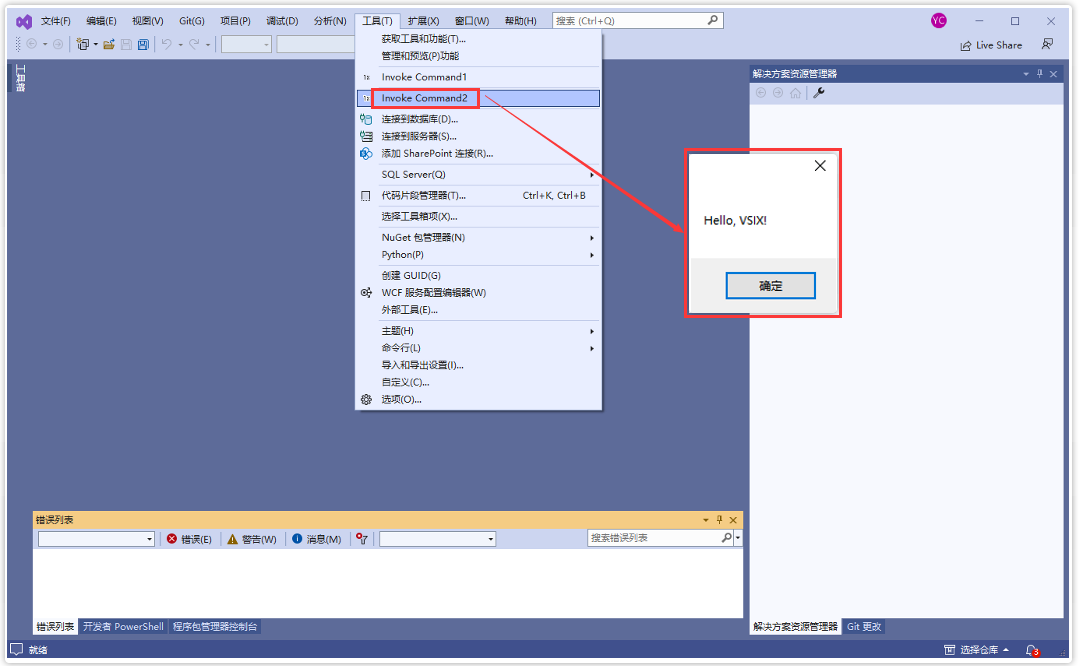
It’s Just Adding One Word at a Time
一次只添加一个词
That ChatGPT can automatically generate something that reads even superficially like human-written text is remarkable, and unexpected. But how does it do it? And why does it work? My purpose here is to give a rough outline of what’s going on inside ChatGPT—and then to explore why it is that it can do so well in producing what we might consider to be meaningful text. I should say at the outset that I’m going to focus on the big picture of what’s going on—and while I’ll mention some engineering details, I won’t get deeply into them. (And the essence of what I’ll say applies just as well to other current “large language models” [LLMs] as to ChatGPT.)
ChatGPT 能够自动生成一些看起来像人类编写的文本的内容,这是非常了不起,也是出乎意料的。但是它是如何做到的呢?为什么会起作用?我在这里的目的是给出 ChatGPT 内部发生的事情的大致轮廓,然后探讨为什么它能够如此出色地生成我们认为有意义的文本。首先我要说的是,我将关注整个过程的大局观,虽然我会提到一些工程细节,但不会深入探讨。(我将要说的内容同样适用于当前像 ChatGPT 那样的其他“大型语言模型”[LLMs]。)
The first thing to explain is that what ChatGPT is always fundamentally trying to do is to produce a “reasonable continuation” of whatever text it’s got so far, where by “reasonable” we mean “what one might expect someone to write after seeing what people have written on billions of webpages, etc.”
首先要解释的是,ChatGPT 基本上总是试图生成与迄今为止得到的文本“合理延续”,其中“合理”是指“在浏览了数十亿网页等内容后,人们可能预期会写下什么”。
So let’s say we’ve got the text “The best thing about AI is its ability to”. Imagine scanning billions of pages of human-written text (say on the web and in digitized books) and finding all instances of this text—then seeing what word comes next what fraction of the time. ChatGPT effectively does something like this, except that (as I’ll explain) it doesn’t look at literal text; it looks for things that in a certain sense “match in meaning”. But the end result is that it produces a ranked list of words that might follow, together with “probabilities”:
那么假设我们有这样一段文本:“关于 AI 最棒的是它的能力”。试想一下,扫描数十亿页由人类书写的文本(比如在网页和数字图书中),找到所有这段文本的实例,然后观察下一个单词出现的频率。ChatGPT 实际上就是执行类似的操作,不过(正如我将解释的),它并不查看字面文本,而是寻找某种意义上“意义相匹配”的内容。最终,它会生成一个可能接下来出现的单词的排序列表,同时附带“概率”:

