存储介绍
对象存储在现在的项目中应用非常广泛,主要用来存储图片、视频、音频、文件等静态资源,所有云服务厂商基本上都有对象存储,对象存储收费一般 按每月每GB收费,如七牛的0.098 元/GB/月,阿里的0.12元/GB/月。比如上个月我用了30GB那上个月的费用就是30*0.098,这里要注意的是上个月用了30G并不是到上个月结束Bucket里有30G的数据,而是指上个平均每天用量是30G。例如小明上个月每天上午传1G文件,那么上个月用量为(1+2+3+…+30)/30=15.5G,这里就引出一个新问题了,如果小明每天上午传1G文件,下午又删除了1G文件,那么上个月存储用量是多少?肯定不是0,不然不是白嫖了吗?为了不让用户白嫖可以定义每天的用量为当天Bucket出现的最大使用空间,那么小明上午上传1G,下午删除1G,当天存储最大空间为1G,当月的用量为(1+1+1…+1)/30=1G。如果要精确计算当天的最大空间,就需要在每个文件增加和删除时统计了下当前的用量,然后取一天中的最大值,如果要求不高也可以每隔一段时间统计一下用量。这里我介绍使用elasticsearch来统计每天的存储用量。
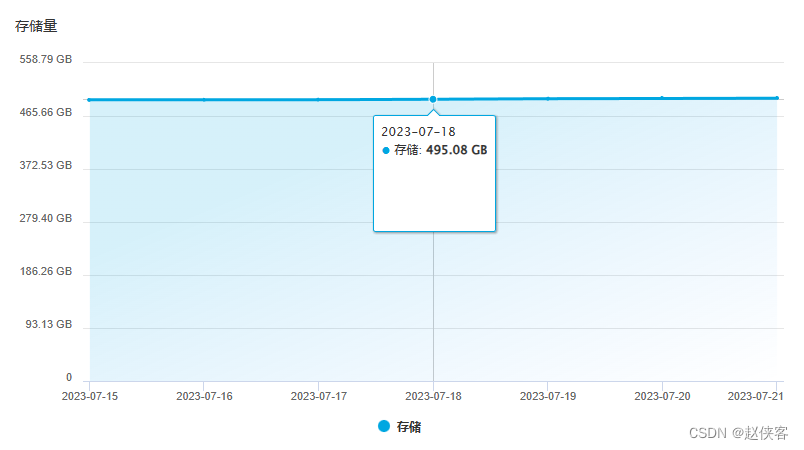
统计基本流程
每隔30分钟统计一下当前存储用量存入ES,主要字段如下:
| 租户ID | 统计时间 | 大小 |
|---|---|---|
| 1 | 2023-07-10 00:00:00 | 1024 |
| 1 | 2023-07-10 00:00:30 | 2024 |
| 1 | 2023-07-10 00:00:00 | 1024 |
创建ES索引
PUT /bucket_size
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"size": {
"type": "long"
},
"tenantId": {
"type": "long"
},
"time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
测试数据
{
"id": "1",
"tenantId": 1,
"size": 1024,
"time": "2023-07-17 18:00:00"
}
{
"id": "2",
"tenantId": 1,
"size": 2048,
"time": "2023-07-17 19:00:00"
}
{
"id": "3",
"tenantId": 1,
"size": 1024,
"time": "2023-07-17 10:00:00"
}
{
"id": "4",
"tenantId": 2,
"size": 1024,
"time": "2023-07-17 09:00:00"
}
{
"id": "5",
"tenantId": 2,
"size": 0,
"time": "2023-07-17 10:00:00"
}
{
"id": "6",
"tenantId": 2,
"size": 1024,
"time": "2023-07-17 11:11:00"
}
查询租户每天用量
查询要求,传入租户ID,起时时间和结束时间,返回指定时间内每个租户每天的用量。
GET /bucket_size/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"tenantId": [
1,
2
],
"boost": 1
}
},
{
"range": {
"time": {
"from": "2023-07-01",
"to": "2023-07-31",
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"aggregations": {
"tenantGroup": {
"terms": {
"field": "tenantId",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
},
"aggregations": {
"groupDay": {
"date_histogram": {
"field": "time",
"format": "yyyy-MM-dd",
"calendar_interval": "1d",
"offset": 0,
"order": {
"_key": "asc"
},
"keyed": false,
"extended_bounds" : {
"min" : "2023-07-01",
"max" : "2023-07-31"
}
},
"aggregations": {
"maxSize": {
"max": {
"field": "size",
"missing": 0
}
}
}
}
}
}
}
}
结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 2,
"hits": [
{
"_index": "bucket_size",
"_type": "_doc",
"_id": "2",
"_score": 2,
"_source": {
"id": "2",
"tenantId": 1,
"size": 2048,
"time": "2023-07-17 19:00:00"
}
}
]
},
"aggregations": {
"tenantGroup": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1,
"doc_count": 3,
"groupDay": {
"buckets": [
{
"key_as_string": "2023-07-01",
"key": 1688169600000,
"doc_count": 0,
"maxSize": {
