文章目录
- 一、Kafka
- 1.Kafka核心介绍:
- 核心架构
- 核心特性
- 典型应用
- 2.Kafka对 ZooKeeper 的依赖:
- 3.去 ZooKeeper 的演进之路:
- 注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
- 二、Zookeeper
- 1.核心架构与特性
- 2.典型应用场景
- 3.优势与局限
- 三、Zookeeper安装部署
- 1.拉取镜像
- 2.创建数据卷
- 3.创建容器
- 4.Zookeepe可视化工具-prettyZoo下载和安装
- 5.prettyZoo使用
- 四、Kafka安装部署
- 1.拉取镜像
- 2.创建数据卷
- 3.创建容器
- 4.Kakfa可视化操作工具kafka-ui安装
- 4.1、拉镜像
- 4.2、创建容器
- 4.3、访问kafka-ui
- 5.Kakfa可视化操作工具kafka-ui使用
- 五、Spring Boot使用Kafka
- 1.pom文件引入关键jar
- 2.yml文件引入配置
- 3.Topic配置
- 4.消息体创建
- 5.Producer实现
- 6.Consumer实现
- 7.启动类配置
- 8.Controller测试发送
- 9.测试验证
- 总结
一、Kafka
kafka官方文档
1.Kafka核心介绍:
Apache Kafka 是由 Apache 软件基金会开发的开源分布式流处理平台,最初由 LinkedIn 团队设计,旨在解决大规模实时数据管道问题。其核心功能是作为高吞吐、低延迟的分布式发布-订阅消息系统,支持每秒百万级消息处理能力。
核心架构
Topic(主题):消息的逻辑分类,生产者按主题发布数据,消费者按主题订阅。
Partition(分区):每个主题划分为多个分区,实现数据并行处理和水平扩展。
Broker(代理):Kafka 集群中的服务节点,负责存储和路由消息。
Producer/Consumer:生产者推送消息至 Broker,消费者从 Broker 拉取数据,支持消费者组(Consumer Group)实现负载均衡。
核心特性
持久化与高可靠:消息持久化到磁盘,通过多副本机制(Replication)保障数据容错。
水平扩展:通过分区和 Broker 动态扩容,支持万级节点和 PB 级数据存储。
实时流处理:与 Spark、Flink 等框架集成,支持实时计算、日志聚合、监控报警等场景。
典型应用
日志收集:统一收集多源日志,供离线分析或实时监控。
