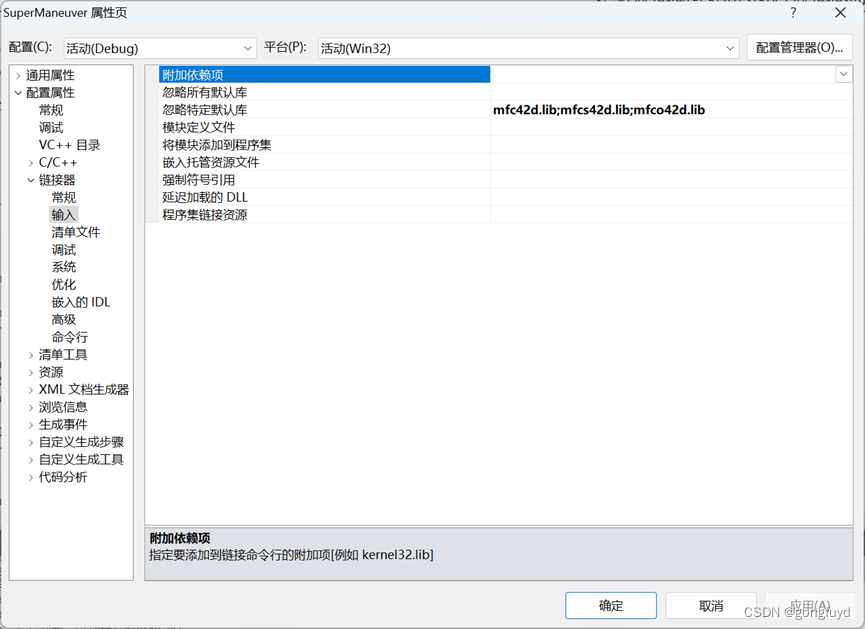
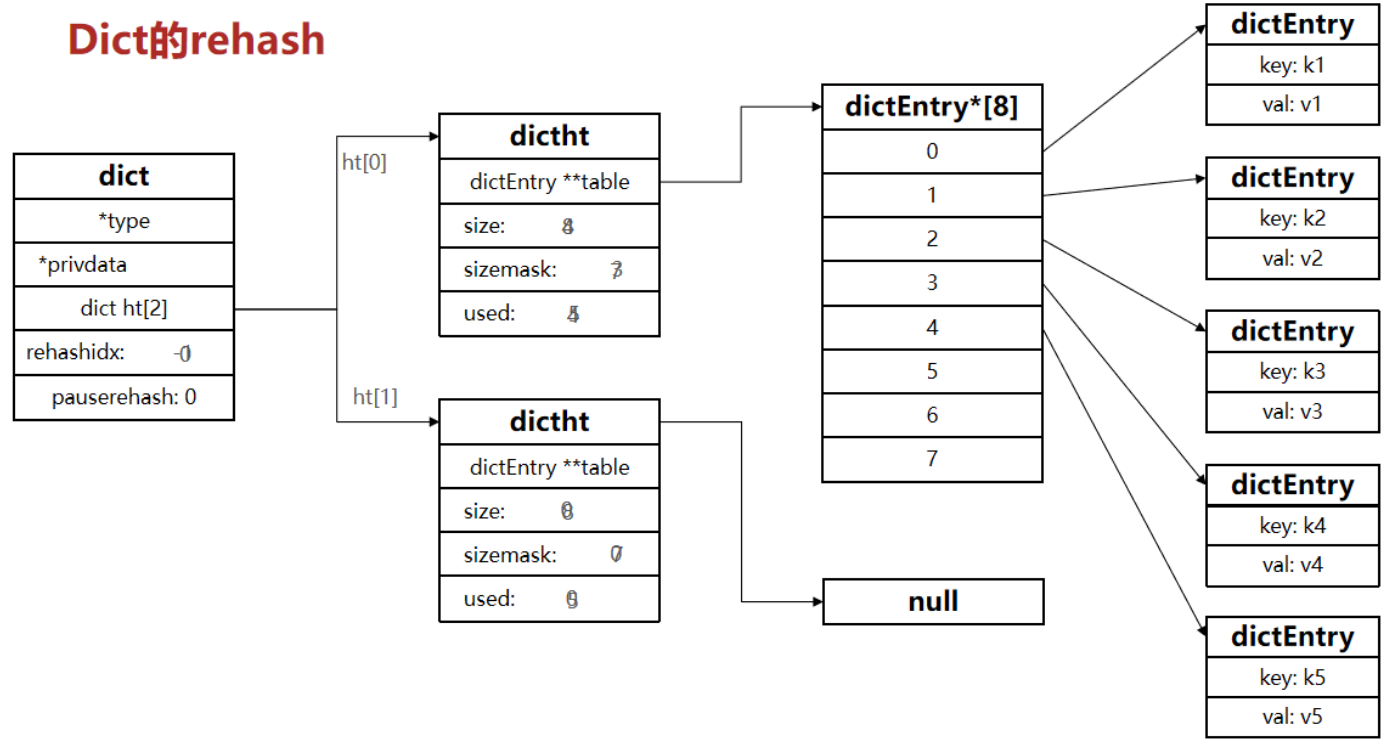
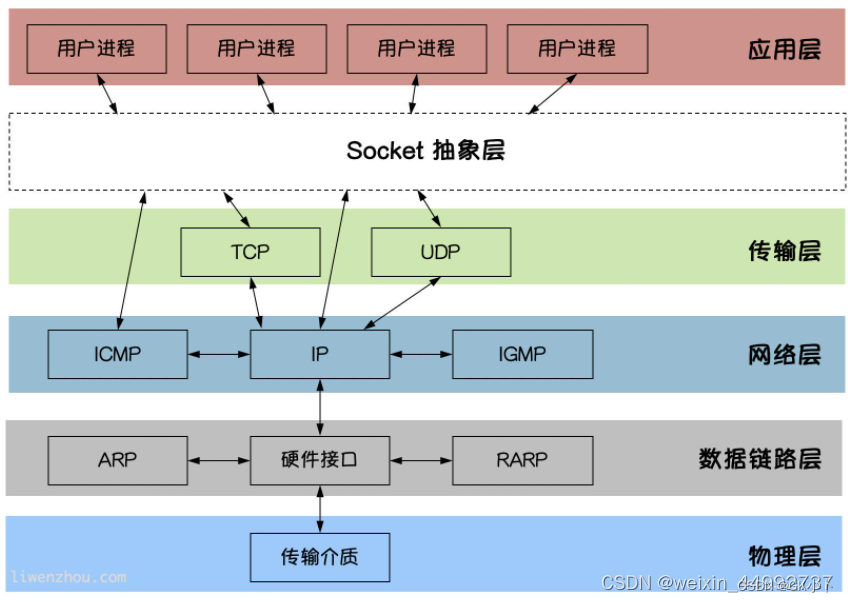
MTU和MSS的区别
MTU和MSS的区别
TCP 的 MTU & MSS
MTU是在那一层?MSS在那一层?
MTU是在数据链路层的载荷大小也就是传给网络层的大小,mss是在传输层的载荷大小也就是传给应用层的大小
mss是根据mtu得到的
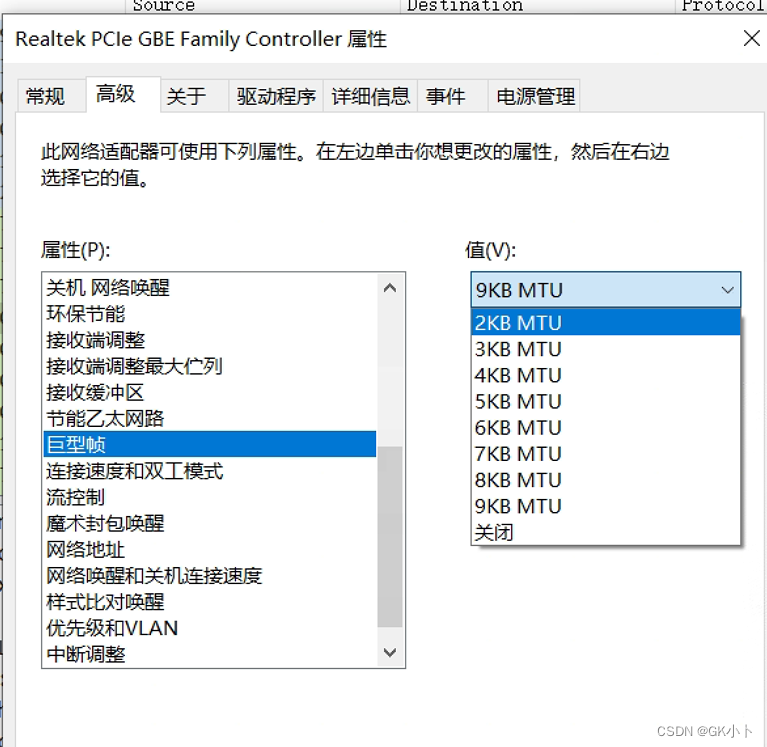
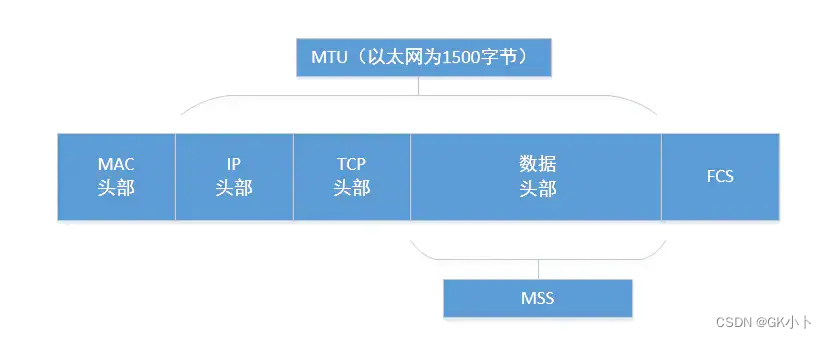
1、MTU: Maximum Transmit Unit,最大传输单元,即物理接口(数据链路层)提供给其上层(通常是IP层)最大一次传输数据的大小;以普遍使用的以太网接口为例,缺省MTU=1500 Byte,(缺省:系统默认状态)这是以太网接口对IP层的约束,如果IP层有<=1500 byte 需要发送,只需要一个IP包就可以完成发送任务;如果IP层有> 1500 byte 数据需要发送,需要分片才能完成发送,这些分片有一个共同点,即IP Header ID相同。
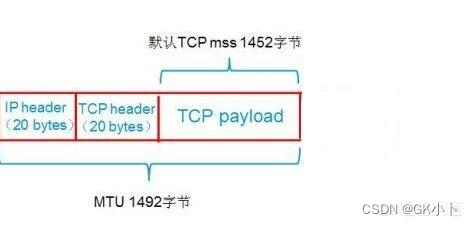
数据链路层,MTU为1500字节,包括IP首部等开销。一般IP首部为20字节,UDP首部为8字节,数据的有效负荷(payload)部分预留是1500-20-8=1472字节。如果数据部分大于1472字节,(TCP则为1500-20-20=1460)就会出现分片现象。
2、MSS:Maximum Segment Size ,最大报文段长度,TCP提交给IP层最大分段大小,不包含TCP Header和 TCP Option,只包含TCP Payload ,MSS是TCP用来限制application层最大的发送字节数。如果底层物理接口MTU= 1500 byte,则 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果application 有2000 byte发送,需要两个segment才可以完成发送,第一个TCP segment = 1460,第二个TCP segment = 540。
终端MSS是怎么确定的?
为了达到最佳的传输效能TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。

如上图 端口53842 为 A; 端口 80 为 B。
见上图,TCP SYN消息,A 发送给B 的MSS= 1460,B发给A最大MSS为1452 。
以后每次通讯,可以看出发送的数据都是 1452 byte。最终为双方中MSS较小的。
path MTU
上述协商的为收发双方的MTU,为终端MTU,但中间路由过程也会经过多个路由设备也会有各自的MTU(path MTU),这时最终的MTU该怎么确定?
1、不确定path MTU,经过时IP分片
由中间路由设备进行IP数据包分片,最终在接收端整合
一个值得注意的是,在分片的数据中,传输层的首部只会出现在第一个分片中,IP数据报分片后,只有第一片带有传输层首部(UDP或ICMP等),后续分片只有IP首部和应用数据,到了目的地后根据IP首部中的信息在网络层进行重组,这一步骤对上层透明,即传输层根本不知道IP层发生了分片与重组。而TCP报文段的每个分段中都有TCP首部,到了目的地后根据TCP首部的信息在传输层进行重组。
TCP分段仅发生在发送端,这是因为在传输过程中,TCP分段是先被封装成IP数据报,再封装在以太网帧中被链路所传输的,并且在端到端路径上通常不会有工作在三层以上,即传输层的设备,故TCP分段不会发生在传输路径中间的某个设备中,在发送端TCP传输层分段后,在接收端TCP传输层重组。
IP分片不仅会发生在在使用UDP、ICMP等没有分段功能的传输层协议的数据发送方,更还会发生在传输途中,甚至有可能都会发生,这是因为原本的大数据报被分片后很可能会经过不同MTU大小的链路,一旦链路MTU大于当前IP分片大小,则需要在当前转发设备(如路由器)中再次分片,但是各个分片只有到达目的地后才会在其网络层重组,而不是像其他网络协议,在下一跳就要进行重组。
发送端进行TCP分段后就一定不会在IP层进行分片,因为MSS本身就是基于MTU推导而来,TCP层分段满足了MSS限制,也就满足了MTU的物理限制。但在TCP分段发生后仍然可能发生IP分片,这是因为TCP分段仅满足了通信两端的MTU要求,传输路径上如经过MTU值比该MTU值更小的链路,那么在转发分片到该条链路的设备中仍会以更小的MTU值作为依据再次分片。当然如果两个通信主机直连,那么TCP连接协商得到的MTU值(两者网卡MTU较小值)就是端到端的路径MTU值,故发送端只要做了TCP分段,则在整个通信过程中一定不会发生IP分片。
2、确定path MTU,将MSS设置为整个链路中最小的
【网络】MTU和MSS
不确定path MTU,经过时IP分片会有什么问题呢?
特别地,对中途发生分片的数据报而言,即使只丢失其中一片数据也要重传整个数据报(这里既然有重传,说明传输层使用的是具有重传功能的协议,如TCP协议。而UDP协议不可靠,即使丢包了也不在意更不会重传,所以必须在应用层实现可靠通信的逻辑),这是因为IP本身没有重传机制,只能由更高层,比如传输层的TCP协议,来负责重传以确保可靠传输。于是,当来自同一个TCP报文段封装得到的原始IP数据报中的的某一片丢失后,接收端TCP迟迟接受不到完整报文段,它就会认为该报文段(包括全部IP分片)已丢失,TCP之后由于超时会收到三个冗余ACK就会重传整个TCP报文段,该报文段对应于一份IP数据报,可能有多个IP分片,但没有办法单独重传其中某一个数据分片,只能重传整个报文段。
分片或分段发生的根源都在于MTU这一数据链路层限制,由于更靠近数据链路层的IP层在感知MTU方面相比于传输层具备天然的优势,在大小超过MTU的大数据报传输问题出现伊始,IP层分片技术就成为主流解决方案。而分片带来的诸多开销(额外首部、复杂处理逻辑)以及其甚至可能在端到端的传输过程中多次发生在网络转发设备(路由器)的问题,让网络协议设计者们又要费尽心思地在端到端通信过程中避免IP分片。
TCP分段技术被提出后,在一定程度上减少了IP分片,但正如上一节末尾所言,TCP分段仅是在发送端避免了IP分片,但是却不能保证在整个端到端通信路径上不会发生IP分片,因为路径上经常会有MTU值小于该TCP连接协商得到的MTU值的链路,在转发至该段链路之前转发设备仍需分片,所以说TCP分段并不能完全避免IP分片。
那么如何才能彻底避免分片呢?
答案其实不难想到:如果能在TCP连接双方正式通信之前,就能通过某种方式预先知道端到端路径的MTU,即路径中包含的各条链路的MTU最小值(称为路径MTU,Path MTU),这一预先获知路径MTU的过程,称为路径MTU发现(Path MTU Discovery),这样此后每次通信都会基于此MTU推导得到的MSS值在发送方TCP层处执行分段。
路径MTU发现如何实现呢?