And the remarkable thing is that when ChatGPT does something like write an essay what it’s essentially doing is just asking over and over again “given the text so far, what should the next word be?”—and each time adding a word. (More precisely, as I’ll explain, it’s adding a “token”, which could be just a part of a word, which is why it can sometimes “make up new words”.)
而令人惊讶的是,当 ChatGPT 做类似于写一篇文章的事情时,它实质上所做的就是一遍又一遍地询问“根据目前的文本,下一个词应该是什么?”——并且每次都添加一个词。(更准确地说,正如我将解释的,它添加的是一个“令牌”,这可能只是一个词的一部分,这就是为什么它有时可以“创造新词”的原因。)
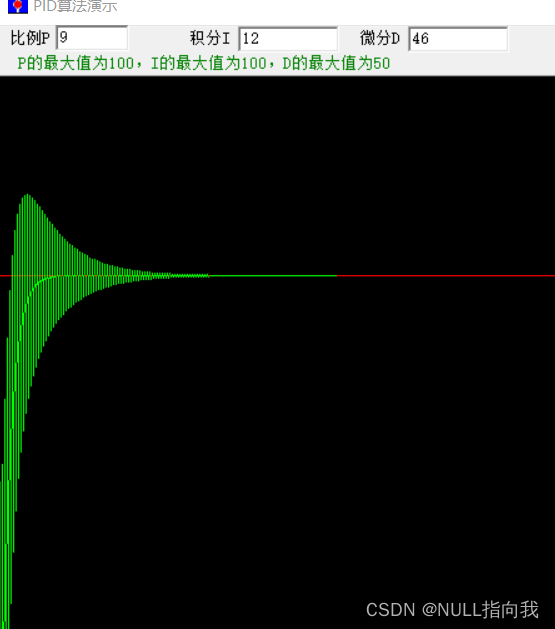
But, OK, at each step it gets a list of words with probabilities. But which one should it actually pick to add to the essay (or whatever) that it’s writing? One might think it should be the “highest-ranked” word (i.e. the one to which the highest “probability” was assigned). But this is where a bit of voodoo begins to creep in. Because for some reason—that maybe one day we’ll have a scientific-style understanding of—if we always pick the highest-ranked word, we’ll typically get a very “flat” essay, that never seems to “show any creativity” (and even sometimes repeats word for word). But if sometimes (at random) we pick lower-ranked words, we get a “more interesting” essay.
好的,在每一步中,它会得到一个带概率的词汇列表。但是,它究竟应该选择哪个词来添加到正在撰写的文章(或其他内容)中呢?人们可能会认为它应该选择“排名最高”的词(即被分配了最高“概率”的词),但这里就开始出现一些神秘的东西了。因为由于某种原因——或许有一天我们会对此有科学式的理解——如果我们总是选择排名最高的词,我们通常会得到一篇非常“平淡”的文章,似乎从未“表现出任何创造力”(甚至有时会逐字重复)。但如果我们有时(随机地)选择排名较低的词汇,我们就能得到一篇“更有趣”的文章。
The fact that there’s randomness here means that if we use the same prompt multiple times, we’re likely to get different essays each time. And, in keeping with the idea of voodoo, there’s a particular so-called “temperature” parameter that determines how often lower-ranked words will be used, and for essay generation, it turns out that a “temperature” of 0.8 seems best. (It’s worth emphasizing that there’s no “theory” being used here; it’s just a matter of what’s been found to work in practice. And for example the concept of “temperature” is there because exponential distributions familiar from statistical physics happen to be being used, but there’s no “physical” connection—at least so far as we know.)
事实上,这里的随机性意味着如果我们多次使用相同的提示,我们可能每次都会得到不同的文章。为了保持神秘感,有一个所谓的“温度”参数用来决定使用排名较低的词汇的频率,而对于生成文章来说,0.8 的“温度”似乎是最佳的。(值得强调的是,这里并没有使用任何“理论”;这只是根据实践中发现的有效方法。例如,“温度”的概念之所以存在,是因为碰巧使用了熟悉的指数分布,这是从统计物理中得出的,但并没有“物理”联系——至少就我们所知。)
Before we go on I should explain that for purposes of exposition I’m mostly not going to use the full system that’s in ChatGPT; instead I’ll usually work with a simpler GPT-2 system, which has the nice feature that it’s small enough to be able to run on a standard desktop computer. And so for essentially everything I show I’ll be able to include explicit Wolfram Language code that you can immediately run on your computer. (Click any picture here to copy the code behind it.)
在继续之前,我需要解释一下,为了阐述的目的,我在大多数情况下不会使用 ChatGPT 中的完整系统;相反,我通常会使用一个更简单的 GPT-2 系统,它的一个好处是它足够小,可以在标准桌面电脑上运行。因此,对于我展示的几乎所有内容,我都能够包含明确的 Wolfram 语言代码,您可以立即在您的电脑上运行。(点击这里的任何图片都可以复制其背后的代码。)
For example, here’s how to get the table of probabilities above. First, we have to retrieve the underlying “language model” neural net:
例如,这是如何得到上述概率表的方法。首先,我们需要获取底层的“语言模型”神经网络:
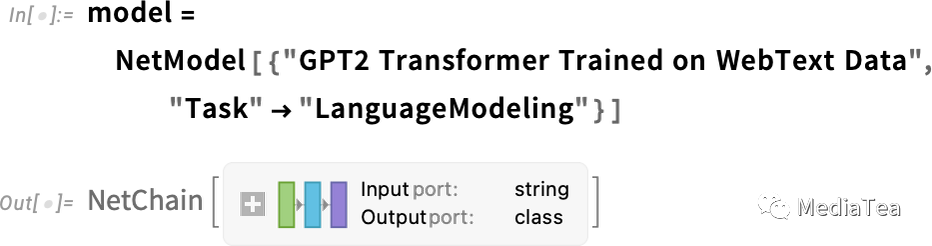
Later on, we’ll look inside this neural net, and talk about how it works. But for now we can just apply this “net model” as a black box to our text so far, and ask for the top 5 words by probability that the model says should follow:
稍后,我们将深入这个神经网络,并讨论它是如何工作的。但现在我们可以将这个“网络模型”作为一个黑盒子应用到目前的文本上,并询问模型认为应该接下来的概率排名前五的词汇:

This takes that result and makes it into an explicit formatted “dataset”:
这将结果转换成一个显式格式化的“数据集”:

Here’s what happens if one repeatedly “applies the model”—at each step adding the word that has the top probability (specified in this code as the “decision” from the model):
以下是反复“应用模型”的结果——在每一步中添加概率最高的词汇(在此代码中,将其指定为模型的“决策”):
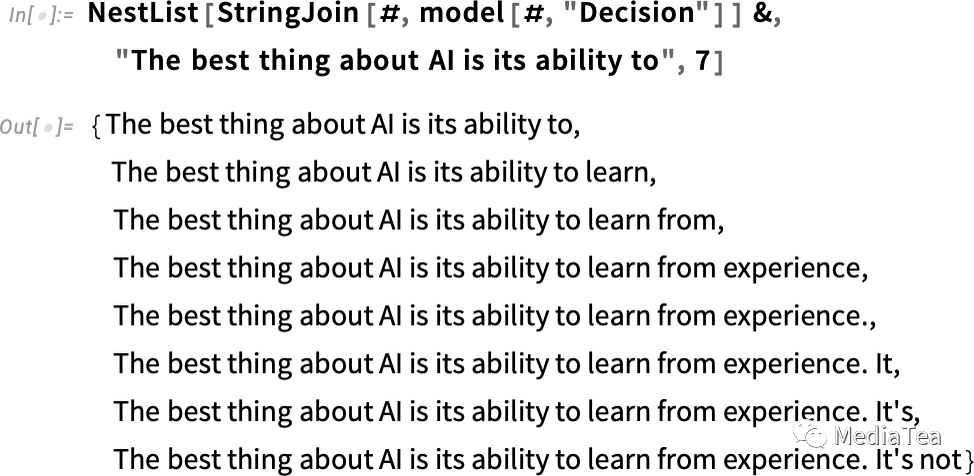
What happens if one goes on longer? In this (“zero temperature”) case what comes out soon gets rather confused and repetitive:
如果持续更长时间会发生什么?在这种(“零温度”)情况下,生成的内容很快变得混乱且重复:

But what if instead of always picking the “top” word one sometimes randomly picks “non-top” words (with the “randomness” corresponding to “temperature” 0.8)? Again one can build up text:
但是,如果不总是选择“排名最高”的词汇,而是有时随机选择“非排名最高”的词汇(这里的“随机性”对应于“温度” 0.8)呢?我们再次生成文本:

And every time one does this, different random choices will be made, and the text will be different—as in these 5 examples:
每次执行这个操作时,都会做出不同的随机选择,生成的文本也会有所不同,就像这 5 个例子中的情况一样:

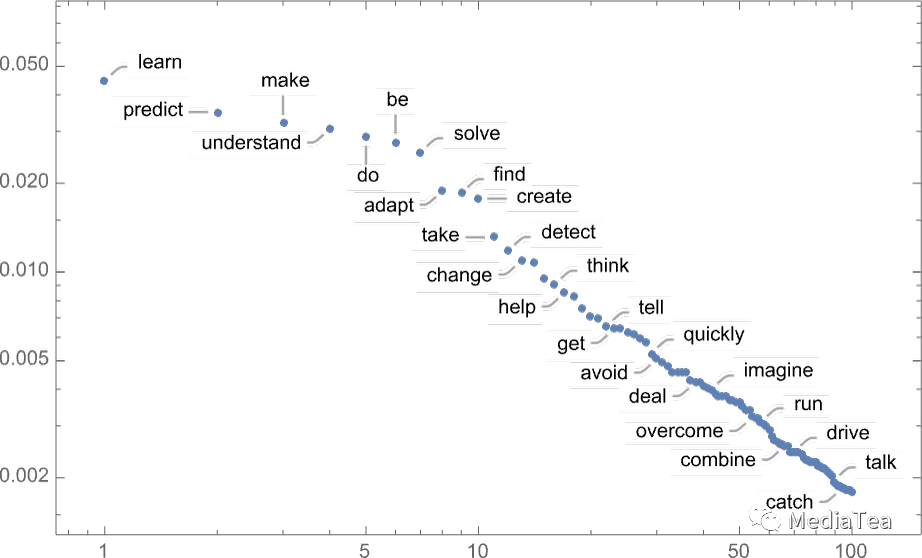
It’s worth pointing out that even at the first step there are a lot of possible “next words” to choose from (at temperature 0.8), though their probabilities fall off quite quickly (and, yes, the straight line on this log-log plot corresponds to an n–1 “power-law” decay that’s very characteristic of the general statistics of language):
值得指出的是,即使在第一步,也有很多可能的“接下来的词汇”可以选择(在温度为 0.8 的情况下),尽管它们的概率下降得相当快(是的,在这个对数-对数图上的直线对应于一个 n-1 的“幂律”衰减,这是语言通用统计特征的一个典型特征):
So what happens if one goes on longer? Here’s a random example. It’s better than the top-word (zero temperature) case, but still at best a bit weird:
那么,如果持续更长时间会发生什么呢?以下是一个随机示例。相比于总选择排名最高的词汇(零温度)情况要好,但最多也只是有点奇怪:

This was done with the simplest GPT-2 model (from 2019). With the newer and bigger GPT-3 models the results are better. Here’s the top-word (zero temperature) text produced with the same “prompt”, but with the biggest GPT-3 model:
这是使用最简单的 GPT-2 模型(2019 年发布)完成的。使用更新且更大的 GPT-3 模型,结果会更好。以下是使用相同的“提示”生成的排名最高词汇(零温度)文本,但使用的是最大的 GPT-3 模型:

And here’s a random example at “temperature 0.8”:
以下是一个“温度 0.8”下的随机示例:


“点赞有美意,赞赏是鼓励”