消息队列:解耦系统组件,如电商订单与库存服务异步通信。
实时推荐:基于用户行为流(如点击、搜索)实时生成个性化推荐。
数据管道:作为 CDC(变更数据捕获)工具,同步数据库变更至数据湖或搜索引擎。
Kafka 凭借其高性能和灵活性,已成为大数据生态的核心组件,适用于金融、物联网、电商等领域的实时数据处理需求。
2.Kafka对 ZooKeeper 的依赖:
Apache Kafka 在 4.0 版本之前 高度依赖 ZooKeeper,主要用于集群元数据管理(如 Broker 注册、Topic 分区分配)、控制器选举、消费者偏移量存储(旧版本)等核心功能。ZooKeeper 作为分布式协调服务,承担了 Kafka 集群的“大脑”角色,但存在运维复杂、性能瓶颈(如万级分区下元数据同步延迟)等问题。
3.去 ZooKeeper 的演进之路:
Kafka 2.8.0(2021年):
首次引入 KRaft 模式(KIP-500),作为实验性功能,允许用户通过 KRaft 协议替代 ZooKeeper 管理元数据。但此时仍需 ZooKeeper 作为过渡支持,且未默认启用。
Kafka 3.3.x(2022年):
KRaft 模式逐步稳定,支持生产环境部署,但仍需用户手动配置切换模式。
Kafka 4.0.0(2025年3月18日发布):
正式移除对 ZooKeeper 的依赖,默认仅支持 KRaft 模式。用户无法再以 ZooKeeper 模式启动集群,需通过 KRaft 完成元数据管理和控制器选举。
注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
我们本文还是使用kafka+zookeeper结合的方式来学习Kafka,在学习kafka的同时也能学习到zookeeper的使用,现在大部分公司还都在使用这种方式。
二、Zookeeper
Zookeeper官网
ZooKeeper 是一款由雅虎开源的分布式协调服务框架,旨在为分布式系统提供高效、可靠的一致性服务。其核心功能包括配置管理、分布式锁、服务注册与发现等,广泛应用于大数据和微服务领域(如 Kafka、HBase、Dubbo)。
1.核心架构与特性
数据模型
采用树形结构的 ZNode(数据节点)存储数据,每个节点可保存数据并包含子节点,类似于文件系统。节点分为四类:
持久节点:长期存在,需手动删除
临时节点:会话结束自动删除
顺序节点:自动追加全局唯一序号,适用于分布式队列
一致性保障
基于 ZAB(ZooKeeper Atomic Broadcast)协议,确保数据顺序一致性、原子性和可靠性。通过 Leader 选举机制(半数以上节点投票)实现高可用,集群需奇数节点(如 3、5 台)以防止脑裂。
