目录
摘要
论文阅读
1、题目和现存问题
2、问题阐述及相关定义
3、LGDL模型框架
4、实验准备
5、实验过程
深度学习
1、GCN简单分类任务
2、文献引用数据分类案例
3、将时序型数据构建为图数据格式
总结
摘要
本周在论文阅读上,对基于图神经网络与深度学习的商品推荐算法论文进行阅读,利用图神经网络提取关联关系的同时,利用深度学习提取评论的优势提取用户和商品的一般偏好,并进行特征融合来提升推荐效果。结果表明,此算法比已有相关算法更好。在深度学习上,对于GCN的实践开始了学习,并开始构建时序性数据。
This week,in terms of thesis reading,perusaling the paper on commodity recommendation algorithm based on graph neural network and deep learning.The graph neural network is used to extract the association relationship,and use the advantage of deep learning to extract comments to extract general preferences of users and products.Besides carry out feature fusion to improve the recommendation effect.The results shows that the algorithm is better than the existing related algorithms.In terms of deep learning, starting to learn about the practice of GCN and began to construct temporal data.
论文阅读
1、题目和现存问题
题目:基于图神经网络与深度学习的商品推荐算法
现存问题:目前大部分基于图神经网络的推荐算法均使用用户物品的ID信息提取用户物品特征,忽略了数据中评论文本等其他数据所隐含的用户物品特征,或使用了辅助信息却使得网络训练更复杂。大部分基于GCN的推荐算法没有考虑到深度学习在文本等其他信息处理中的优势。
文章提出的解决办法:利用LightGCN基础网络同时增加注意力机制来提取用户物品之间的高阶特性,作为用户物品特征表示的一部分。其次,使用传统深度学习网络从评论文本中提取用户物品特征的另一部分。最终将两特征表示进行融合获得最终用户物品特征表示,进而给出推荐。
2、问题阐述及相关定义
给定一个包含X个样本的数据集D,其中每个样本(u,i,Rui)表示用户u对商品i写了一条评论Rui。如下图所示,本文的核心任务是训练出一个模型,根据全部用户与全部商品交互(不包含用户u与商品i的交互)来学习用户u、商品i的关联关系表示,同时根据用户u的评论集(用户u除Rui外的评论)、商品i的评论集(商品i除Rui外的评论)学习用户u与商品i的一般偏好表示,综合两种特征表示预测用户 u 对商品i的评分Pui。

使用相同方法得到用户u对全部商品的评分集合Pu,根据该评分集合对用户u给出前K个商品推荐,最终任务是使该推荐集合更接近用户u未来的购买行为。下表为本文使用的相关运算符号及其定义。

3、LGDL模型框架
该模型框架中包含嵌入层、前向传播层和评分预测层三个主要模块,框架图如下所示。

嵌入层
嵌入层负责将用户商品ID及用户商品评论信息输入模型。
全部用户的ID嵌入向量构成集合:
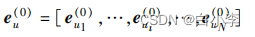
全部商品的ID嵌入向量构成集合:

商品与用户的ID嵌入向量均为初始状态,通过在前向传播层进行传播来进一步细化嵌入,使ID嵌入向量可以更好地表达其内含的关联关系。
前向传播层
前向传播层分为两个并行框架来分别提取用户与商品的关联关系及一般偏好。
用户ui 的ID嵌入在图卷积网络传播一次的计算规则为:

商品Ij的ID嵌入在网络中传播一次的计算规则为:

节点在图卷积网络中的一阶传播建模了用户和项目之间的一阶关联关系特征,利用一阶传播的计算方法,可以在图卷积网络中堆叠多层图卷积来建模用户与项目之间的高阶关联关系特征。
用户ui和商品ij 的表达:
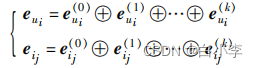
利用注意力向量将每层的嵌入向量加权求和可以得到最终的用户ui 的关联关系嵌入表达:

商品ij的关联关系嵌入最终表达:
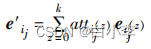
评分预测层
本文采用concat方法对两特征向量进行特征融合,从而得到最终用户ui和商品ij的特征表示:

用户对商品的最终评分预测:
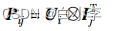
文章采用推荐系统中使用广泛的BPR损失。该损失基于贝叶斯排序,考虑到了可观察到和不可观察到的用户与物品交互的相对顺序,认为观察到的交互项的重要程度比不可观察到的交互项的重要程度更高。
4、实验准备
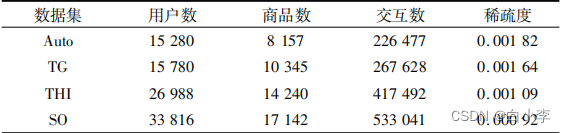
采用亚马逊数据集。首先从总数据集中提取所需数据,其次由于评论文本数据存在空值、评论字数过少等情况,需要对评论文本数据进行数据清洗。由于空评论无法反映用户对商品的偏好,即使进行随机填充也无法正确表达用户偏好,所以去除空值评论数据;对于评论字数过少的数据通过对评论进行复制填充,对于评论字数过长的数据进行删除(无意义、意义相对较低的词和符号等),使评论字数长度统一为RL=50。通过对用户ID和商品ID进行统计分析,制作10-core版本的数据集。
本文采取top K推荐方法进行推荐,其中K=20,采用了召回率recall和归一化折损累计增益两种评价指标来评价模型性能。模型召回率的计算公式为