大家都记得IP首部中有三个标志位,第一位预留,第二位DF(Don’t Fragment),第三位MF(More Fragments)。其中DF如果为1,意思是这个IP数据报在传输的过程中不能分片,如果此IP数据报大于网络接口的MTU,请直接丢弃,并发送消息告诉源主机已丢包。什么消息呢?ICMP的消息,告诉包因为太大了,因为不能分片所以丢弃了,并告诉源主机请重新发送不超过MTU的数据报,那发什么样的ICMP消息呢?再回顾一下ICMP首部结构,有一个Type字段,还有Code字段,发送Type=3, Code=4, MTU=该接口的MTU值X的消息既可以了。当这个ICMP消息到达IP数据报的源主机,源主机知道原来是IP数据报太大了,那最大可以发送多大的包呢?ICMP消息里有,那就是MTU=丢弃该包的网络接口的MTU值X,于是源主机再次发送不超过MTU=X的数据报就可以避免在传输路径上的IP分片。
注意
路径MTU发现看似完美避免了IP分片的问题,但同时又带来了新的问题:如果ICMP消息最终没能到达源主机怎么办?很显然该IP数据报就被静静丢弃了,TCP连接超时而被断开。ICMP为什么回不来?一般是被防火墙或路由器的访问控制列表(Access Control List, ACL)给无情拒绝了。如果你可以管理并配置这些设备,只要允许ICMP Type=3, Code=4 的消息可以通过即可,否则只有老老实实关闭路径MTU发现功能了,因为至少分片还能通信,而避免分片则彻底无法通信了…
TCP分段与IP分片的区别与联系
TCP分段准确的说应该是TCP载荷分段
IP分片准确的来说应该是数据链路层载荷分片
TCP分段与IP分片的区别与联系
简而言之:
UDP不会分段,就由IP来分片。TCP会分段,当然就不用IP来分了!
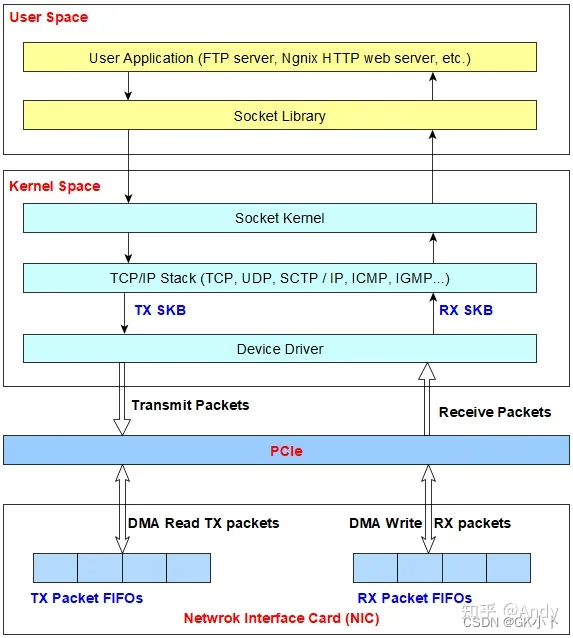
网卡收发包系统结构
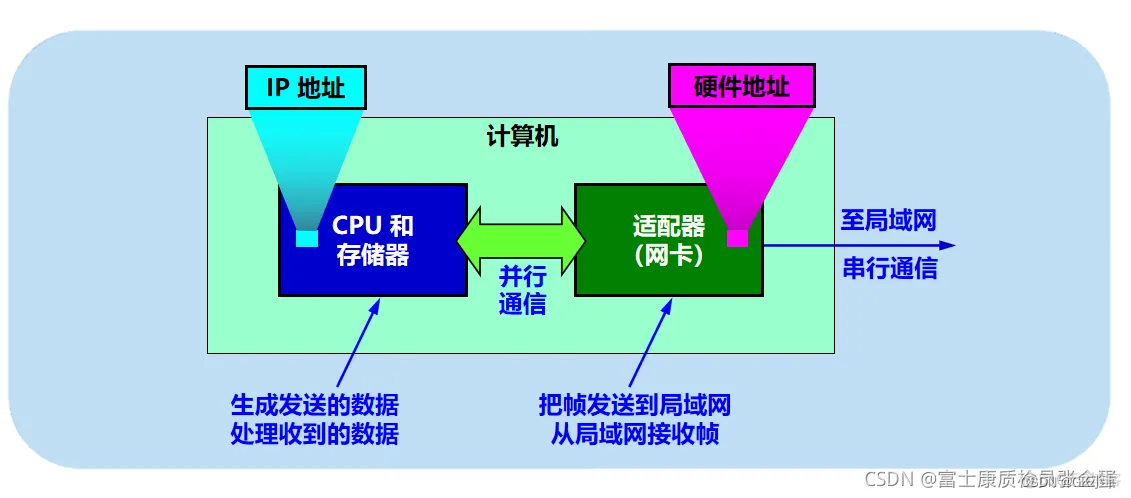
网卡是工作在链路层和物理层的网络组件,是局域网中连接计算机和传输介质的接口,不仅能实现与局域网传输介质之间的物理连接和电信号匹配,还涉及帧的发送与接收、帧的封装与拆封、帧的差错校验、介质访问控制(以太网使用CSMA/CD协议)、数据的编码与解码以及数据缓存的功能等。(物理层:将要传输的数据变为数字信号,编码传出去)
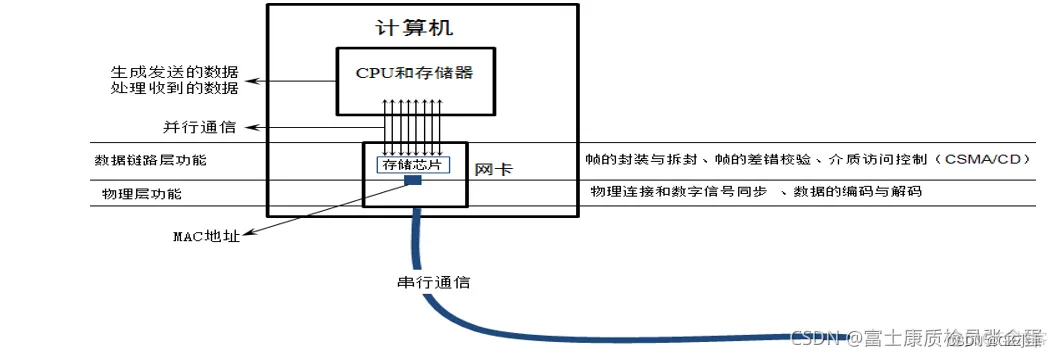


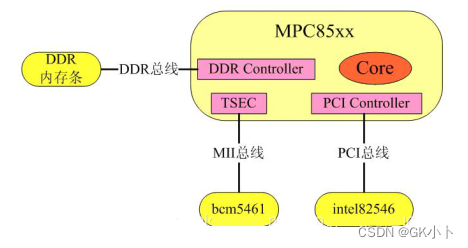
intel82546:PHY与MAC集成在一起的PCI网卡芯片;
bcm5461:PHY芯片,与之对应的MAC是TSEC;
TSEC:Three Speed Ethernet Controller,三速以太网控制器,TSEC内部有DMA子模块;
DMA:(Direct Memory Access,直接存储器访问) ,它将数据从一个地址空间复制到另外一个地址空间,而无需CPU的参与。
网络传输数据链路层,MAC和PHY芯片
3、收包流程
网线 -> Rj45网口 -> MDI 差分线->bcm5461(PHY芯片进行数模转换) -> MII总线-> TSEC(MAC) -> DMA把网络数据包搬到CPU收包缓存->收够n个包,CPU开始处理
4、网络发包
预先把发送的数据拷贝到一个物理连续的缓冲区里,然后把缓冲区的物理地址传递给网卡,启动网卡传输,网卡就用DMA方式把数据发送出去。发送成功后给出一个中断,表示发送完成。
网络发送和接收数据
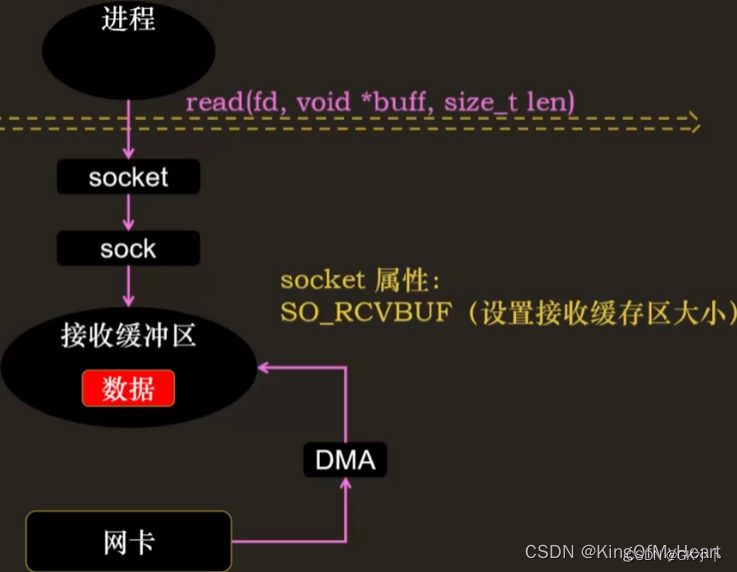
Linux网络发送和接收内核缓冲区大小的设置
SO_SNDBUF 发送缓冲区
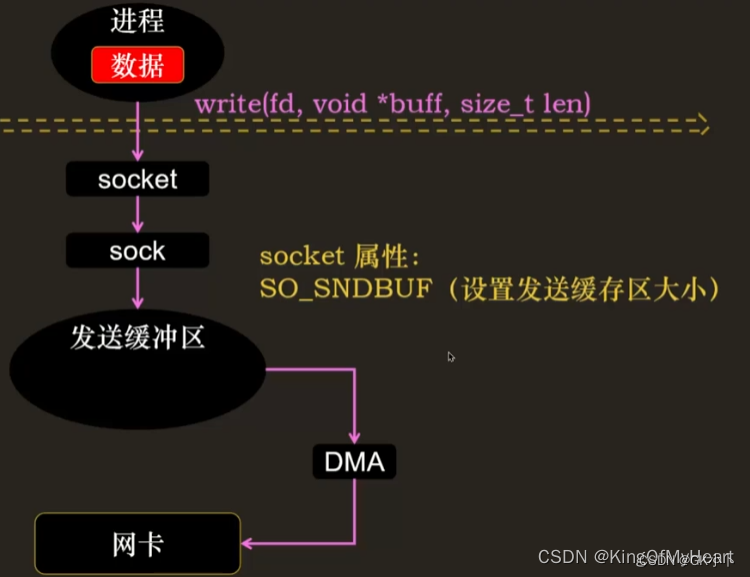
SO_RCVBUF 接收缓冲区
上图的接收缓冲区和发送缓冲区与下图的socket层的接收发送缓冲区等同 都是下下图中的socket接收和发送队列:
收缓冲区和发送缓冲区本质是应用层调用socket函数创建socket时创建的sk_recive_queue和sk_write_queue,详细参考sk_buff章节
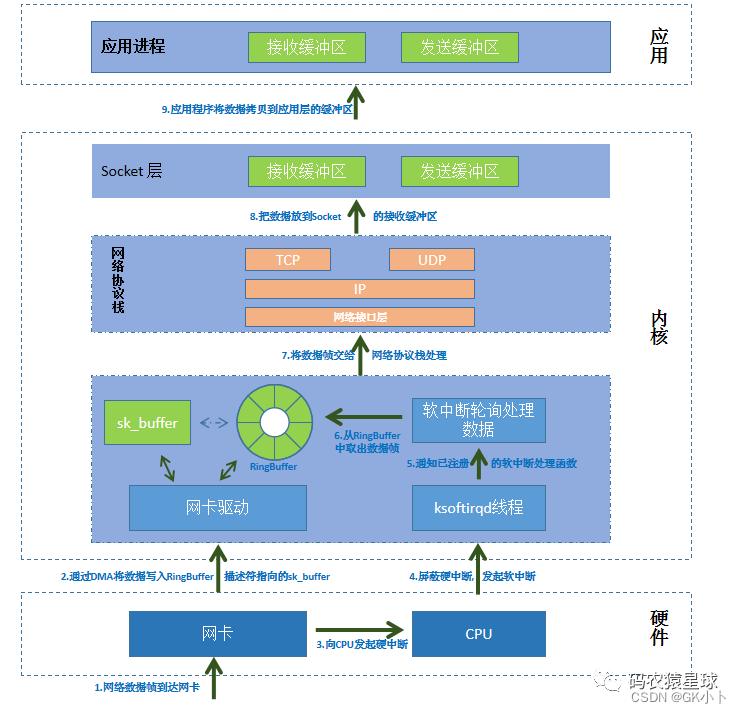
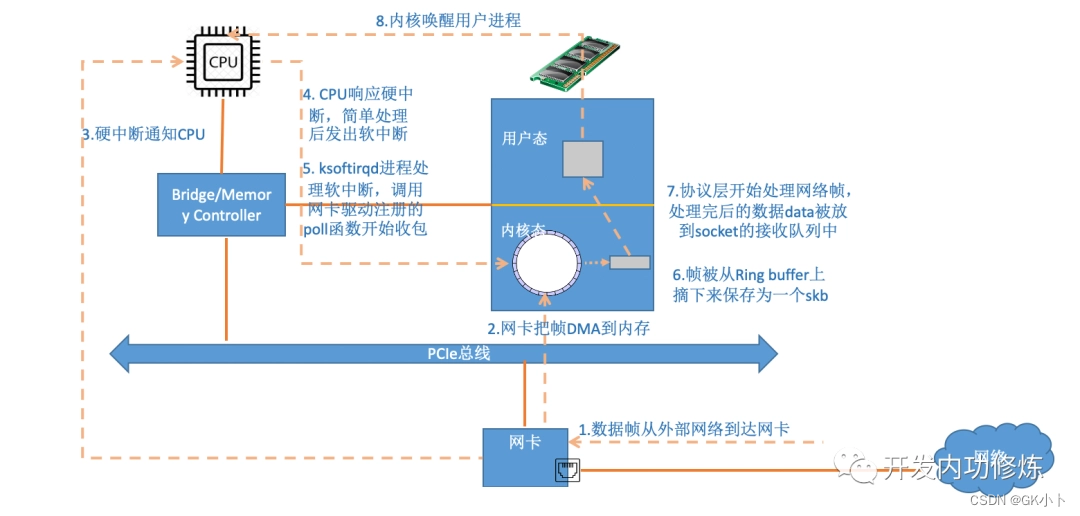
图1—数据从网卡到应用总流程
上图第6步不对,帧不是从ring buffer上取下来的,帧本来就保存在sk_buff数据缓冲区中,这里应该改成从ring buffer中找到下一个要解析的sk_buff数据缓冲区(数据帧)地址
第7步有个容易被误解的地方,数据data被放到socket的接收队列中,容易被误解为拷贝,其实不是,sk_buff数据缓冲区创建完成后就一直是存放数据帧的地方,在6,7过程中只是将sk_buff数据缓冲区从最开始挂在ring
buffer下,转变成挂在sk_recive_queue下了
网络设配器的收发建立连接过程,TCP 三次握手
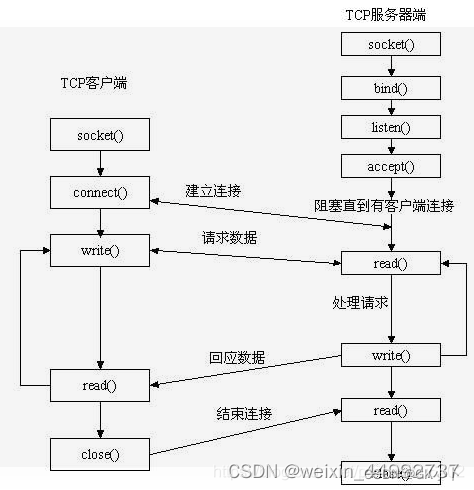
下图是用户进程端调用函数流程图:
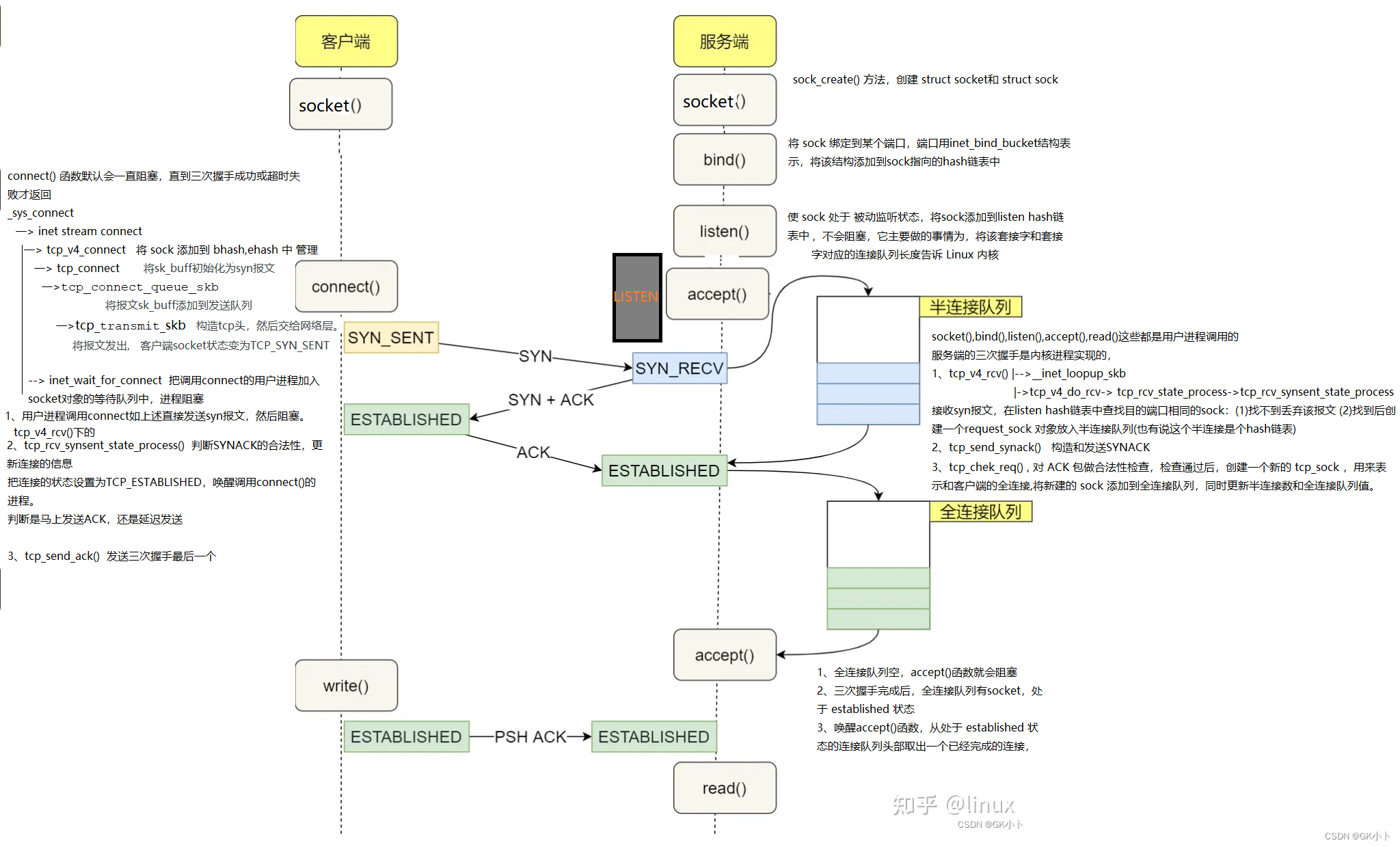
三次握手,客户端和服务端对应调用的函数:
1、客户端第一次握手是用户进程系统调用connect()函数立即发送syn报文(C1)后,其它握手都是在内核线程网络协议栈下完成的了,如下:
tcp_v4_rcv的源码:tcp_v4_rcv源码
发送端的2、3和接收端的1、2、3都是在接收报文的内核处理线程ksoftirqd下调用的,如下:
tcp_v4_rcv
|--tcp_v4_do_rcv
| |--tcp_rcv_established //状态为ESTABLISHED
| |--tcp_rcv_state_process
| |--tcp_v4_conn_request //状态为TCP_LISTEN S1服务端第一次握手,接收syn报文 分配request_sock 将该sock添加进半连接队列inet_csk_reqsk_queue_hash_add(sk,req, TCP_TIMEOUT_INIT);
| | --tcp_v4_send_synack //状态为TCP_NEW_SYN_RECV S2服务端第二次握手,发送syn + ack报文
| |--tcp_rcv_synsent_state_process //TCP_SYN_SENT C2客户端第二次握手,接收syn + ack报文
| | |--tcp_send_ack //状态为ESTABLISHED C3客户端第三次握手,发送ack报文
| | |--sock_def_wakeup
| | --wake_up_interruptible_all
| | --__wake_up
| |--case:TCP_SYN_RECV //服务端进入第三次握手后半程
| |--建立路由,初始化拥塞控制块
| |--tcp_set_state //状态变为TCP_ESTABLISHED
| |--sk_wake_async //唤醒阻塞的服务端用户进程
| --sock_def_wakeup //TCP_SYN_RECV
| --wake_up_interruptible_all
| --__wake_up
|--tcp_check_req //状态为TCP_NEW_SYN_RECV
| 一> tcp_v4_syn_recv sock // S3服务端进入第三次握手前半程,接收ack报文 将新的sock对象添加进accept队列
| 一> tcp_create_openreq_child
| 一> inet_csk_clone_lock
| |一> sk_clone_lock
| |一> inet_sk_set_state //状态变为TCP_SYN_RECV
|--tcp_child_process
| --tcp_rcv_state_process //该函数也出现在tcp_v4_do_rcv下
| |--case:TCP_SYN_RECV // S3服务端进入第三次握手后半程
| |--建立路由,初始化拥塞控制块
| |--tcp_set_state //状态变为TCP_ESTABLISHED
| |--sk_wake_async //唤醒阻塞的服务端用户进程
| --sock_def_wakeup //TCP_SYN_RECV
| --wake_up_interruptible_all
| --__wake_up
用户调用套接字实现三次握手的细节,详细作用以及参考文章:
struct sk_buff<=>skb, struct sock<=>sk,struct skb_share_info<=>shinfo
socket():
