*分类是离散的,回归是连续的
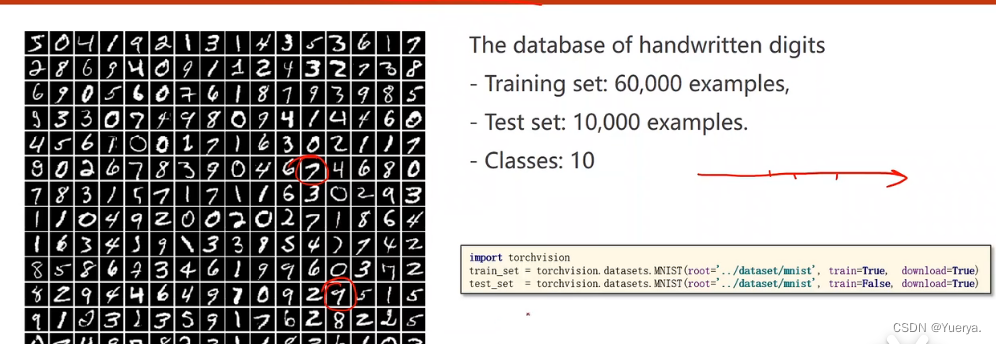
下载数据集
train=True:下载训练集

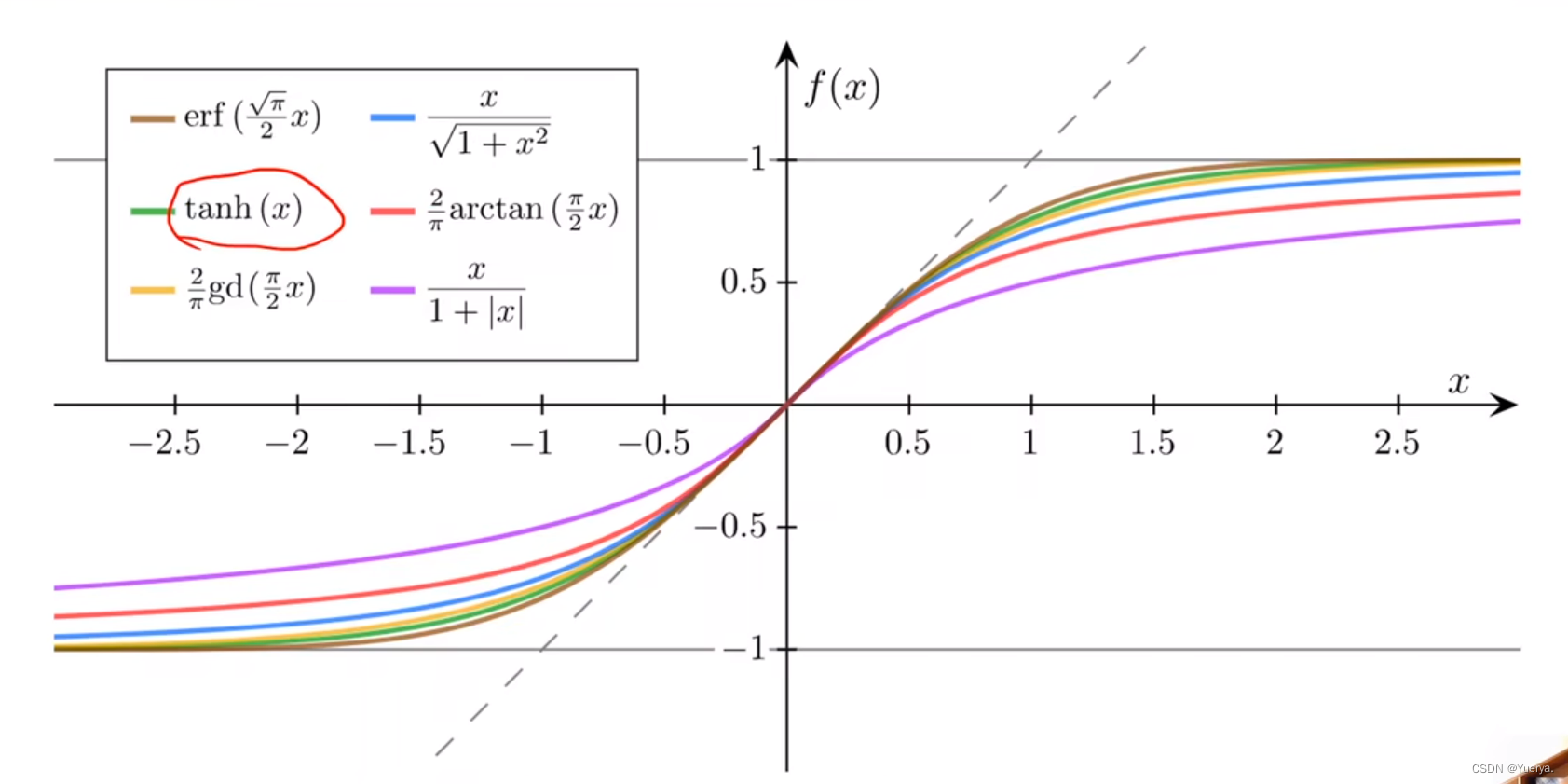
逻辑斯蒂函数保证输出值在0-1之间
能够把实数值映射到0-1之间

导函数类似正态分布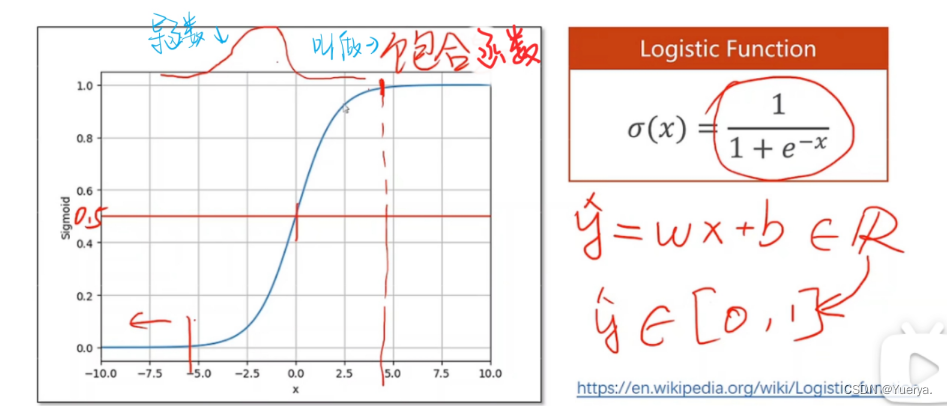
其他饱和函数sigmoid functions
循环神经网络经常使用tanh函数
与线性回归区别
塞戈马无参数,构造函数无区别
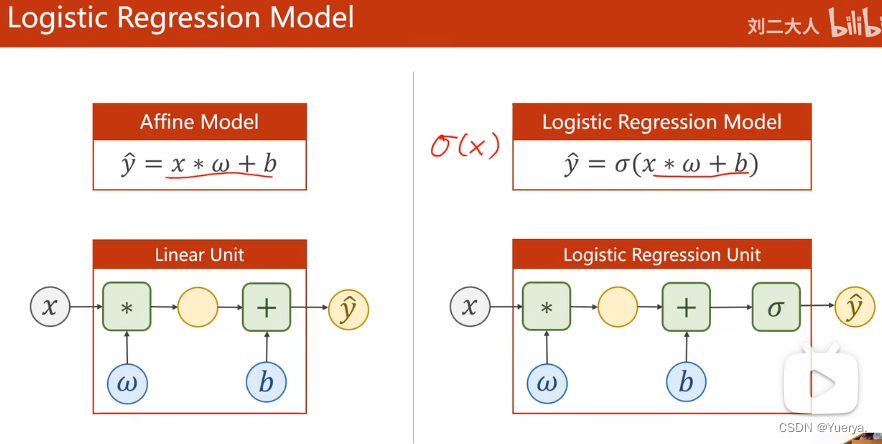
更改损失函数MSE->BCE损失(越小越好)
分布的差异:KL散度,cross-entropy交叉熵
二分类的交叉熵
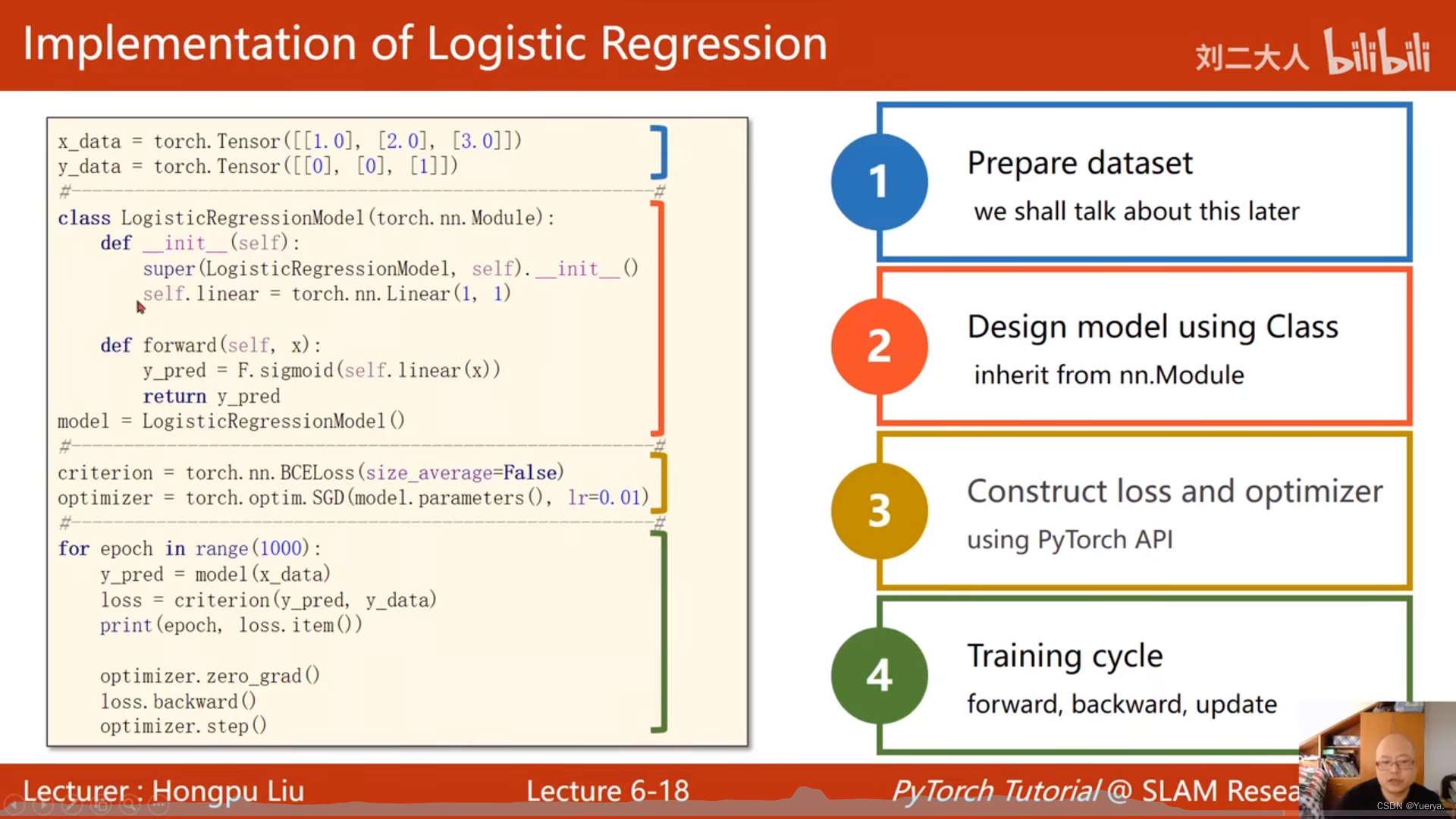

# -*- coding: utf-8 -*-
# @Time : 2023-07-18 20:26
# @Author : yuer
# @FileName: exercise06.py
# @Software: PyCharm
import matplotlib.pyplot as plt
import numpy as np
import torch
# 数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
# 先根据x算出y值再根据y的范围找到分类
class logisticRegressionModel(torch.nn.Module):
def __init__(self):
super(logisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
# x_data,y_data都是一维,与线性回归相比构造没有函数区别
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = logisticRegressionModel()
# 默认情况size_average=True 即loss是1/n倍的,False设置loss不除n
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# SGD梯度下降优化方法 初始化w,b都为0
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 清空梯度
loss.backward() # 反馈算梯度并更新
optimizer.step() # 更新w,b的值
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred=', y_test.data)
x = np.linspace(0, 10, 200) # 在线性空间中以均匀步长生成数字序列;在0-10之间的200个点
x_t = torch.Tensor(x).view((200, 1)) # 转换为200*1的矩阵
y_t = model(x_t) # 利用模型训练
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()