动态监听(Watcher)
客户端可监听节点变化(数据修改、子节点增减),触发事件通知实现实时响应。
2.典型应用场景
配置管理:集中存储配置信息,动态推送到所有服务节点
分布式锁:通过临时顺序节点实现互斥资源访问
服务注册与发现:如 Dubbo 使用 ZooKeeper 维护全局服务地址列表
集群管理:监控节点状态,自动处理故障切换
3.优势与局限
优势:简化分布式系统开发,提供高性能(内存存储)和强一致性
局限:不适用于海量数据存储,写性能受集群规模限制
ZooKeeper 通过封装复杂的一致性算法,成为分布式系统的“基础设施”,尤其适用于需要协调与状态同步的场景。
三、Zookeeper安装部署
1.拉取镜像
docker pull zookeeper:3.8

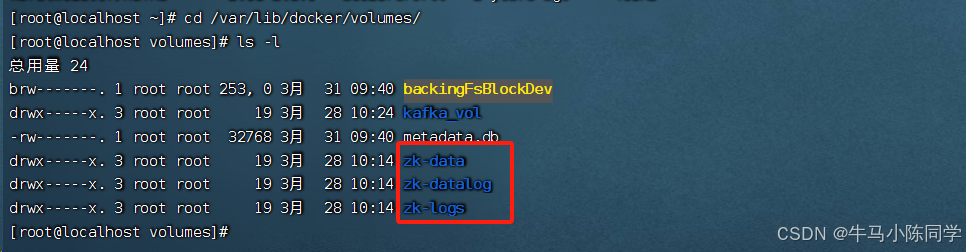
2.创建数据卷
创建数据卷,方便数据持久化
docker volume create zk-data
docker volume create zk-datalog
docker volume create zk-logs
3.创建容器
创建zookeeper-test容器,同时挂载数据卷和并指定端口映射(2181)
docker run -d --name zookeeper-test -p 2181:2181 \
--env ZOO_MY_ID=1 \
-v zk-data:/data \
-v zk-datalog:/datalog \
-v zk-logs:/logs \
zookeeper:3.8

4.Zookeepe可视化工具-prettyZoo下载和安装
PrettyZoo 是一款基于 Apache Curator 和 JavaFX 开发的开源 Zookeeper 图形化管理客户端,专为简化 Zookeeper 运维设计。其核心功能包括:
多平台支持:提供 Windows(msi)、Mac(dmg)、Linux(deb/rpm)安装包,无需额外安装 Java 运行时即可运行;
可视化操作:支持节点增删改查(CRUD)、实时数据同步、ACL 权限配置、SSH 隧道连接,以及 JSON/XML 数据格式化与高亮显示;
命令行集成:内置终端支持 80% 的 Zookeeper 命令,并可直接执行四字命令(如 stat、ruok 等)监控集群状态;
多集群管理:可同时连接多个 Zookeeper 服务器,支持配置导入导出,提升运维效率。