网络应用调用Socket API socket (int fa mi ly, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 use rs pace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。应用层处理流程
bind():
服务端 首先要调用 bind() 将 sock 绑定到某个端口,然后调用 listen() 使 sock 处于 被动监听状态,然后客户端才可以向服务端发起连接请求。
首先根据 端口号 计算一个 hash 值,然后通过这个 hash 值在定位到 inet_bind_hashbucket 某个 slot;
定位到 slot 后,遍历指向的链表,看这个端口是否已经存在:
如果端口不存在,就新建一个 inet_bind_bucket 并添加到链表中;
如果端口已经存在,则要检查是否已经有连接使用了该端口:
如果已经有连接使用,则报错(不考虑端口重用);
执行到这里,已经有一个 inet_bind_bucket 表示这个端口了,接下来,只要把调用 bind 函数的 sock 加入到 inet_bind_bucket.owners 即可。
bind()函数的使用
bind()和listen()函数的实现源码
listen():
首先将 sock 状态设置为 TCP_LISTEN;
然后根据端口号计算哈希值定位到 listening_hash 某个 slot,将 sock 添加进来;
最后按类似的方式,把 sock 也添加到 lhash2 中。bind()和listen()函数的实现源码
。
accpet():
从「 Accept 队列」取出建立连接的socket对象,如果Accept 队列全连接队列一直为空,这意味着没有客户端和服务器建立连接,那么accept就会一直阻塞。
当客户端一调用connect函数发起连接时,如果完成tcp三次握手,那么accept函数就会被唤醒,会取出一个客户端连接(注意:是已经建立好的连接)然后立即返回。
connect():
客户端通过调用connect 向服务器发送SYN 包( 启动重传timer )
完成tcp 三次握手 的第一步操作, 根据套接字是否设置成阻塞模式, connect 会执行阻塞操作, 等待服务器的SYN+ACK 、RST 等响应报文。
第一次握手主要流程:
1、设置 sock 状态为 SYN_SENT;
2、 inet_hash_connect 绑定端口,将 sock 加入到 bhash (也就是bind hash 表,确保其它请求使用该端口时知道知道该端口被占用)和 ehash 中;三次握手-主动方发送SYN
3、构造 SYN 包,发送给服务端(C1)。
sys_connect
--inet_stream_connect //TCP
--tcp_v4_connect
-- inet_hash_connect
--tcp_connect //tcp_connect 就是构造一个SYN 报文, 并将其发送出去, 但是由于TCP 要提供可靠服务, 所以发送完之后还需要将该SYN 报文加入到发送队列, 并启动SYN 重传定时器, 只有等收到对端的AC K 报文后, 才能将该报文,从发送队列删除井停止SYN 重传定时器。
--tcp_connect_queue_skb //将该SYN 报文加入到发送队列, 并启动SYN 重传定时器
--tcp_transmit_skb //传递给IP层发送该报文
--inet_wait_for_connect 把调用connect 的用户进程加入socket对象的等待队列中, 进程阻塞
--inet_dgram_connect //UDP
--ip4_datagram_connect
linux内核协议栈 connect 源码
Linux内核网络协议栈《connect函数剖析》
connect内核源码
connect函数出错情况
服务端第一次握手S1,被动方接收SYN,第二次握手S2,发送syn + ack报文
服务端调用 listen 函数后一直处于 TCP_LISTEN 状态,等待客户端的连接请求;
tcp_v4_rcv
|--__inet_lookup
|--tcp_v4_do_rcv
| |--tcp_rcv_state_process
| |--tcp_v4_conn_request //状态为TCP_LISTEN S1服务端第一次握手,接收syn报文 分配request_sock 将该sock添加进半连接队列inet_csk_reqsk_queue_hash_add(sk,req, TCP_TIMEOUT_INIT);
| | --tcp_v4_send_synack //状态为TCP_NEW_SYN_RECV S2服务端第二次握手,发送syn + ack报文
内核收到任何 TCP 消息,都会进入该tcp_v4_rcv函数。首先在全局的 tcp_hashinfo 中查找 sock,然后进行相应的处理。
看下查找函数 __inet_lookup:
查找过程是先查 ehash,然后再查 inet_listen_hashbucket 。
服务端在接收到 SYN 包的时候,还没有可以表示这个连接的 sock 存在 ehash 中,所以要继续 inet_listen_hashbucket 中查找。
inet_listen_hashbucket 保存的了服务端调用 listen 函数时插入的 sock,它处于 TCP_LISTEN 状态,端口号等于 SYN 请求包的目的端口,因此,这里可以找到这个 sock。
找到以上 sock 后,服务端要创建一个 request_sock 对象来表示这个 半连接,最后要构建 SYN+ACK 响应包发送给客户端,即向客户端发送 第二次握手。
inet_reqsk_alloc() 函数创建一个 request_sock 对象来表示这个半连接,然后将它添加到 ehash(这个就是下一章节说的半连接队列) 中,在网上经常会看到说服务器在收到 SYN 请求包后,会创建一个 socket 保存到半连接队列,但实际上 ehash 是个 hash 表,只是它又使用了链表来解决 hash 冲突;
此外,服务端还要更新一下半连接数;我们知道,半连接数是针对服务端监听 socket 而言的,而该 sock 正是第一步在 inet_listen_hashbucket 中查找到的那个 socket,更新值:sk.icsk_accept_queue.qlen++。
这里还有个地方需要注意, 代表这个半连接的 request_sock 的状态是 TCP_NEW_SYN_RECV,不是 TCP_SYN_RECV,这和以前学到的三次握手状态转换图有点出入。
查阅资料发现这个状态是 Linux 4.4+ 以后新增的,本文主要以理清握手过程为主,暂不深究为什么新增这个状态,以后再探讨。
服务端第一次,第二次握手
客户端第二次握手C2,接收syn + ack报文,客户端第三次握手C3,发送ack报文
tcp_v4_rcv
|--> tcp_v4_do_rcv
|-> tcp_rcv_state_process
|-> tcp_rcv_synsent_state_process //客户端第二次握手C2,接收syn + ack报文
|--tcp_send_ack //状态为ESTABLISHED C3客户端第三次握手,发送ack报文
|--sock_def_wakeup
--wake_up_interruptible_all
--__wake_up
客户端第二次第三次握手
客户端主动建立连接时,发送SYN段后,连接的状态变为SYN_SENT。
此时如果收到SYNACK段,处理函数为tcp_rcv_state_process()。
(1) 接收到SYNACK
一般情况下会收到服务端的SYNACK,处理如下:
检查ack_seq是否合法。
如果使用了时间戳选项,检查回显的时间戳是否合法。
检查TCP的标志位是否合法。
如果SYNACK是合法的,更新sock的各种信息。
把连接的状态设置为TCP_ESTABLISHED,唤醒调用connect()的进程。
判断是马上发送ACK,还是延迟发送。发送ACK报文
第三次握手报文——发送ACK报文
在一下几种情况下会延迟发送。
1、当前刚好有数据等待发送
2、用户设置了TCP_DEFER_ACCEPT选项
3、禁用快速确认模式,可通过TCP_QUICKACK选项设置
不过即使延迟,也最多延迟200ms,这个通过延迟ACK定时器操作。
(2) 接收到SYN
本端之前发送出一个SYN,现在又接收到了一个SYN,双方同时向对端发起建立连接的请求。
处理如下:
把连接状态置为SYN_RECV。
更新sock的各种信息。
构造和发送SYNACK。
接者对端也会回应SYNACK,之后的处理流程和服务器端接收ACK类似,可参考之前的blog。
当tcp_rcv_synsent_state_process()的返回值大于0时,会导致上层调用函数发送一个被动的RST。
Q:那么什么情况下此函数的返回值会大于0?