"value": null
}
},
{
"key_as_string": "2023-07-02",
"key": 1688256000000,
"doc_count": 0,
"maxSize": {
"value": null
}
}
]
}
},
{
"key": 2,
"doc_count": 3,
"groupDay": {
"buckets": [
{
"key_as_string": "2023-07-31",
"key": 1690761600000,
"doc_count": 0,
"maxSize": {
"value": null
}
}
]
}
}
]
}
}
}
使用JAVA代码实现
public Map<Long, Map<String, Long>> getTenantSize(Long[] tenantIds, String mouthStartDate, String mouthEndDate) throws IOException {
Map<Long, Map<String, Long>> map = new TreeMap<>();
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.must(QueryBuilders.termsQuery("tenantId", Arrays.asList(tenantIds)));
queryBuilder.must(QueryBuilders.rangeQuery("time").gte(mouthStartDate).lte(mouthEndDate));
AggregationBuilder tenantGroup = AggregationBuilders.terms("tenantGroup").field("tenantId")
.subAggregation(AggregationBuilders.dateHistogram("groupDay").field("time").calendarInterval(DateHistogramInterval.DAY)
.format(DatePattern.NORM_DATE_PATTERN).order(BucketOrder.key(true)).extendedBounds(new LongBounds(mouthStartDate,mouthEndDate))
.subAggregation(AggregationBuilders.max("maxSize").field("size"))
);
Aggregations aggregations = esClient.search(queryBuilder, tenantGroup, "bucket_size");
Map<String, Aggregation> tenantGroupMap = aggregations.asMap();
if (MapUtil.isNotEmpty(tenantGroupMap)) {
tenantGroupMap.forEach((k, v) -> {
Terms terms = (Terms) v;
List<? extends Terms.Bucket> buckets = terms.getBuckets();
if (CollUtil.isNotEmpty(buckets)) {
buckets.forEach(bucket -> {
Map<String, Long> daySizeMap = new TreeMap<>();
Map<String, Aggregation> dayGroup = bucket.getAggregations().asMap();
if (MapUtil.isNotEmpty(dayGroup)) {
dayGroup.forEach((key, value) -> {
ParsedDateHistogram daySizeTerms = (ParsedDateHistogram) value;
List<? extends Histogram.Bucket> daySizeBucket = daySizeTerms.getBuckets();
if (CollUtil.isNotEmpty(daySizeBucket)) {
daySizeBucket.forEach(daySize -> {
ParsedMax maxSize = daySize.getAggregations().get("maxSize");
Long size=maxSize.getValue()!=Double.NEGATIVE_INFINITY? Double.valueOf(maxSize.getValue()).longValue():0L;
daySizeMap.put(daySize.getKeyAsString(),size);
});
}
});
}
map.put(Long.valueOf(bucket.getKeyAsString()), daySizeMap);
});
}
});
}
return map;
}
总结
本文主要通过介绍使用elasticsearch计算存储来学习一下elasticsearch分组查询的使用以及使用JAVA代码调用elasticsearch分组查询,有以下注意事项:
- 如果查询7月1号到7月30号,ES中没有当天数据也要返回,这里使用了date_histogram,extended_bounds强制返回null
- 查询结果分组后要按时间排序
- 按天aggregations后再用max取当天最大的size为当天的存储用量
- elasticsearch分组查询比较吃内存,已经三层分组了,时间和租户数量不宜太多,不然会OOM
- 案例中是每隔30分钟统计一次存储,如果在30分钟内上传又删除就会被白嫖了