NDCG衡量了推荐列表中不同位置推荐结果的相关性得分,与用户相关性越高的推荐商品的排序越靠前,其推荐效果越好,得分也越高。
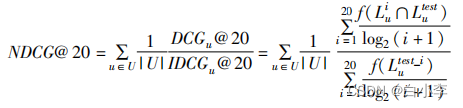
对比模型:LFM、NeuMF、NGCF、LightGCN。
正则化权重采用5E-5,最终迭代层数确定为2层,故嵌入向量维度最终采用64维。
5、实验过程
本文在四个数据集上对五个模型进行了实验对比
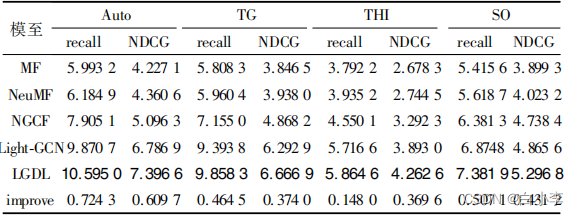
由本文模型LGDL与其他模型对比可以看出,其在四个数据集的模型表现均优于其他模型,召回率在数值上至少有0.15%的提升,NDCG在数值上至少有0.37%的提升。相比于次优模型LightGCN效果相对提升了约 5%,证明本文模型设计的方法对于模型效果的提升有相应贡献。
本文针对LGDL模型的各个部分设置了四种变体来进行消融实验,以验证模型的有效性。模型对比结果如下图所示。

LGDL-1表示模型取消注意力机制部分且不使用评论文本嵌入数据。
LGDL-2表示模型增加了注意力机制部分,且不使用评论文本嵌入数据。
LGDL-3表示模型只使用评论文本嵌入数据进行推荐。
LGDL-1采用简单的GCN层嵌入的融合效果,相比LightGCN效果略低。LGDL-2相比LGDL-1明显增加了注意力机制模型效果,说明注意力机制模块在模型中是有效的。LGDL-3只采用评论文本数据,相比前两个变体效果略低,但结合评论文本及注意力机制的LGDL的效果比单使用注意力机制的LGDL-2效果要好,说明评论文本中提取的用户商品一般偏好特征在最终特征表达中作出了贡献,即添加评论文本数据处理模块对模型效果增加是有贡献的。
深度学习
1、GCN简单分类任务
使用PyTorch和PyTorch Geometric库在Karate Club数据集上实现图卷积网络(GCN)。目标是在Karate Club网络上执行节点分类。
-
数据准备:
-
使用
torch_geometric.datasets中的KarateClub类下载Karate Club数据集。 -
打印一些关于数据集的基本信息,如图的数量、特征数量和类别数量。
-
-
图可视化(可选):
-
代码中包含一个名为
visualize_graph(G, color)的函数,用于根据节点的颜色可视化图。
-
-
网络模型:
-
定义了一个名为
GCN的类,表示图卷积网络。 -
该类包含了三个图卷积层(
GCNConv)和一个线性层(Linear)作为分类器。
-
-
训练过程:
-
使用交叉熵损失函数(
CrossEntropyLoss)作为损失函数。 -
使用Adam优化器(
Adam)进行参数优化。 -
进行多个训练轮次,每100轮可视化一次嵌入向量,并打印当前损失和训练轮次。
-
import time
import torch
import pandas
import networkx as nx
import torch.nn as nn
from torch.nn import Linear
from torch_geometric.nn import GCNConv
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch_geometric.datasets import KarateClub
#
from torch_geometric.utils import to_networkx
#画图工具
def visualize_graph(G,color):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
nx.draw_networkx(G, pos=nx.spring_layout(G,seed=42), with_labels=False, node_color=color, cmap="Set2")
plt.show()
#
def visualize_embedding(h,color, epoch=None, loss=None):
plt.figure(figsize=(7,7))
plt.xticks()
plt.yticks()
h = h.detach().cpu().numpy()
plt.scatter(h[:, 0],h[:, 1], s=140, c=color, cmap="Set2")
if epoch is not None and loss is not None:
plt.xlabel(f'Epoch:{epoch}, Loss:{loss.item():.4f}', fontsize=16)
plt.show()
#下载数据集
dataset = KarateClub()
print(f'Dataset;{dataset}:')
print(f'----------')
print(f'Number of grapshs:{len(dataset)}')
print(f'Number of feature:{dataset.num_features}')
print(f'Number of classes:{dataset.num_classes}')
data = dataset[0]
print(data) #Data(x=[34, 34](样本数和特征维度), edge_index=[2, 156], y=[34](标签), train_mask=[34](指定哪些点有标签,哪些没有))
edge_index= data.edge_index
# print(edge_index.t()) #输出邻接矩阵
#画图
# G = to_networkx(data, to_undirected=True)
# visualize_graph(G, color=data.y)
#网络模块
class GCN(nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(1234)
self.conv1 = GCNConv(dataset.num_features, 4) #只需定义输入特征和输出特征
self.conv2 = GCNConv(4,4)
self.conv3 = GCNConv(4,2)
self.classifer = Linear(2, dataset.num_classes)
def forward(self, x, edge_index):
h = self.conv1(x, edge_index) #输入特征和邻接矩阵
h = h.tanh()
h = self.conv2(h, edge_index)
h = h.tanh()
h = self.conv3(h, edge_index)
h = h.tanh()
out = self.classifer(h)
return out,h #h是上面那个2维向量
model = GCN()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
def train(data):
optimizer.zero_grad()
out, h = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss,h
for epoch in range(401):
loss, h = train(data)
if epoch % 100 == 0:
visualize_embedding(h, color=data.y, epoch=epoch,loss=loss)
time.sleep(0.3)分类最终结果:

2、文献引用数据分类案例
对引用数据集进行节点分类任务。数据集中每个节点都有一个1433维的特征向量,最终需要对每个节点进行7分类任务,其中每个类别只有20个节点有标注。
-
数据准备:
-
使用
torch_geometric.datasets中的Planetoid类下载Cora数据集,并进行特征向量的标准化处理(NormalizeFeatures)。 -
打印数据集的相关信息。
-
-
可视化函数:
-
visualize(h, color)函数用于对嵌入向量进行可视化,使用t-SNE算法将高维向量降维到2维,然后在二维平面上绘制节点。
-
-
GCN模型定义:
-
定义一个名为
GCN的子类,继承自torch.nn.Module。 -
GCN模型包含两个图卷积层和一个ReLU激活函数。
-
-
训练和测试:
-
使用交叉熵损失函数(
CrossEntropyLoss)作为损失函数。 -
使用Adam优化器(
Adam)进行参数优化。 -
进行多个训练轮次,在每个轮次中进行训练和损失计算。
-
在训练完成后,计算测试集的分类准确率。
-
-
可视化训练后的节点嵌入:
-
在训练完成后,将模型应用于数据,获取节点嵌入向量,并用
t-SNE算法降维并绘制节点的分布图。
-
'''
论文引用数据集,每一个点哟1433维向量
最终要对每个点进行7分类任务(每个类别只有20个点有标注)
'''
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import GCNConv
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import torch
import torch.nn.functional as F
from torch.nn import Linear
#可视化部分
def visualize(h,color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(10,10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:,0],z[:,1], s=70, c=color, cmap="Set2")
plt.show()
dataset = Planetoid(root='./Planetoid', name='Cora', transform=NormalizeFeatures())#transform预处理
print(dataset)
data = dataset[0]
print(data)
class GCN(torch.nn.Module):
def __init__(self, hidden_channels) :
super().__init__()
torch.manual_seed(1234)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index) #x:2708*1433
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
#训练前数据的展示图
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
for epoch in range(1,101):
loss = train()
print(f'Epoch:{epoch}, Loss:{loss:.4f}')
test_acc = test()
print(f'Test Accuracy:{test_acc:.4f}')
#训练后数据的展示图
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)训练前的数据分布图

训练后的图像

3、将时序型数据构建为图数据格式
选取3个表,将其连接为全连接图,后6列作为节点的属性
import pandas as pd
import torch
from torch_geometric.data import Data
data1 = pd.read_excel('data\桂林市\八中.xlsx')
data2 = pd.read_excel('data\桂林市\监测站.xlsx')
data3 = pd.read_excel('data\桂林市\龙隐路小学.xlsx')
# 提取后6列数据并转换为PyTorch Tensor
features1 = torch.tensor(data1.iloc[:, -6:].values, dtype=torch.float)
features2 = torch.tensor(data2.iloc[:, -6:].values, dtype=torch.float)
features3 = torch.tensor(data3.iloc[:, -6:].values, dtype=torch.float)
# # 建立节点与行的对应关系
node_features = torch.cat([features1, features2, features3], dim=0)
# 构建边的索引
num_nodes1, num_nodes2, num_nodes3 = len(data1), len(data2), len(data3)
edge_index1 = torch.tensor([[i, j] for i in range(num_nodes1) for j in range(num_nodes2 + num_nodes3)], dtype=torch.long)
edge_index2 = torch.tensor([[i + num_nodes1, j] for i in range(num_nodes2) for j in range(num_nodes1 + num_nodes3)], dtype=torch.long)
edge_index3 = torch.tensor([[i + num_nodes1 + num_nodes2, j] for i in range(num_nodes3) for j in range(num_nodes1 + num_nodes2)], dtype=torch.long)
# 合并三个表的边索引
edge_index = torch.cat([edge_index1, edge_index2, edge_index3], dim=0).t()
# 创建Data对象
data = Data(x=node_features, edge_index=edge_index)
torch.save(data,'./GNN数据/gnn_guilin.pt')
print(data)总结
本周继续对图神经网络的相关知识进行学习,在构建时序型数据时遇见了问题,对于表中的这么多行数据到底该进行什么样的处理,在接下来的学习将进一步思考。