A:收到一个ACK段,但ack_seq的序号不正确,或者回显的时间戳不正确。
tcp_finish_connect()用来完成连接的建立,主要做了以下事情:
-
把连接的状态从SYN_SENT置为ESTABLISHED。
-
根据路由缓存,初始化TCP相关的变量。
-
获取默认的拥塞控制算法。
-
调整发送缓存和接收缓存的大小。
-
如果使用了SO_KEEPALIVE选项,激活保活定时器。
-
唤醒此socket等待队列上的进程(即调用connect的进程)。
如果使用了异步通知,则发送SIGIO通知异步通知队列上的进程可写。
服务端进入第三次握手S3,接收ack报文 将新的sock对象添加进accept队列
tcp_v4_rcv
|--tcp_check_req //状态为TCP_NEW_SYN_RECV
| 一> tcp_v4_syn_recv sock // S3服务端进入第三次握手前半程,接收ack报文 将新的sock对象添加进accept队列
| 一> tcp_create_openreq_child
| 一> inet_csk_clone_lock
| |一> sk_clone_lock
| |一> inet_sk_set_state //状态变为TCP_SYN_RECV
|--tcp_child_process
| --tcp_rcv_state_process //该函数也出现在tcp_v4_do_rcv下
| |--case:TCP_SYN_RECV // S3服务端进入第三次握手后半程
| |--建立路由,初始化拥塞控制块
| |--tcp_set_state //状态变为TCP_ESTABLISHED
| |--sk_wake_async //唤醒阻塞的服务端用户进程
| --sock_def_wakeup //TCP_SYN_RECV
| --wake_up_interruptible_all
| --__wake_up
三次握手-被动方接收ACK
在 上上一章节 我们讨论了被动方接受 SYN 后的逻辑,简单回顾一下:
收到 SYN 请求包后,服务端创建一个 request_sock 对象来表示这个 半连接,并添加到 ehash 中管理,此时该 sock 的状态为 TCP_NEW_SYN_RECV。然后就向客户端发送了第二次握手包。
现在我们看下服务端接收到第三次握手后的处理。
入口函数 tcp_v4_rcv 老相识了:
1、首先查找 sock,会在 ehash 中找到代表半连接的 request_sock,它处于 TCP_NEW_SYN_RECV 状态;
2、根据 request_sock 关联到 inet_listen_hashbucket 监听该端口的 tcp_sock (TCP_LISTEN);
3、调用子流程 tcp_check_req 对 ACK 包做合法性检查,检查通过后,创建一个新的 tcp_sock ,用来表示和客户端的全连接;
4、对新的 tcp_sock 进一步处理。
流程相比之前稍微复杂一些,我们分步骤阅读,首先,进入 tcp_check_req 看下:
1、对客户端发来的第二次握手包做合法性检查,比如序列号是否正确,控制位检查等…;
2、检查通过后,创建一个全新的 tcp_sock 表示这个连接,状态为 TCP_SYN_RECV;
3、把这个新的 sock 添加到 inet_bind_bucket 的 owners 链表 和 ehash 中管理,将代表半连接的 request_sock 从 ehash 中删除;
4、最后将新建的 sock 添加到全连接队列,同时更新半连接数和全连接队列值。
syn队列(半连接队列)和accept队列(全连接队列)
如何建立连接
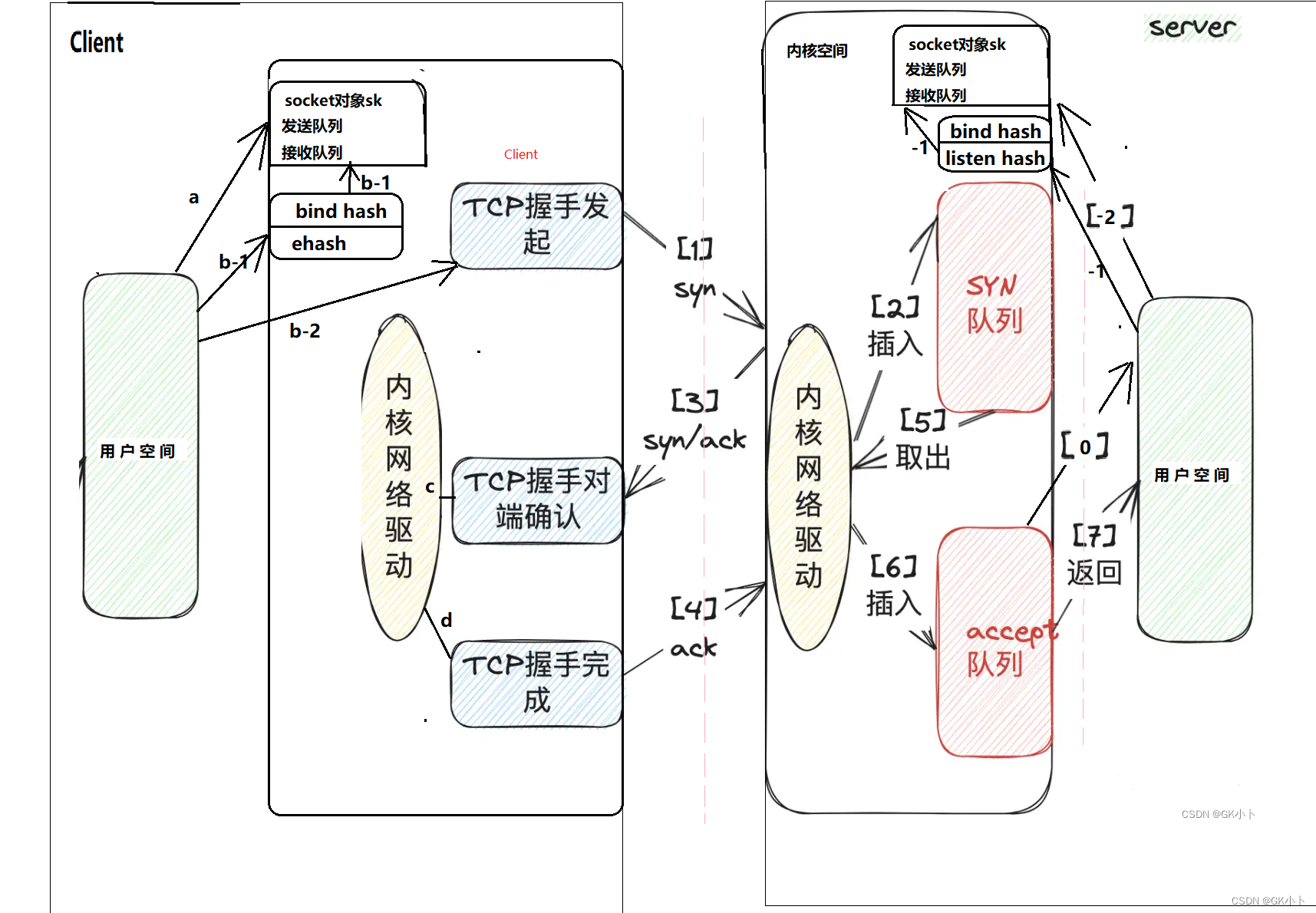
tcp_v4_rcv。接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
也就是socket层调用accept()等待客户端连接时,会调用网络协议栈tcp_rcvmsg()
(a)对应上一章的socket()函数
(b)对应上一章的connect()函数,b-1为绑定端口,b-2为发送syn报文C1
(1)client端发起TCP握手,发送syn包;
(2)服务端内核收到包以后先将当前连接的信息插入到网络的SYN队列;对应上一章的S1,这里的队列严格来说是hash表。但按照队列来理解也没问题。TCP半连接队列是怎么取出信息的?
(3)插入成功后会返回握手确认(SYN+ACK); 对应上一章的S2
(c) 对应上一章的C2
(d) 对应上一章的C3
(4)(d)client端如果继续完成TCP握手,回复ACK确认;对应上一章的C3
(5)内核会将TCP握手完成的包,先将对应的连接信息从SYN队列取出;(5)(6)对应上一章的S3,这里的说法只是为了好理解,真正的过程按上一章节来
(6)将连接信息丢入到ACCEPT队列;
(7)应用层sever通过系统调用accept就能拿到这个连接,整个网络套接字连接完成;
将复杂的流程简化为上述主要是为了以下分析:
对syn队列和accept队列的攻击
1、这里有两个队列,必然会有满的情况,那如果遇到这种情况内核是怎么处理的呢?
(1)如果SYN队列满了,内核就会丢弃连接;
(2)如果ACCEPT队列满了,那内核不会继续将SYN队列的连接丢到ACCEPT队列,如果SYN队列足够大,client端后续收发包就会超时;
(3)如果SYN队列满了,就会和(1)一样丢弃连接;
2、如何控制SYN队列和ACCEPT队列的大小?
(1)内核2.2版本之前通过listen的backlog可以设置SYN队列(半连接状态SYN_REVD)和ACCEPT队列(完全连接状态ESTABLISHED)的上限;
(2)内核2.2版本以后backlog只是表示ACCEPT队列上限,SYN队列的上限可以通过/proc/sys/net/ipv4/tcp_max_syn_backlog设置;
3、server端通过accept一直等,岂不是会卡住收包的线程?
在linux网络编程中我们都会追求高性能,accept如果卡住接收线程,性能会上不去,所以socket编程中就会有阻塞和非阻塞模式。
(1)阻塞模式下的accept就会卡住,当前线程什么事情都干不了;
(2)非阻塞模式下,可以通过轮询accept去处理其他的事情,如果返回EAGAIN,就是ACCEPT队列为空,如果返回连接信息,就是可以处理当前连接;
什么是 SYN 攻击?如何避免 SYN 攻击?
如何查看 TCP 的连接状态?
已建立连接的TCP,收到SYN会发生什么?
SYN 报文什么时候情况下会被丢弃?
以上问题在以下参考链接中:
TCP的三次握手
网络设配器的收包流程
网络设配器的收包流程
网络收包流程与该文章中有冲突的以本文为主
Linux TCP滑动窗口代码简述
TCP/IP 协议栈在 Linux 内核中的 运行时序分析
TCP输入 之 tcp_rcv_established
TCP协议ESTABLISHED状态处理
linux内核TCP/IP源码浅析
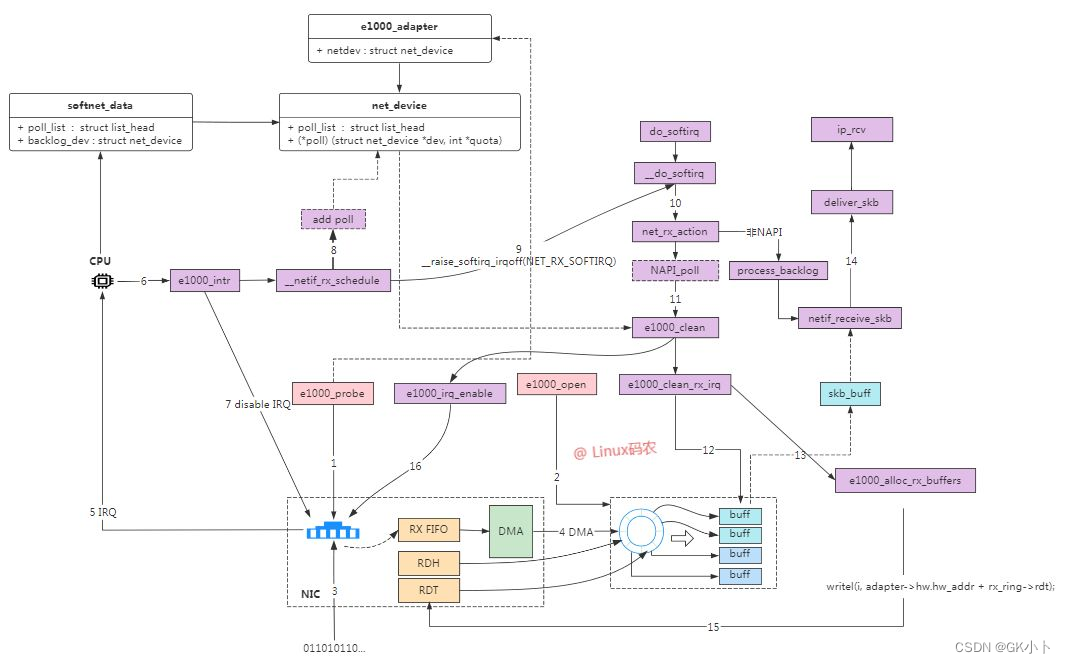
1、网卡驱动申请 Rx descriptor ring,本质是一致性 DMA 内存,保存了若干的 descriptor。将 Rx descriptor ring 的总线地址写入网卡寄存器 RDBA。
2、在数据帧到达网卡时,网卡会产生中断,网卡驱动为每个 descriptor 分配 skb_buff 数据缓存区(调用skb = dev_alloc_skb(pkt_len+5);),本质上是在内存中分配的一片缓冲区用来接收数据帧。将数据缓存区的总线地址保存到 descriptor。中断环境下 SKB 的分配流程
3、网卡接收到高低电信号。
4、PHY 芯片首先进行数模转换,即将电信号转换为比特流。
5、MAC 芯片再将比特流转换为数据帧(Frame)。
6、网卡驱动将数据帧写入 Rx FIFO。
7、网卡驱动找到 Rx descriptor ring 中下一个将要使用的 descriptor。
8、网卡驱动使用 DMA 通过 PCI 总线将 Rx FIFO 中的数据包复制到 descriptor 保存的总线地址指向的数据缓存区中。其实就是复制到 skb_buff 数据实体中。
9、因为是 DMA 写入,所以内核并没有监控数据帧的写入情况。所以在复制完后,需要由网卡驱动启动硬中断通知 CPU 数据缓存区中已经有新的数据帧了。每一个硬件中断会对应一个中断号,CPU 执行硬下述中断函数。实际上,硬中断的中断处理程序,最终是通过调用网卡驱动程序来完成的。硬中断触发的驱动程序首先会暂时禁用网卡硬中断,意思是告诉网卡再来新的数据就先不要触发硬中断了,只需要把数据帧通过 DMA 拷入主存即可。
10、硬中断后继续启动软中断,启用软中断目的是将数据帧的后续处理流程交给软中断处理程序异步的慢慢处理。此时网卡驱动就退出硬件中断了,其他外设可以继续调用操作系统的硬件中断。但网络 I/O 相关的硬中断,需要等到软中断处理完成并再次开启硬中断后,才能被再次触发。ksoftirqd 执行软中断函数 net_rx_action():
NAPI(以 e1000 网卡为例),触发 napi() 系统调用,napi() 逐一消耗 Rx Ring Buffer 指向的 skb_buff 中的数据包:
net_rx_action() -> e1000_clean() -> e1000_clean_rx_irq() -> e1000_receive_skb() -> netif_receive_skb()
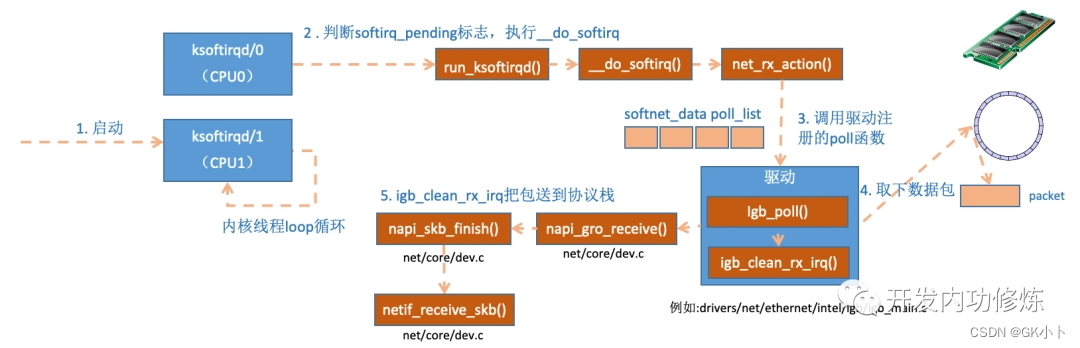
图2–ksoftirqd 执行软中断函数将 sk_buff 上送到协议栈
该图显示的过程是上述图1里5-6过程的细节。ksoftirqd 内核线程处理软中断
11、内核线程调用网卡驱动通过 netif_receive_skb() 将 sk_buff 上送到协议栈。
表项descriptor会在对应的 sk_buff 送到协议栈后更新
12、重新开启网络 I/O 硬件中断(这里是CPU的硬中断不是网卡的中断),有新的数据帧到来时可以继续触发网络 I/O 硬件中断,继续通知 CPU 来消耗数据帧。(协议栈处理skb接着往下走,同时2-11又开始运行,所以图二有两个相同的内核线程来分别执行)
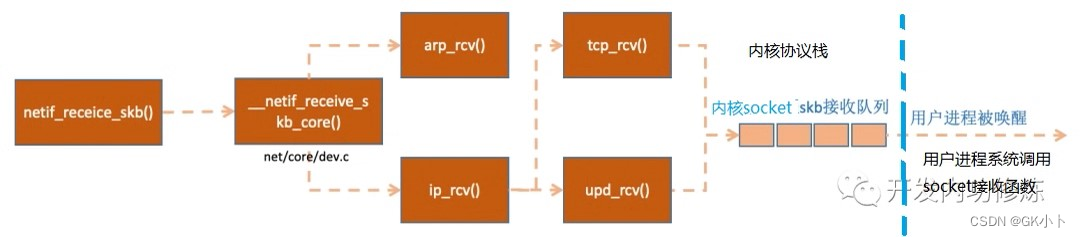
协议栈涉及到哪些处理函数详细参考:网络协议栈处理
__netif_receive_skb_core ()为抓包软件的抓包点
接下来的13,14,15协议栈中 也都属于软中断的处理过程
13、判断skb包的协议,接下来去到哪些处理函数里
