准确率:', svc_accuracy)
支持向量机模型的准确率: 0.9513251783893986
4.2 回归问题
(1)特征提取部分
- 过去11天的每天时间特征,day、hour、minute,还可以增加节假日和周末和工作日等时间特征
- 过去11天用户对a类APP的总使用时长
- 过去11天用户对a类APP的使用次数
- 过去11天用户对a类APP的曲线趋势
- 其他与a类APP相关的特征
读取数据
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import holidays
import os
# 加载 APP 类别文件
app_class = pd.read_csv('初赛数据集/app_class.csv',names=['appid','app_type'])
app_type_dict = dict(zip(app_class['appid'], app_class['app_type']))
# 读取训练集,该文件夹下面包括day01.txt到day21.txt,总共21个文件
train_folder_path = '初赛数据集/问题2数据集'
train_dfs = []
cols = ['uid','appid','app_type','start_day','start_time','end_day','end_time','duration','up_flow','down_flow']
for filename in os.listdir(train_folder_path):
if filename.endswith('.txt'):
csv_path = os.path.join(train_folder_path, filename)
tempdf = pd.read_csv(csv_path,names=cols)
train_dfs.append(tempdf)
data = pd.concat(train_dfs,axis=0)
data.shape
数据预处理
# 处理app类别
data['category'] = data['appid'].map(app_type_dict)
# 处理时间格式
data['start_time'] = pd.to_datetime(data['start_time'])
data['end_time'] = pd.to_datetime(data['end_time'])
# 构建"使用时长(小时)"特征
data['duration_hour'] = (data['end_time'] - data['start_time']).dt.seconds / 3600
# 缺失值处理
data = data.dropna()
# 提取时间特征
data['start_time_day'] = data.start_time.dt.day
data['start_time_hour'] = data.start_time.dt.hour
data['start_time_minute'] = data.start_time.dt.minute
# 异常值处理(例如使用时长小于0或大于24小时的数据)
data = data[(data['duration_hour'] >= 0) & (data['duration_hour'] <= 24)]
# 构建训练集和测试集
train = data[data['start_day'] <= 11]
test = data[(data['start_day'] >= 12) & (data['start_day'] <= 21)]
特征工程
# 提取过去11天用户对a类APP的总使用时长
。。。略
# 提取过去11天用户对a类APP的使用次数
。。。略
# 将特征合并到训练集和测试集中
train = pd.merge(train, total_duration, on='uid', how='left')
train = pd.merge(train, count, on='uid', how='left')
test = pd.merge(test, total_duration, on='uid', how='left')
test = pd.merge(test, count, on='uid', how='left')
# 缺失值处理
train = train.fillna(0)
test = test.fillna(0)
# 选择必要的特征
features = ['a_total_duration', 'a_count','start_time_day','start_time_hour','start_time_minute']
# 构建训练集和测试集的特征矩阵和目标变量
。。。略
X_test = test[features].values
mean_test_duration = test.groupby('uid')['duration_hour'].mean()
y_test = test['uid'].map(dict(mean_test_duration))
(2)模型训练部分
使用XGB回归模型,还可以使用LGB、线性回归、决策树回归、神经网络回归等模型,此外还要调参,机器学习方法可以考虑网格寻优的方法。
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
# 特征归一化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)
# XGBoost回归模型,还可以使用线性回归、决策树回归、神经网络回归
xgbmodel = xgb.XGBRegressor(
objective='reg:squarederror',
n_jobs=-1,
n_estimators=1000,
max_depth=7,
subsample=0.8,
learning_rate=0.05,
gamma=0,
colsample_bytree=0.9,
random_state=2021, max_features=None, alpha=0.3)
# 训练模型
xgbmodel.fit(X_train, y_train)

(3)模型评价
根据题目给的公式实现,公式如下
M
M
S
E
=
∑
(
y
i
−
y
i
^
)
∑
(
y
i
−
y
i
‾
)
MMSE = \sqrt{\frac{\sum(y_i-\hat{y_i})}{\sum(y_i-\overline{y_i})}}
MMSE=∑(yi−yi)∑(yi−yi^)
from sklearn.metrics import mean_squared_error, mean_absolute_error
def MMSE(y_test, y_pred):
# 计算实际值与预测值之间的平均误差
error = y_test - y_pred
# 计算分子和分母
numerator = np.sum(np.square(error))
denominator = np.sum(np.square(y_test - np.mean(y_test)))
# 计算 MMSE
mmse = np.sqrt(numerator / denominator)
return mmse
# 对测试集进行预测
y_pred = xgbmodel.predict(X_test)
# 计算评价指标
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
mmse = MMSE(y_test, y_pred)
print("MMSE: {:.4f},MSE: {:.4f}, MAE: {:.4f}".format(mmse,mse, mae))
MMSE: 1.0709,MSE: 0.0432, MAE: 0.1181
4 下载
见知乎文章底部,下载后包括所有问题的完整代码
zhuanlan.zhihu.com/p/643785015