该工具界面简洁美观,适合开发测试及中小规模环境,大幅降低 Zookeeper 的操作复杂度。
GitHub下载地址
我这里是在windows上下载使用,所以选择windows版本。
安装很简单,傻瓜式安装即可,没有特殊配置。


5.prettyZoo使用
填写IP和端口进行连接。
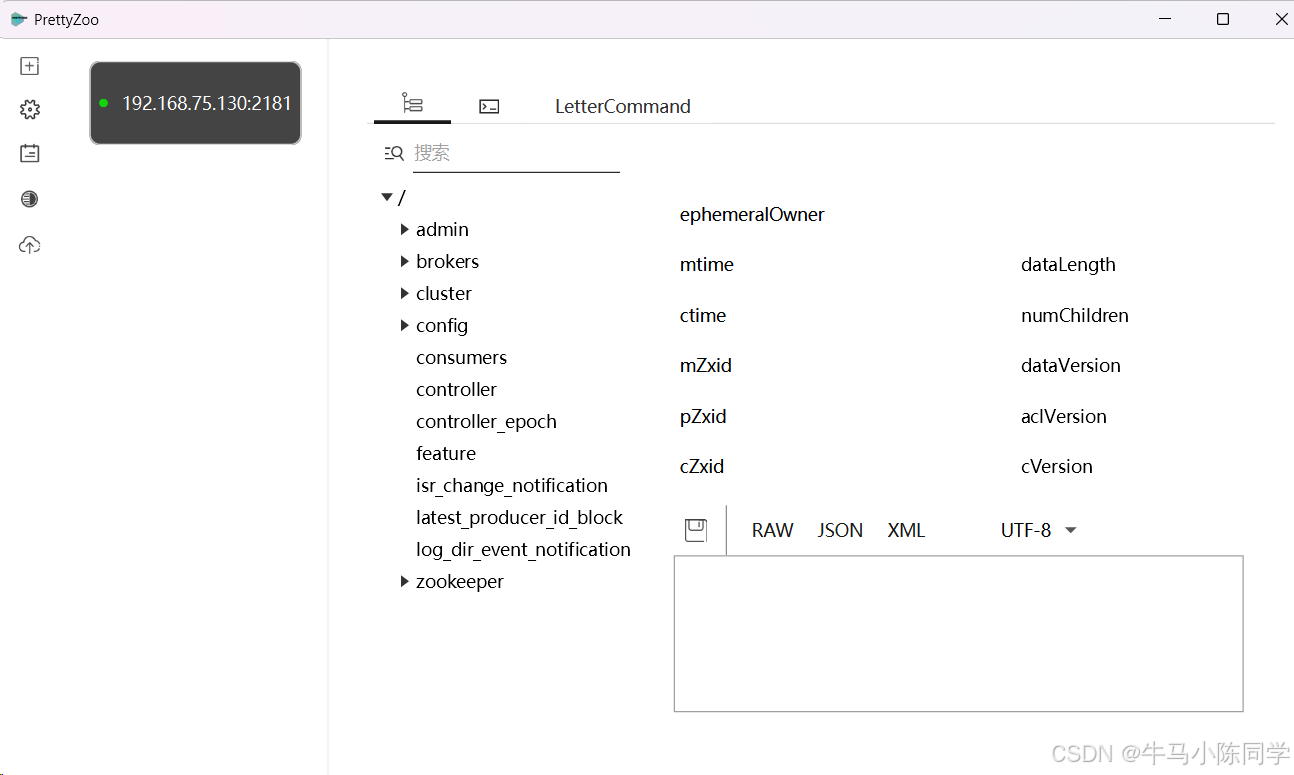
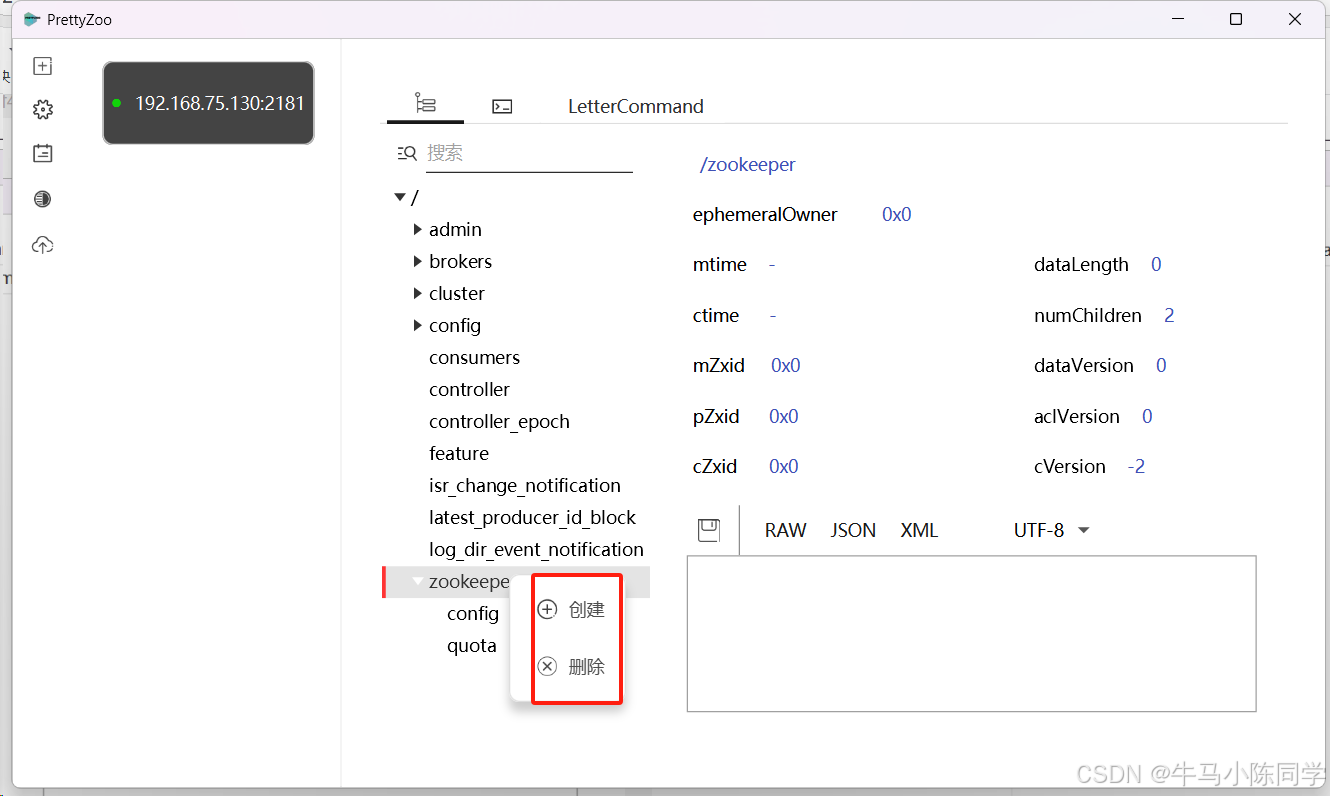
连接成功后,目录结构就能看到了,可以直接在工具上创建和删除节点。还可以编写命令进行操作。工具使用就简单介绍一下,感兴趣的同学可以下载玩一玩。
四、Kafka安装部署
1.拉取镜像
wurstmeister/kafka 适合开发/测试,但生产环境建议使用官方或企业版(如 Confluent)。
2.13-2.8.1 代表Kafka 依赖的 Scala 版本为2.13,kafka自身的版本为2.8.1。
docker pull wurstmeister/kafka:2.13-2.8.1

2.创建数据卷
创建数据卷,方便数据持久化
docker volume create kafka_vol

3.创建容器
创建kafka-test容器,同时挂载数据卷和并指定端口映射(9092),并将zookeeper-test链接到该容器,使Kafka可以成功访问到zookeeper-test,Kafka相关参数通过环境变量(—env)设置。
docker run -d --name kafka-test -p 9092:9092 \
--link zookeeper-test \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper-test:2181 \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.75.130 \
--env KAFKA_ADVERTISED_PORT=9092 \
--env KAFKA_LOG_DIRS=/kafka/logs \
-v kafka_vol:/kafka \
wurstmeister/kafka:2.13-2.8.1

4.Kakfa可视化操作工具kafka-ui安装
Kafka-UI 是一款开源的 Web 可视化工具,专为管理和监控 Apache Kafka 集群设计,提供轻量、高效的运维体验。它支持多集群统一管理,可实时查看集群状态(如 Broker、Topic、分区和消费者组详情),并支持消息浏览(JSON、纯文本、Avro 格式)。用户可通过界面动态配置 Topic,管理消费者偏移量,并集成数据脱敏、权限控制等功能。其部署灵活,支持 Docker、Kubernetes 等多种方式,适合开发测试及中小规模生产环境,大幅降低 Kafka 的运维复杂度