netif_receive_skb 函数会根据包的协议,假如是 udp 包,会将包依次送到 ip_rcv (),udp_rcv () 协议处理函数中进行处理。如果是 arp 包的话,会进入到 arp_rcv
14、网络层
在ip_rcv函数中,网络层取出IP头,判断网络包下一步的走向,是转发还是交给上层。当确认网络包是要发送给本机后,就取出上层协议的类型(比如TCP或UDP),去掉IP头,然后交给传输层处理。
15、传输层
传输层的协议栈如下:
tcp_v4_rcv
|--tcp_v4_do_rcv
| |--tcp_rcv_established //状态为ESTABLISHED
| --fast path:
| --len <= tcp_header_len //接收的报文无payload数据
| --tcp_ack //若接收的报文无payload数据,则处理输入ack
| --tcp_data_snd_check //检查本端是否有数据要发送,并检查发送缓冲区大小
| --len > tcp_header_len //接收的报文有payload数据
| --tcp_copy_to_iovec //当前应用进程是等待数据的进程 ,且当前套接字运行在当前用户进程现场,当前套接字是否运行在当前用户进程现场,如果复制成功要清除prequeue队列中已经复制的数据,腾出空间。
| --slow path:
| --tcp_data_queue //将数据加入sk_receive_queue常规队列中
| --tcp_data_snd_check //检查本端是否有数据要发送,并检查发送缓冲区大小
| --tcp_ack_snd_check //检查是否有ack要发送,需要则发送
|--tcp_child_process
| --tcp_rcv_state_process //该函数也出现在tcp_v4_do_rcv下
| |--case:TCP_ESTABLISHED
TCP协议是可靠的、快速传递数据的协议,当套接字状态是ESTABLISHED状态表明两端已经建立连接,可以互相传送数据了,tcp_v4_do_rcv接受到数据后首先检查套接字状态,如果是ESTABLISHED就交给tcp_rcv_established函数处理具体数据接受过程。如果是LISTEN就由tcp_v4_hnd_req处理,如果是其他状态就由tcp_rcv_state+process处理,关系图如下。
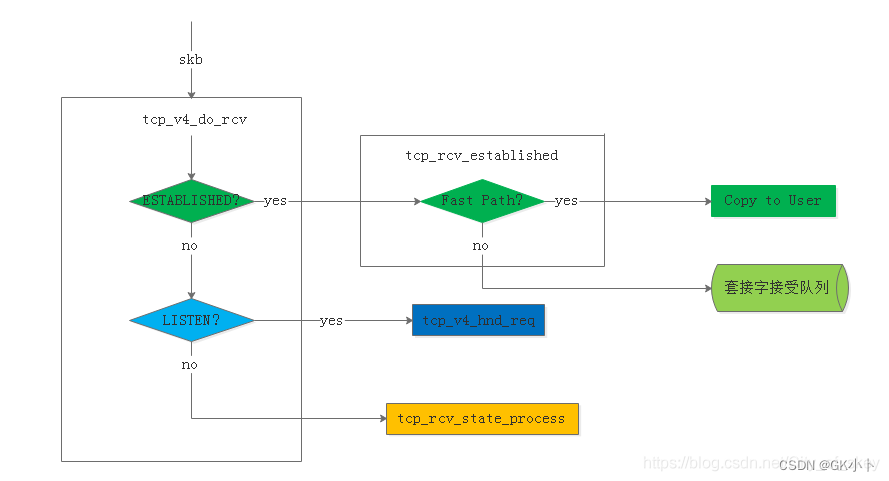
简单来说就是,处理过程根据首部预测字段分为快速路径和慢速路径;
- 在快路中,对是有有数据负荷进行不同处理:
(1) 若接收的报文无payload数据,则处理输入ack,释放该skb,检查本端是否有数据发送,有则发送;
(2) 若有数据,检查是否当前处理进程上下文,并且是期望读取的数据,若是则将数据复制到用户空间,若不满足直接复制到用户空间的情况,或者复制失败,则需要将数据段加入到接收队列中,加入方式包括合并到已有数据段,或者加入队列尾部,并唤醒用户进程通知有数据可读;
- 在慢路中,会进行更详细的校验,然后处理接收到的ack,处理紧急数据,接收数据段,其中数据段可能包含乱序的情况,最后进行是否有数据和ack的发送检查;
通常网络上大多数报文都会走fast path,ack报文的处理tcp_ack(),在这个函数中,会更新发送窗口,使窗口右移,这样就会有新的报文可以被发送,
传输层取出 TCP 头或者 UDP 头后,根据四元组【 源 IP、源端口、目的 IP、目的端口 】,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓冲区。
传输层 TCP 处理入口在 tcp_v4_rcv 函数(位于 linux/net/ipv4/tcp ipv4.c 文件中),它会做 TCP header 检查等处理。
调用 _tcp_v4_lookup,查找该 package 的 open socket。如果找不到,该 package 会被丢弃。接下来检查 socket 和 connection 的状态。
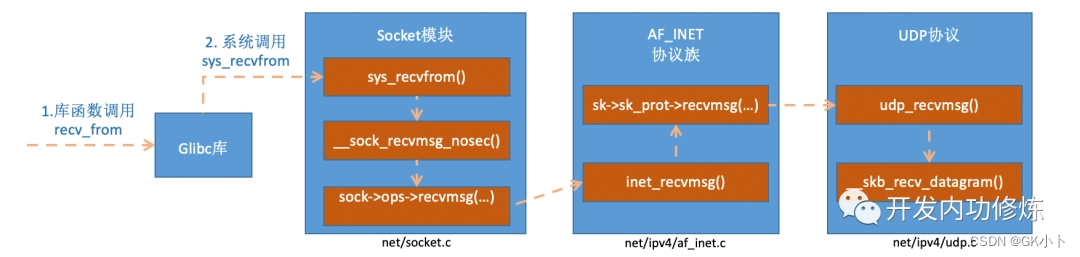
上图显示的流程为接在16步骤后面,用户进程被唤醒(处在内核态被阻塞的用户进程)
网络设配器的发包流程
发包流程参考链接:
网络发包流程
tcp_sendmsg代码
Linux网络发送流程概述
TCP/IP 协议栈在 Linux 内核中的 运行时序分析
在应用层调用send()或write()函数后,数据有两种情况发出去:
(1) 用户进程立即将发送队列(发送缓冲区)的数据发送出去
调用send发送网络数据包一定会立马发送出去吗?
这里能立即发送出去需要满足以下情况:
用户进程调用send()或write()函数发送的第一个报文且
情况1:
发现发送的数据量已经超过发送窗口的一半时,设置TCP_NAGLE_PUSH标记,会忽略nagle规则强制发送缓冲区中的所有skb。
情况2:
如果当前skb是未发送skb链表的header,那么它肯定会被发送,设置TCP_NAGLE_PUSH标记,会忽略nagle规则强制发送当前的这一个skb,注意仅仅发送一个。
情况3:
如果发送缓冲区已经满了,需要触发立即发送,腾出内存空间,设置了TCP_NAGLE_PUSH标记,表示忽略nagle规则强制发送缓冲区中的所有skb。
情况4:
当send把一次应用写入的数据都已经写入到发送缓冲区后,退出函数之前,会调用一次发送函数,注意这次发送是需要按照NAGLE规则判断是否触发真实发送的,如果满足Nagle条件才会发送,否则依然会保留在发送缓冲区中。
(2) 通过内核线程调用tcp_v4_rcv函数实现发送队列剩余数据的发送
详情可以查看tcp_v4_rcv的作用那一章节
tcp_sendmsg
----copied = tcp_send_rcvq
--tcp_push
--__tcp_push_pending_frames
--tcp_mark_push
--forced_push // 检查是否需要立马发送,这里是不需要立马发送
--tcp_mark_push
--__tcp_push_pending_frames
-- // 如果是头部需要立马发送
--tcp_push_one // 如果是头部则发送第一个


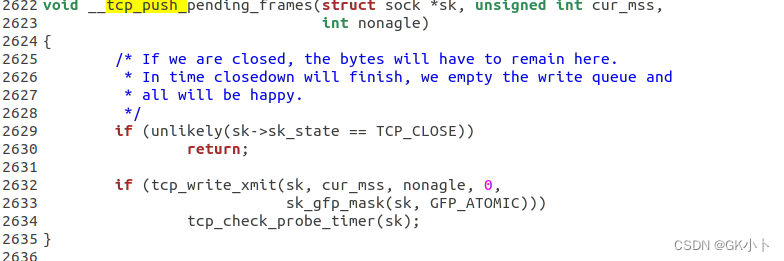
tcp_push最终都是通过__tcp_push_pending_frames函数里传入的参数nonagle来决定开不开器nagle算法,也就是绝不决定要不要立即发送数据
tcp_push_one是立即发送数据
1、网卡驱动创建 Tx descriptor ring,将 Tx descriptor ring 的总线地址写入网卡寄存器 TDBA(这一步在网卡启动时就已经完成)。
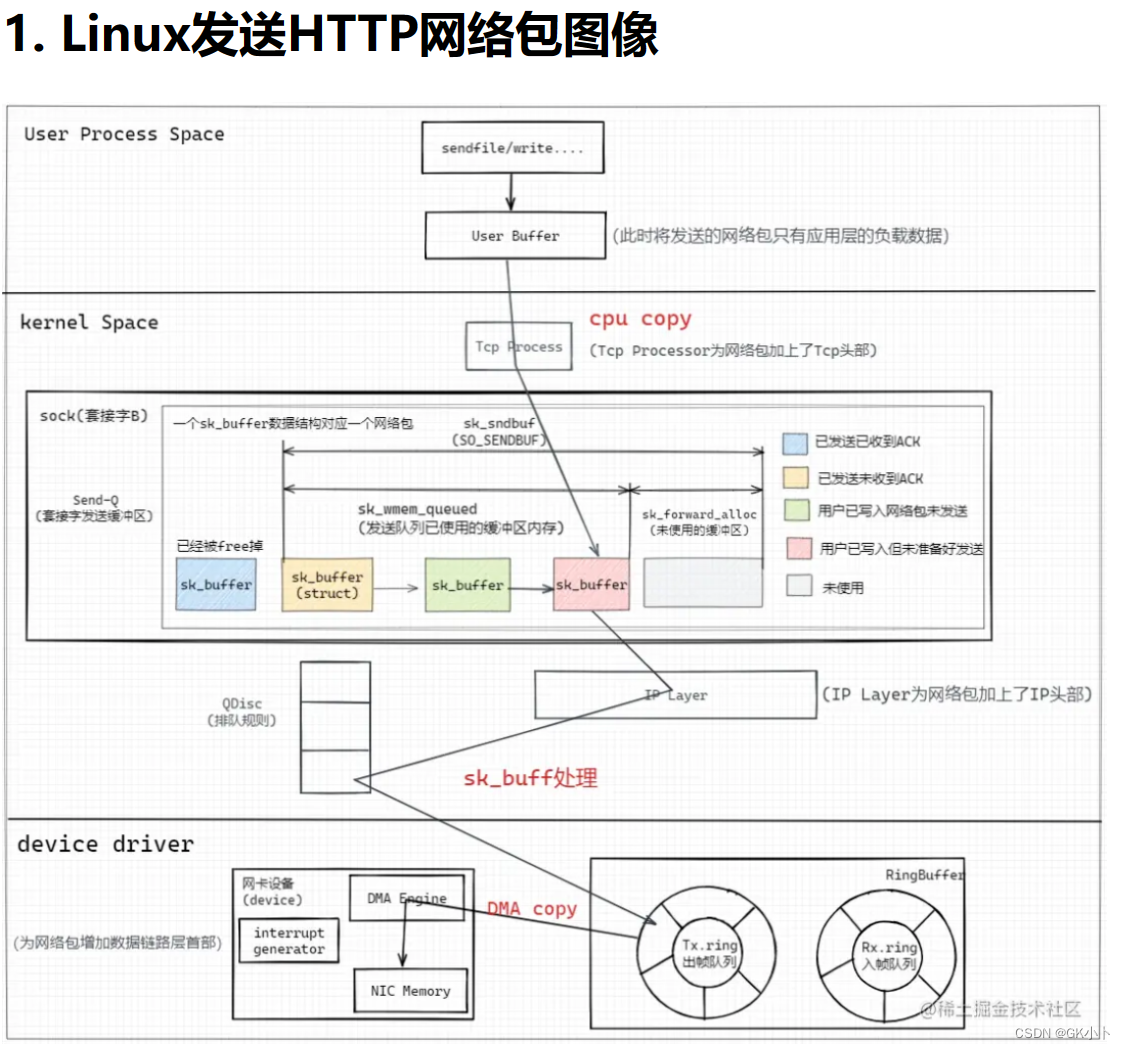
2、首先,应用程序调用 Socket 发送网络包的接口。这是一个系统调用,会从用户态陷入到内核态的套接字层中。
在内核中首先根据fd将真正的Socket找出,这个Socket对象中记着各种协议栈的函数地址,然后构造struct msghdr对象,将用户需要发送的数据全部封装在这个struct msghdr结构体中。
3、传输层,
在TCP协议的发送函数tcp_sendmsg中,创建内核数据结构sk_buffer(alloc_skb() ),将struct msghdr结构体中的发送数据拷贝到sk_buffer中。调用tcp_write_queue_tail函数获取Socket发送队列中对尾元素,将新创建的sk_buffer添加到Socket发送队列的尾部。
在传输层,会为器添加TCP头,同时拷贝一个新的 sk_buff 副本 ,这是因为 sk_buff 在到达网卡发送完成的时候,会被释放掉,而TCP 协议是支持重传的,为确保网络包可靠传输,在收到对方的 ACK 之前,这个 sk_buff 不能被删除。
4、网络层
在网络层,主要会做这些工作:选取路由(确认下一跳的 IP)、填充 IP 头、netfilter 过滤、对超过 MTU 大小的数据包进行分片。处理完这些工作后会交给网络接口层处理。
5、网络接口层
网络接口层会进行物理地址寻址,以找到下一跳的 MAC 地址,填充帧头和帧尾,
6、协议栈通过 dev_queue_xmit() 将 sk_buffer 下送到网卡驱动。
7、网卡驱动将 sk_buff的数据结构地址 放入 Tx descriptor ring,更新网卡寄存器 TDT。(这一步就是将挂在发送缓冲区sk_write_queue上的sk_buff 重新挂在Tx ring buffer上)
8、DMA 感知到 TDT 的改变后,找到 Tx descriptor ring 中下一个将要使用的 descriptor。
9、DMA 通过 PCI 总线将 descriptor 的数据缓存区复制到 Tx FIFO。
10、复制完后,通过 MAC 芯片将数据包发送出去。
11、发送完后,网卡更新网卡寄存器 TDH,启动硬中断通知 CPU 释放数据缓存区中的数据包。
网卡设备从FIFO发送队列中取出数据包,将其发送到网络;当发送完成的时候,网卡设备会触发一个硬中断来释放内存,主要是释放 sk_buff内存和清理 RingBuffer 内存。最后,当收到这个 TCP 报文的 ACK 应答时,传输层就会释放原始的 sk_buff。
tcp_v4_rcv的作用
tcp_v4_rcv的源码:tcp_v4_rcv源码
linux内核TCP/IP源码浅析
TCP/IP 协议栈在 Linux 内核中的 运行时序分析
三次握手中客户端的后两次和服务端的三次实现
如三次握手那一章节
发送发送缓冲区剩余数据
Linux TCP滑动窗口代码简述
除了用户进程调用send()或write()函数主动发出去的数据,剩下不能在一个报文中发出去的数据(拷贝在发送缓冲区中,发送窗口未发出去的部分)
都是通过内核线程调用tcp_v4_rcv,如下函数栈:
tcp_v4_rcv
-->tcp_ack() //会更新发送窗口,使窗口右移,这样就会有新的报文可以被发送,
-->tcp_data_snd_check
-->tcp_write_xmit //在这个函数中,会循环获取Socket发送队列中待发送的sk_buffer,然后进行拥塞控制以及滑动窗口的管理。
-->tcp_transmit_skb
tcp_ack(),在这个函数中,会更新发送窗口,使窗口右移,这样就会有新的报文可以被发送,tcp_data_snd_check(sk);就把这些报文发送出去。