4.1、拉镜像
docker pull provectuslabs/kafka-ui

4.2、创建容器
docker run -it --name kafka-ui -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui

4.3、访问kafka-ui
访问地址为你部署的服务器地址:http://localhost:8080/ (http://192.168.75.130:8080/)
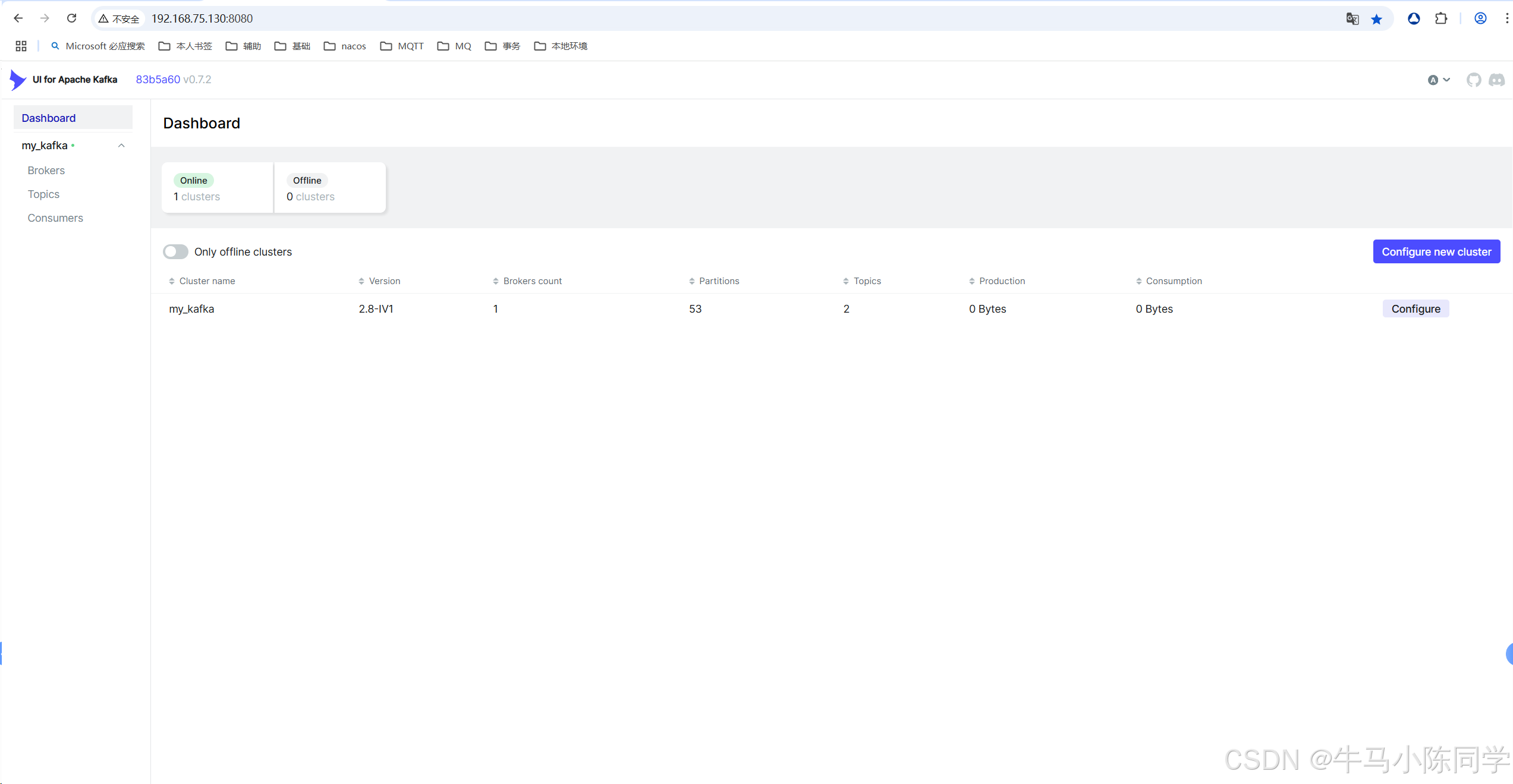
5.Kakfa可视化操作工具kafka-ui使用
创建连接:

连接后可以查看Brokers、Consumers,可以操作Topics,可以查看消息,也可以模拟Produce生产消息等等。详细操作功能就不再描述了,各位同学可以自行部署尝试。
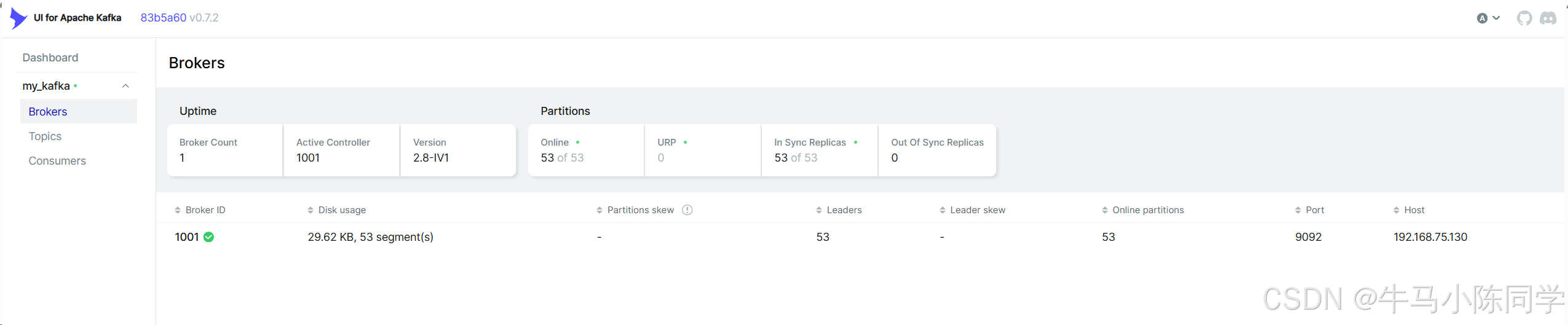


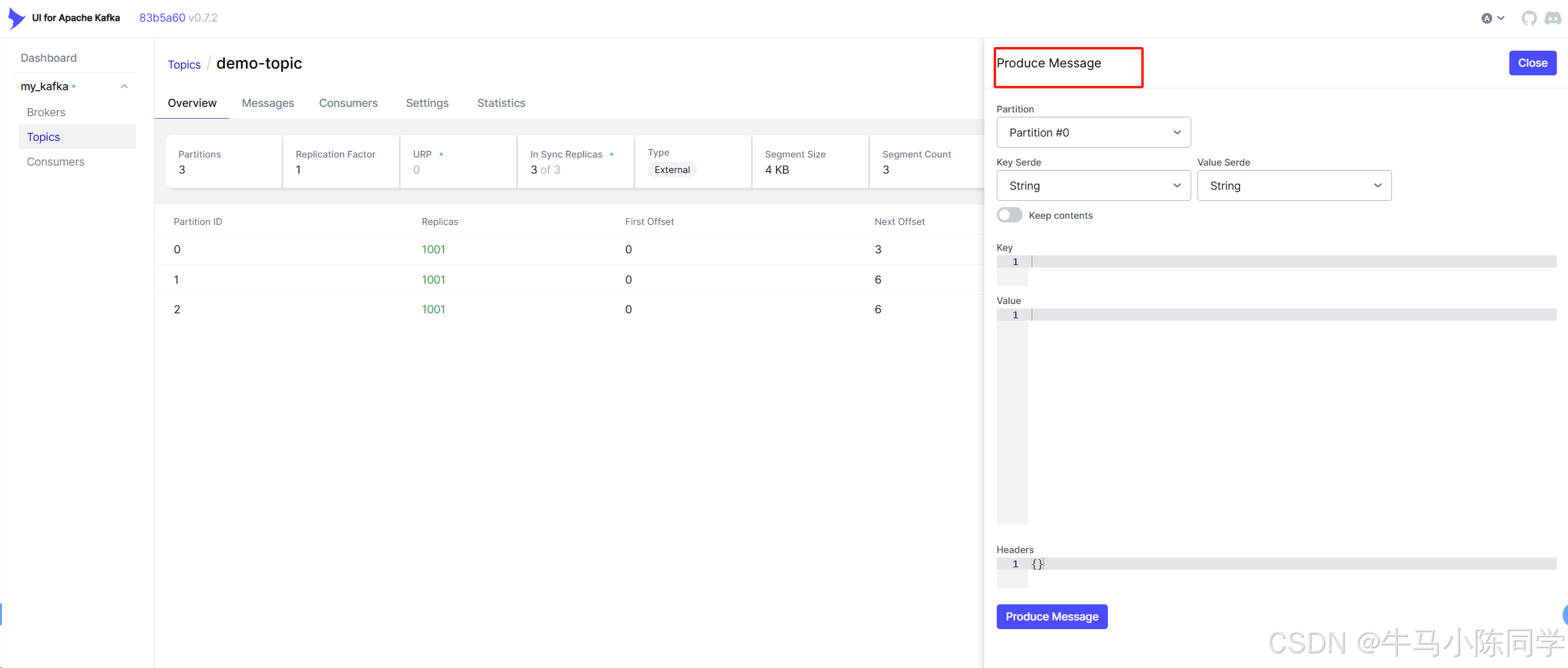
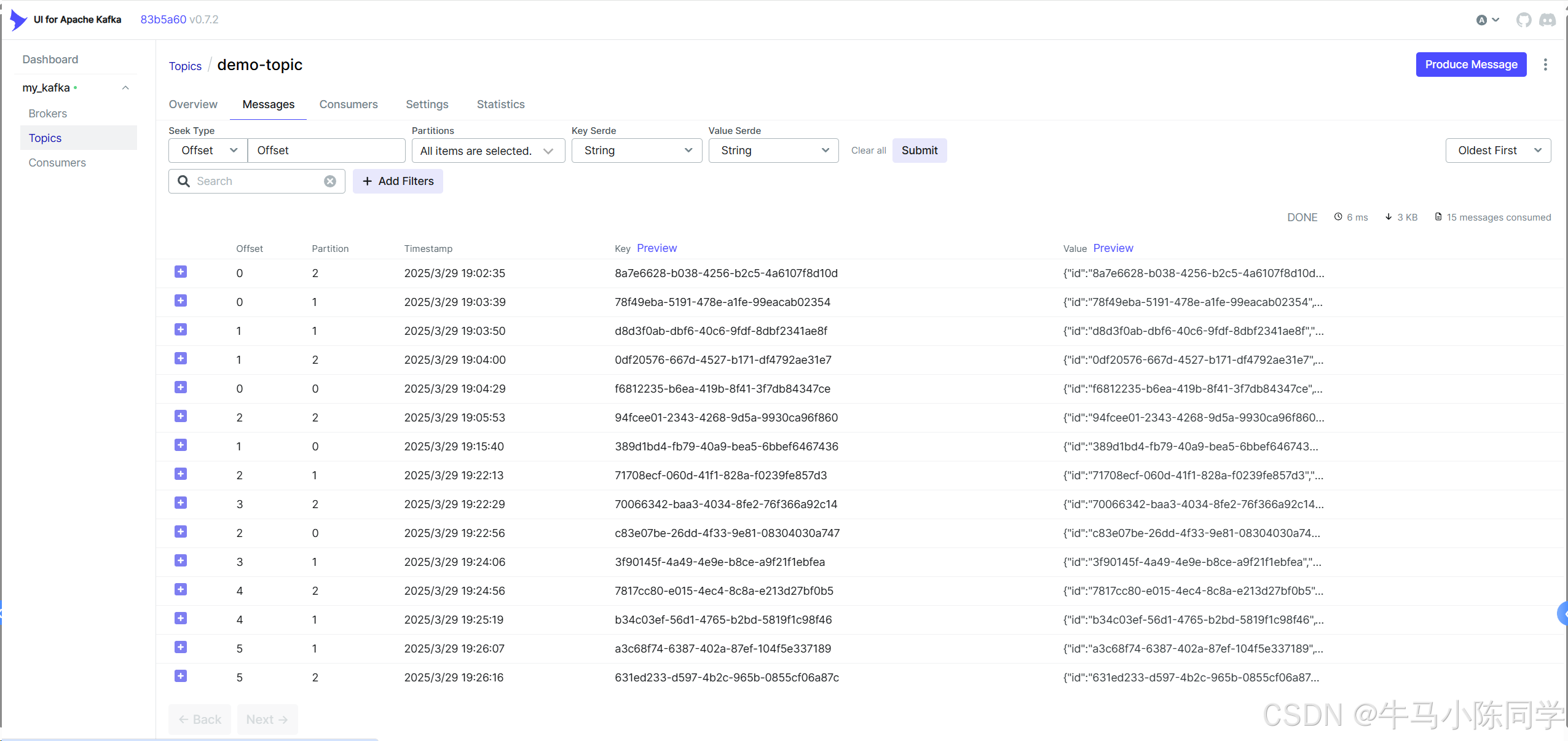
五、Spring Boot使用Kafka
因为kafka部署的是2.8.1,需要对应Spring boot 2.7.x系列,我这里使用spring boot 2.7.6进行案例。
1.pom文件引入关键jar
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!-- spring boot版本 -->
<spring-boot.version>2.7.6</spring-boot.version>
<!-- kafka版本 -->
<spring-kafka.version>2.8.1</spring-kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Kafka 核心依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>${spring-kafka.version}</version>
</dependency>
<!-- Lombok 简化代码 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- JSON 序列化支持 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
</dependencies>
2.yml文件引入配置
spring:
kafka:
# 集群地址(多个用逗号分隔)
bootstrap-servers: 192.168.75.130:9092
# 生产者配置
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
retries: 3 # 失败重试次数
acks: all # 确保消息可靠投递
batch-size: 16384 # 批量发送优化
# 消费者配置
consumer:
group-id: demo-group # 消费组ID
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
enable-auto-commit: false # 手动提交偏移量
properties:
spring.json.trusted.packages: "*" # 允许反序列化任意包
# 监听器配置
listener:
ack-mode: MANUAL # 手动ACK
concurrency: 3 # 消费线程数
# 自定义主题名称
kafka:
topic:
demo: demo-topic
3.Topic配置
@Configuration
public class KafkaTopicConfig {
@Value("${kafka.topic.demo}")
private String demoTopic;
@Bean
public NewTopic demoTopic() {
return TopicBuilder.name(demoTopic)
// 分区数
.partitions(3)
// 副本数
.replicas(1)
.config(TopicConfig.RETENTION_MS_CONFIG, "604800000") // 保留7天
.build();
}
}
4.消息体创建
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DemoMessage {
private String id;
// 内容
private String content;
// 时间戳
private LocalDateTime timestamp;
}
5.Producer实现
@Slf4j