TCP的滑动窗口的流量控制是通过协调发送方和接收方的速度来实现的,具体来说,就是发送方窗口是由接收方回的ack驱动的,也就是说发送方要能持续发送包需要持续接收ack。另一个方面,接收方在读取报文后,发送ack进行响应,循环进行接收。这个过程通过驱动窗口的可持续滑动,进而实现了流量控制和提高传输效率。
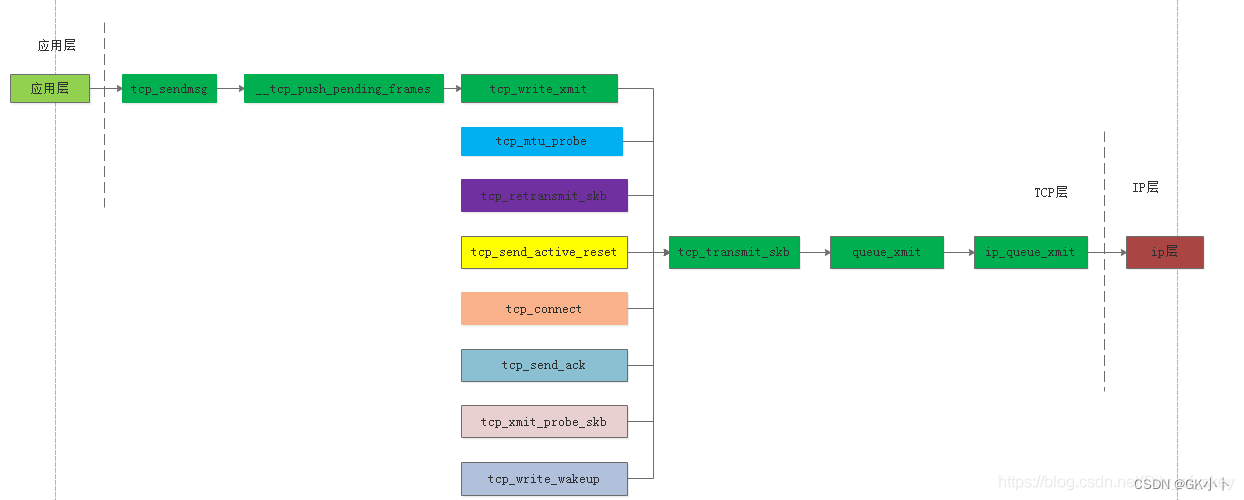
tcp_transmit_skb函数的作用
(1)重传数据包tcp_retransmit_skb。
(2)探测路由最大传送单元数据包。
(3)发送复位连接数据包
(4)发送连接请求数据包
(5)发送回答ACK数据包
(6)窗口探测数据包
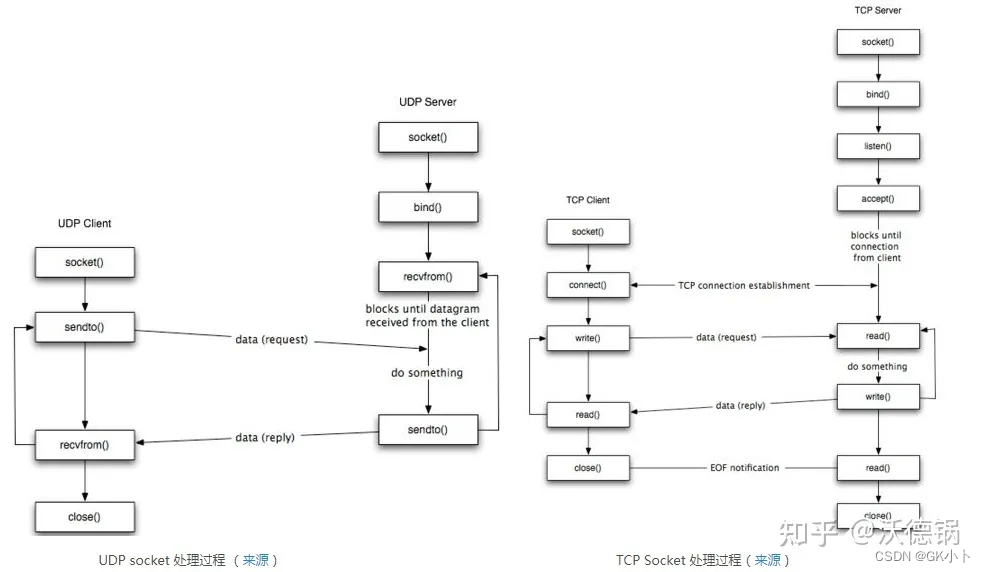
应用层、TCP层、IP层之间接口关系如下图:
TCP发送函数tcp_transmit_skb
网络结构须知:
1、ring buffer
看了很多文章,发现很多人误解了ring buffer,
存储的不是网络数据帧,存储是sk_buffer数据结构实体的地址和大小
Ring Buffer是在网卡驱动程序启动时创建和初始化的,
网卡驱动会在 RAM 中建立并为例两个环形队列ring buffer,又称为 BD(Buffer descriptor)表,一个收(Rx)、一个发(Tx),每一个表项称为 descriptor(描述符(sk_buff))。descriptor 所存放的内容是由 CPU 决定的,一般会存放 descriptor 所指代的 Data buffer(实际的数据存储空间)的指针、数据长度以及一些标志位。
表项descriptor会在对应的 sk_buff 送到协议栈后更新
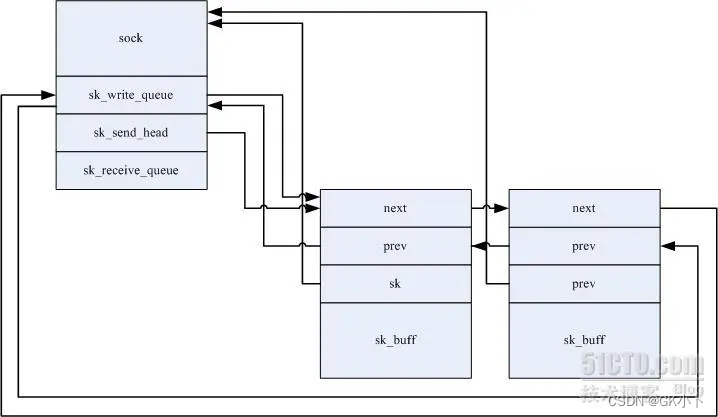
2、sk_buff与套接字缓冲区
sk_buff与套接字缓冲区一般是指代同一个意思,但严格来说sk_buff是一种数据结构,用来管理一个数据区的结构,这个结构加上这个数据区合起来叫套接字缓冲区,即socket buffer9(skb)
也有说挂载在sk_write_queue和sk_read_queue上的sk_buff叫套接字缓冲区
socket kernel buffer (skb) 是 Linux 内核网络栈(L2 到 L4)处理网络包(packets)所使用的 buffer,它的类型是 sk_buffer。简单来说,一个 skb 表示 Linux 网络栈中的一个 packet;TCP 分段和 IP 分片生产的多个 skb 被一个 skb list 形式来保存。
skb的结构和主要操作
分配skb
skb = alloc_skb(len, GFP_KERNEL)
alloc_skb是net/core/skbuff.c里面定义的,用于分配缓冲区的函数。我们已经知道,数据缓冲区和缓冲区的描述结构(sk_buff结构)是两种不同的实体,这就意味着,在分配一个缓冲区时,需要分配两块内存(一个是缓冲区,一个是缓冲区的描述结构sk_buff)。
与数据缓冲区的区别?
skb挂载在sk_recive_queue或sk_write_queue上时,skb属于数据缓冲区里的数据,如下图是被挂载
sk_buff的组织形式
1、skb 在内核的哪些层次会被使用
2、skb 有哪些重要的成员,如何借助于一些辅助函数操作这些成员
3、skb_shared_info 中的 frags 和 frag_list 有什么区别,各自的用途是什么
4、怎么基于 skb_shared_info 中的 frags[] 实现磁盘文件到网络的零拷贝
5、怎么基于 skb_shared_info 中的 frags[] 实现TSO (硬件TCP Segment Offload)
6、linux 内核和驱动是如何支持 scatter-gather
上述这些问题参考如下文章链接:
内核 skb/sk_buff 详解
*
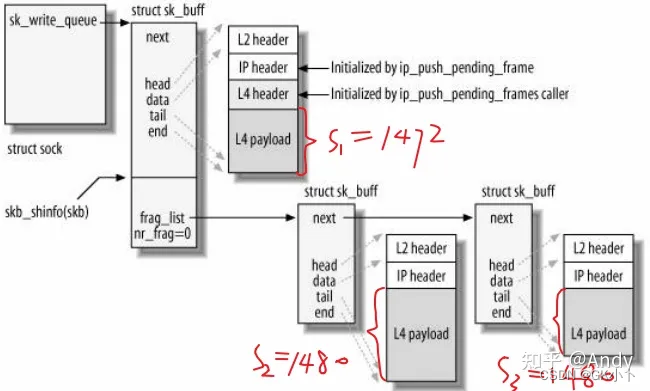
skb网络包的流向
IP分片结构
frag_list 主要用在内核协议栈的 IP 分片。目前看来,还很少有硬件网络设备支持 frag list 卸载(如果硬件支持卸载,则设备驱动会对 netdevice feature 或上 NETIF_F_FRAGLIST,即 netdev->hw_features |= NETIF_F_FRAGLIST)。
例如,当应用层write 发送一笔 4432 (S1 + S2 + S3) 字节的packet,MTU为1500, 则会分为三个skb进行发送。三个skb通过第一个skb 的 frag_list 作为链表的头部,后面两个skb 通过 skb->next 指针进行串联。
3、滑动窗口与缓冲区的关系
滑动窗口与缓冲区的关系
滑动窗口在tcp_write_xmit函数运行维护
滑动窗口的移动在tcp_ack函数中进行
详细可以了解有关章节
滑动窗口的实现与维护在tcp_write_xmit()函数中
发送窗口
我们在创建套接字的时候, 通过SO SENDBUF 指定
了发送缓冲区的大小, 如果设置了大小为2048KB ,
则Li n ux 在真实创建的时候会设置大小
2048 * 2 = 4096 , 因为丨inu × 除了要考虑用户的应用
层数据, 还需要考虑| i n ux 自身数据结构的开销一协议头部、指针、非线性内存区域结构等·
sk buff 结构中通过sk wmem queued 标识发送缓
冲区已经使用的内存大小, 并在发包时检查当前缓冫中
区大小是否小于S O SENDBUF 指定的大小, 如果不
满足贝刂阻塞当前线程, 进行睡眠, 等待发送窗口中有
包被AC K 后触发内存free 的回调函数唤醒后继续尝试
发送;
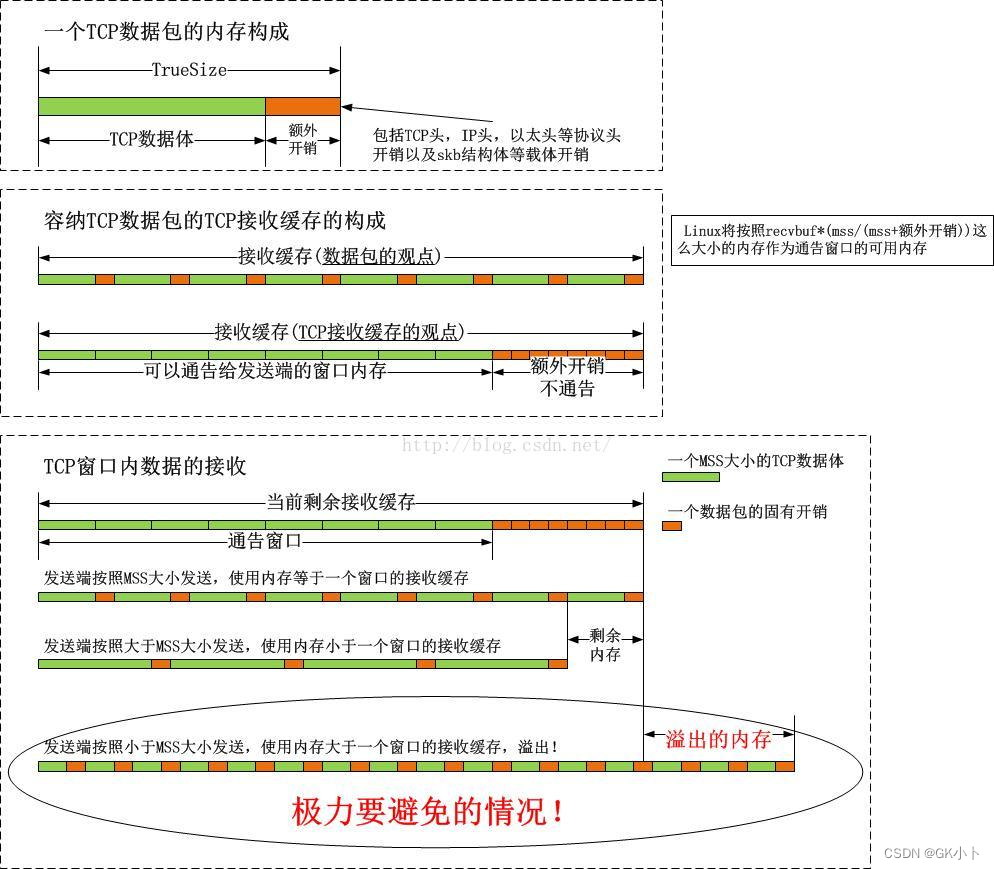
接收窗口
主要分为3 部分:
RCV.USER 为积压的已经收到但尚未被用户进程
通过read 等系统调用获取的网络数据包; 当用户
进程获取后窗口的左端会向右移动, 并触发回调
函数将该数据包的内存free 掉;
RCV.WN D 为未使用的, 推荐返回给该套接字的
客户端发送方当前剩余的可发送的bytes 数, 即
拥塞窗口的大小;
第三部分为未使用的, 尚未预先内存分配的, 并
不计算在拥塞窗口的大小中;
|<---------- RCV.BUFF ---------------->|
1 2 3
|<-RCV.USER->|<--- RCV.WND ---->|<---->|
----|------------|------------------|------|----
RCV.NXT
滑动窗口最重要的是接收窗口,因为TCP报文中通告的win代表的是client或server端的接收窗口,告诉对方接下来可以接收的数据大小
一个 TCP 接收缓冲区问题的解析
一个 TCP 发送缓冲区问题的解析
滑动窗口与缓冲区的区别
Socket发送缓冲区接收缓冲区快问快答
关于Linux TCP接收缓存以及接收窗口的一个细节解析
滑动窗口工作原理
TCP滑动窗口原理终于清楚了!有抓包实验
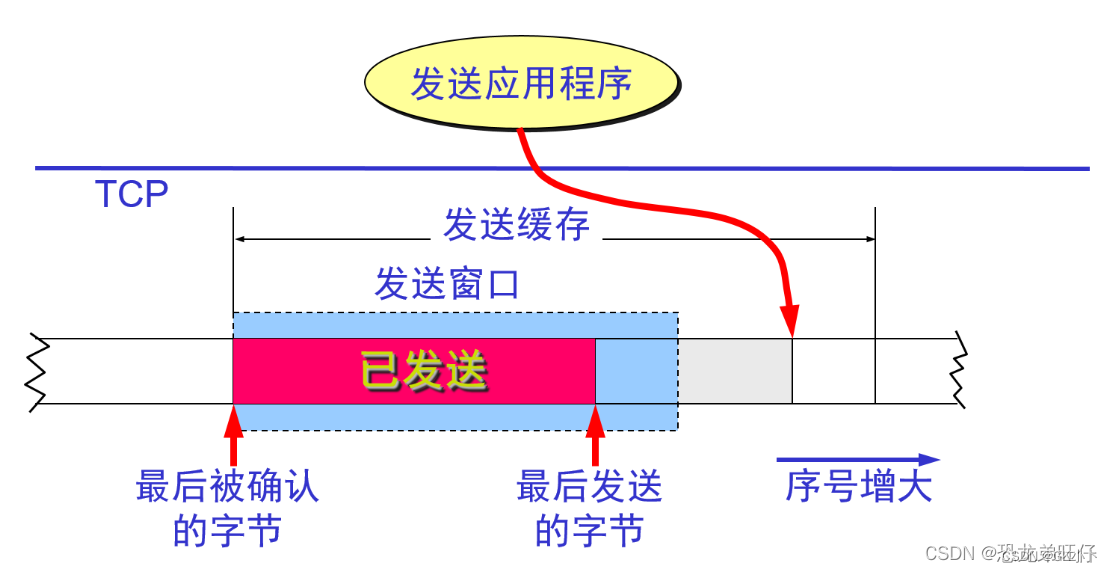
TCP 的流量控制
TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于 接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报。滑动窗口是 TCP 中实现诸如 ACK 确认、流量控制、拥塞控制的承载结构。
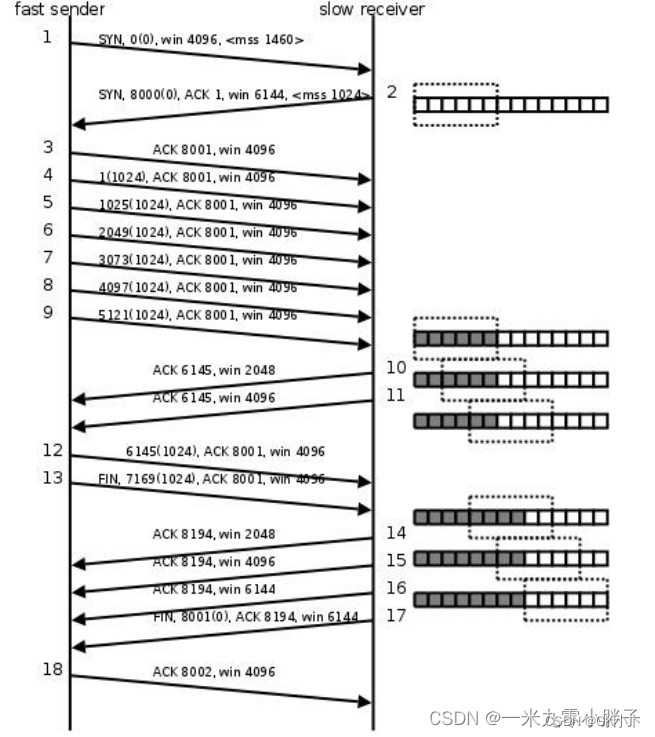
#mss:Maximum segment size(一条数据的最大的数据量)
win:滑动窗口
1、客户端向服务器发起连接,客户端的滑动窗口是4096,一次发送的最大数据量是1460(第一次握手);
2、服务器接收连接情况,告诉客户端服务器的窗口大小是6144,一次发送的最大数据量10243(第二次握手);
3、第三次握手;
4、4-9客户端连续给服务器发送了 6k 的数据,每次发送 1k;
5、第10次,服务器告诉客户端:发送的6k数据以及接收到,存储在缓冲区中,缓冲区数据已经处理了 2k,窗口大小是 2k;
6、第11次,服务器告诉客户端:发送的 6k 数据以及接收到,存储在缓冲区中,缓冲区数据已经处理了 4k,窗口大小是 4k;
7、第12次,客户端给服务器发送了 1k 的数据;
8、第13次,客户端主动请求和服务器断开连接,并且给服务器发送了1k的数据
9、第14次,服务器回复ACK 8194,a:同意断开连接的请求 b:告诉客户端已经接受到方才发的2k的数据 c:滑动窗口2k;
10、第15、16次,通知客户端滑动窗口的大小;
11、第17次,第三次挥手服务器端给客户端发送FIN ,请求断开连接;
12、第18次,第四次回收各户端同意了服务器端的断开请求。
说明:1-3是三次握手,4-9是进行通信;第一次和第二次握手时不能带有通信数据,因为还没有建立连接,第三次握手时可以带通信数据;
引入滑动窗口后引入tcp传输中存在的问题,解决方法
TCP协议中的窗口机制------滑动窗口详解
死锁状态
(1)概述:
当接收端向发送端发送零窗口报文段后不久,接收端的接收缓存又有了一些存储空间,于是接收端向发送端发送了Windows size = 2的报文段,然而这个报文段在传输过程中丢失了。发送端一直等待收到接收端发送的非零窗口的通知,而接收端一直等待发送端发送数据,这样就死锁了。
(2)解决方法
TCP为每个连接设有一个持续计时器。只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器,若持续计时器设置的时间到期,就发送一个零窗口探测报文段(仅携带1字节的数据),而对方就在确认这个探测报文段时给出了现在的窗口值。
TCP报文段的发送时机(传输效率问题)
可以用以下三种不同的机制控制TCP报文段的发送时机:
(1)TCP维持一个变量MSS,等于最大报文段的长度。只要缓冲区存放的数据达到MSS字节时,就组装成了一个TCP报文段发送出去
(2)由发送方的应用进程指明要发送的报文段,即:TCP支持推送操作
(3)发送方的一个计时器期限到了,这时就把当前已有的缓存数据装入报文段(但长度不能超过MSS)发送出去。
Nagle算法(控制TCP报文段的发送时机)
(1)主旨:避免大量发送小包
(2)初衷:避免发送大量的小包,防止小包泛滥于网络,在理想情况下,对于一个TCP连接而言,网络上每次只能有一个小包存在。它更多的是端到端意义上的优化
【CORK算法:提高网络利用率,理想情况下,完全避免发送小包,仅仅发送满包以及不得不发的小包】
发送方将第一个数据字节发送出去,把后面到达的数据字节缓存起来。当发送方接收对第一个数据字符的确认后,再把发送缓存中的所有数据组装成一个报文段再发送出去,同时继续对随后到达的数据进行缓存。只有在收到对前一个报文段的确认之后,才继续发送下一个报文段。规定一个TCP连接最多只能有一个未被确认的未完成的小分组,在该分组的确认到达之前不能发送其它的小分组。当数据到达较快而网络速率较慢时,用这样的方法可以明显的减少所用的网络带宽。
Nagle算法还规定:当达到的数据已经达到发送窗口大小的一半或者已经达到报文段的最大长度时,就可以立即发送一个报文段。
糊涂窗口综合症(接收端糊涂,网络上小包泛滥的原因之一)
(1)概述:
TCP接收方的缓存已满,而交互式的应用进程一次只从接收缓存区中读取1字节(这样就使接收缓存空间仅腾出1字节),然后向发送方发送确认,并把窗口设置为1个字节(但发送的数据报为40字节的话),然后,发送方又发来1字节的数据(发送方的IP数据报是41字节),接收方发回确认,仍将窗口设置为1个字节,这样,网络效率就会很低
(2)解决办法
a.你糊涂我不糊涂法。即Nagle算法。
可让接收方等待一段时间,使得或者 接收缓存已有足够的空间容纳一个 最长的报文段,或者等到接收方缓存已有一半的空闲空间。只要出现这两种情况,接收方就发回确认报文,并向发送方通知当前的窗口大小。此外,发送方也不要发送太小的报文段,而是把数据报文积累为足够大的报文段或达到接收方缓存的空间的一半大小。
b.治疗接收端的糊涂(其中一种机制是延迟ACK(还有其它机制,例如不发送小窗口通告等))
对于接收方而言, 延迟ACK可以拖延ACK发送时间,进而延迟窗口通告,在这段时间内,接收窗口有机会进一步放大
对于发送方而言, 不理会接收端的小窗口通告等于说不马上1发送小包,小包有时间积累成大包
拥塞窗口
TCP的拥塞处理 – Congestion Handling
网络编程5: TCP滑动窗口
上面我们知道了,TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。TCP的设计者觉得,一个伟大而牛逼的协议仅仅做到流控并不够,因为流控只是网络模型4层以上的事,TCP的还应该更聪明地知道整个网络上的事。
具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。
总的思想是增加一个发送方维护的变量cwnd(拥塞窗口), 然后swnd = min(cwnd, rwnd). 即发送窗口大小由拥塞窗口和接收窗口中较小的值决定。
4、为什么会粘包,怎么拆包
网络包的大小占用
考虑一个包含2bytes 的网络包, 需要包括预留头( 64
bytes) + Mac 头(14bytes) + 甲头(20bytes) + Tcp
头(32bytes) + 有效负载为2bytes(len) +
skb shared info(320bytes) = 452bytes, 向上取
整后为512bytes; sk_buff 这个存储结构占用
256bytes; 则一个2bytes 的网络包需要占用
512+256=768bytes(truesize) 的内存空间;
因此当发送这个网络包时:
Case1 : 不存在缓冲区积压, 则新建一个
sk buff 进行网络包的发送;
skb->truesize = 768
skb->datalen = 0
skb_shared_info 结构有效负载 (非线性区域)
skb->len = 2 有效负载 (线性区域 + 非线性区域(datalen),这里暂时不考虑协议头部)
Case2: 如果缓冲区积压( 存在未被AC K 的已经
发送的网络包一即SEND-Q (发送缓冲区:sk_write_queue)中存在sk buff 结构) ,Li n ux 会尝试将当前包合并到SEND一Q 的最后一个sk buff 结构中( 粘包) ; 考虑我们上述的768bytes 的结构体为SEN D 一Q 的最后一个sk buff, 当用户进程继续调用write 系统调用写入2kb 的数据时, 前一个数据包还未达到
MSS/MTU 的限制、整个缓冲区的大小未达到SO SENDBUF 指定的限制, 会进行包的合并,packet data = 2 + 2 , 头部的相关信息都可以
进行复用, 因为套接字缓冲区与套接字是一一对应的;
tail_skb->truesize = 768
tail_skb->datalen = 0
tail_skb->len =4 (2 + 2)
当启用了Nagle算法后,数据会倾向于堆积到一定大小或超时后才真正往网络发送数据,因此启用Nagle算法后的发送缓冲区更容易发生数据堆积。
在tcp_sendmsg()中有下面这段代码
if (tcp_send_head(sk)) { /* 还有未发送的数据,说明该skb还未发送 */
/* 如果网卡不支持检验和计算,那么skb的最大长度为MSS,即不能使用GSO */
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len; /* 此skb可追加的最大数据长度 */
}
if (copy <= 0) { /* 需要使用新的skb来装数据 */
在tcp_write_xmit()函数里下面,进行nagle算法测试
/* tso_segs=1表示无需tso分段 */
if (tso_segs == 1) {
// 更据上面的代码,nagle只有在发送数据小于窗口的时候才有用
/* 根据nagle算法,计算是否需要发送数据 */
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
nonagle : TCP_NAGLE_PUSH))))
break;
}
会发生黏包的两种情况
5、期间网络包经历了哪些缓冲区,经历了几次拷贝
read then write
常见的场景中, 当我们要在网络中发送一个文件, 那
么首先需要通过read 系统调用陷入内核态读取
PageCache 通过CPU Copy 数据页到用户态内存
中, 接着将数据页封装成对应的应用层协议报文, 并
通过write 系统调用陷入内核态将应用层报文CPU
Copy 到套接字缓冲区中, 经过TC P/I P 处理后形成甲
包, 最后通过网卡的DMA Engine 将RingBuffer
Tx.ring 中的sk buff 进行DMA Copy 到网卡的内
存中, 并将| P 包封装为帧并对外发送。
PS: 如果PageCache 中不存在对应的数据页缓存,
贝刂需要通过磁盘D M A ( opy 到内存中。
因此read then write 需要两次系统调用( 4 次上下文
切换, 因为系统调用需要将用户态线程切换到内核态
线程进行执行) , 两次CPU Copy 、两次DMA
发送要拷贝三次:
1、用户空间–> 内核空间(套接字缓冲区,也即sk_write_queue)–>
2、网卡驱动空间(也是在内核空间,但是是要发送的sk_buff的备份,主要是为了重传,在tcp_transmit_skb函数中操作)–>
3、 DMA到网卡空间的发送队列
接收只用拷贝两次
1、DMA将网络帧从网卡拷贝到sk_buff缓冲区(这里的sk_buff缓冲区是指申请了有一大堆以sk_buff实体结构和数据结构为单位的内存,并挂载在ring buffer上)
2、从sk_buff缓冲区拷贝到用户空间(有的人要问了中间为什么没有拷贝到套接字缓冲区呢?因为中间的协议栈只是将sk_buff添加到了套接字缓冲区sk_read_queue上)
6、fastopen,获取当前的发送MSS,,设置TCP控制块结构
在tcp_sendmsg()中实现
TCP/IP协议栈在Linux内核中的运行时序分析
7、超时重传,拥塞窗口,滑动窗口
在tcp_write_xmit()中实现
8、 TCP segment,ip分片
9、 构建TCP头部和校验和 ,确定TCP数据段协议头包含的内容
tcp_transmit_skb()
在ip_fragment ()进行ip分片
10、接收缓冲区被TCP和UDP用来缓存网络上来的数据,一直保存到应用进程读走为止。
对于TCP,如果应用进程一直没有读取,接收缓冲区满了之后,发生的动作是:接收端通知发发端,接收窗口关闭(win=0)。这个便是滑动窗口的实现。保证TCP套接口接收缓冲区不会溢出,从而保证了TCP是可靠传输。因为对方不允许发出超过所通告窗口大小的数据。 这就是TCP的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方TCP将丢弃它。
11、发送端send()返回之时,数据不一定会发送到对端去
send(),仅仅是把应用层buffer的数据拷贝进socket的内核发送buffer中,发送是内核线程调用发送网络协议的事情,和用户进程send其实没有太大关系。
调用send发送网络数据包一定会立马发送出去吗?
代码执行send成功后,数据就发出去了吗?
Linux网络发送流程概述
TCP/IP 协议栈在 Linux 内核中的 运行时序分析
TCP协议发送函数tcp_sendmsg
12、通过合理的设置“TCP.SO_RCVBUF & TCP.SO_SNDBUF”来提高系统的吞吐量以及快速检测tcp链路的连通性; 这两个选项就是来设置TCP连接的两个buffer尺寸的。
13、UDP接收缓冲区
每个UDP socket都有一个接收缓冲区,没有发送缓冲区,从概念上来说就是只要有数据就发,不管对方是否可以正确接收,所以不缓冲,不需要发送缓冲区。
UDP:当套接口接收缓冲区满时,新来的数据报无法进入接收缓冲区,此数据报就被丢弃。UDP是没有流量控制的;快的发送者可以很容易地就淹没慢的接收者,导致接收方的UDP丢弃数据报。
14、阻塞:阻塞的本质是,进程因为资源等待而主动让出CPU
进程从运行队列删除,幷加入到等待队列,然后等待资源。等超时或数据资源到来则唤醒进程继续执行,若有数据可读那就把数据拷贝给进程,无数据可读但超时了则返回进程继续执行后面的逻辑。
TCP阻塞和非阻塞模式下的数据发送
15、非阻塞:本质是应用进程掌控读取数据的节奏,通过轮训的方式查询数据是否可读,
进程始终占用着CPU,能比较好地满足高性能进程需求,执行效率高(数据没到位,进程可以继续处理其他业务,无需阻塞其他业务进行)。
UDP有没有缓冲区
UDP也有缓冲区吗
3.1 UDP也有缓冲区吗
说完TCP了,我们聊聊UDP。这对好基友,同时都是传输层里的重要协议。既然前面提到TCP有发送、接收缓冲区,那UDP有吗?
以前我以为。
“每个UDP socket都有一个接收缓冲区,没有发送缓冲区,从概念上来说就是只要有数据就发,不管对方是否可以正确接收,所以不缓冲,不需要发送缓冲区。”