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, Object> kafkaTemplate;
@Autowired
public KafkaProducerService(KafkaTemplate<String, Object> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
// 发送消息(支持回调)
public void sendMessage(String topic, DemoMessage message) {
// 普通发送消息(支持回调)
kafkaTemplate.send(topic, message.getId(), message)
.addCallback(
success -> {
if (success != null) {
log.info("发送成功: Topic={}, Offset={}",
success.getRecordMetadata().topic(),
success.getRecordMetadata().offset());
}
},
ex -> log.error("发送失败: {}", ex.getMessage())
);
// 事务性发送消息(支持回调)
// kafkaTemplate.executeInTransaction(operations -> {
// operations.send(topic, message.getId(), message)
// .addCallback(
// success -> {
// if (success != null) {
// log.info("发送成功: Topic={}, Offset={}",
// success.getRecordMetadata().topic(),
// success.getRecordMetadata().offset());
// }
// },
// ex -> log.error("发送失败: {}", ex.getMessage())
// );
// return true;
// });
}
}
6.Consumer实现
@Slf4j
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "${kafka.topic.demo}", groupId = "demo-group")
public void consumeMessage(@Payload DemoMessage message, Acknowledgment ack) {
try {
log.info("收到消息: Content={}", message.getContent());
// 幂等处理
if (isMessageProcessed(message.getId())) {
log.warn("消息已处理: ID={}", message.getId());
ack.acknowledge();
return;
}
// 业务处理
// ...
// 手动提交偏移量
ack.acknowledge();
} catch (Exception e) {
log.error("处理异常: {}", e.getMessage());
}
}
private boolean isMessageProcessed(String messageId) {
// 实现幂等检查(如查数据库)
return false;
}
}
7.启动类配置
@EnableKafka
@SpringBootApplication
public class MyKafkaApplication {
public static void main(String[] args) {
SpringApplication.run(MyKafkaApplication.class, args);
}
}
8.Controller测试发送
@RestController
@RequestMapping("/kafka")
public class kafakTestController {
@Autowired
private KafkaProducerService producerService;
@RequestMapping("/sendMessage")
public String sendMessage(@RequestParam(value = "message") String message) {
DemoMessage message1 = new DemoMessage(
UUID.randomUUID().toString(),
message,
LocalDateTime.now()
);
producerService.sendMessage("demo-topic", message1);
return "消息发送成功!";
}
}
9.测试验证
模拟生产者生产消息,验证生产者和消费者是否正常工作。测试可用。

总结
总结了kafka使用的完整教程,加强一下自己对于kafka的整体概念,给想使用kafka的同学们入个门。