后来我发现我错了。
UDP socket 也是 socket,一个socket 就是会有收和发两个缓冲区。跟用什么协议关系不大。
有没有是一回事,用不用又是一回事。
3.2 UDP不用发送缓冲区?
事实上,UDP不仅有发送缓冲区,也用发送缓冲区。
一般正常情况下,会把数据直接拷到发送缓冲区后直接发送。
还有一种情况,是在发送数据的时候,设置一个 MSG_MORE 的标记。
ssize_t send(int sock, const void *buf, size_t len, int flags); // flag 置为 MSG_MORE
大概的意思是告诉内核,待会还有其他更多消息要一起发,先别着急发出去。此时内核就会把这份数据先用发送缓冲区缓存起来,待会应用层说ok了,再一起发。
我们可以看下源码。
int udp_sendmsg()
{
// corkreq 为 true 表示是 MSG_MORE 的方式,仅仅组织报文,不发送;
int corkreq = up->corkflag || msg->msg_flags&MSG_MORE;
// 将要发送的数据,按照MTU大小分割,每个片段一个skb;并且这些
// skb会放入到套接字的发送缓冲区中;该函数只是组织数据包,并不执行发送动作。
err = ip_append_data(sk, fl4, getfrag, msg->msg_iov, ulen,
sizeof(struct udphdr), &ipc, &rt,
corkreq ? msg->msg_flags|MSG_MORE : msg->msg_flags);
// 没有启用 MSG_MORE 特性,那么直接将发送队列中的数据发送给IP。
if (!corkreq)
err = udp_push_pending_frames(sk);
}
因此,不管是不是 MSG_MORE, IP都会先把数据放到发送队列中,然后根据实际情况再考虑是不是立刻发送。
而我们大部分情况下,都不会用 MSG_MORE,也就是来一个数据包就直接发一个数据包。从这个行为上来说,虽然UDP用上了发送缓冲区,但实际上并没有起到"缓冲"的作用。
深入分析网络接收发送
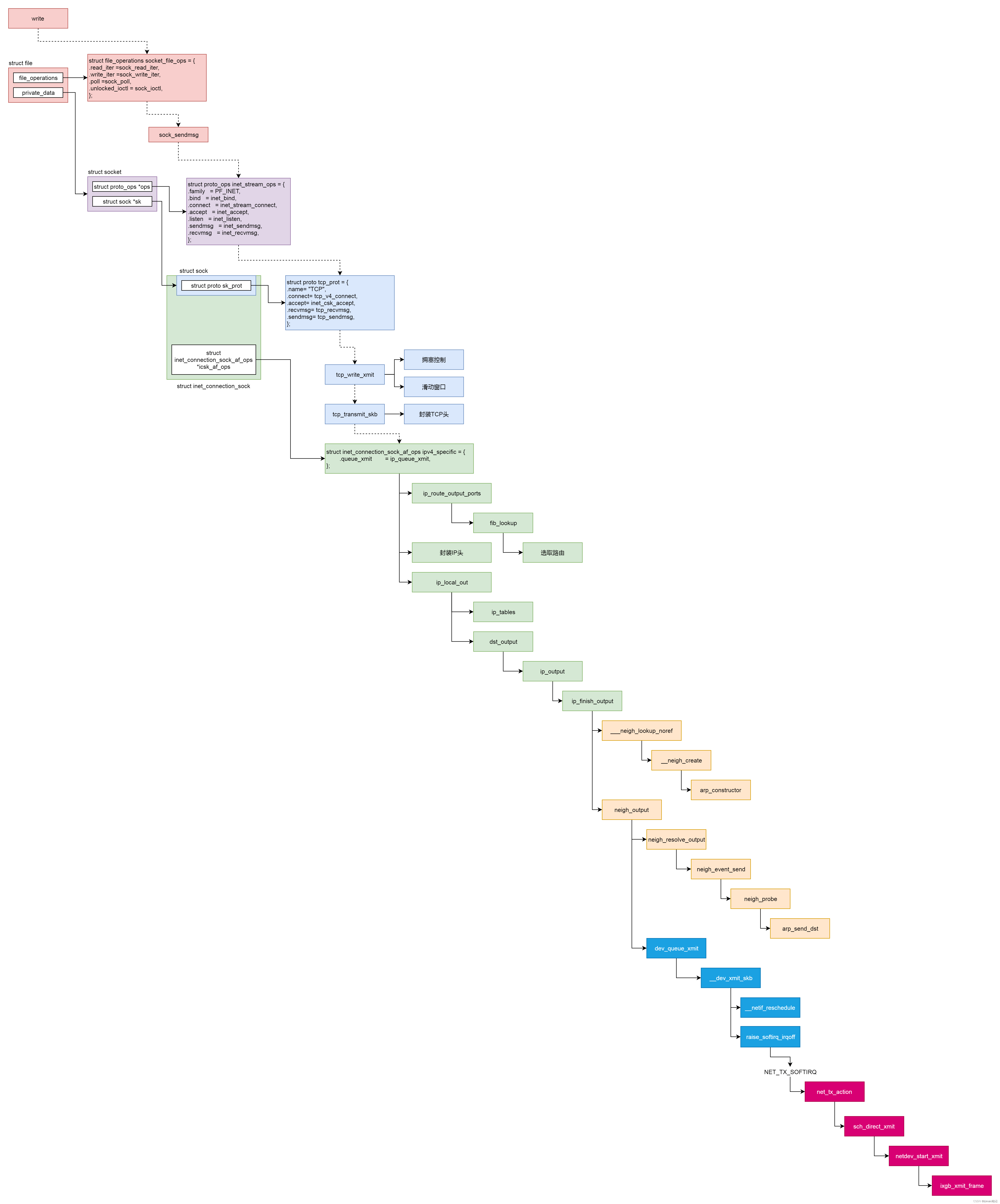
下图为发送接收的总流程函数图:
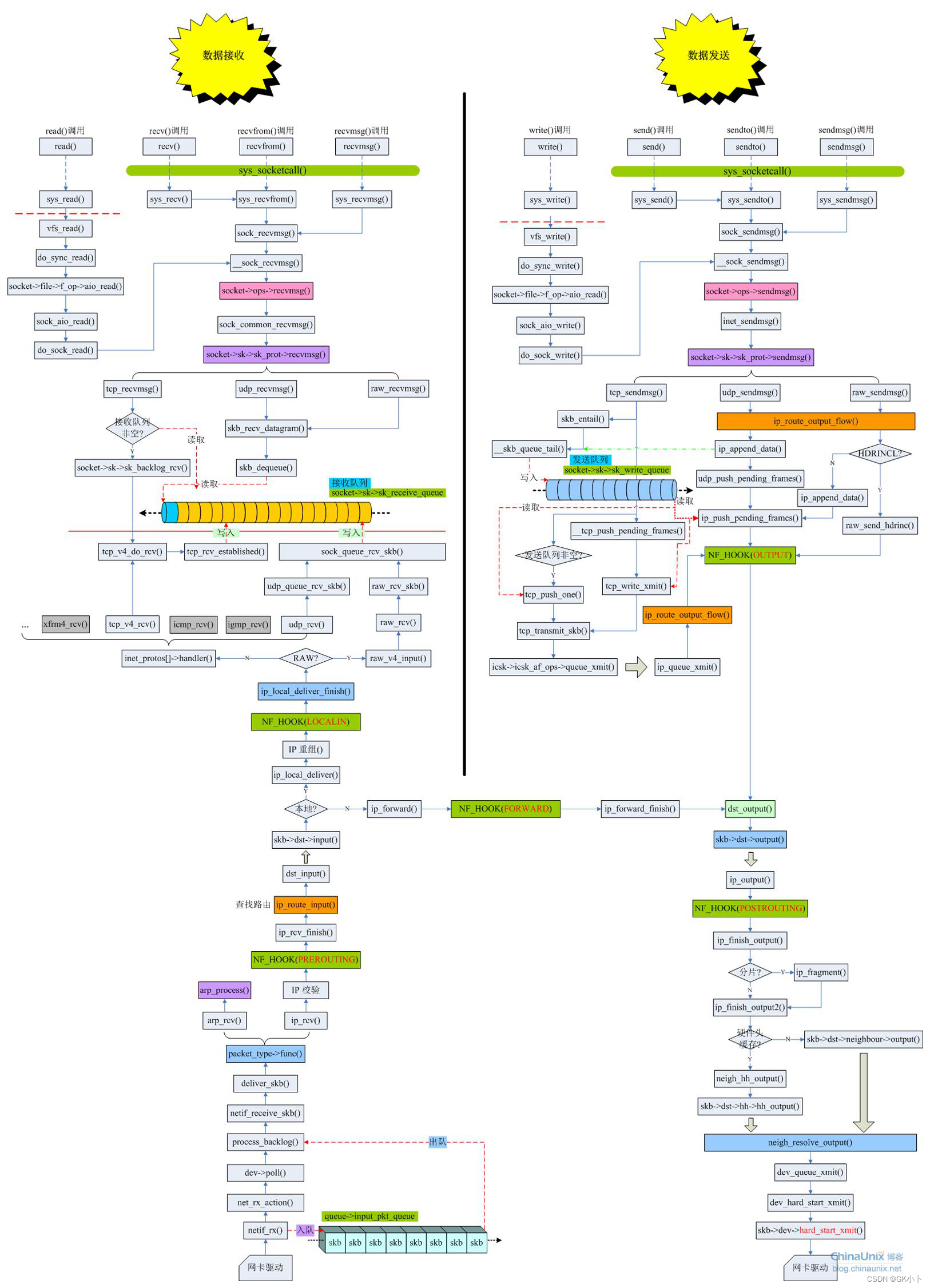
接收数据:
上图为网卡接收数据到IP网络层 网卡接收数据流程——设备驱动与内核线程详细函数解析
图解 Linux 网络包接收过程
TCP/IP协议栈在Linux内核中的运行时序分析(有接收代码详解)
发送数据
对于数据发送,网络发送缓冲区与窗口关系的探究与思考(有发送代码详解)
网卡适配器收发数据帧流程
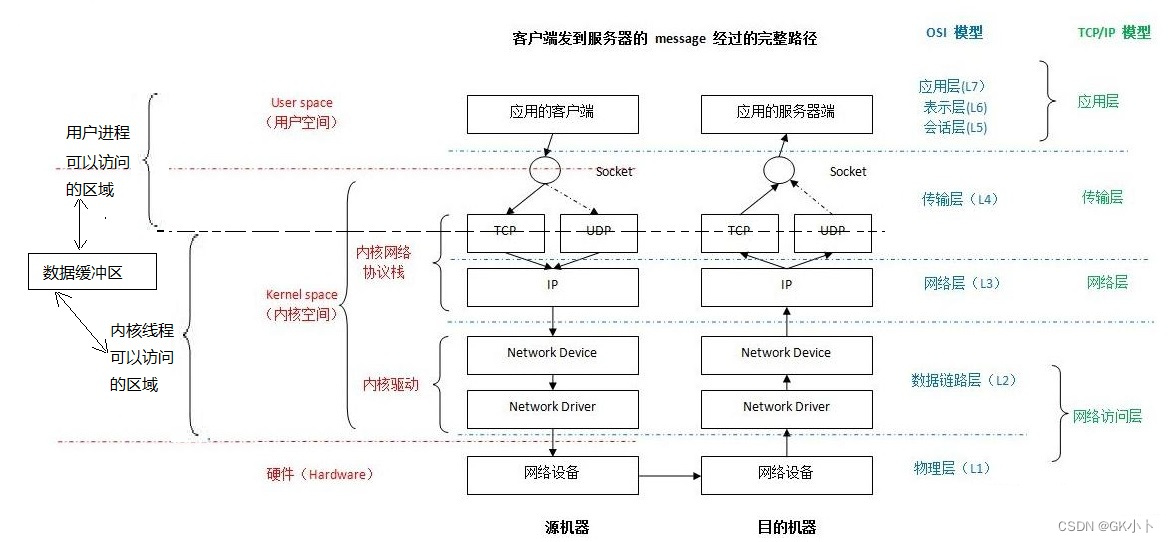
深度解析Linux网络收发包流程
TCP/IP 协议栈在 Linux 内核中的 运行时序分析
TCP三次握手和四次挥手
wireshark分析TCP的三次握手和四次断开

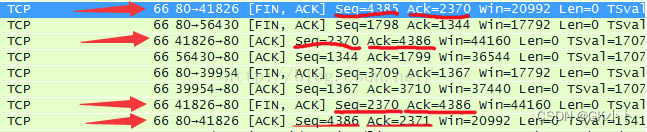
断开请求FIN可以是client发也可以是服务器端发
下面这个就是服务器段发,
下面是我进入路由器界面发送http请求,获取到的包如下:
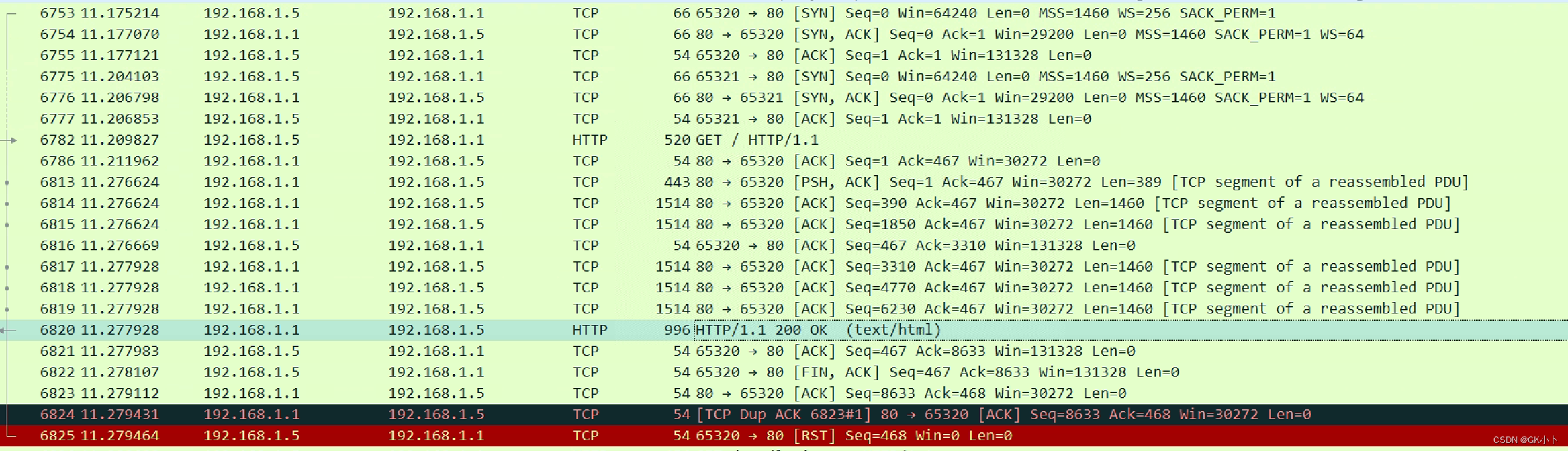
最后一个http 报文就是服务器段发起的FIN结束
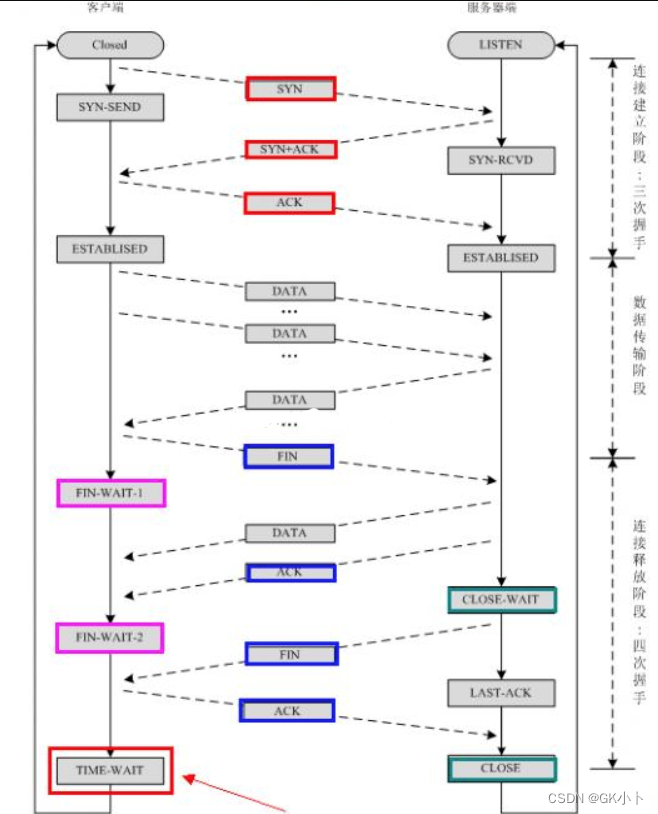
TCP为什么是三次握手,而不是两次或者四次的解析
TCP为什么是三次握手,而不是两次或者四次的解析
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。
假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。
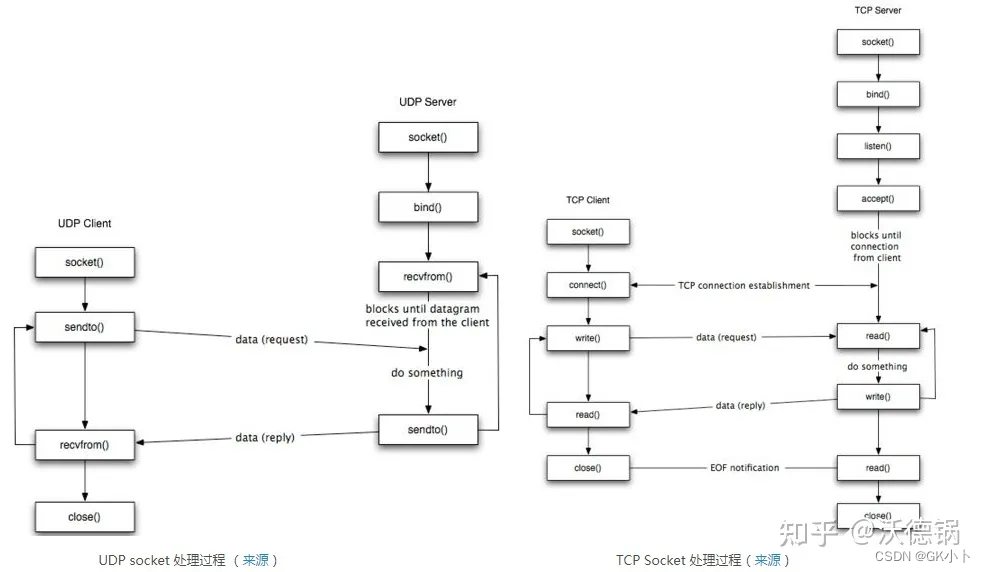
socket套接字编程
python网络编程
网络编程——python

![[DASCTF 2023 0X401七月暑期挑战赛] REV1 controlflow复现](https://img-blog.csdnimg.cn/8caa349b0a3b44f2b326586e84ceea51.png)